import fitz
import re
import pandas as pd
#判断行业中上市公司个数是否满足大于等于10的要求
def does_match(text):
if len(re.findall('\n\d{6}\n',text)) < 10:
return False
else:
return True
def find_assignment(No,num):
#No为int类型,表示在本次作业中该学生的序号
#num代表该行业前num家上市公司
#读取所有的内容
text = ''
with fitz.open('../1638277734844_11692.pdf') as doc:
for page in doc:
text = text + page.get_text('text')
#找到所有行业的两位代码
locs = re.finditer('\n\d{2}\n',text)
#注意locs里面可能有重复的行业标号,需要筛选一下
loc_dict = {}
for loc in locs:
#loc.span()的结果为左开右闭的区间,去除两端的换行符
s = loc.span()[0] + 1
e = loc.span()[1] - 1
if text[s:e] in loc_dict:
continue
else:
loc_dict[text[s:e]] = [s,e]
#获取有效行业(上市公司>=10),将他们放入列表effective_industries中,
last_key = '' #保存上一次循环中的key
last_value = 0 #保存上一次循环中的value[1],即行业代码的索引的后一位置(为换行符)
effective_industries = []
for key,value in loc_dict.items():
if key != '01':
subtext = text[last_value:value[0]]
if does_match(subtext) == False:
last_key = key
last_value = value[1]
continue
else:
effective_industries.append(last_key)
#第一个的key必定是01,所以第一次循环直接跳到这一步
last_key = key
last_value = value[1]
#注意,最后还剩下一部分没循环到
subtext = text[last_value:len(text)]
if does_match(subtext) == True:
effective_industries.append(key)
#判断No匹配哪个行业
#可能会出现No超过了有效行业数,故采用模运算
No = No % len(effective_industries)
my_industry = effective_industries[No-1]
print('第'+ str(No) + '号的作业是行业 ' + my_industry)
'''
附加代码,找到自己的行业包含的所有公司代码,以列表返回
'''
s = loc_dict.get(my_industry)[1]
#获得下一个键值对,如'01'之后为'02'
if int(my_industry) < 9:
nxt = '0' + str(int(my_industry) + 1)
elif int(my_industry) == 9:
nxt = '10'
else:
nxt = str(int(my_industry) + 1)
e = loc_dict.get(nxt)[0]
subtext = text[s:e]
code_list = re.findall('\n\d{6}\n',subtext)
code_list = [code.strip() for code in code_list]
'''
附加代码,找到自己的行业包含的所有公司名称,以列表返回
'''
name_list = []
for code in code_list:
code_first_loc = subtext.find(code)
start = code_first_loc + 7
end = subtext.find('\n', start)
name = subtext[start : end]
name_list.append(name)
'''
把公司代码code_list和公司名称name_list合并成dataframe
'''
df = {'code_list':code_list[0:num], 'name_list':name_list[0:num]}
df = pd.DataFrame(df)
return df
import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
import pdfplumber
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
company_list = ['000488','000815','001206','002012','002067','002078','002228','002303','002511','002521','002565',
'002799','002831','003006','300883','301009','301062','600103','600235','600308','600356','600433',
'600567','600793','600963','600966','603022','603165','603607','603687','603733','603863','605007',
'605009','605377','605500']
for company in company_list:
os.mkdir(company)
orgId, plate,code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")
运行结果
import fitz
import re
import pandas as pd
import os
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
'''董秘信息、营业收入、办公地址'''
def getText(pdf):#定义函数获取文本
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.get_text()
doc.close()
text = text.replace(" "," \n")
text = text.replace("\n\n","\n")
# 由于后续subp匹配过程中,有的数字后面没有换行符,无法成功进行非贪婪的匹配,所以通过文本内部符号替换
return(text)
path = 'D:\年报' #年报所处路径
全部文件 = os.listdir(r'D:\年报')
#j=0 #用来控制for
董秘信息 = pd.DataFrame()
营业收入 = pd.DataFrame()
收益 = pd.DataFrame()
地址 = pd.DataFrame()
网址 = pd.DataFrame()
邮箱 = pd.DataFrame()
for 年报 in range(len(全部文件)):
#j = j+1
# if j >5:
# break
路径 = os.path.join(r'D:\年报',全部文件[年报])
text = getText(路径)
# 匹配出董秘信息
try:
p_site = re.compile('(?<=\n)\w*董事会秘书?\s?\n证券事务代表\s\n姓名?\s?\n?(.*?)\s?(?=\n)', re.DOTALL) # 匹配出董事会秘书姓名
site1 = p_site.search(text).group(0)
p_site2 = re.compile(
'(?<=\n)\w*董事会秘书?\s?\n证券事务代表\s\n姓名?\s?\n?(.*?)\s?(?=电话)\s?\电话?\s\n?(.*?)(?=\n)', re.DOTALL)
site2 = p_site2.search(text).group(0)
len(site2)
董秘姓名 = site1[19:]
董秘电话 = site2[-13:]
# print(pd.DataFrame(data = [董秘姓名,董秘电话],index = ['董秘姓名','董秘电话'],columns = [年报[7:11]]))
df = (pd.DataFrame(data = [董秘姓名,董秘电话],index = ['{年报}董秘姓名'.format(年报=全部文件[年报][:6]),'{年报}董秘电话'.format(年报=全部文件[年报][:6])],columns = [全部文件[年报][7:11]]))
董秘信息 = pd.concat([董秘信息,df],axis=1)
#print(董秘信息)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
董秘信息.to_excel(r'C:\Users\HI\Desktop\董秘信息汇总\{年报}董秘信息.xlsx'.format(年报=全部文件[年报][:6])) #d
董秘信息 = pd.DataFrame()
else:
董秘信息.to_excel(r'C:\Users\HI\Desktop\董秘信息汇总\{年报}董秘信息.xlsx'.format(年报=全部文件[年报][:6])) # d
董秘信息 = pd.DataFrame()
except:
print(全部文件[年报],'董秘信息出错了')
pass
# 匹配出营业收入
try:
# p_site = re.compile('(?<=\n)\w*营业收入?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
# site1 = p_site.search(text).group(0)
# 收入 = site1[5:]
#text = getText(r'F:\许晶作业\年报\601225-2014年度报告.pdf')
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)净利润', re.DOTALL)
txt = p_s.search(text).group(0)
p_site = re.compile('(?<=\n)\w*营业收入?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
site1 = p_site.search(txt).group(0)
收入 = site1[6:]
a = re.findall(r"\d+\.?\d*", site1)
收入 = ''.join(a)
收入 = 收入.replace(',','')
收入 = pd.to_numeric(收入)
if '单位:亿元' in txt:
收入 = 收入 * 1000000
elif '单位:万元' in txt:
收入 = 收入 * 10000
elif '单位:百万元' in txt:
收入 = 收入 * 1000000
elif '单位:千元' in txt:
收入 = 收入 * 1000
df = pd.DataFrame(data = [收入],index = ['{年报}收入'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
#print(df)
营业收入 = pd.concat([营业收入,df],axis=1)
#print(营业收入)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
营业收入.to_excel(r'C:\Users\HI\Desktop\营业收入汇总\{年报}营业收入.xlsx'.format(年报=全部文件[年报][:6])) #d
营业收入 = pd.DataFrame()
else:
营业收入.to_excel(r'C:\Users\HI\Desktop\营业收入汇总\{年报}营业收入.xlsx'.format(年报=全部文件[年报][:6])) # d
营业收入 = pd.DataFrame()
except:
print(全部文件[年报], '营业收入出错了')
营业收入 = pd.DataFrame()
pass
# 匹配出办公地址
try:
p_site = re.compile('(?<=\n)\w*办公地址?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
site1 = p_site.search(text).group(0)
办公地址 = site1[8:]
df = pd.DataFrame(data = [办公地址],index = ['{年报}办公地址'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
# print(df)
地址 = pd.concat([地址,df],axis=1)
#print(地址)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
地址.to_excel(r'C:\Users\HI\Desktop\办公地址汇总\{年报}办公地址.xlsx'.format(年报=全部文件[年报][:6])) #d
地址 = pd.DataFrame()
else:
地址.to_excel(r'C:\Users\HI\Desktop\办公地址汇总\{年报}办公地址.xlsx'.format(年报=全部文件[年报][:6])) # d
地址 = pd.DataFrame()
except:
print(全部文件[年报], '办公地址出错了')
pass
'''电子邮箱、公司网址、每股收益'''
try:
p_site = re.compile('(?<=\n)\w*电子信箱?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
site1 = p_site.search(text).group(0)
电子信箱 = site1[6:]
df = pd.DataFrame(data = [电子信箱],index = ['{年报}邮箱'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
# print(df)
邮箱 = pd.concat([邮箱,df],axis=1)
# print(邮箱)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
邮箱.to_excel(r'C:\Users\HI\Desktop\邮箱汇总\{年报}邮箱.xlsx'.format(年报=全部文件[年报][:6])) #d
邮箱 = pd.DataFrame()
else:
邮箱.to_excel(r'C:\Users\HI\Desktop\邮箱汇总\{年报}邮箱.xlsx'.format(年报=全部文件[年报][:6])) # d
邮箱 = pd.DataFrame()
except:
print(全部文件[年报], '邮箱出错了')
pass
# 匹配出公司网址
try:
p_site = re.compile('(?<=\n)\w*公司?网址\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
p_site = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
site1 = p_site.search(text).group(0)
公司网址 = site1[6:]
df = pd.DataFrame(data = [公司网址],index = ['{年报}网址'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
# print(df)
网址 = pd.concat([网址,df],axis=1)
#print(网址)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
网址.to_excel(r'C:\Users\HI\Desktop\网址汇总\{年报}网址.xlsx'.format(年报=全部文件[年报][:6])) #d
网址 = pd.DataFrame()
else:
网址.to_excel(r'C:\Users\HI\Desktop\网址汇总\{年报}网址.xlsx'.format(年报=全部文件[年报][:6])) # d
网址 = pd.DataFrame()
except:
print(全部文件[年报], '网址出错了')
pass
# 匹配出每股收益
try:
# text = getText(r'F:\许晶作业\年报\601088-2020年度报告.pdf')
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)收益率', re.DOTALL)
txt = p_s.search(text).group(0)
p_site = re.compile('(?<=\n)\w*基本每股(.*?)亏?损?\s?\n?(.*?)\s?(?=\n)\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
site1 = p_site.search(txt).group(0)
if site1[:11] == '基本每股收益(元/股)' or site1[:11] == '基本每股收益(元/股)' or site1[:11] == '基本每股收益(元/股)':
每股收益 = site1[13:]
else:
每股收益 = site1[16:]
df = pd.DataFrame(data = [每股收益],index = ['{年报}每股收益'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
#print(df)
收益 = pd.concat([收益,df],axis=1)
#print(收益)
if 年报 != len(全部文件)-1:
if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
收益.to_excel(r'C:\Users\HI\Desktop\收益汇总\{年报}收益.xlsx'.format(年报=全部文件[年报][:6])) #d
收益 = pd.DataFrame()
else:
收益.to_excel(r'C:\Users\HI\Desktop\收益汇总\{年报}收益.xlsx'.format(年报=全部文件[年报][:6])) # d
收益 = pd.DataFrame()
except:
print(全部文件[年报], '每股收益出错了')
收益 = pd.DataFrame()
pass
.png)
import matplotlib.pyplot as plt
import numpy as np
import tool
def draw_pics_twinx(df):
plt.rcParams['figure.dpi'] = 200
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图片显示中文
x = df['year']
tool.to_year_list(x)
y_rt = df['营业收入']
tool.to_num_list(y_rt)
y_ni = df['净利润']
tool.to_num_list(y_ni)
fig = plt.figure()
ax1 = fig.subplots()
ax1.plot(x, y_rt,'steelblue',label="营业收入",linestyle='-',linewidth=2,
marker='o',markeredgecolor='pink',markersize='2',markeredgewidth=2)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_rt[i],(y_rt[i]),fontsize = '10')
ax1.legend(loc = 6)
ax2 = ax1.twinx()
ax2.plot(x, y_ni, 'orange',label = "归属于股东的净利润",linestyle='-',linewidth=2,
marker='o',markeredgecolor='teal',markersize='2',markeredgewidth=2)
ax2.set_ylabel('归属于股东的净利润(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_ni[i],(y_ni[i]),fontsize = '10')
ax2.legend(loc = 2)
'''
title部分必须放最后,否则会出现左边的y轴有重复刻度的问题
'''
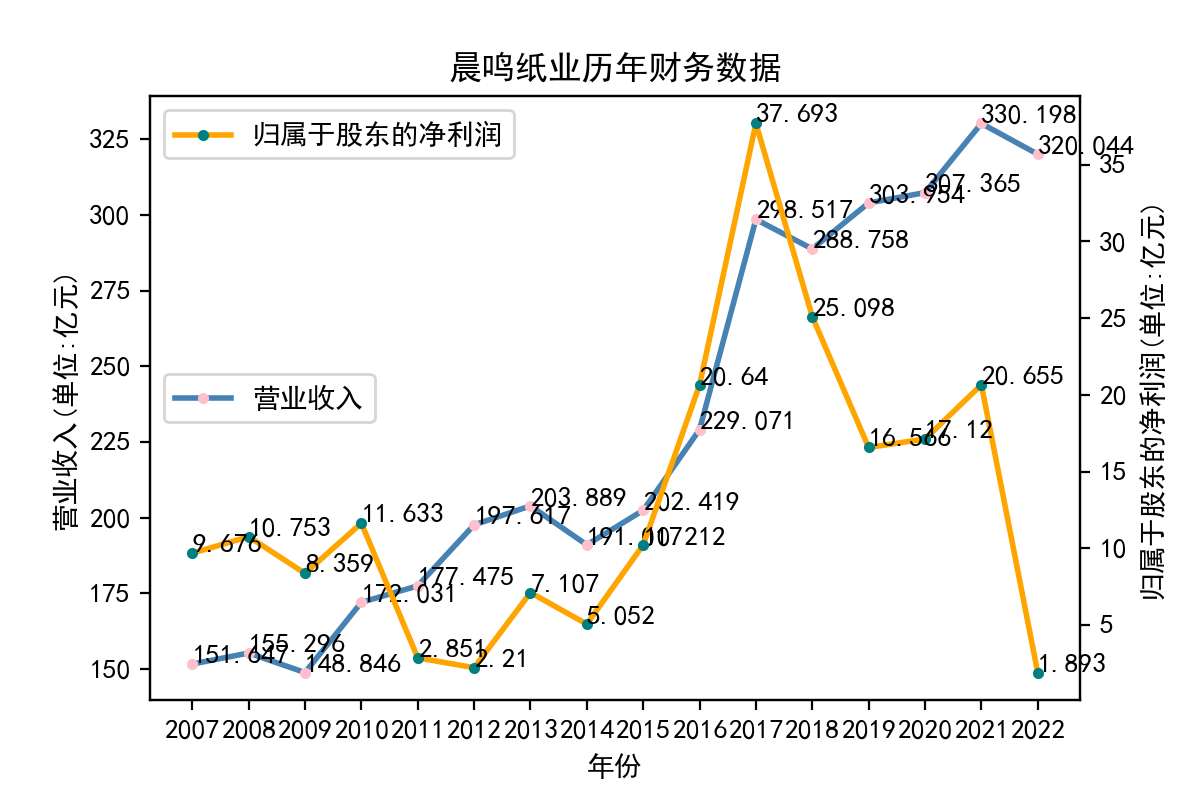
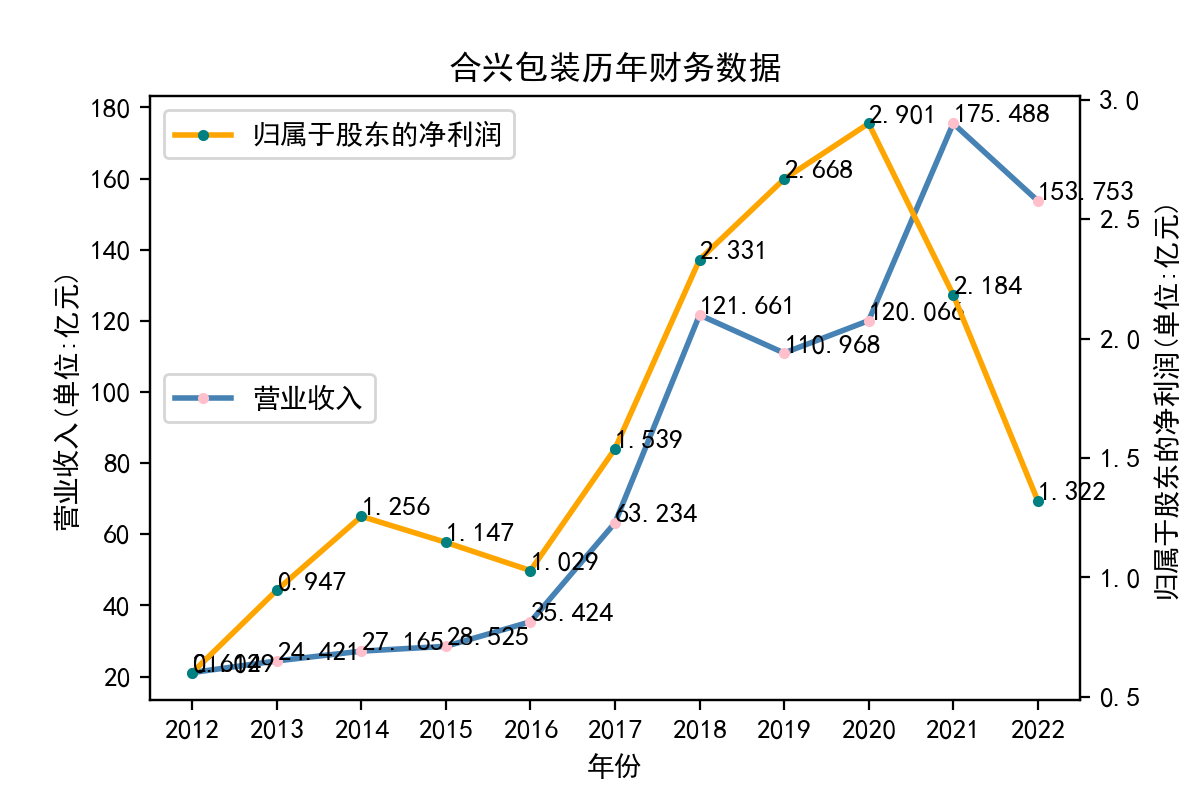
title = df['name'][0] + '历年' + '财务数据'
plt.title(title)
plt.savefig('../pics/' + title + '.png')
plt.show()
运行结果
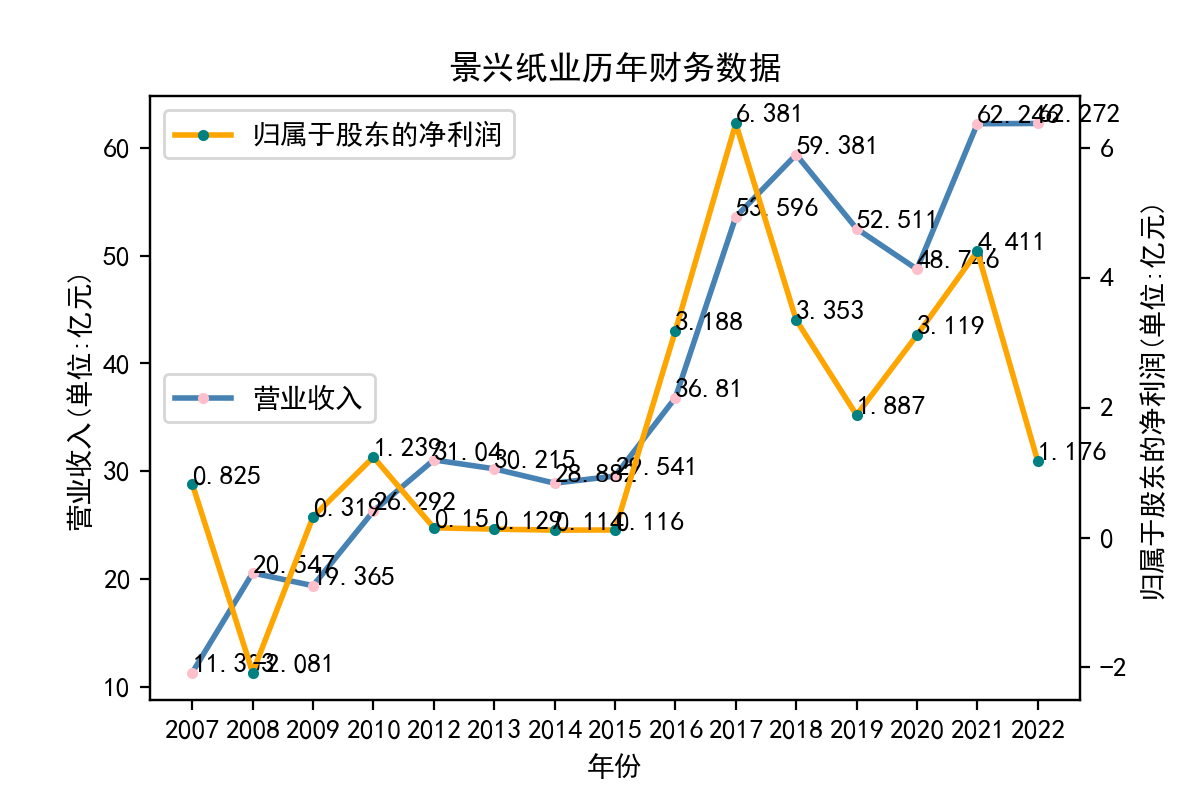
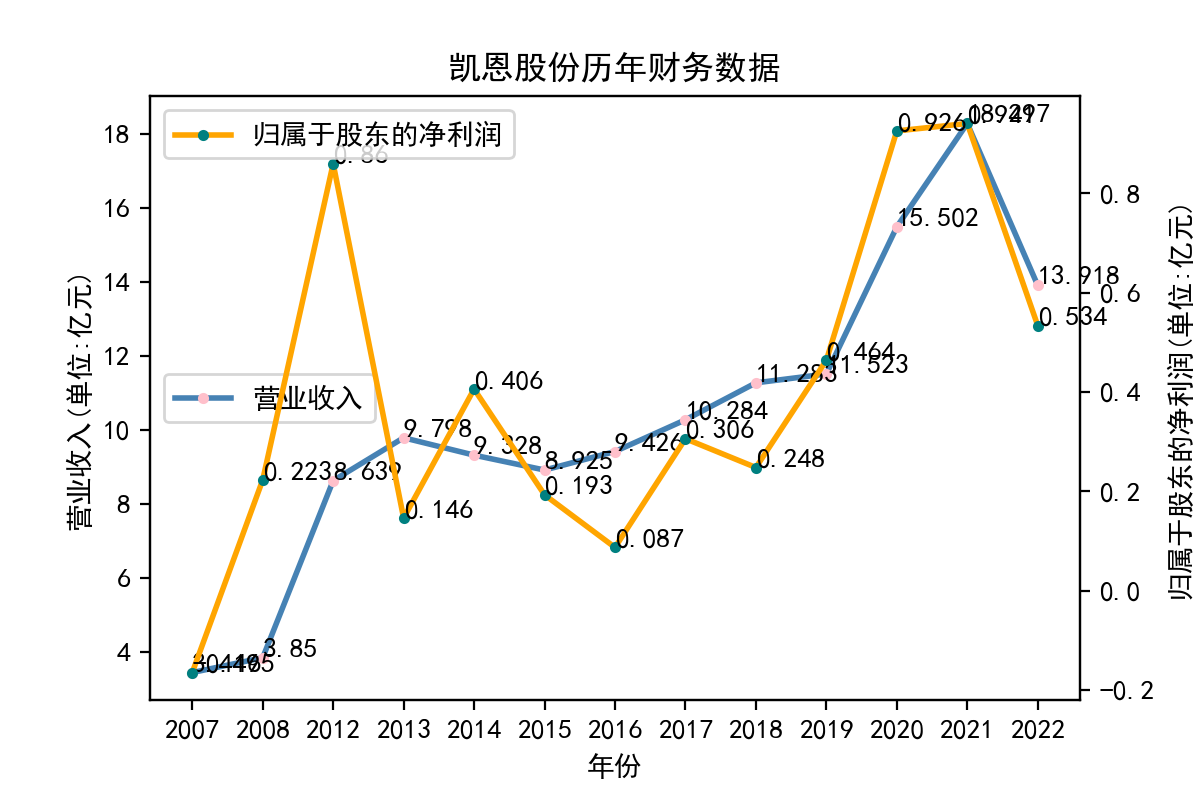
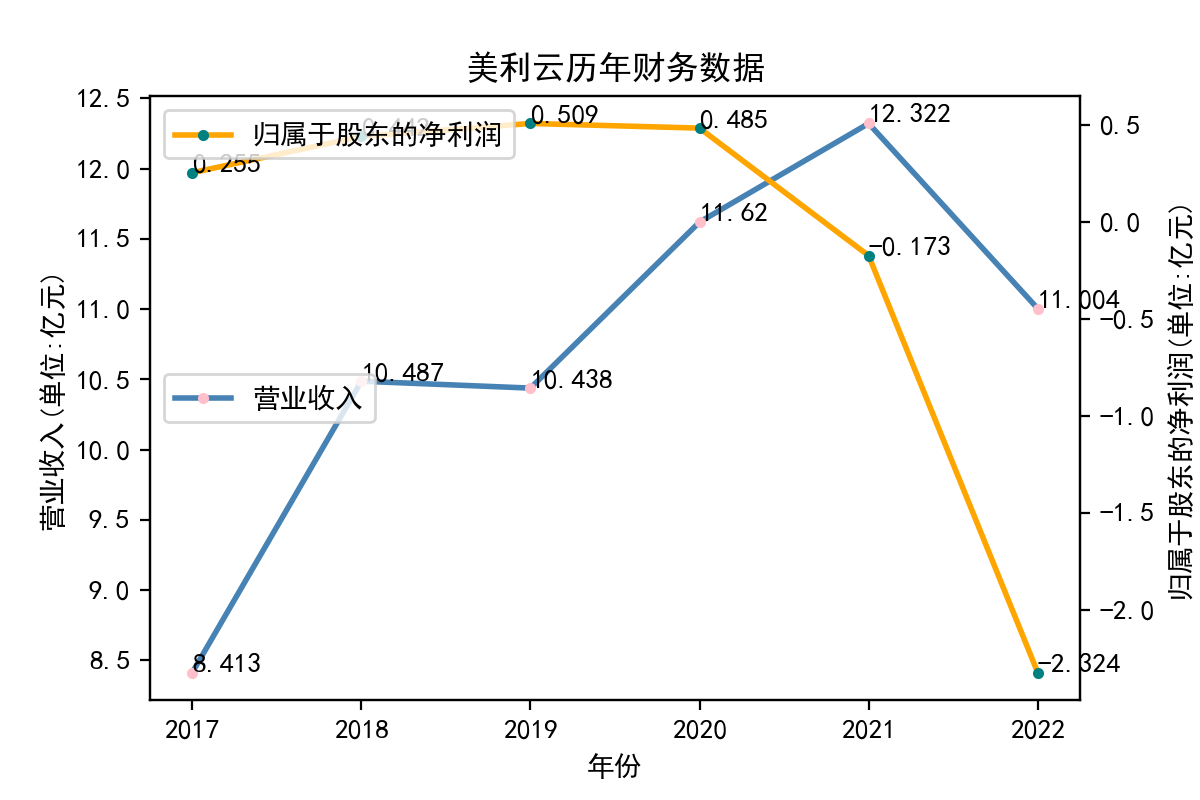
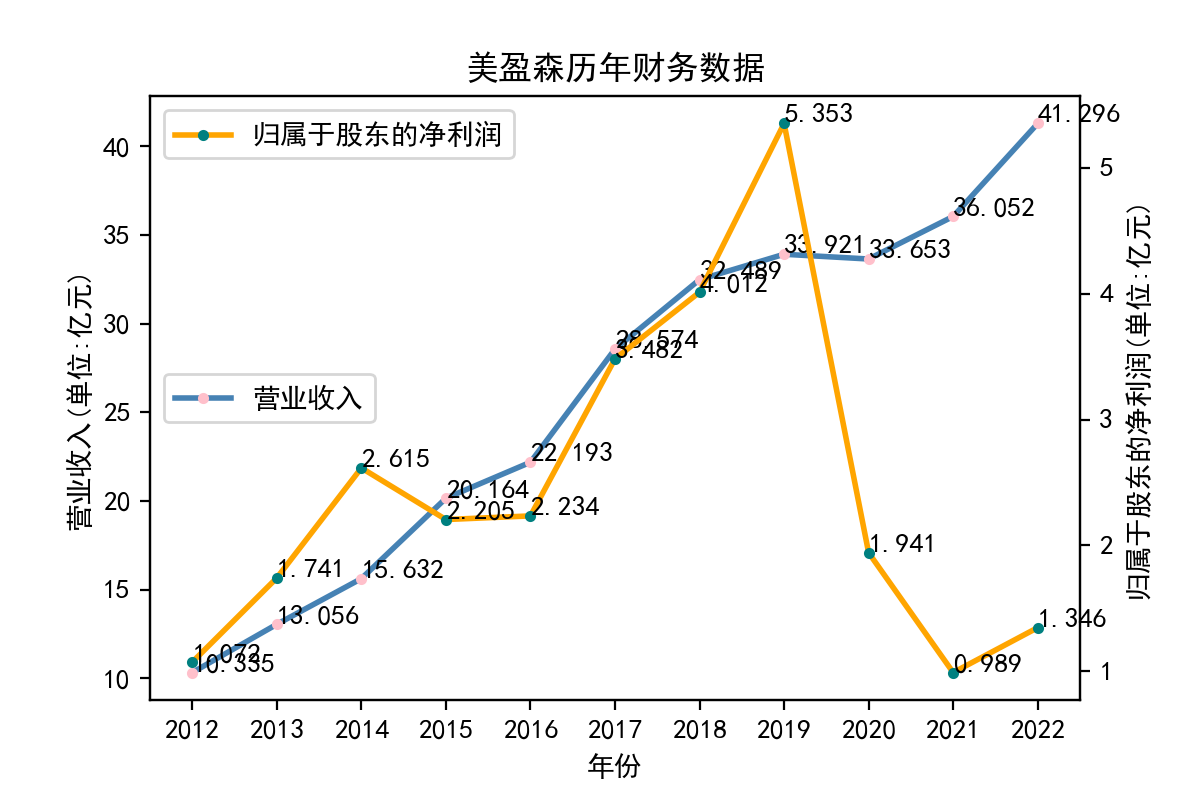
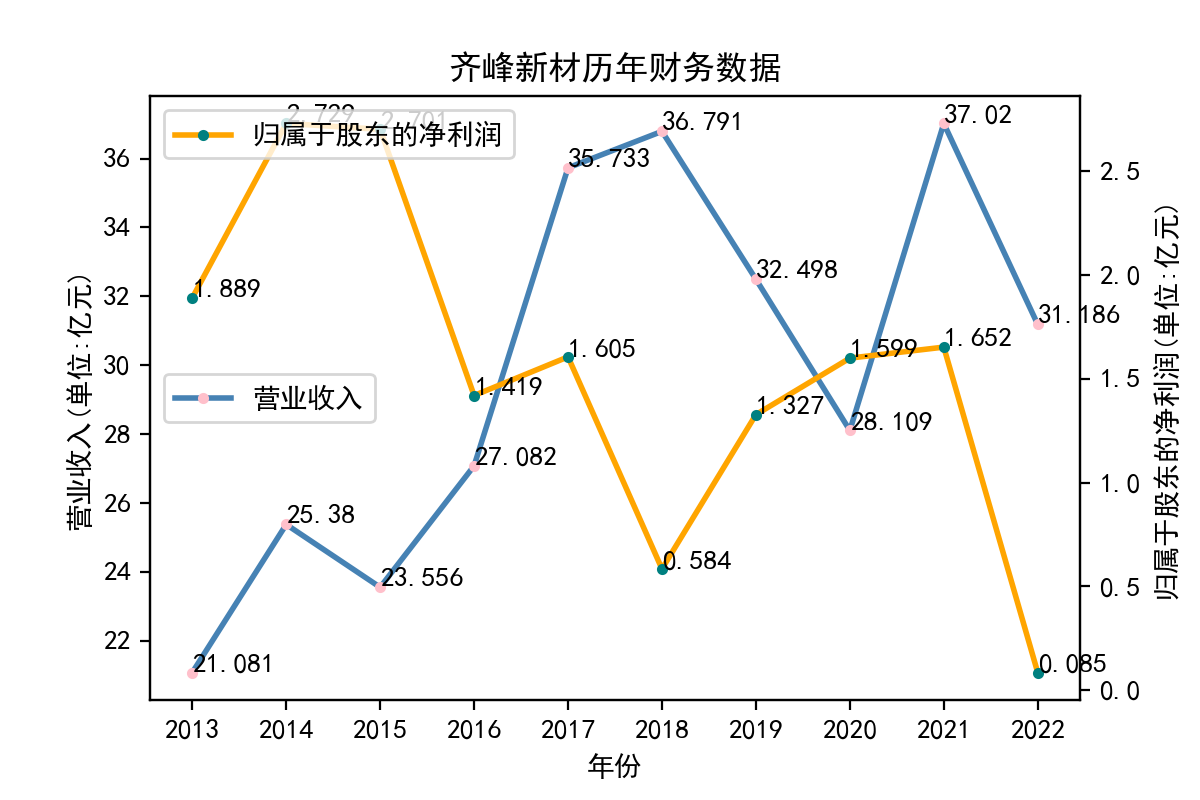
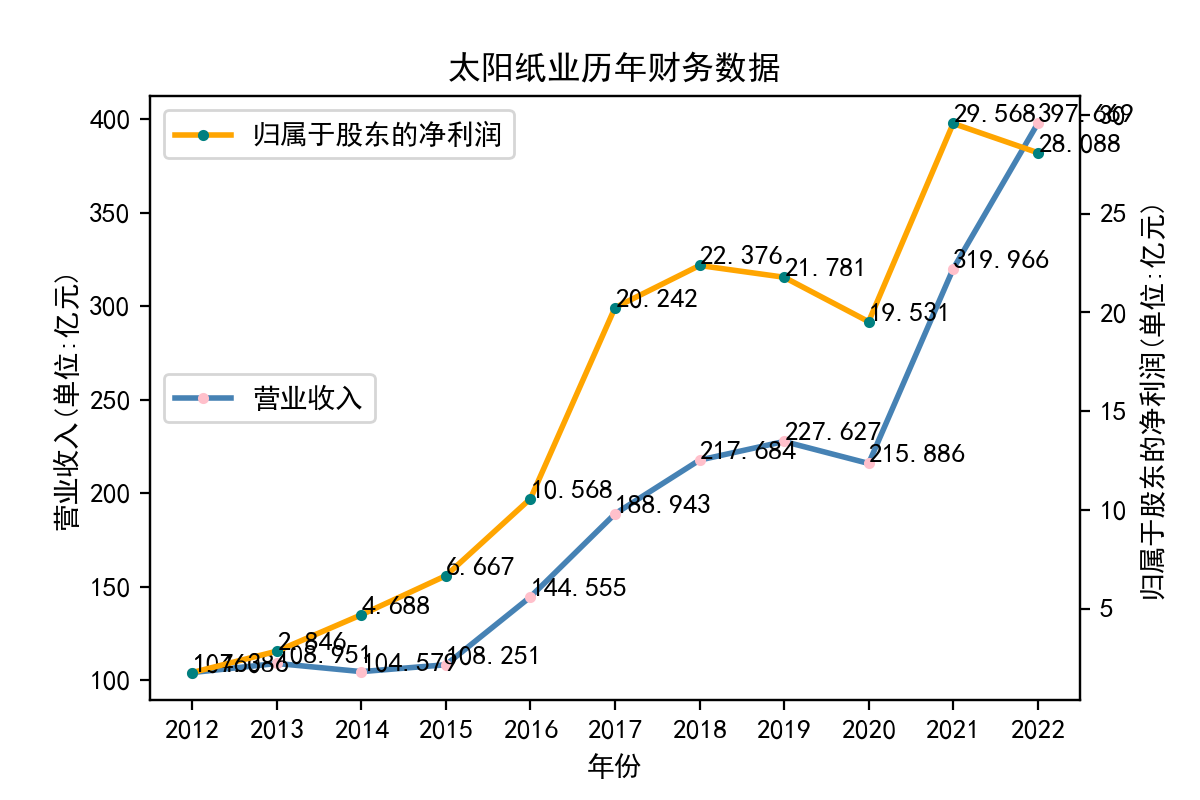

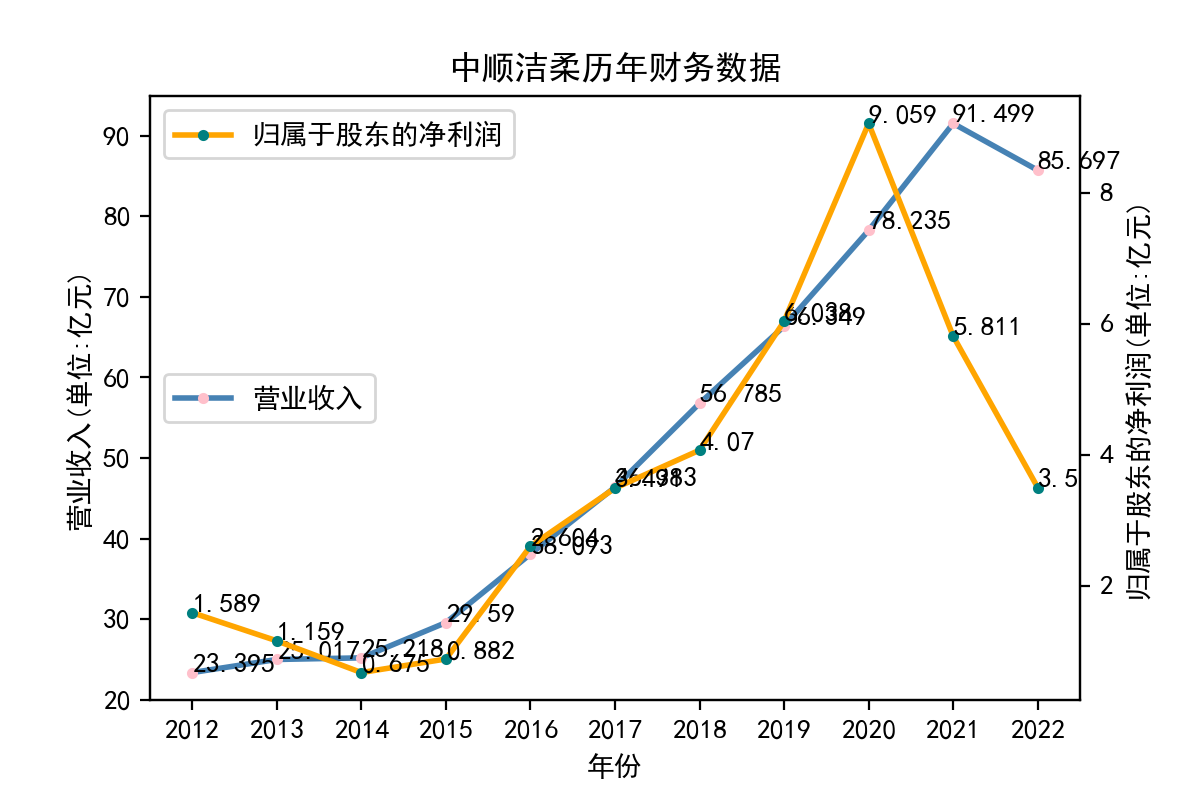
当使用Python进行文本处理时,正则表达式是一个非常有用的工具。Python提供了re模块,该模块可以让我们使用正则表达式来快速地处理文本。 在实验中,我学习了如何使用re模块编写正则表达式。re模块提供了很多函数来处理正则表达式,例如match、search、findall等。我们可以使用这些函数来匹配文本,找到我们需要的内容。 其次,我学习了正则表达式的语法。正则表达式是一种强大的工具,但其语法比较复杂。例如,使用特殊字符来匹配文本、使用字符集和范围、使用量词和分组等。在实验中,我通过不断的尝试和调试,对正则表达式的语法有了更深入的认识。 最后,我也学习了如何在Python中使用正则表达式来完成实际的文本处理任务。例如,我用正则表达式来提取邮件地址、公司网址、每股收益等。这些任务都可以使用正则表达式来完成。 总的来说,通过这个实验,我对Python正则表达式有了更深入的认识。我学习了使用re模块、正则表达式的语法以及如何在Python中使用正则表达式来处理文本。这些知识对我今后的学习和工作都非常有用。 我也意识到了自己实力的不足,学艺不精,在以后的学习中我会不断深入去理解这门课所学到的知识