按要求我应选取有色金属矿采业的后10家公司,但获取年报链接时发现部分公司不符合要求, 故将部分公司剔除向前递延,直至选出符合要求的公司如图所示:绿色标记的是可以通过上证交易所 下载近10年公告链接的公司;黄色标记的是需自行查询某一年年报链接的公司;蓝色标记的是需自行 查询某两年年报链接的公司。
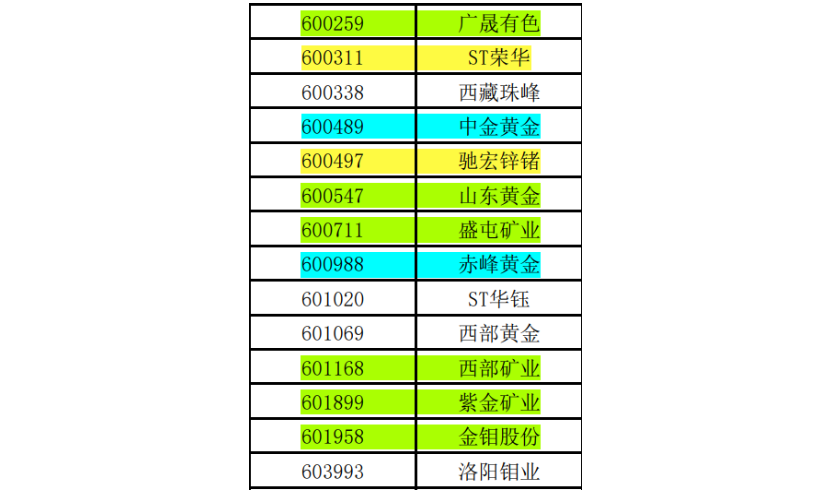
剔除原因如下:1.洛阳钼业:在上证交易所官网下载的公告链接中缺失2021和2022年的年报, 而其官网中只有2021年的季度报告,没有年报;2.西部黄金:在上证交易所官网下载的公告链接 中缺失2013年的年报,且无法查询到;3.ST华钰:在上证交易所官网下载的公告链接中缺失2013、 2014和2015年的年报,且无法查询到;4.西藏珠峰:同ST华钰。
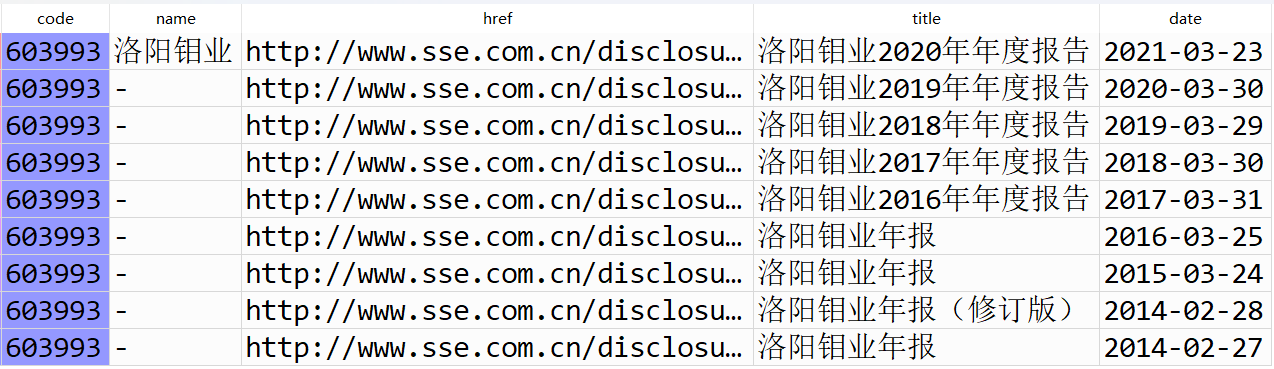

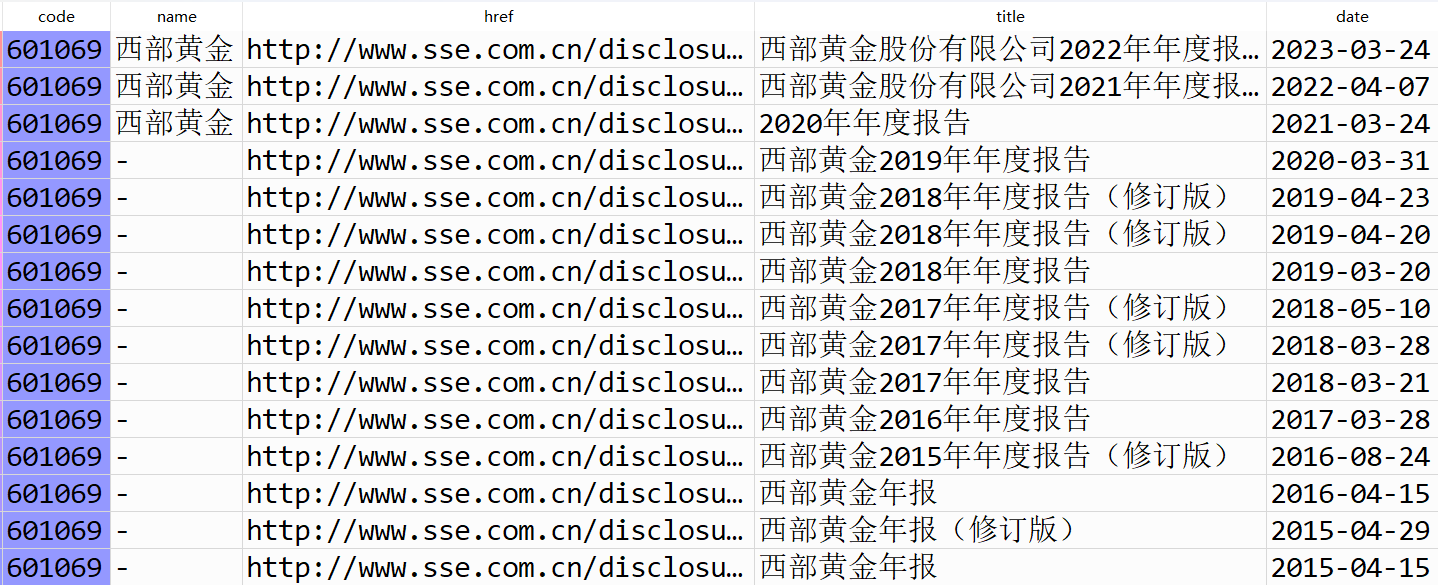
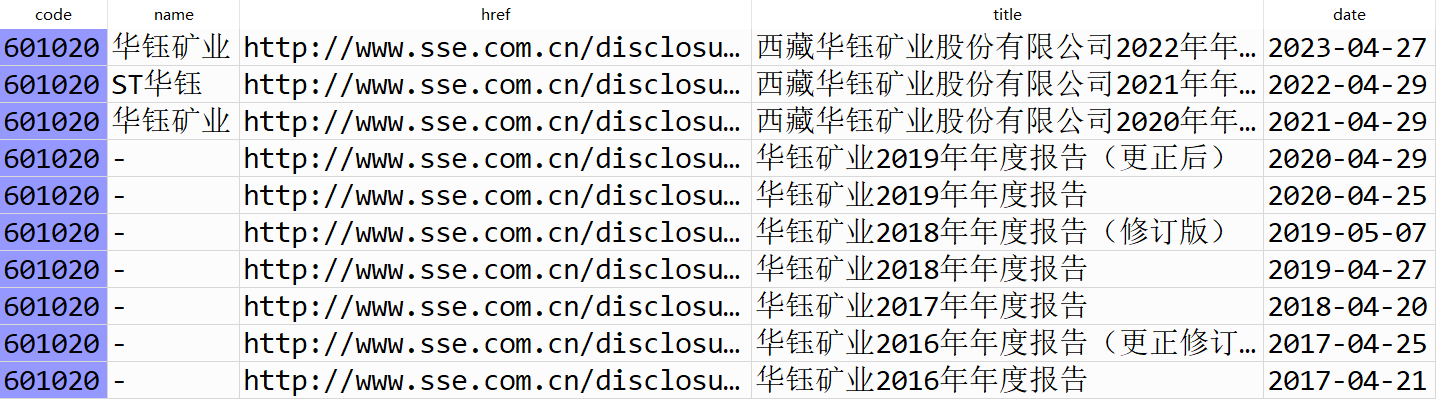
利用老师课堂上写的get_table_sse_codes函数获取10家公司的年报链接,再用parse_table_fnames 函数生成数据框,并用filter_nb_10y函数筛选出我们想要的链接,最后用download_pdfs函数下载年报。
利用老师课堂上写的parse_ar解析年报中财务指标的包,运用循环语句对所有年报进行解析, 并保存成csv文件。



一家公司只需要用一年的年报解析公司信息,我们均采用2022年的公司年报进行解析,为了 方便使用循环,我们对年报PDF进行重命名。
循环获取10家公司的股票代码、股票简称、公司网站、电子邮箱、办公地址的结果如下,并 保存为csv文件。


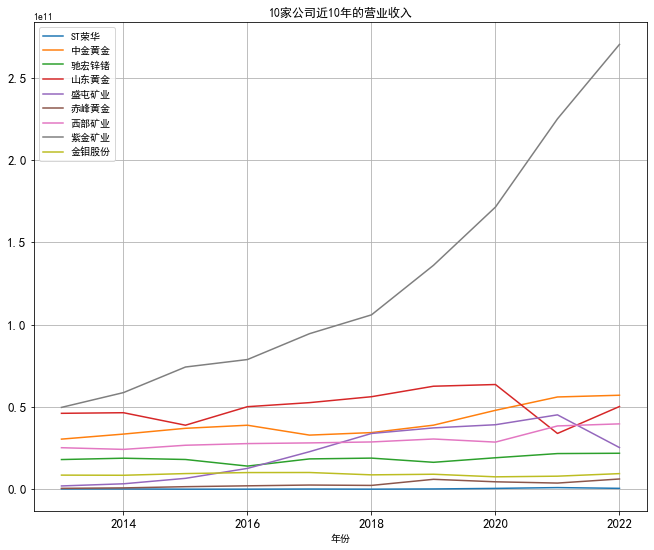
从图中可以看出紫金矿业的营业收入呈逐年上升趋势,山东黄金、盛屯矿业小幅波动,而 其余7家公司营业收入波动不大。
从图中可以看出紫金矿业的归属于上市公司股东的净利润呈逐年上升趋势,驰宏锌锗、西部 矿业、山东黄金小幅波动,其余6家公司归属于上市公司股东的净利润波动不大。
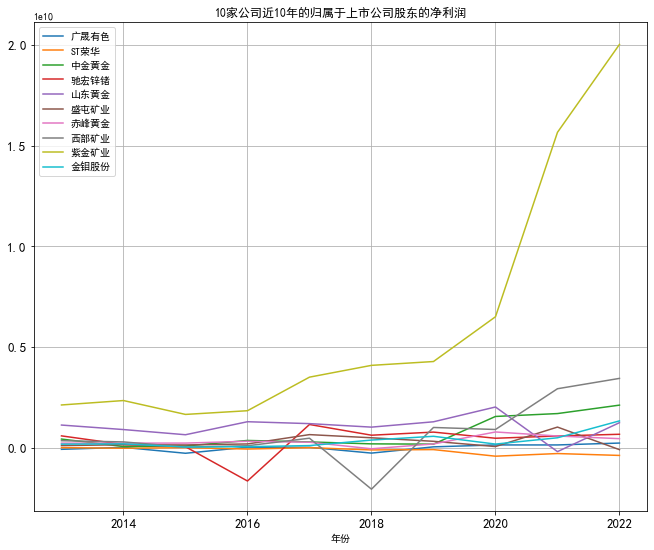
综上,紫金矿业的业绩逐年向好,其他公司业绩较为稳定。
from sse import get_table_sse_codes,parse_table_fnames
#获取10家公司的年报链接
codes=[600259,600311,600489,600497,600547,600711,600988,601168,601899,601958]
get_table_sse_codes(codes)
#生成10家公司的年报链接数据框
fnames=['600259.html','600311.html','600489.html','600497.html','600547.html',
'600711.html','600988.html','601168.html','601899.html','601958.html']
parse_table_fnames(fnames)
#
import pandas as pd
from filter_url import filter_nb_10y
#筛选年报链接
df=[]
def filter_nb(csvs):
for csv in csvs:
df.append(filter_nb_10y(pd.read_csv(csv)))
return(df)
csvs=['600259.csv','600311.csv','600489.csv','600497.csv','600547.csv',
'600711.csv','600988.csv','601168.csv','601899.csv','601958.csv']
filter_nb(csvs)
#下载年报
for i in range(10):
df[i]['索引']=range(10)
df[i].set_index('索引',inplace=True)
col = df[i].columns.tolist()
col.remove('Unnamed: 0')
df[i] = df[i][col]
df_new=df[:10]
href0=df_new[0]['href']
code0=codes[0]
years=['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
from download import download_pdfs
for i in range(10):
download_pdfs(df_new[i]['href'],codes[i],years)
import fitz
import pandas as pd
import re
from parse_ar import get_subtxt,get_th_span,get_bounds,get_keywords,parse_key_fin_data
import os
company=['广晟有色','荣华','中金黄金','驰宏锌锗','山东黄金','盛屯矿业','赤峰黄金','西部矿业','紫金矿业','金钼股份']
for i in company:
file_path = r'C:/Users/wwy/Documents/Python/nianbao/src/nianbao/'+i
#提取文件中的所有文件生成一个列表
folders = os.listdir(file_path)
for j in folders:
doc=fitz.open(file_path+'/'+j)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
data=parse_key_fin_data(subtxt, keywords)
print(data)
import PyPDF2
import re
# 读取PDF文件并解析信息
for i in range(1, 11):
# 读取PDF文件
pdf_file = open(f'C:/Users/wwy/Documents/Python/nianbao/src/nianbao/company_report_{i}.pdf', 'rb')
pdf_reader = PyPDF2.PdfReader(pdf_file)
# 解析PDF文本
text = ''
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text += page.extract_text()
'''
# 解析股票代码
pattern = re.compile('(?<=股票代码[::]\s*)[^\s,]+')
code = pattern.findall(text)[0]
print(f"第{i}家公司股票代码为:{code}")
# 解析股票简称
pattern = re.compile('(?<=股票简称[::]\s*)[\u4e00-\u9fa5]+')
name = pattern.findall(text)[0]
print(f"第{i}家公司股票简称为:{name}")
'''
# 解析公司网址
pattern = re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
url = pattern.findall(text)[0]
print(f"第{i}家公司公司网址为:{url}")
# 解析电子邮箱
pattern = re.compile('(?<=\n)\w*电子信箱?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
email = pattern.findall(text)[0]
print(f"第{i}家公司电子邮箱为:{email}")
# 解析办公地址
pattern = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
address = pattern.findall(text)[0]
print(f"第{i}家公司办公地址为:{address}")
# 关闭文件
pdf_file.close()
import matplotlib.pyplot as plt #导入子模块pyplot并且缩写为plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] #以仿宋的字体显示中文
#解决保存图像是负号'-'显示为方块的问题
mpl.rcParams['axes.unicode_minus'] = False
import numpy as np
import pandas as pd
data_return=pd.read_excel('C:/Users/wwy/Nutstore/1/我的坚果云/大三下/金融数据获取与处理/大作业/营业收入.xlsx',sheet_name='Sheet1',header=0,index_col=0)
data_return.plot(kind='line',figsize=(11,9),title=u"10家公司近10年的营业收入",grid=True,fontsize=13)
data_profit=pd.read_excel('C:/Users/wwy/Nutstore/1/我的坚果云/大三下/金融数据获取与处理/大作业/归属于上市公司股东的净利润.xlsx',sheet_name='Sheet1',header=0,index_col=0)
data_profit.plot(kind='line',figsize=(11,9),title=u"10家公司近10年的归属于上市公司股东的净利润",grid=True,fontsize=13)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import re
import pandas as pd
def get_table_sse(code): #√获取一家公司的年报链接
'''
Get HTML source of 年报链接
:param code: 证券代码,上交所上市公司
:type string: str
:return: None
:rtype: None
'''
browser = webdriver.Edge()
url='http://www.sse.com.cn/disclosure/listedinfo/regular/'
browser.get(url)
browser.set_window_size(1550, 830)
time.sleep(3)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code) #'601919'
time.sleep(3)
selector='.sse_outerItem:nth-child(4) .filter-option-inner-inner'
browser.find_element(By.CSS_SELECTOR,selector).click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(3)
#
selector = "body > div.container.sse_content > div > "
selector += "div.col-lg-9.col-xxl-10 > div > "
selector += "div.sse_colContent.js_regular > "
selector += "div.table-responsive > table"
#
element = browser.find_element(By.CSS_SELECTOR,selector)
table_html = element.get_attribute('innerHTML')
#
fname=f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
#
browser.quit()
def get_data(tr): #√为parse_table()内的内置函数
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_table(fname,save=True): #√生成一家公司的年报链接数据框
f=open(fname,encoding='utf-8')
html=f.read()
f.close()
#
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
#
if save:
df.to_csv(f'{fname[0:-5]}.csv')
return(df)
def get_table_sse_codes(codes):
for code in codes:
get_table_sse(code)
def parse_table_fnames(fnames):
for fname in fnames:
parse_table(fname)
'''
筛选过滤掉一些不必要的公告链接
to be finished
'''
import datetime
def filter_links(words,df,include=True): #√筛选年报链接的名称
'''
筛选保留年报链接
:param words:保留或剔除包含关键字词列表
:param df:DataFrame
:param include:keep or exclude
:return:a dataframe
:rtype:DataFrame
'''
ls=[]
for word in words:
if include:
#ls.append([word in f for f in df.f_name])
ls.append([word in f for f in df['title']])
else:
#ls.append([word not in f for f in df.f_name])
ls.append([word not in f for f in df['title']])
index=[]
for r in range(len(df)):
flag=not include
for c in range(len(words)):
if include:
flag=flag or ls[c][r]
else:
flag=flag and ls[c][r]
index.append(flag)
df2=df[index]
return(df2)
def filter_date(start,end,df): #√筛选年报链接的时间
date=df['date']
v=[d>=start and d<=end for d in date]
df_new=df[v]
return(df_new)
def start_end_10y(): #为filter_nb_10y()的内置函数
dt_now=datetime.datetime.now()
current_year=dt_now.year
start=f'{current_year-9}-01-01'
end=f'{current_year}-12-31'
return((start,end))
'''---------------------------------------------------------'''
def filter_nb_10y(df,keep_words=['年报','年度报告'],exclude_words=['摘要'],start=''): #√集合筛选年报链接的名称和时间
if start =='':
start,end=start_end_10y()
else:
start_y=int(start[0:4])
end=f'{start_y+9}-12-31'
#
df=filter_links(keep_words,df,include=True)
df=filter_links(exclude_words,df,include=False)
df=filter_date(start,end,df)
return df
'''
def prepare_herefs_years(df):
hrefs=df['href'].to_list()
years=[int(d[:4])-1 for d in df['date']]
return((hrefs,years))
'''
import requests
import time
def download_pdf(href,code,year): #下载一家公司某一年的年报
'''
下载单份年报,自动命名保持
:param href:download link address
:type string:str
:param code:证券代码。
:type string:str
:param code:年报年份。
:type string:str
:return:None
:rtype:None
'''
r=requests.get(href,allow_redirects=True)
fname=f'{code}_{year}.pdf'
f=open(fname,'wb')
f.write(r.content)
f.close()
#
r.close()
def download_pdfs(hrefs,code,years): #下载一家公司几年间的年报
for i in range(len(hrefs)):
href=hrefs[i]
year=years[i]
download_pdf(href, code, year)
time.sleep(30)
return()
def download_pdfs_codes(list_hrefs,codes,list_years): #下载几家公司几年间的年报
for i in range(len(list_hrefs)):
hrefs=list_hrefs[i]
years=list_years[i]
code=codes[i]
download_pdfs(hrefs,code,years)
return()
'''
解析年报
to be finished!
'''
import fitz
import pandas as pd
import re
filename='C:/Users/wwy/Documents/Python/nianbao/src/nianbao/002352_2022.PDF'
doc=fitz.open(filename)
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')): #√找到财务指标页码
#默认设置为首尾页码
start_pageno=0
end_pageno=len(doc)-1
#
lb,ub=bounds #元组可以拆,lb:lower bound(下界);ub:upper bound(上界)
#获取左界页码
for n in range(len(doc)):
page=doc[n];txt=page.get_text()
if lb in txt:
start_pageno=n;break #一旦找到首个n,跳出for循环
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno=n;break
#获取小范围内字符串
txt=''
for n in range(start_pageno,end_pageno+1):
page=doc[n]
txt+=page.get_text()
return(txt)
def get_th_span(txt): #获取财务指标表头,年份
nianfen='(20\d\d|199\d)\s*年末?' #|199\d 结尾有无问号
s=f'{nianfen}\s*{nianfen}.*?{nianfen}'
p=re.compile(s,re.DOTALL) #|或 \s空格 *有可能有或没有 re.DOTALL遇到换行符也行
matchobj=p.search(txt)
#
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2)==1) and (int(year2)-int(year3)==1)
#
while(not flag):
matchobj=p.search(txt[end:])
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=(int(year1)-int(year2)==1)
flag=flag and (int(year2)-int(year3)==1)
#
return(matchobj.span())
def get_bounds(txt):
th_span_1st=get_th_span(txt)
end=th_span_1st[1]
th_span_2nd=get_th_span(txt[end:])
th_span_2nd=(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]
#
while(txt[e] not in '0123456789'):
e=e-1
return(s,e)
def get_keywords(txt):
p=re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords=p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext,keywords):
#kws=['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss=[]
s=0
for kw in keywords:
n=subtext.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtext))
data=[]
#
p=re.compile('\D+(?:\s+\D*)?(?: (.*) |\(.*\))?')
p2=re.compile('\s')
for n in range(len(ss)-1):
s=ss[n]
e=ss[n+1]
line=subtext[s:e]
#获取可能换行的账户名称
matchobj=p.search(line)
account_name=p2.sub('',matchobj.group())
#获取三年数据
amnts=line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return(data)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
data=parse_key_fin_data(subtxt, keywords)
'''
def get_account_data(account,txt):
p_txt='%s\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)'%account
p=re.compile(p_txt)
matchobj=p.search(txt)
amt=matchobj.group(1)
return(amt)
yysr=get_account_data('营业收入',txt)
gbjlr=get_account_data('归属于上市公司股东的净利润',txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
'''
'''
s=txt.find('主要会计数据和财务指标')
e=txt.find('注 :')
subtext=txt[s:e]
data=parse_key_fin_data(subtext)
colnames=['指标','2022年','2021年','本年比上年变动','2020年']
df=pd.DataFrame(data,columns=colnames)
df.to_csv('SF2022.csv')
'''