卢欣鸿的实验报告
卢欣鸿的实验报告
结果
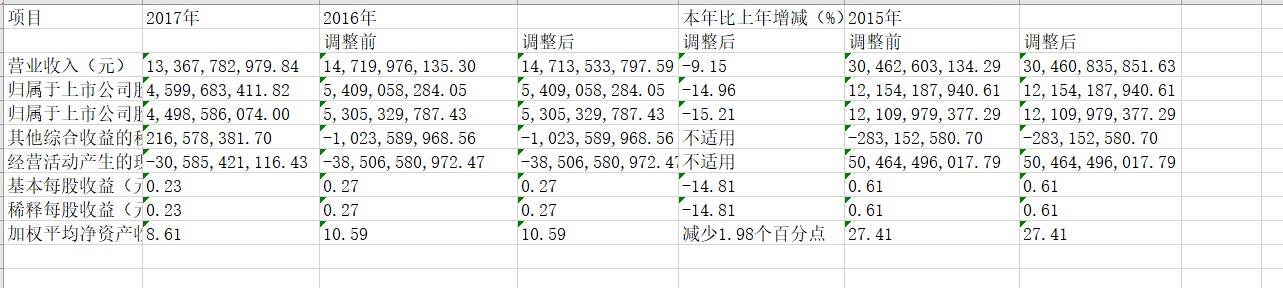
获取的数据截图


代码
import requests,json,os,time,re
def read_l(txt):
line_l = [line.strip() for line in open(txt, encoding='UTF-8').readlines()]
return line_l
def downloadpdf(pdf_url, filename):
pdf = requests.get(pdf_url)
with open(filename, 'wb') as f:
f.write(pdf.content)
def find_text(text,l):
for i in l:
if i in text:
r = True
break
else:
r = False
return r
def rename(file_name,firm_id):
global pattern,s_l
year = re.findall(pattern,file_name)[0]
for s in s_l:
if s in file_name:
season = str(s_l.index(s)+1)
break
else:
pass
new_name = f'{firm_id}_{year}_{season}.pdf'
return new_name
pattern = '[0-9]{4}'
s_l = ['第一季度','半年度','第三季度','年年度']
txt = r'D:\金融数据获取与处理\company1.txt'
firm_ids = read_l(txt)
date = ["2010-12-31", "2023-5-29"]
path = r'D:\金融数据获取与处理\abcd'
l = ['摘要','取消','正文']
#url
url = 'http://www.szse.cn/api/disc/announcement/annList?random=0.8015180112682705'
headers = {'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Connection':'keep-alive',
'Content-Length':'92',
'Content-Type':'application/json',
'DNT':'1',
'Host':'www.szse.cn',
'Origin':'http://www.szse.cn',
'Referer':'http://www.szse.cn/disclosure/listed/fixed/index.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Request-Type':'ajax',
'X-Requested-With':'XMLHttpRequest'}
#payload,获取源代码
for firm_id in firm_ids:
dirname = path+f'{firm_id}'
os.mkdir(dirname)
for page in range(1,5):
try:
payload = {'seDate': date,
'stock': ["{firm_id}".format(firm_id=firm_id)],
'channelCode': ["fixed_disc"],
'pageSize': 30,
'pageNum': '{page}'.format(page=page)}
response = requests.post(url, headers=headers, data=json.dumps(payload))
doc = response.json()
if response.status_code==200:
print('获取{0}的第{1}页源代码成功'.format(firm_id,page))
datas = doc.get('data')
for i in range(len(datas)):
data = datas[i]
pdf_url = 'http://disc.static.szse.cn/download'+data.get('attachPath')
title = data.get('title')
publish_time = data.get('publishTime')[:9]
filename = rename(title,firm_id)
if find_text(title,l):
continue
else:
downloadpdf(pdf_url, dirname+'/'+filename)
print(f'开始下载{filename}')
time.sleep(2)
except:
print('{0}的第{1}页不存在'.format(firm_id,page))
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\金融数据获取与处理\abcd'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("2017_4.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
file_list = ['D:\\金融数据获取与处理\\abcd\\abcd000166\\000166_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000617\\000617_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000666\\000666_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000686\\000686_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000712\\000712_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000728\\000728_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000750\\000750_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd002670\\002670_2017_4.pdf']
import pandas as pd
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables() # 提取多个表格
pd.set_option('display.max_columns', None) # 把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1, df2])
df3.to_csv(filename+'info.csv')
import pdfplumber
import pandas as pd
from openpyxl import Workbook #保存表格,需要安装openpyxl
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\金融数据获取与处理\abcd'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("2017_4.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
file_list = ['D:\\金融数据获取与处理\\abcd\\abcd000166\\000166_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000617\\000617_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000666\\000666_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000686\\000686_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000712\\000712_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd000728\\000728_2017_4.pdf',
'D:\\金融数据获取与处理\\abcd\\abcd000750\\000750_2017_4.pdf', 'D:\\金融数据获取与处理\\abcd\\abcd002670\\002670_2017_4.pdf',]
import pandas as pd
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[8] # 指定提取第几页
table = page01.extract_table()
workbook = Workbook()
sheet = workbook.active
for row in table:
sheet.append(row)
print(type(workbook))
workbook.save(filename="D:\\金融数据获取与处理\\abcd\\abcd000166.xlsx")
def xlsx_to_csv_pd():
data_xls = pd.read_excel('D:\\金融数据获取与处理\\abcd\\abcd000166.xlsx', index_col=0)
data_xls.to_csv('000166.csv', encoding='utf-8')
xlsx_to_csv_pd()
data = pd.read_csv('000166.csv')
print(data)
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
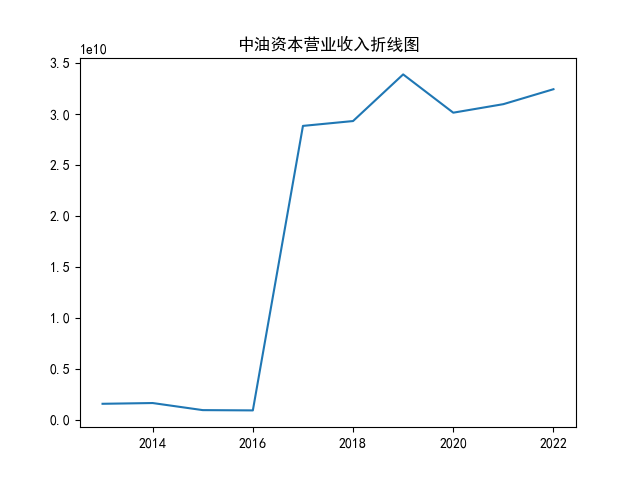
x = range(2013,2023)
y1=[1550635405.88,1624727209.92,929518743.99,901787760.47,28830386089.04,29306189171.45,33885599825.37,30127421045.60,30963931672.48,32431443205.38]
#对其营业收入做折线图
plt.plot(x,y1)
plt.title("中油资本营业收入折线图")
plt.show()
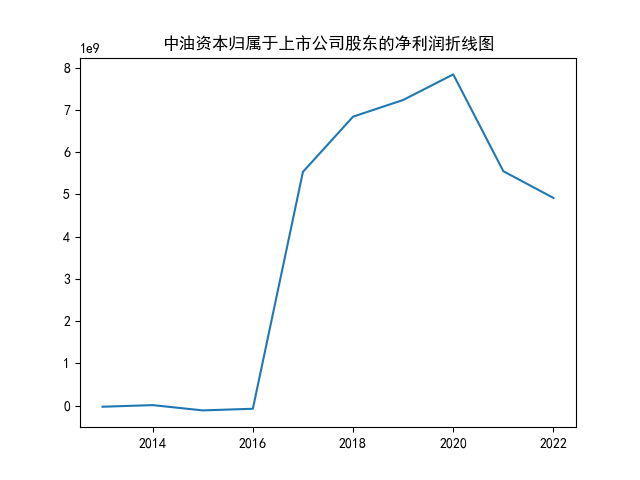
#对归属于上市公司股东的净利润(元)做折线图
y2 = [-28342658.05,9844601.90,-115180623.91,-76181117.94,5535421902.28,6842540372.67,7237830948.22,7843863454.16,5550119961.32,4917991589.44]
plt.plot(x,y2)
plt.title("中油资本归属于上市公司股东的净利润折线图")
plt.show()
#绘制十家公司十年的营业收入曲线
x = range(2013,2023)
data = pd.read_excel(r"D:\\金融数据获取与处理\\abcd\\ten_company_income.xlsx")
print(data)
data = data.T
data = data.rename(columns={0:"申万宏源",1:"中油资本",2:"经纬纺机",3:"东北证券 ",4:"锦龙股份",5:"国元证券",6:"国海证券",7:"国盛金控",8:"西部证券",9:"国信证券"})
data.plot()
plt.title("资本市场服务业营业收入对比折线图")
plt.show()