由加琦的实验报告
要求一:爬取10支股票的年报下载链接等信息
分配到的10家上市公司

运行结果截图

要求二:获取公司资料里的相关信息
运行结果截图
提取公司基本信息及董事会秘书联系方式

提取会计账单和财务信息到csv
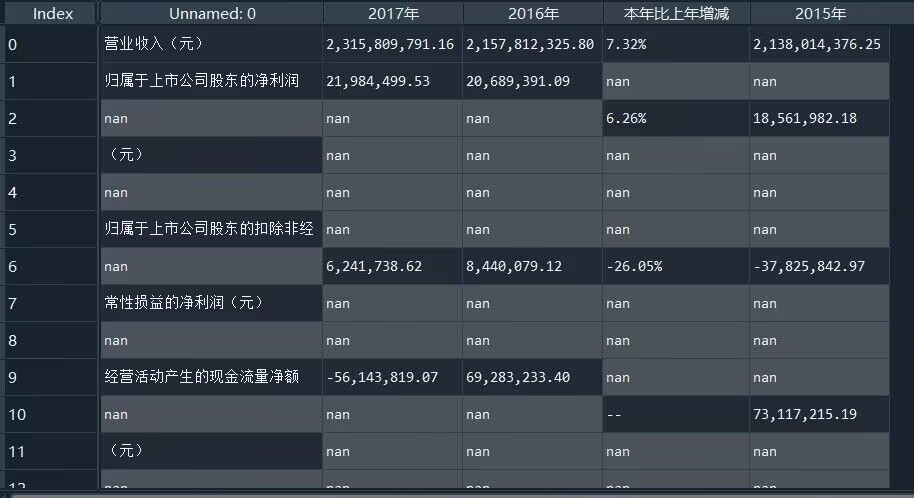
要求三:对国华网安进行数据可视化
营业收入折线图
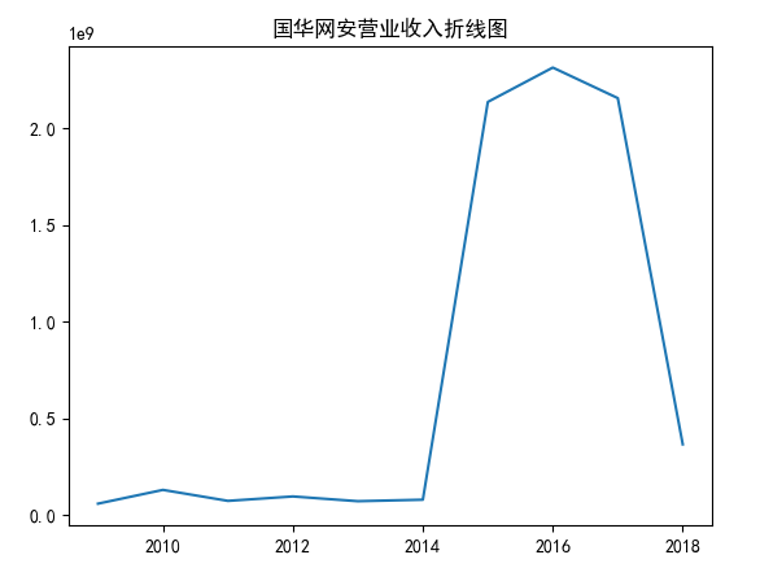
归属于上市公司股东的净资产(元)折线图
结果分析
由上方两张图可以看出,国华网安在上市的10年中,营业收入和归属于上市公司股东的净利润随时间整体呈先平缓再上升而后下降的趋势。
学习总结
通过使用Anaconda进行上市公司近十年年报爬取,结合pdfplumber进行数据提取,并利用Matplotlib进行数据可视化,受益匪浅。
代码实现
import requests,json,os,time,re
def read_l(txt):
line_l = [line.strip() for line in open(txt, encoding='UTF-8').readlines()]
return line_l
def downloadpdf(pdf_url, filename):
pdf = requests.get(pdf_url)
with open(filename, 'wb') as f:
f.write(pdf.content)
def find_text(text,l):
for i in l:
if i in text:
r = True
break
else:
r = False
return r
def rename(file_name,firm_id):
global pattern,s_l
year = re.findall(pattern,file_name)[0]
for s in s_l:
if s in file_name:
season = str(s_l.index(s)+1)
break
else:
pass
new_name = f'{firm_id}_{year}_{season}.pdf'
return new_name
pattern = '[0-9]{4}'
s_l = ['第一季度','半年度','第三季度','年年度']
txt = r'D:\金融数据获取与处理\company.txt'
firm_ids = read_l(txt)
date = ["2010-12-31", "2023-5-29"]
path = r'D:\金融数据获取与处理\nMteal'
l = ['摘要','取消','正文']
#url
url = 'http://www.szse.cn/api/disc/announcement/annList?random=0.8015180112682705'
headers = {'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Connection':'keep-alive',
'Content-Length':'92',
'Content-Type':'application/json',
'DNT':'1',
'Host':'www.szse.cn',
'Origin':'http://www.szse.cn',
'Referer':'http://www.szse.cn/disclosure/listed/fixed/index.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Request-Type':'ajax',
'X-Requested-With':'XMLHttpRequest'}
#payload,获取源代码
for firm_id in firm_ids:
dirname = path+f'{firm_id}'
os.mkdir(dirname)
for page in range(1,5):
try:
payload = {'seDate': date,
'stock': ["{firm_id}".format(firm_id=firm_id)],
'channelCode': ["fixed_disc"],
'pageSize': 30,
'pageNum': '{page}'.format(page=page)}
response = requests.post(url, headers=headers, data=json.dumps(payload))
doc = response.json()
if response.status_code==200:
print('获取{0}的第{1}页源代码成功'.format(firm_id,page))
datas = doc.get('data')
for i in range(len(datas)):
data = datas[i]
pdf_url = 'http://disc.static.szse.cn/download'+data.get('attachPath')
title = data.get('title')
publish_time = data.get('publishTime')[:9]
filename = rename(title,firm_id)
if find_text(title,l):
continue
else:
downloadpdf(pdf_url, dirname+'/'+filename)
print(f'开始下载{filename}')
time.sleep(2)
except:
print('{0}的第{1}页不存在'.format(firm_id,page))
pass
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\金融数据获取与处理\nMteal'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("2017_4.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
file_list = ['D:\\金融数据获取与处理\\nMteal\\nMteal000004\\000004_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000158\\000158_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000409\\000409_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000555\\000555_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000638\\000638_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000682\\000682_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000889\\000889_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000948\\000948_2017_4.pdf',]
import pandas as pd
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables() # 提取多个表格
pd.set_option('display.max_columns', None) # 把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1, df2])
df3.to_csv(filename+'info.csv')
import pdfplumber
import pandas as pd
from openpyxl import Workbook #保存表格,需要安装openpyxl
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\金融数据获取与处理\nMteal'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("2017_4.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
file_list = ['D:\\金融数据获取与处理\\nMteal\\nMteal000004\\000004_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000158\\000158_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000409\\000409_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000555\\000555_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000638\\000638_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000682\\000682_2017_4.pdf',
'D:\\金融数据获取与处理\\nMteal\\nMteal000889\\000889_2017_4.pdf', 'D:\\金融数据获取与处理\\nMteal\\nMteal000948\\000948_2017_4.pdf',]
import pandas as pd
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[5] # 指定提取第几页
table = page01.extract_table()
workbook = Workbook()
sheet = workbook.active
for row in table:
sheet.append(row)
print(type(workbook))
workbook.save(filename="D:\\金融数据获取与处理\\nMteal\\nMteal000004.xlsx")
def xlsx_to_csv_pd():
data_xls = pd.read_excel('D:\\金融数据获取与处理\\nMteal\\nMteal000004.xlsx', index_col=0)
data_xls.to_csv('000004.csv', encoding='utf-8')
xlsx_to_csv_pd()
data = pd.read_csv('000004.csv')
print(data)
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
x = range(2009,2019)
y1=[60080600.35,131331494.69,74503718.53,97363301.61,72784567.16,80608820.00,2138014376.25,2315809791.16,2157812325.80,366868804.70]
#对其营业收入做折线图
plt.plot(x,y1)
plt.title("国华网安营业收入折线图")
plt.show()
#对归属于上市公司股东的净利润(元)做折线图
y2 = [8463829.57,11624092.32,2989891.05,2005254.96,-1033376.96,3801373.74,1247118.29,39299310.06,8566720.65,-20270783.78]
plt.plot(x,y2)
plt.title("国华网安归属于上市公司股东的净利润折线图")
plt.show()
#绘制十家公司十年的营业收入曲线
x = range(2009,2019)
data = pd.read_excel(r"D:\\金融数据获取与处理\\nMteal\\ten_company_income.xlsx")
print(data)
data = data.T
data = data.rename(columns={0:"国华网安",1:"常山北明",2:"云鼎科技",3:"神州信息 ",4:"*ST万方",5:"东方电子",6:"中嘉博创",7:"南天信息",8:"ST高升",9:"新大陆"})
data.plot()
plt.title("软件与信息技术服务业营业收入对比折线图")
plt.show()