STEP2:下载行业公司的近十年年报
STEP3:获取十家公司指定基本信息,保存为excel文件
STEP4:选取一家公司画出近十年营业收入和归属于上市公司净利润时间序列图
STEP5:画出十家公司营业收入时间序列图

STEP1:获取所需下载股票的url,保存为excel文件
import fitz
#########获取要下载的年报代码
import fitz
import pdfplumber
import pandas as pd
import numpy as np
n=[72,73,74]
dff=pd.DataFrame()
with pdfplumber.open('D:/Python程序/金融数据获取与处理/期末大作业/行业分类顺序.PDF') as pdf:
for i in n:
page=pdf.pages[i]
table=page.extract_tables()
for t in table:
df =pd.DataFrame(t[1:],columns=t[0])
dff=pd.concat([dff,df],ignore_index=True)
code_firm=pd.concat([dff.iloc[9:42,3:],dff.iloc[42:84,3:],dff.iloc[84:90,3:]]
,ignore_index=True)
code_firm.columns=['code','firm']
#########获取单个公司年报url(上交所)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support.expected_conditions import title_contains
from selenium.webdriver.common.keys import Keys
import time
def get_firm_url_SH(firm_code):
driver = webdriver.Edge()
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
time.sleep(3)
#选取代码
driver.find_element(By.XPATH,'//*[@id="inputCode"]').send_keys(firm_code)
time.sleep(2)
driver.find_element(By.XPATH,'/html/body/div[8]/div/div[1]/div/div[5]/div[2]/input').click()
#年份退回至2014年
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[1]').click()
time.sleep(0.5)
#月份退回至1月
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[2]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[2]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[2]').click()
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[1]/i[2]').click()
#日期点击1日
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[1]/div[2]/table/tbody/tr[1]/td[3]').click()
#点击确定
driver.find_element(By.XPATH,'//*[@id="layui-laydate1"]/div[3]/div/span').click()
time.sleep(3)
driver.find_element(By.XPATH,'//*[@id="exampleModal"]').click()
#类型选取年报
time.sleep(1)
driver.find_element(By.XPATH,'/html/body/div[8]/div/div[1]/div/div[4]/div[2]/div/button').click()
driver.find_element(By.XPATH,'/html/body/div[8]/div/div[1]/div/div[4]/div[2]/div/div/div/ul/li[2]/a').click()
time.sleep(3)
#获取当前年报的代码、公司名称、年报名称与年报url
c_e=driver.find_element(By.XPATH,'/html/body/div[8]/div/div[2]/div/div[1]/div[1]/table/tbody/tr[1]/td[1]')
f_e=driver.find_element(By.XPATH,'/html/body/div[8]/div/div[2]/div/div[1]/div[1]/table/tbody/tr[1]/td[2]')
n_es=driver.find_elements(By.CLASS_NAME,'table_titlewrap')
yearss=driver.find_elements(By.CLASS_NAME,'text-nowrap')
time.sleep(3)
code=c_e.text
firm=f_e.text
names=[]
for n_e in n_es:
name=n_e.text
names.append(name)
year_ns=[]
for y in yearss:
year_n=y.text
year_ns.append(year_n)
years=[]
for y in year_ns:
y=y[0:10]
year=time.strptime(y,"%Y-%m-%d")
years.append(year.tm_year-1)
pdfs=driver.find_elements(By.CLASS_NAME,'table_titlewrap')
time.sleep(2)
urlss=[]
for pdf in pdfs:
url_single=pdf.get_attribute('href')
urlss.append(url_single)
urls=pd.DataFrame({'code':[code]*len(pdfs),
'firm':[firm]*len(pdfs),
'url':urlss,
'name':names,
'year':years})
return(urls)
#########获取单个公司年报url(深交所)
def get_firm_url_SZ(firm_code):
driver = webdriver.Edge()
driver.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(4)
#选取代码
driver.find_element(By.XPATH,'//*[@id="input_code"]').send_keys(firm_code)
time.sleep(1)
driver.find_element(By.XPATH,'//*[@id="input_code"]').send_keys(Keys.ENTER)
time.sleep(1)
#选取公告类型
driver.find_element(By.XPATH,'//*[@id="select_gonggao"]/div/div/a/span[1]').click()
driver.find_element(By.XPATH,'//*[@id="c-selectex-menus-3"]/li[1]/a').click()
time.sleep(1)
#输入日期
driver.find_element(By.XPATH,'//*[@id="query"]/div[1]/div[5]/div/div/input[1]').send_keys('2014-01-01')
driver.find_element(By.XPATH,'//*[@id="query"]/div[1]/div[5]/div/div/input[2]').send_keys('2023-06-01')
time.sleep(1)
driver.find_element(By.XPATH,'/html/body/div[5]/div/div[2]/div/div[1]/h4').click()
#点击查询
driver.find_element(By.XPATH,'//*[@id="query-btn"]').click()
time.sleep(2)
#获取当前页面所有待下载年报新页面的链接
elements=driver.find_elements(By.CLASS_NAME,"annon-title-link")
links=[]
for element in elements:
link=element.get_attribute('href')
links.append(link)
#获取当前年报的代码、公司名称、年报名称、年份
c_e=driver.find_element(By.XPATH,'//*[@id="disclosure-table"]/div/div[1]/div/table/tbody/tr[1]/td[1]/a')
f_e=driver.find_element(By.XPATH,'//*[@id="disclosure-table"]/div/div[1]/div/table/tbody/tr[1]/td[2]/a')
n_es=driver.find_elements(By.CLASS_NAME,'text-title-box')
yearss=driver.find_elements(By.CLASS_NAME,'text-time')
code=c_e.text
firm=f_e.get_attribute('title')
names=[]
for n_e in n_es:
name=n_e.text
names.append(name)
year_ns=[]
for y in yearss:
year_n=y.text
year_ns.append(year_n)
years=[]
for y in year_ns:
y=y[0:10]
year = time.strptime(y,"%Y-%m-%d")
years.append(year.tm_year-1)
driver.close()
#循环进入链接获取年报url
urls=pd.DataFrame(data=None,columns=['code','firm','url','name','year'])
for link in links:
driver = webdriver.Edge()
driver.get(link)
time.sleep(4)
pdf=driver.find_element(By.XPATH,'//*[@id="annouceDownloadBtn"]')
time.sleep(2)
urls.loc[len(urls.index)] = [code,firm,pdf.get_attribute('href'),
names[links.index(link)],years[links.index(link)]]
driver.close()
time.sleep(1)
return(urls)
######过滤不符要求的年报url
def filter_words(words,df,include=True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df['name']])
else:
ls.append([word not in f for f in df['name']])
index=[]
for r in range(len(df)):
flag=not include
for c in range(len(words)):
if include:
flag=flag or ls[c][r]
else:
flag=flag and ls[c][r]
index.append(flag)
df2=df[index]
return(df2)
#########整理年报
def sort_firm_url(urls):
urls=filter_words(words=['年报','年度报告','更新后'], df=urls)
urls=filter_words(words=['摘要','已取消','更新前','督导'], df=urls,include=False)
return(urls)
#########获取要下载的年报url
url_all=pd.DataFrame()
for code in code_firm['code'][74:]:
if code in list(i for i in code_firm['code'][0:32]):
urls=get_firm_url_SZ(code)
url_all=pd.concat([url_all,urls],ignore_index=True)
else:
urls=get_firm_url_SH(code)
url_all=pd.concat([url_all,urls],ignore_index=True)
#########整理所有的url并存入excel
url_all=sort_firm_url(url_all)
url_all.index=[i for i in range(0,743)]
#去除年报名称中的换行符、特殊字符和公司名称中的特殊字符
for i in range(0,743):
if '\n' in list(str(url_all['name'][i])) :
newname=str(url_all['name'][i]).replace('\n', '')
url_all['name'][i]=newname
if '*' in list(str(url_all['name'][i])) :
newname=str(url_all['name'][i]).replace('*', '')
url_all['name'][i]=newname
elif '*' in list(str(url_all['firm'][i])):
newfirm=str(url_all['firm'][i]).replace('*', '')
url_all['firm'][i]=newfirm
continue
write = pd.ExcelWriter("D:/Python程序/金融数据获取与处理/期末大作业/年报url.xlsx")
url_all.to_excel(write)
write.close()
结果展示
获取的年报url
STEP2:下载行业公司的近十年年报
#########下载所有年报
import requests
import openpyxl
import os
import random
wb=openpyxl.load_workbook('D:\\Python程序\金融数据获取与处理\期末大作业\年报url.xlsx')
ws=wb.get_sheet_by_name('Sheet1')
root='D:\\Python程序\金融数据获取与处理\期末大作业\PDF_downloaded'
##下载所属深交所年报
for i in range(2,294):
dir_name=ws.cell(i,2).value+'-'+ws.cell(i,3).value
pdf_name=ws.cell(i,5).value+'-'+ws.cell(i,3).value
dir_path=root+'\\'+dir_name
pdf_path=dir_path+'\\'+pdf_name+'.pdf'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
pdf_url=ws.cell(i,4).value
r=requests.get(pdf_url)
time.sleep(1)
data=r.content
time.sleep(random.random()*3)
with open(pdf_path,mode='wb') as f:
f.write(data)
time.sleep(random.random()*5)
##下载所属上交所年报
for i in range(294,745):
dir_name=ws.cell(i,2).value+'-'+ws.cell(i,3).value
pdf_name=ws.cell(i,3).value+'-'+str(ws.cell(i,6).value)+'-'+ws.cell(i,5).value
dir_path=root+'\\'+dir_name
pdf_path=dir_path+'\\'+pdf_name+'.pdf'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
pdf_url=ws.cell(i,4).value
r=requests.get(pdf_url)
time.sleep(1)
data=r.content
time.sleep(random.random()*3)
with open(pdf_path,mode='wb') as f:
f.write(data)
time.sleep(random.random()*5)
结果展示
下载的行业公司近十年年报如图所示,共723份
STEP3:获取十家公司指定基本信息,保存为excel文件
#########读取指定信息
def get_target_pageNo(doc,anchor):
'''获取目标页码'''
pageNo = -1
for n in range(len(doc)):
page=doc[n]
txt=page.get_text()
if anchor in txt:
pageNo=n
break
return(pageNo)
def get_target_table(pdf_path,anchor):
'''获取目标表格'''
doc=fitz.open(pdf_path)
pageNo=get_target_pageNo(doc,anchor)
with pdfplumber.open(pdf_path) as pdf:
page1=pdf.pages[pageNo]
tables1=page1.extract_tables()
page2=pdf.pages[pageNo+1]#防止表格分页展示
tables2=page2.extract_tables()
tables=tables1+tables2
for i in range(len(tables)):
table=tables[i]
for t in table:
for lis in t:
try:
lis=lis.replace('\n', '')
except:
continue
if anchor == lis:
return tables[i]
def get_target_table_new(pdf_path,anchor):
'''获取目标表格-针对不去除换行符'''
doc=fitz.open(pdf_path)
pageNo=get_target_pageNo(doc,anchor)
with pdfplumber.open(pdf_path) as pdf:
page1=pdf.pages[pageNo]
tables1=page1.extract_tables()
page2=pdf.pages[pageNo+1]#防止表格分页展示
tables2=page2.extract_tables()
tables=tables1+tables2
for i in range(len(tables)):
table=tables[i]
for t in table:
for lis in t:
# try:
# lis=lis.replace('\n', '')
# except:
# continue
if anchor == lis:
return tables[i]
def get_target_info(table,anchor):
dff=pd.DataFrame()
for t in table[1:]:
df =pd.DataFrame(np.array(t[1:]).reshape(1,2),index=['董秘'+t[0]])
dff=pd.concat([dff,df])
dff.columns=table[0][1:]
return dff[anchor]
def save_table_as_df(table):
dff=pd.DataFrame()
for t in table[1:]:
df =pd.DataFrame(np.array(t[1:]).reshape(1,2),index=[t[0]])
dff=pd.concat([dff,df])
dff.columns=table[0][1:]
return dff
dff=save_table_as_df(table)
######获取董秘信息
df_data=pd.DataFrame()
for i in list(range(297,297+10*21,10)):
dir_name=ws.cell(i,2).value+'-'+ws.cell(i,3).value
pdf_name=ws.cell(i,3).value+'-'+str(ws.cell(i,6).value)+'-'+ws.cell(i,5).value
dir_path=root+'\\'+dir_name
pdf_path=dir_path+'\\'+pdf_name+'.pdf'
try:
table=get_target_table(pdf_path,anchor='董事会秘书')
info=get_target_info(table,anchor='董事会秘书')
info.rename(index=dir_name,inplace=True)
df_data = pd.concat([df_data,info], axis=1)
except:
continue
######获取公司信息
df_data_cor=pd.DataFrame()
for i in range(297,297+10*21,10):
dir_name=ws.cell(i,2).value+'-'+ws.cell(i,3).value
pdf_name=ws.cell(i,3).value+'-'+str(ws.cell(i,6).value)+'-'+ws.cell(i,5).value
dir_path=root+'\\'+dir_name
pdf_path=dir_path+'\\'+pdf_name+'.pdf'
try:
table=get_target_table(pdf_path,anchor='公司办公地址')
dff=pd.DataFrame()
for t in table:
df =pd.DataFrame(np.array(t[1]).reshape(-1),index=[t[0]])
dff=pd.concat([dff,df])
dff.columns=[dir_name]
df_data_cor= pd.concat([df_data_cor,dff], axis=1)
except:
continue
#合并相同公司的董秘信息和公司信息
same_col=[]
for i in df_data.columns:
if i in df_data_cor.columns:
same_col.append(i)
continue
df_all_con=pd.DataFrame()
for i in same_col:
dfa=pd.DataFrame(pd.concat([df_data[i],df_data_cor[i]]))
df_all_con=pd.concat([dfa,df_all_con],axis=1)
#整理并保存十家公司指定信息
df_all_con=df_all_con.loc[['董秘姓名','董秘电话','董秘电子信箱','公司办公地址','公司网址']]
df_all_con.dropna(axis=1,inplace=True)
df_all_con=pd.concat([df_all_con.iloc[:,0:7],df_all_con.iloc[:,-4:-1]],axis=1)
df_all_con.to_csv('D:/Python程序/金融数据获取与处理/期末大作业/十家公司指定信息.csv',encoding='gbk')
结果展示
获取的十家公司指定基本信息
STEP4:选取一家公司画出近十年营业收入和归属于上市公司净利润时间序列图
#########获取十家公司财务摘要第一张表并存入excel
comp_info=pd.read_csv('D:/Python程序/金融数据获取与处理/期末大作业/十家公司指定信息.csv',encoding='gbk',index_col=0)
root='D:\\Python程序\金融数据获取与处理\期末大作业\PDF_downloaded'
writer = pd.ExcelWriter('D:/Python程序/金融数据获取与处理/期末大作业/十家公司主要会计数据.xlsx')
def turn_table_toDataFrame(table):
'''将获取的表格转为DataFrame'''
dff=pd.DataFrame()
for t in table:
#根据列数转换,并去除值不为空的列的换行符
if len(t)==7:
try:
df =pd.DataFrame(np.array(t[1:]).reshape(1,6),index=[t[0].replace('\n', '')])
except:
df =pd.DataFrame(np.array(t[1:]).reshape(1,6),index=[t[0]])
elif len(t)==6:
try:
df =pd.DataFrame(np.array(t[1:]).reshape(1,5),index=[t[0].replace('\n', '')])
except:
df =pd.DataFrame(np.array(t[1:]).reshape(1,5),index=[t[0]])
elif len(t)==5:
try:
df =pd.DataFrame(np.array(t[1:]).reshape(1,4),index=[t[0].replace('\n', '')])
except:
df =pd.DataFrame(np.array(t[1:]).reshape(1,4),index=[t[0]])
else:
try:
df =pd.DataFrame(np.array(t[1:]).reshape(1,3),index=[t[0].replace('\n', '')])
except:
df =pd.DataFrame(np.array(t[1:]).reshape(1,3),index=[t[0]])
dff=pd.concat([dff,df])
dff.columns=table[0][1:]
return dff
for i in range(0,10):
file_path=root+'\\'+comp_info.columns[i] #文件夹路径
latest_pdfname = os.listdir(file_path )[-1] # 打开文件夹获取最新年报名称
pdf_path=file_path+'\\'+latest_pdfname
table=get_target_table(pdf_path, anchor='主要会计数据')
dff=turn_table_toDataFrame(table)
dff.to_excel(writer, sheet_name=comp_info.columns[i])
writer.save()
#########选取一家公司画出近十年营业收入和归属于上市公司净利润时间序列图
#获取营业收入
def get_income_1company(file_path):
'''获取一家公司营业收入'''
income=pd.DataFrame()
for i in range(0,10):
latest_pdfname = os.listdir(file_path )[i]
pdf_path=file_path+'\\'+latest_pdfname
table1=get_target_table(pdf_path,anchor='营业收入')
dff1=turn_table_toDataFrame(table1)
income1=pd.DataFrame({int(2013+i):[dff1.loc['营业收入'][0]]})
income=pd.concat([income,income1],axis=1)
return income
file_path=root+'\\'+comp_info.columns[0]
income=get_income_1company(file_path=file_path)
#获取归属于上市公司股东净利润
anchors=['归属于上市公司股东\n的净利润','归属于上\n市公司股\n东的净利\n润',
'归属于上市公司股东的\n净利润','归属于上市公司\n股东的净利润']
net_income=pd.DataFrame()
def create_netincome(table2):
dff2=turn_table_toDataFrame(table2)
net_income1=pd.DataFrame({int(2013+i):[dff2.loc['归属于上市公司股东的净利润'][0]]})
return net_income1
for i in range(0,10):
latest_pdfname = os.listdir(file_path)[i]
pdf_path=file_path+'\\'+latest_pdfname
table2=get_target_table_new(pdf_path,anchor=anchors[0])
if type(table2)==list:
net_income1=create_netincome(table2)
net_income=pd.concat([net_income,net_income1],axis=1)
else:
table2=get_target_table_new(pdf_path,anchor=anchors[1])
if type(table2)==list:
net_income1=create_netincome(table2)
net_income=pd.concat([net_income,net_income1],axis=1)
else:
table2=get_target_table_new(pdf_path,anchor=anchors[2])
if type(table2)==list:
net_income1=create_netincome(table2)
net_income=pd.concat([net_income,net_income1],axis=1)
else:
table2=get_target_table_new(pdf_path,anchor=anchors[3])
net_income1=create_netincome(table2)
net_income=pd.concat([net_income,net_income1],axis=1)
#转换营业收入和归属于上市公司股东净利润为浮点数
def transfer_tofloat(df):
df_new=pd.DataFrame()
for n in range(0,10):
i=str(df.iloc[0,n])
try:
i=i.replace('\n','')
except:
i=i
df1=pd.DataFrame({int(2013+n):i},index=[0])
df_new=pd.concat([df_new,df1],axis=1)
return df_new
income=transfer_tofloat(income)
net_income=transfer_tofloat(net_income)
#数据可视化
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['FangSong']#显示中文
mpl.rcParams['axes.unicode_minus']=False#显示负号
x=[i for i in range(2013,2023)]
y1=[i for i in income.loc[0]]
y2=[i for i in net_income.loc[0]]
plt.plot(x,y1,label='营业收入',linestyle=':',marker='o')
plt.plot(x,y2,label='归属于上市公司股东净利润',marker='s')
plt.xlabel=('年份')
plt.legend(loc=1, fontsize=13)#图例位置在右上方
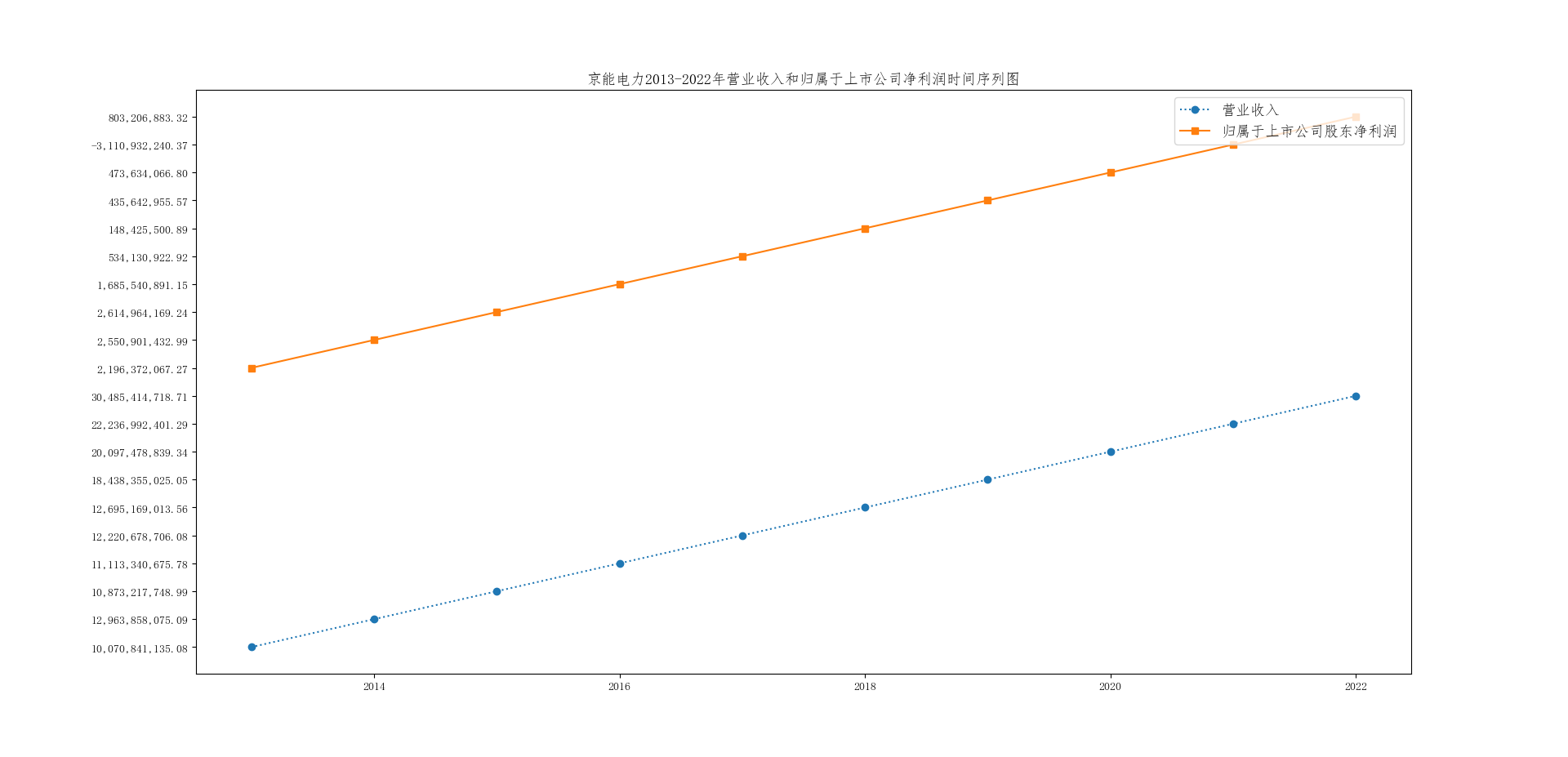
plt.title('京能电力2013-2022年营业收入和归属于上市公司净利润时间序列图', fontsize=13)
plt.show()
结果展示
京能电力2013-2022年营业收入和归属于上市公司净利润时间序列图
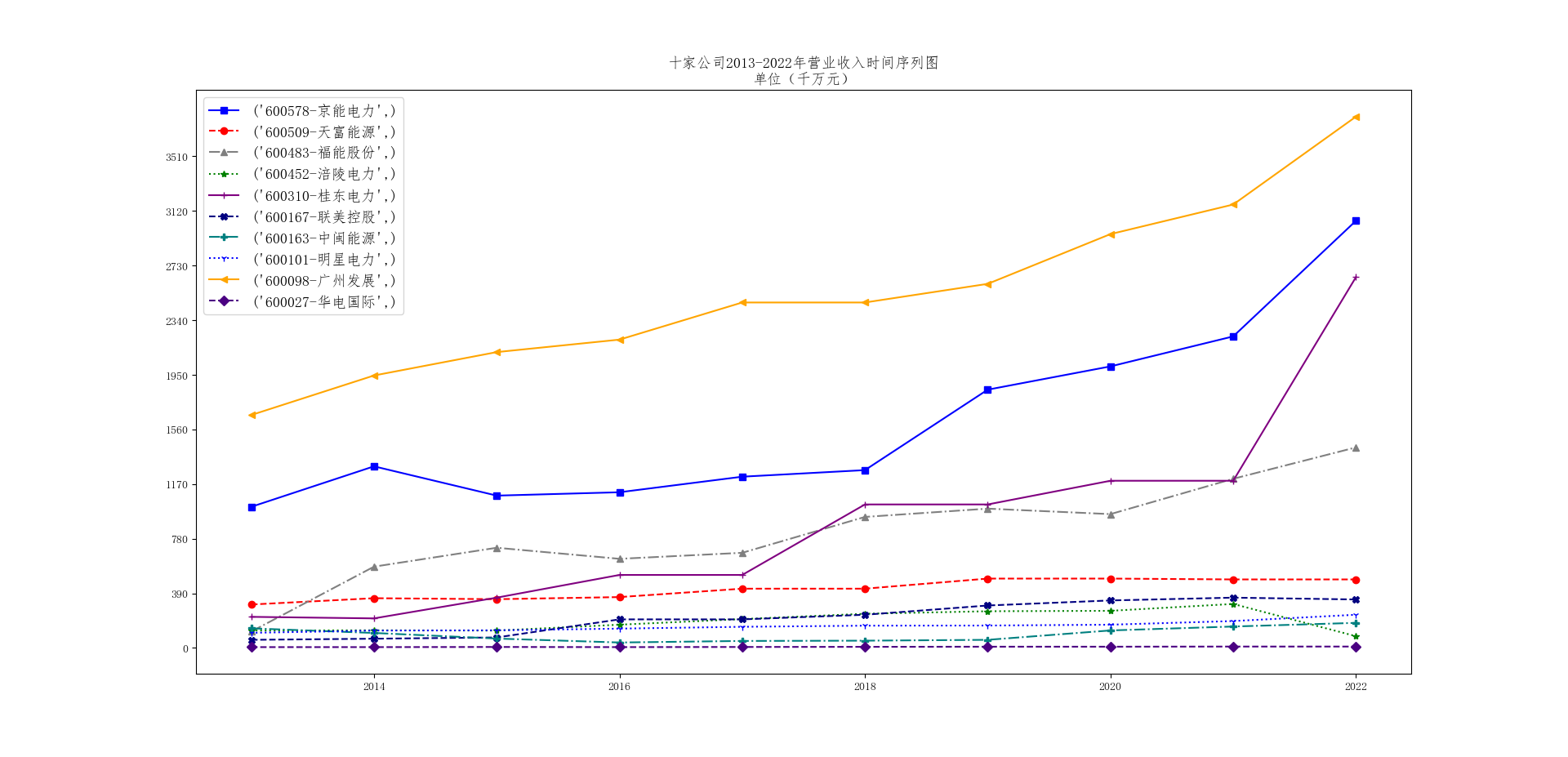
STEP5:画出十家公司营业收入时间序列图
#########画出十家公司营业收入时间序列图
#获取十家公司营业收入
income10=pd.DataFrame()
for i in range(0,10):
file_pathi=root+'\\'+comp_info.columns[i]
incomei=get_income_1company(file_path=file_pathi)
incomei=transfer_tofloat(incomei)
income10=pd.concat([income10,incomei],axis=0)
income10.index=[comp_info.columns]
#将数据单位改为“千万”
income=pd.DataFrame()
for x in range(0,10):
a=[]
for y in range(0,10):
i=int(float(income10.iloc[x,y].replace(',',''))/10000000)
a.append(i)
incomei=np.array(a).reshape(1,10)
income=pd.concat([income,pd.DataFrame(incomei)],axis=0)
income.columns=[i for i in range(2013,2023)]
income.index=comp_info.columns
#数据可视化
x=[i for i in range(2013,2023)]
labels=income10.index
linestyles=['-','dashed','dashdot','dotted','-','dashed','dashdot','dotted','-','dashed']
markers=['s','o','^','*','+','X','P','1','<','D']
colors=['b','r','gray','g','purple','navy','teal','blue','orange','indigo']
for i in range(0,10):
plt.plot(x,income.iloc[i,:],label=labels[i],linestyle=linestyles[i],
marker=markers[i],color=colors[i])
plt.yticks(np.arange(0,3900,390))
plt.legend(loc=0, fontsize=13)#图例位置在左上方
plt.title('十家公司2013-2022年营业收入时间序列图\n单位(千万元)', fontsize=13)
plt.show()
结果展示
十家公司营业收入时间序列图
电力、热力生产及供应行业解读与分析
- 行业总体解读
- 可视化结果解读
中国电力热力行业在过去十年中不断增加装机容量。随着能源需求的增长和经济发展的需要,大型火力发电厂和热力供应系统得到了快速扩张。这包括传统的火电、燃煤发电以及燃气发电等。
从上述的营业收入时间序列图中可以观测到:电力、热力生产及供应行业总体来说最近十年发展稳步提高。
但是十家公司的营业收入时间序列图中也反映了只有部分企业在过去十年里真正实现了营业收入的有效提高。大部分企业的营业收入只实现了一般速度的略微增长。这是由于我国尤其是最近几年随着“碳达峰”、“碳中和”的概念提出而随之而来的能源结构调整的影响:中国电力热力行业逐渐实施结构调整,向清洁能源和高效能源转型。随着环境意识的提高和减少碳排放的需求,清洁能源如天然气发电、风能和太阳能等得到了更多关注。同时,进行了燃煤发电的超低排放和脱硫脱硝等控制技术改造,以减少对环境的影响。由此就造成了积极响应国家号召开始转型的企业的努力在营业收入上有了成效;而部分或出于理念或出于成本的考虑固守传统发电企业的营收便相应地不如变革地企业。