按照要求,我匹配到的行业是废弃资源综合利用业,正好有10家公司。 现将该行业前10家上市公司的基本信息列示如下。
| 上市公司代码 | 上市公司简称 |
|---|---|
| 000820 | 神雾节能 |
| 002340 | 格林美 |
| 002672 | 东江环保 |
| 002996 | 顺博合金 |
| 300779 | 惠城环保 |
| 300930 | 屹通新材 |
| 301026 | 浩通科技 |
| 600217 | 中再资环 |
| 688087 | 英科再生 |
| 688196 | 卓越新能 |
该部分函数旨在定义自动爬取上海交易所和深圳交易所定期报告页面, 并对爬取之后的页面进行信息提取。即提取出每一家公司的年报的名称、 pdf的链接等等,最终将这些指标保存为一个CSV文件。
此部分爬取用到老师上课教过的代码, 但在原本parse_sse_table函数中写的打开fname并读取存于变量html中这一部分代码却 使得最终读取的html为空,于是另定义了一个函数sse_table进行运行。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import re
import pandas as pd
def get_table_sse(code):
browser = webdriver.Edge()
url = "http://www.sse.com.cn/disclosure/listedinfo/regular/"
browser.get(url)
time.sleep(3)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code) #601919
time.sleep(3)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
dropdown = browser.find_element(By.CSS_SELECTOR, ".dropup > .selectpicker")
dropdown.find_element(By.XPATH, "//option[. = '年报']").click()
time.sleep(3)
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
def get_table_sse_code(codes):
for code in codes:
get_table_sse(code)
def get_sse_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_sse_table(fname,save=True):
# f = open(fname, encoding='utf-8')
# html = f.read()
# f.close()
#
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(fname)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_sse_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
def sse_table(fname):
f = open(fname, encoding='utf-8')
html = f.read()
f.close()
#
df = parse_sse_table(html)
return(df)
import time
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
def get_table_szse(code):
driver = webdriver.Edge()
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.set_window_size(1552, 832)
time.sleep(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(code)
time.sleep(3)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
time.sleep(3)
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(3)
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
element = driver.find_element(By.ID, 'disclosure-table')
# add
time.sleep(5)
table_html = element.get_attribute('innerHTML')
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
driver.quit()
#循环获取
def get_table_szse_codes(codes):
for code in codes:
get_table_szse(code)
#HTML解析
def get_szse_data(tr):
p_td = re.compile('(.*?)',re.DOTALL)
tds = p_td.findall(tr) #tds是一个列表,包含四个(.+?) ',re.DOTALL)
trs = p.findall(html)
# 找出不为空的“tr对”
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#del trs_new[0]
# 应用get_data()函数和提取code、name、herf、title 和 date;
data_all = [get_szse_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({'code':[d[0] for d in data_all],
'name':[d[1] for d in data_all],
'href':[d[2] for d in data_all],
'title':[d[3] for d in data_all],
'date':[d[4] for d in data_all]})
#
return df
import datetime
import pandas as pd
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df['title']])
else:
ls.append([word not in f for f in df['title']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
def filter_date(start,end,df):
date = df['date']
v =[d >= start and d <= end for d in date]
df_new = df[v]
return(df_new)
def start_end_10y():
dt_now = datetime.datetime.now()
current_year = dt_now.year
start = f'{current_year-9}-01-01'
end = f'{current_year}-12-31'
return((start,end))
def filter_nb_10y(df,
keepwords=['年报','年度报告','(修订版)'],
exclude_word=['摘要','专项说明'],
start='',
end = ''):
if start == '':
start, end = start_end_10y()
else:
start_y = int(start[0:4])
end = f'{start_y + 9}-12-31'
#
df = filter_links(keepwords, df, include=True)
df = filter_links(exclude_word, df, include=False)
df = filter_date(start, end, df)
return(df)
def prepare_hrefs_years(df):
hrefs = list(df['href'])
years = [str(int(d[0:4])-1) for d in df['date']]
code = list(df['code'])
return pd.DataFrame([code,hrefs, years],index = ['code','href','year']).T
此部分老师上课讲解定义了三个函数,我在之后的运行过程中适当调整删去一个。
import requests
import time
def download_pdf(hrefs, code, year):
r = requests.get(hrefs, allow_redirects=True)
fname = f'{code}_{year}.pdf'
f = open(fname, 'wb')
f.write(r.content)
f.close()
#
r.close()
def download_pdfs_code(list_hrefs,codes,list_years):
for i in range(len(list_hrefs)):
hrefs = list_hrefs[i]['href']
year = list_years[i]
code = codes[i]
download_pdf(hrefs,code,year)
return()
调用之前定义的函数,先爬取下载html并提取信息,清洗过滤后保存为CSV文件。 而后通过读取CSV文件,访问每一张DataFrame的href列,获取pdf下载链接, 在下载途中遇到问题,最后发现要将list_hrefs转化为字典,否则download_pdfs_code函数无法成功调用 最终成功爬取到10家上市公司的10年内的pdf年报。
#调用定义好的函数
from sse import get_table_sse,get_table_sse_code,get_sse_data,parse_sse_table,sse_table
from szse import get_table_szse,get_table_szse_codes,get_szse_data,parse_szse_table
from filter_url import filter_links,filter_date,start_end_10y,filter_nb_10y,prepare_hrefs_years
from download import download_pdf,download_pdfs,download_pdfs_code
from parse_ar import get_target_subtxt,get_th_span,get_bounds,get_keywords,parse_key_fin_data,file_name_walk,pdf_sum_pa
import numpy as np
import pandas as pd
import os
# -------------------------------------------HTML爬取----------------------------------------------------
#自动爬取上交所、深交所下载相应股票的html
codes1=['000820','002340','002672','002996','300779','300930','301026']
codes2=['600217','688087','688196']
get_table_szse_codes(codes1)
get_table_sse_code(codes2)
# 读取上交所的html,并存为csv文件
df_600217 = sse_table(r'600217.html'); df_600217 = filter_nb_10y(df_600217,keepwords = ['年报','年度报告','(修订版)'],exclude_word = ['摘要','专项说明'],start = '',end = ''); df_600217.to_csv('600217.csv')
df_688087 = sse_table(r'688087.html'); df_688087 = filter_nb_10y(df_688087,keepwords = ['年报','年度报告'],exclude_word = ['摘要','决算报告'],start = '',end = ''); df_688087.to_csv('688087.csv')
df_688196 = sse_table(r'688196.html'); df_688196 = filter_nb_10y(df_688196,keepwords = ['年报','年度报告'],exclude_word = ['摘要'],start = '',end = ''); df_688196.to_csv('688196.csv')
# 读取深交所的html,并存为csv文件
df_000820 = parse_szse_table(r'000820.html'); df_000820 = filter_nb_10y(df_000820,keepwords = ['年报','年度报告','(更新后)'],exclude_word = ['摘要','已取消'],start = '',end = ''); df_000820.to_csv('000820.csv')
df_002340 = parse_szse_table(r'002340.html'); df_002340 = filter_nb_10y(df_002340,keepwords = ['年报','年度报告','(更新后)'],exclude_word = ['摘要','已取消'],start = '',end = ''); df_002340.to_csv('002340.csv')
df_002672 = parse_szse_table(r'002672.html'); df_002672 = filter_nb_10y(df_002672,keepwords = ['年报','年度报告','(更新后)'],exclude_word = ['摘要','已取消'],start = '',end = ''); df_002672.to_csv('002672.csv')
df_002996 = parse_szse_table(r'002996.html'); df_002996 = filter_nb_10y(df_002996,keepwords = ['年报','年度报告'],exclude_word = ['摘要'],start = '',end = ''); df_002996.to_csv('002996.csv')
df_300779 = parse_szse_table(r'300779.html'); df_300779 = filter_nb_10y(df_300779,keepwords = ['年报','年度报告'],exclude_word = ['摘要'],start = '',end = ''); df_300779.to_csv('300779.csv')
df_300930 = parse_szse_table(r'300930.html'); df_300930 = filter_nb_10y(df_300930,keepwords = ['年报','年度报告'],exclude_word = ['摘要'],start = '',end = ''); df_300930.to_csv('300930.csv')
df_301026 = parse_szse_table(r'301026.html'); df_301026 = filter_nb_10y(df_301026,keepwords = ['年报','年度报告'],exclude_word = ['摘要'],start = '',end = ''); df_301026.to_csv('301026.csv')
#------------------------------------------下载年报-----------------------------------------------------
#读取csv并进行清洗过滤
df1_600217 = pd.read_csv('600217.csv',dtype=object); temp_600217 = prepare_hrefs_years(df1_600217)
df1_688087 = pd.read_csv('688087.csv',dtype=object); temp_688087 = prepare_hrefs_years(df1_688087)
df1_688196 = pd.read_csv('688196.csv',dtype=object); temp_688196 = prepare_hrefs_years(df1_688196)
df1_000820 = pd.read_csv('000820.csv',dtype=object); temp_000820 = prepare_hrefs_years(df1_000820)
df1_002340 = pd.read_csv('002340.csv',dtype=object); temp_002340 = prepare_hrefs_years(df1_002340)
df1_002672 = pd.read_csv('002672.csv',dtype=object); temp_002672 = prepare_hrefs_years(df1_002672)
df1_002996 = pd.read_csv('002996.csv',dtype=object); temp_002996 = prepare_hrefs_years(df1_002996)
df1_300779 = pd.read_csv('300779.csv',dtype=object); temp_300779 = prepare_hrefs_years(df1_300779)
df1_300930 = pd.read_csv('300930.csv',dtype=object); temp_300930 = prepare_hrefs_years(df1_300930)
df1_301026 = pd.read_csv('301026.csv',dtype=object); temp_301026 = prepare_hrefs_years(df1_301026)
# 合并DataFrame
list_hrefs = pd.concat([temp_600217,temp_688087,temp_688196,
temp_000820,temp_002340,temp_002672,
temp_002996,temp_300779,temp_300930,
temp_301026], axis=0, ignore_index=False)
# 获取list_hrefs中的codes、years
codes = list(list_hrefs['code'])
list_years = list(list_hrefs['year'])
# 将list_hrefs转化为字典,否则download_pdfs_code函数无法成功调用
list_hrefs = list(list_hrefs[['code', 'href', 'year']].to_dict(orient='records'))
# 下载PDF
download_pdfs_code(list_hrefs,codes,list_years)
爬取的html文件和经过清洗提取后得到的CSV文件、下载的pdf年报、以“格林美”为例的csv文件列表。

import fitz
import pandas as pd
import re
import os
def get_target_subtxt(doc,bounds = ('主要会计数据和财务指标','归属于上市公司股东的净资产')): #
# 默认设置为首页页码
start_pageno = 0
end_pageno = len(doc) - 1
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0][0] or bounds[0][1]) in doc[n].get_text():
start_pageno = n
break
# 获取下界页码
for i in range(start_pageno,len(doc)):
p = re.compile('(?:\s*\n*归\s*\n*属\s*\n*于\s*\n*上\s*\n*市\s*\n*公\s*\n*司\s*\n*股\s*\n*东\s*\n*的\s*\n*净\s*\n*资\s*\n*产\s*\n*)',re.DOTALL)
a = p.findall(doc[i].get_text())
if len(a)==0:
continue
elif bounds[1] in a[0].replace('\n','').replace(' ',''):
end_pageno = i
break
# 获取界定的内容
txt = ''
if start_pageno == end_pageno:
txt = doc[start_pageno].get_text()
else:
for _ in range(start_pageno,end_pageno + 1):
page =doc[_]
txt += page.get_text()
return txt
# 获取界定
def get_th_span(txt):
nianfen = '(20\d\d|199\d)\s*年末?' #
s = '{}\s*{}.*?{}'.format(nianfen,nianfen,nianfen)
p = re.compile(s,re.DOTALL)
matchobj_ = p.search(txt)
#
end = matchobj_.end()
year1 = matchobj_.group(1)
year2 = matchobj_.group(2)
year3 = matchobj_.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
while not flag:
matchobj_.search(txt[end:])
end = matchobj_.end()
year1 = matchobj_.group(1)
year2 = matchobj_.group(2)
year3 = matchobj_.group(3)
flag = int(year1) - int(year2) == 1
flag = flag and (int(year2) - int(year3) == 1)
return ([year1,year2,year3],matchobj_.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)[1]
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])[1]
th_span_2nd = (end + th_span_2nd[0],end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[1]
#
# p = re.compile('(\s*\n*(\d{1,3}(?:,\d{3})*(?:\.\d+)?(?:\%)?)\s*){4}',re.DOTALL) #
# matchobj_ = p.search(txt[s:e])
# end_withs = matchobj_.group()
while txt[e] not in '0123456789':
e = e-1
return (s,e)
# 提取关键字
def get_keywords(subtxt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(subtxt)
if '营业收入' not in keywords:
keywords.insert(0,'营业收入')
for i in keywords:
if len(i) <= 3:
keywords.remove(i)
for x in keywords:
if ('股份有限公司' or '年度报告') in x:
keywords.remove(x)
return keywords
# 提取成表格
def parse_key_fin_data(subtxt,keywords):
#keywords = ['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss = []
s= 0
for kw in keywords:
n = subtxt.find(kw,s)
ss.append(n)
s = n +len(kw)
ss.append(len(subtxt))
data = []
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
p3 = re.compile('(\s*\n*\-*(\d{1,3}(?:,\d{3})*(?:\.\d+)?(?:\%)?)\s*){3,4}',re.DOTALL)
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtxt[s:e]
# 获取可能换行的账户名
matchobj = p.search(line)
account_name = matchobj.group().replace('\n','')
account_name = p2.sub('',matchobj.group())
# 获取3年数据
#amnts = line[matchobj.end():].split()
#
matchobjs = p3.search(line)
amnts = matchobjs.group().split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
def file_name_walk(file_dir):
file_path_lst = []
for x in os.walk(file_dir):
file_path_lst.append((x[0],x[2]))
return file_path_lst
def pdf_sum_pa(paths,fil_name):
pdf_path = '{}\{}'.format(paths,fil_name)
doc = fitz.open(r'{}'.format(pdf_path))
# 获取大致范围的文本
txt = get_target_subtxt(doc)
# 建立列名
col = [ x for x in get_th_span(txt)[0]]
col.insert(-1,'变动')
col.insert(0,'指标')
# 获取精确范围
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
# 获取项目名称
keywords = get_keywords(subtxt)
# 建立成列表族
datas = parse_key_fin_data(subtxt,keywords)
# 换成DataFame
df = pd.DataFrame(datas,columns=col)
new_dirs = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/csv_data'
dir_name = new_dirs+'\{}'.format(fil_name[0:6])
if os.path.exists(dir_name) == False:
os.makedirs(dir_name)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
else:
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
def get_target(doc,bounds =['股票简称','信息披露及备置地点']):
# 默认设置为首页页码
start_pageno = 0
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0] or bounds[0]) in doc[n].get_text():
start_pageno = n
break
return start_pageno
正则表达式按要求从10家上市公司2022年的年报中提取出“公司简称”“股票代码”“办公地址”“公司网址”“董秘电话”“董秘&公司电子信箱”等指标的关键信息。
# ---------------------------------------提取公司信息------------------------------------------------
# 利用file_name_walk找出pdf_data下所有文件的路径和文件名
paths = "D:\\Ana\\.spyder-py3\\nianbao\\src\\nianbao\\code_pdf"
paths_pos = file_name_walk(paths)
del paths_pos[0]
# 创建一个只包含每只股票2022年年报绝对路径的列表,然后遍历调用
abs_pos_lst = []
for i in file_name_walk(paths):
for n in i[1]:
if '2022' in n:
abs_pos = '{}/{}'.format(i[0],n)
abs_pos_lst.append(abs_pos)
else:
continue
# 提前创建一个表格,以便于存储数据
keys_Data = pd.DataFrame(columns=['公司简称','股票代码','办公地址','公司网址','董秘电话','董秘&公司电子信箱'])
for i in abs_pos_lst:
docs = fitz.open(i)#i[0]+'\\{}'.format(n)
brief_ =docs[get_target(docs,bounds =['股票简称','信息披露及备置地点'])].get_text()
# name
cor_name_compile = re.compile('.*股票简称.*?\n(.*?)\s*\n*股票代码.*',re.DOTALL)
name = cor_name_compile.findall(brief_)[0].strip()
# code
cor_code_compile = re.compile('.*股票代码.*?\n(.*?)\s.*',re.DOTALL)
code = cor_code_compile.findall(brief_)[0].strip()
# address
cor_address_compile = re.compile('办公地址.*?\n(.*?)\s*\n.*?',re.DOTALL)
address = cor_address_compile.findall(brief_)[0].strip()
# web
cor_web_compile = re.compile('公司.*?网址\s*(.*?)\n', re.DOTALL)
web = cor_web_compile.findall(brief_)[0].strip()
# secretary_telephone
sec_tel_compile = re.compile('.*电话.*?\n\s*(.*?)\s*\n.*?',re.DOTALL)
tele = sec_tel_compile.findall(brief_)[0].strip()
# secretary_mail
sec_mail_compile = re.compile('.*电子信箱.*?\n\s*(.*?)\n.*',re.DOTALL)
mail = sec_mail_compile.findall(brief_)[0].strip()
keys_Data.loc[len(keys_Data.index)] = {'公司简称':name,'股票代码':code,
'办公地址':address,'公司网址':web,
'董秘电话':tele,'董秘&公司电子信箱':mail}
print('Processing', i)
keys_Data.to_csv('D:/Ana/.spyder-py3/nianbao/src/nianbao/corperate_info.csv',encoding = 'ANSI')
在提取会计数据表格时,出现了异常情况,难以解决。 向同学请教后利用了“try-except”异常处理结构:如果格式正常,则正常执行“try”后的语句; 如果解析格式异常,则打印错误类型,执行except后面的内容(用pdfplumber提取)。 虽然这样保证了程序的正常运行,但读取出的表格存在着问题,没能找到办法解决, 于是只好对600217的2018年的数据进行手动调整。
#-------------------------------------------表格提取------------------------------------------------------
# 获取csv表格
file_dir = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/code_pdf'
pdf_path = file_name_walk(file_dir)
del pdf_path[0]
for ele in pdf_path[:]:
for name_ in ele[1]:
try:
pdf_sum_pa(ele[0],name_)
except Exception as e:
# 600217的2018解析失败
print('--------------------------------------------------')
print(name_,'出现异常.错误类型为:',e)
# 利用pdfplumber进行提取
new_pos = '{}/{}'.format(ele[0],name_)
new_dirs = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/csv_data'
dir_name = new_dirs+'\{}'.format(name_[0:6])
import pdfplumber
page = pdfplumber.open(new_pos).pages
for i in page:
if '主要会计数据和财务指标' in i.extract_text():
df = pd.DataFrame(i.extract_table())
df.columns = df.iloc[0]
df.drop(0,inplace = True)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,name_[0:6],name_[7:-4]))
#
print(name_,'错误已解决,内容成功为pdfplumber所提取')
从csv文件中提取“营业收入”“归属于上市公股东的净利润”在当年的数据, 按照公司为类别合并成时间序列类型的表格。运行过程中encoding编码出现错误, 于是我在循环中利用chardet库检测文件编码方式,使用正确的编码方式进行解码,避免出现无法解码的情况。
# --------------获取10家公司10年内“营业收入”和“归属于上市公司股东的净利润”组成的的时间序列表格-----------------
import chardet
file_dir = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/csv_data'
file_pos = file_name_walk(file_dir)
del file_pos[0]
Series_Data_Path = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/Series_data'
for i in file_pos:
joint_lst = []
for x in i[1]:
#用chardet库检测文件编码方式,并使用正确的编码方式进行解码,避免出现无法解码的情况
with open('{}/{}'.format(i[0],x), 'rb') as f:
content = f.read()
encoding = chardet.detect(content)['encoding']
df = pd.read_csv('{}/{}'.format(i[0],x), dtype=object, encoding=encoding)
# df = pd.read_csv('{}/{}'.format(i[0],x),dtype = object,encoding='gb2312')
if 'Unnamed: 0' in df.columns:
df = df.drop('Unnamed: 0', axis=1)
lst = ['营业收入(元)','营业收入',
'归属于上市公司股东的净利润(元)',
'归属于上市公司股东的净利润']
# keys_ = '|'.join(lst)
df = df[df['指标'].isin(lst)].iloc[:,0:2]
df.index = range(len(df))
df = df.T
df.columns = df.iloc[0]
df.drop(index = '指标',inplace = True)
# df
joint_lst.append(df)
Series_Data = pd.concat(joint_lst,axis = 0)
for i in Series_Data.index:
# 用any判断是否有些行的内容与列相同,如果True,则删去与列相同的行
if any(Series_Data.columns == Series_Data.loc[i]) == True:
Series_Data.drop(i,inplace = True)
#Series_Data.index = range(len(Series_Data))
Series_Data.to_csv('{}/{}.csv'.format(Series_Data_Path,x[0:6]),encoding = 'ANSI')
将两个指标时间序列按公司合并,整理成时间序列类型的数据,方便后续绘图调用。 由于有些公司上市不足10年,合并后数据存在nan值,无法去除逗号并转化为数值类型, 于是进行分段处理,按上市时间分为4个子集。
# 提取10家公司营业收入时间序列
series_pos = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/Series_data'
csv_name = os.listdir(series_pos)
# 创建代码名称字典
code_ = ['000820','002340','002672','002996','300779','300930','301026','600217','688087','688196']
values = ['神雾节能','格林美','东江环保','顺博合金','惠城环保','屹通新材','浩通科技','中再资环','英科再生','卓越新能']
nvs = zip(code_,values)
nvDict = dict( (name,value) for name,value in nvs)
merge_lst = []
for _ in csv_name:
df = pd.read_csv('{}/{}'.format(series_pos,_),encoding = 'ANSI',dtype = object,index_col = 0)
df_revenue = df.iloc[:,0]
df_revenue.rename(nvDict[_[0:-4]],inplace = True)
df_revenue.columns = [nvDict[_[0:-4]]]
merge_lst.append(df_revenue)
revenue_series = pd.concat(merge_lst,axis = 1)
#有些公司上市未到10年,分开取值并将所有元素的逗号去掉,然后转换为数值类型,再除以一亿将单位变为亿元。
year_10_series = revenue_series.iloc[:,[0,1,2,7]].applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/100000000)
year_4_series = revenue_series.iloc[:,[4,9]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/100000000)
year_3_series = revenue_series.iloc[:,[3,5]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/100000000)
year_2_series = revenue_series.iloc[:,[6,8]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/100000000)
# 合并上市公司股东净利润的时间序列表格
merge_lst_1 = []
for _ in csv_name:
df = pd.read_csv('{}/{}'.format(series_pos,_),encoding = 'ANSI',dtype = object,index_col = 0)
df_profit = df.iloc[:,1]
df_profit.rename(nvDict[_[0:-4]],inplace = True)
df_profit.columns = [nvDict[_[0:-4]]]
merge_lst_1.append(df_profit)
profit_series = pd.concat(merge_lst_1,axis = 1)
#有些公司上市未到10年,分开取值并将所有元素的逗号去掉,然后转换为数值类型,再除以一千万将单位变为千万。
pro_10year_series = profit_series.iloc[:,[0,1,2,7]].applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000000)
pro_4year_series = profit_series.iloc[:,[4,9]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000000)
pro_3year_series = profit_series.iloc[:,[3,5]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000000)
pro_2year_series = profit_series.iloc[:,[6,8]].dropna().applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000000)
profit_series_1 = pd.concat([pro_10year_series, pro_4year_series, pro_3year_series, pro_2year_series], axis=1)
.png)
| 公司简称 | 股票代码 | 办公地址 | 公司网址 | 董秘电话 | 董秘& 公司电子信箱 |
|---|---|---|---|---|---|
| 神雾节能 | 000820 | 江苏省南京市雨花台区宁双路 28 号汇智大厦 A 座 9 楼 | www.njswes.com.cn | 025-85499131 | stocks@shenwujieneng.com |
| 格林美 | 002340 | 深圳市宝安区宝安中心区兴华路南侧荣超滨海大厦 A 栋 20 层 | http://www.gem.com.cn | 0755-33386666 | panhua@gem.com.cn |
| 东江环保 | SZ002672 | 深圳市南山区科技园北区朗山路 9 号东江环保大楼 1 楼、3 楼、8 楼北面、9-12 楼 | www.dongjiang.com.cn | 0755-88242614 | ir@dongjiang.com.cn |
| 顺博合金 | 002996 | 重庆市合川区草街拓展园区 | www.sballoy.com | 023-86521019 | ir@soonbest.com |
| 惠城环保 | 300779 | 青岛经济技术开发区淮河东路 57 号 | www.hcpect.com | 0532-58657701 | stock@hcpect.com |
| 屹通新材 | 300930 | 浙江省杭州市建德市大慈岩镇檀村村 | http://www.ytpowder.com | 0571-64560598 | IR@hzytxc.com |
| 浩通科技 | 301026 | 江苏省徐州经济技术开发区刘荆路 1 号 | www.hootech.com.cn | 0516 - 8798 0269 | sc@hootech.com.cn |
| 中再资环 | 600217 | 北京市西城区宣武门外大街甲1号环球财讯中心B座8层 | http://www.zhongzaizihuan.com | 010-59535600 | irm@zhongzaizihuan.com |
| 英科再生 | 688087 | 山东省淄博市临淄区齐鲁化学工业园清田路 | www.intco.com.cn | 0533-6097778 | Board@intco.com.cn |
| 卓越新能 | 688196 | 龙岩市新罗区铁山镇平林(福建龙州工业园东宝工业集中区) | www.zyxny.com | 0597-2342338 | zyxnyir@163.com |
利用第二部分整理合并的两指标(营业收入和上市公司股东净利润)时间序列绘制图形。
由于有几家公司上市不足十年,之前处理时间序列数据时将其拆分, 绘制图形过程中,并未想到重新将其合并,而是通过在循环中设置if条件进行绘制。
#引入库+设置参数+创建画布
from pylab import mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['axes.unicode_minus'] = 0
plt.style.use('ggplot')
plt.figure(figsize=(15,9))
# 创建新的 Figure 对象,并设置 figsize 参数
fig = plt.figure(figsize=(20, 10))
# 绘制每个子图
for i in range(10):
ax = fig.add_subplot(2, 5, i+1)
#有些公司年份不足十年
if i <=3:
ax.plot(year_10_series.iloc[:,i],label = revenue_series.iloc[:,i].name)
elif 3< i <=5:
ax.plot(year_4_series.iloc[:,i-4],label = revenue_series.iloc[:,i].name)
elif 5< i <=7:
ax.plot(year_3_series.iloc[:,i-6],label = revenue_series.iloc[:,i].name)
else:
ax.plot(year_2_series.iloc[:,i-8],label = revenue_series.iloc[:,i].name)
# ax.plot(year_10_series.iloc[:,i], label=revenue_series.iloc[:,i].name)
ax.set_xlabel(u'年份', fontsize=20)
ax.set_ylabel(u'营业收入(单位:亿元)', fontsize=20)
ax.tick_params(axis='both', which='major', labelsize=20)
ax.legend(loc=0, fontsize=20)
# 调整子图之间的间距
plt.tight_layout(pad=3)
# 添加总标题
plt.suptitle('废弃资源综合利用业10家上市公司营业收入时序图', fontsize=20, fontweight='heavy')
# 显示图形
plt.show()
将数据进行合并绘制营业收入纵向对比图,观察图形发现格林美的营业收入达到百亿级, 与其他公司差距较大。
# 合并
revenue_series_1 = pd.concat([year_10_series, year_4_series, year_3_series, year_2_series], axis=1)
# 废弃资源综合利用业10家上市公司10年营业收入纵向柱状对比图'
plt.figure(figsize=(15,6))
ro = 0
labels = list(revenue_series_1.index)
x = np.arange(len(labels))
for i in range(len(revenue_series_1[:])):
labels = list(revenue_series_1.index)
plt.bar(x+ro,revenue_series_1.iloc[:,i],width=0.08,label = revenue_series_1.iloc[:,i].name,edgecolor = 'black')
ro += 0.086
plt.xticks(x+0.3,labels,fontsize = 23,rotation = 22.5)
plt.yticks(fontsize = 23)
plt.xlabel(u'年 份',fontsize = 30)
plt.ylabel(u'营业收入(单位:亿元)',fontsize = 30)
plt.legend()
plt.title(u'废弃资源综合利用业10家上市公司营业收入纵向柱状对比图',fontsize = 35,fontweight='heavy')
plt.show()
因格林美的营业收入达到百亿级,与其他公司差距较大,将其剔除后画出图形。
year_10new_series = revenue_series.iloc[:,[0,2,7]].applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/100000000)
revenue_series_2 = pd.concat([year_10new_series, year_4_series, year_3_series, year_2_series], axis=1)
# 废弃资源综合利用业9家上市公司10年营业收入纵向柱状对比图(不含格林美)'
plt.figure(figsize=(15,6))
ro = 0
labels = list(revenue_series_2.index)
x = np.arange(len(labels))
for i in range(len(revenue_series_2[:])):
labels = list(revenue_series_2.index)
plt.bar(x+ro,revenue_series_2.iloc[:,i],width=0.08,label = revenue_series_2.iloc[:,i].name,edgecolor = 'black')
ro += 0.086
plt.xticks(x+0.3,labels,fontsize = 23,rotation = 22.5)
plt.yticks(fontsize = 23)
plt.xlabel(u'年 份',fontsize = 30)
plt.ylabel(u'营业收入(单位:亿元)',fontsize = 30)
plt.legend()
plt.title(u'废弃资源综合利用业9家上市公司营业收入纵向柱状对比图(不含格林美)',fontsize = 35,fontweight='heavy')
plt.show()
# 绘图
from pylab import mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['axes.unicode_minus'] = 0
plt.style.use('ggplot')
plt.figure(figsize=(15,8))
for i in range(10):
# 绘制子图
plt.subplot(2,5,i+1)
plt.plot(profit_series_1.iloc[:,i],label = profit_series_1.iloc[:,i].name)
plt.xlabel(u'年 份',fontsize = 12)
plt.ylabel(u'股东净利润(单位:千万)',fontsize = 12)
plt.xticks(fontsize = 12)
plt.yticks(fontsize = 12)
plt.legend(loc = 0,fontsize =13)
plt.grid(c= 'white',ls ='--',lw = 1)
plt.tight_layout()
plt.suptitle('废弃资源综合利用业10家上市公司股东净利润时序图',fontsize = 18,fontweight='heavy')
plt.show()
将数据进行合并绘制股东净利润纵向对比图,观察图形发现神雾节能的股东净利润达到百亿级, 与其他公司差距较大。
plt.figure(figsize=(15,6))
plt.title(u'废弃资源综合利用业10家上市公司10年股东净利润纵向对比图',fontsize = 30,fontweight='heavy')
ro = 0
labels = list(profit_series_1.index)
x = np.arange(len(labels))
for i in range(len(profit_series_1[:])):
labels = list(profit_series_1.index)
plt.bar(x+ro,profit_series_1.iloc[:,i],width=0.08,label = profit_series_1.iloc[:,i].name,edgecolor = 'black')
ro += 0.086
plt.xticks(x+0.3,labels,fontsize = 23,rotation = 22.5)
plt.yticks(fontsize = 23)
plt.xlabel(u'年 份',fontsize = 25)
plt.ylabel(u'股东净利润(单位:千万)',fontsize = 25)
plt.legend()
plt.show()
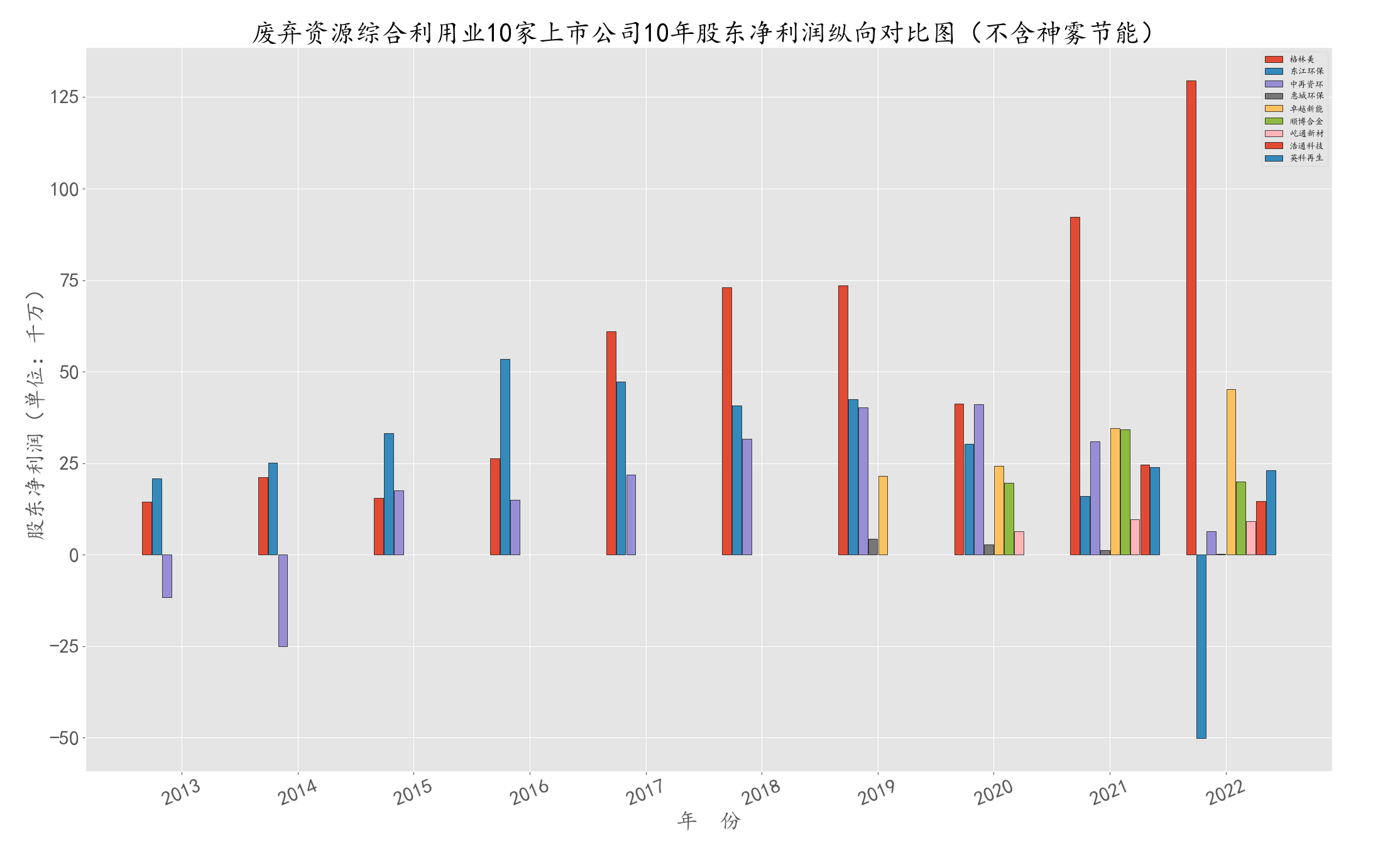
因神雾节能的股东净利润达到百亿级,与其他公司差距较大,将其剔除后画出图形。
pronew_10year_series = profit_series.iloc[:,[1,2,7]].applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000000)
profit_series_2 = pd.concat([pronew_10year_series, pro_4year_series, pro_3year_series, pro_2year_series], axis=1)
#废弃资源综合利用业10家上市公司9年股东净利润纵向对比图(不含神雾节能)
plt.figure(figsize=(15,6))
plt.title(u'废弃资源综合利用业9家上市公司10年股东净利润纵向对比图(不含神雾节能)',fontsize = 30,fontweight='heavy')
ro = 0
labels = list(profit_series_2.index)
x = np.arange(len(labels))
for i in range(len(profit_series_2[:])):
labels = list(profit_series_2.index)
plt.bar(x+ro,profit_series_2.iloc[:,i],width=0.08,label = profit_series_2.iloc[:,i].name,edgecolor = 'black')
ro += 0.086
plt.xticks(x+0.3,labels,fontsize = 23,rotation = 22.5)
plt.yticks(fontsize = 23)
plt.xlabel(u'年 份',fontsize = 25)
plt.ylabel(u'股东净利润(单位:千万)',fontsize = 25)
plt.legend()
plt.show()
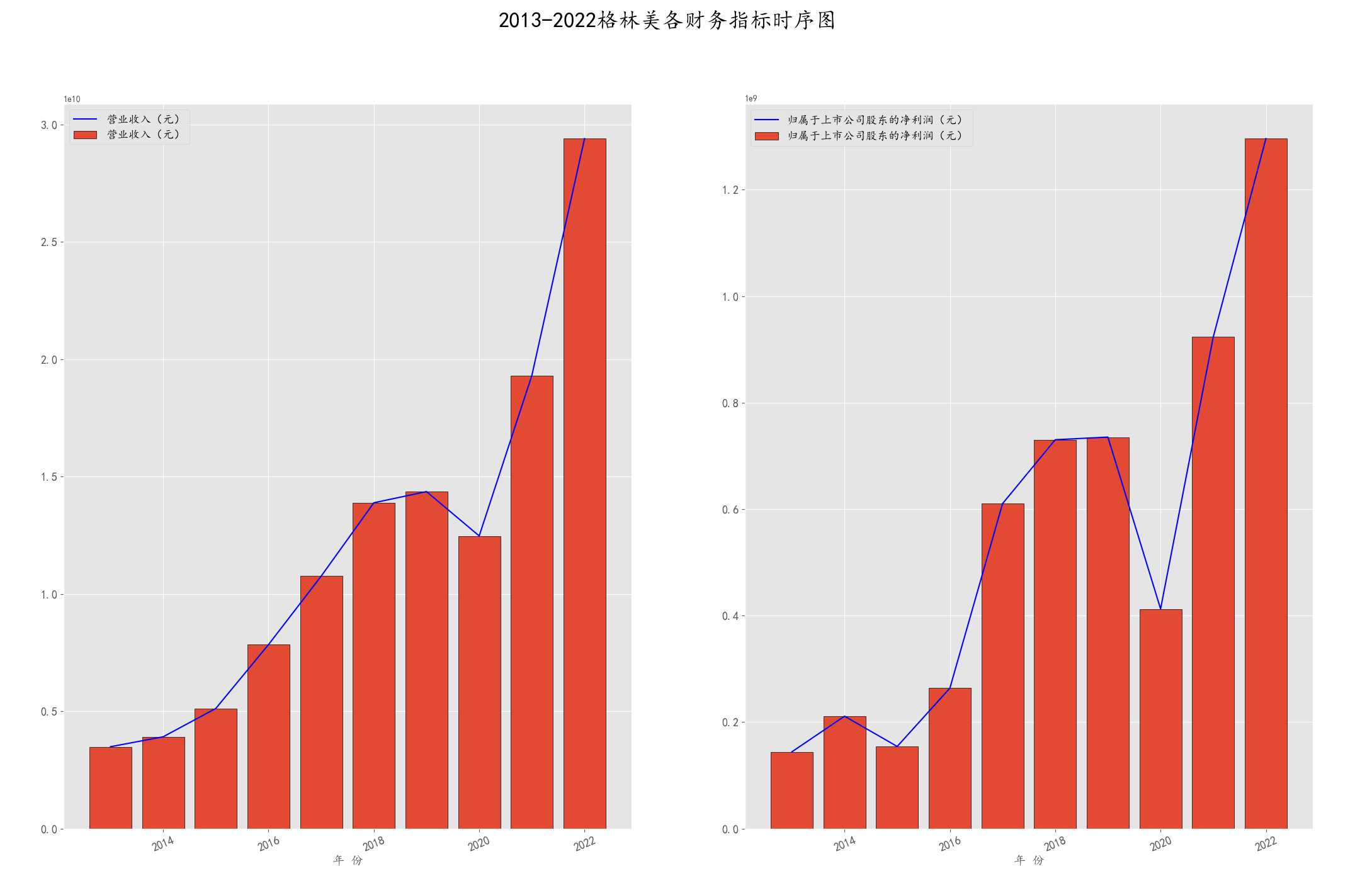
#以格林美为例,绘制各指标时间序列图
glm_data = pd.read_csv('D:\\Ana\\.spyder-py3\\nianbao\\src\\nianbao\\Series_data\\002340.csv',
encoding = 'ANSI',dtype = object,index_col = 0)
glm_data = glm_data.applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric)
#
plt.figure(figsize=(9,6))
for i in range(2):
plt.subplot(1,2, i+1)
plt.bar(glm_data.index, glm_data.iloc[:,i], edgecolor = 'black',label = glm_data.iloc[:,i].name)
plt.plot(glm_data.iloc[:,i],label = glm_data.iloc[:,i].name,color ='blue')
plt.xlabel(u'年 份',fontsize = 14)
plt.xticks(fontsize = 13,rotation = 22.5)
plt.yticks(fontsize = 13)
plt.legend(loc = 0,fontsize =13)
plt.suptitle('2013-2022格林美各财务指标时序图',fontsize = 25,fontweight='heavy')
plt.show()
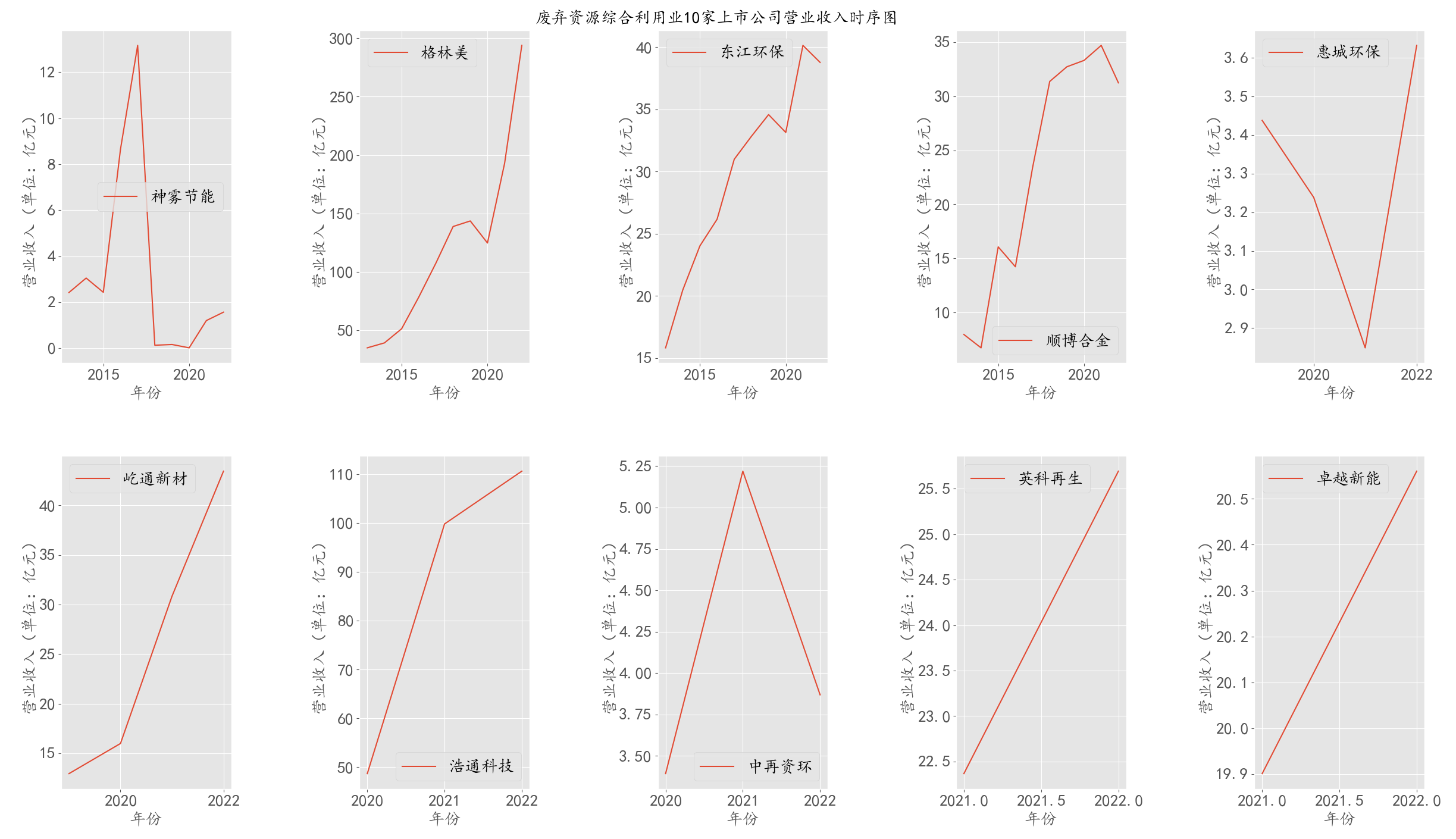
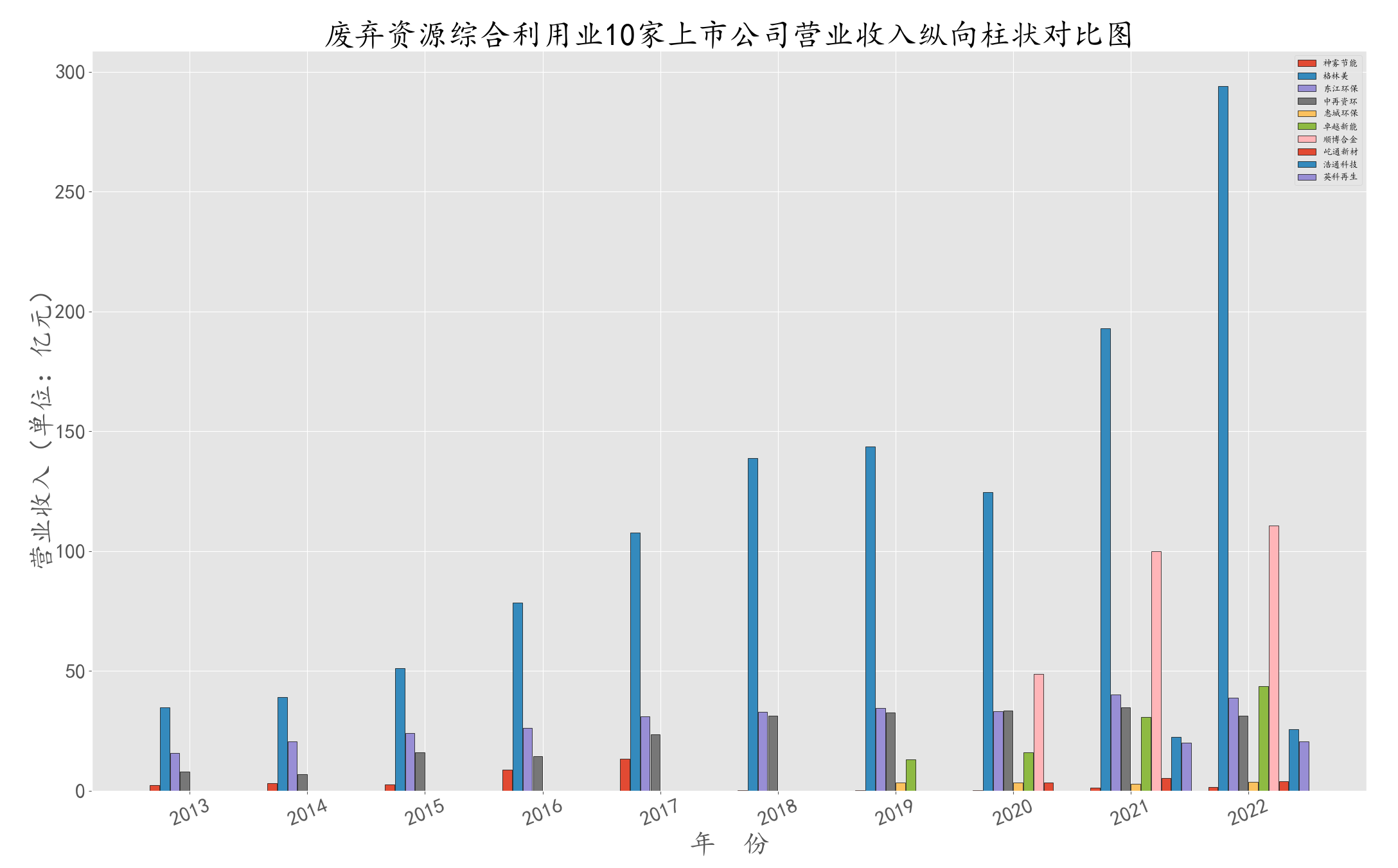
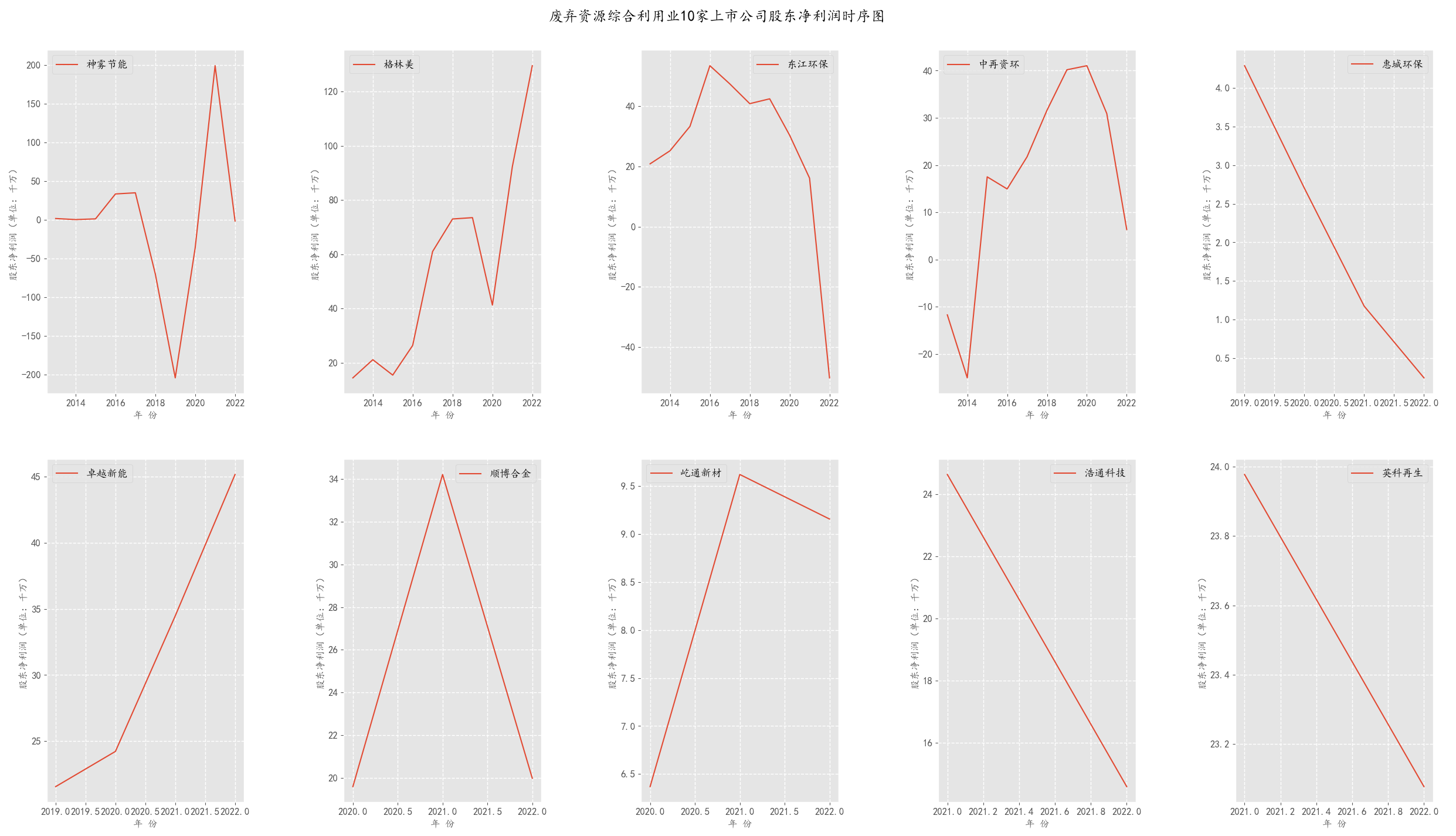
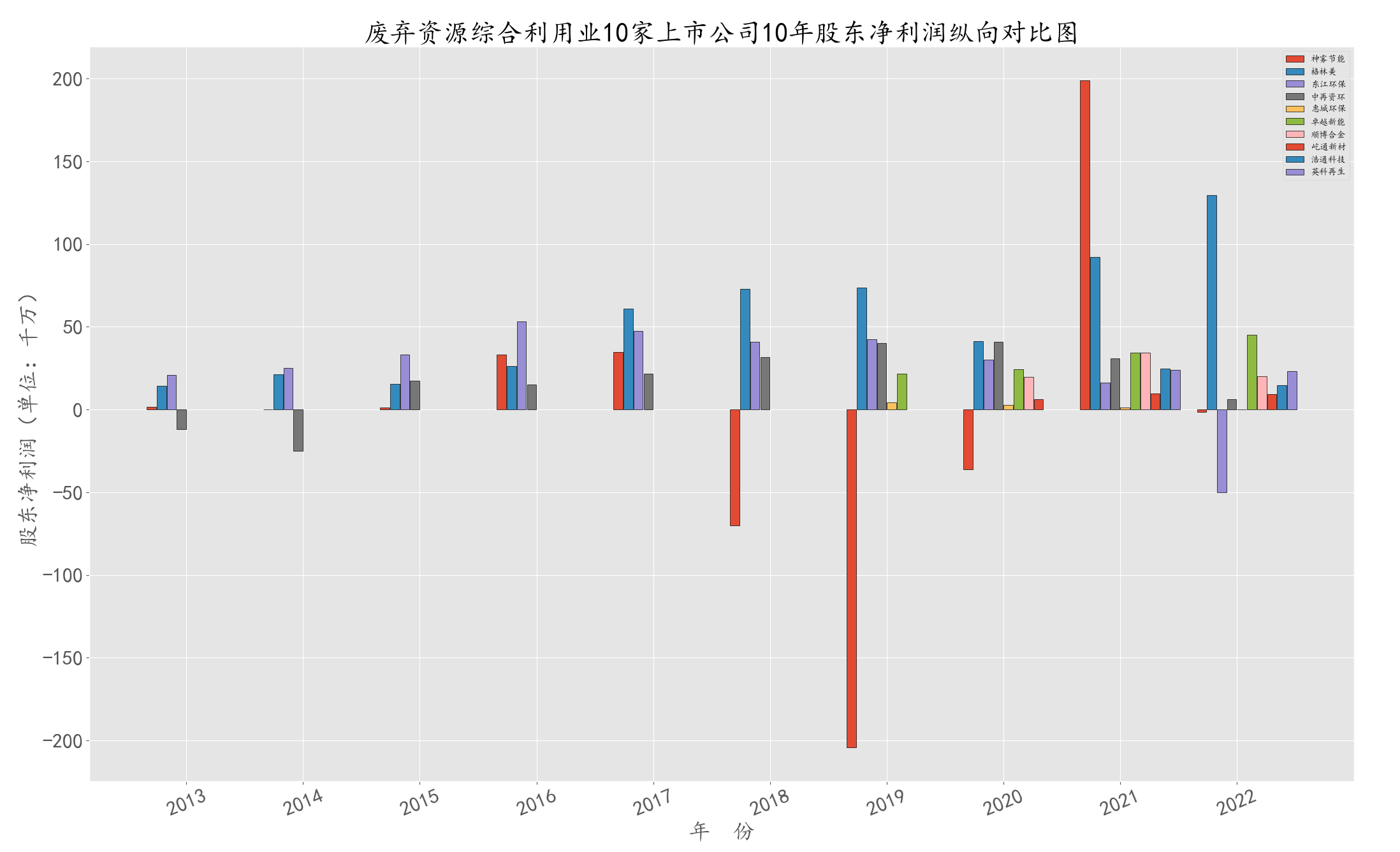
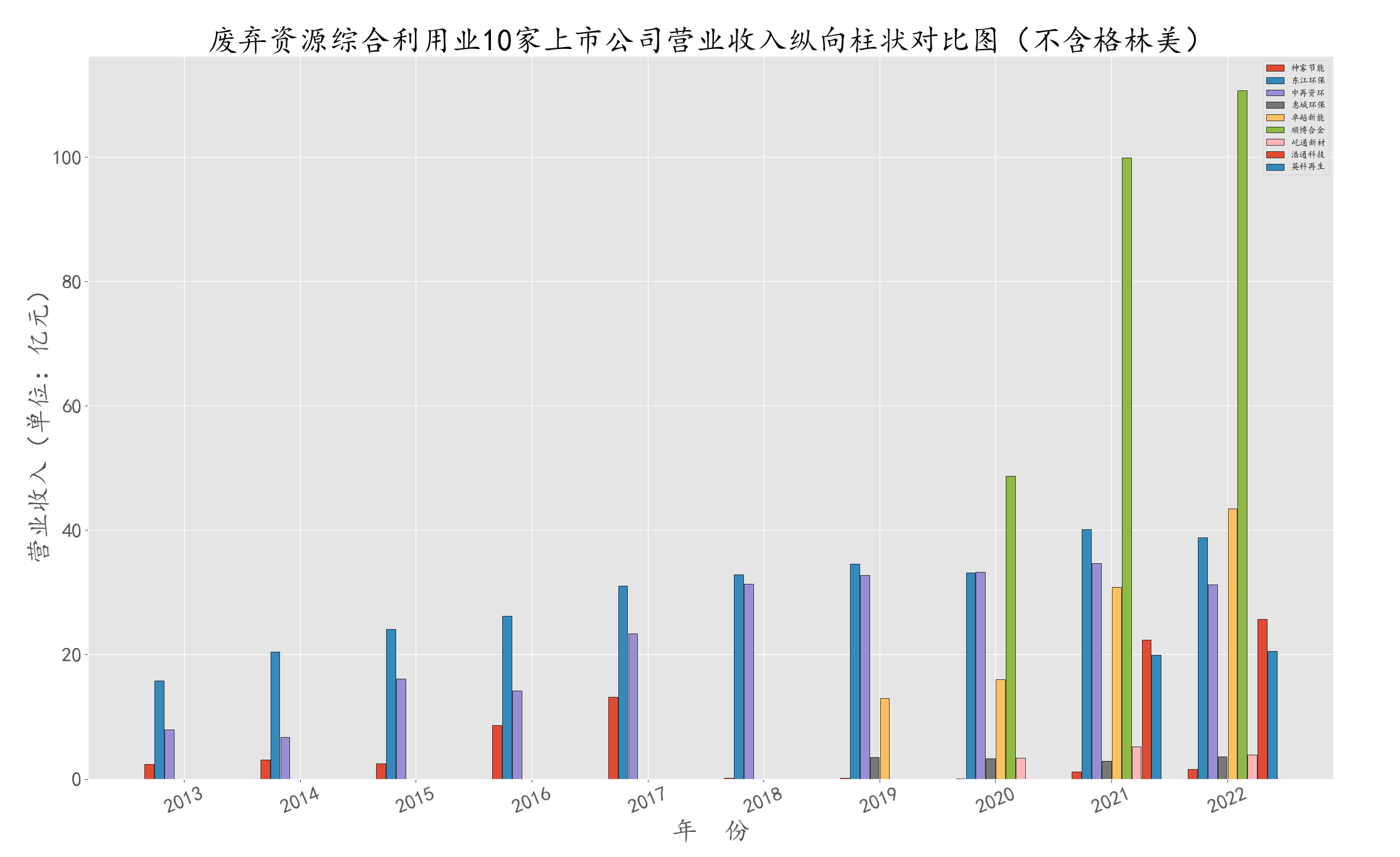
首先,由整体的横向对比图可知,“格林美”占废弃资源综合利用业的份额较大,其营业收入为百亿级,与其他公司差距较大。 另外,虽然从图中看出“顺博合金”在2022年也达到百亿级,但因其只有3年数据,未将其删去。
通过观察时序图可知,格林美占据还行业大量的份额,且营业收入和净利润几乎稳定增长。 其余几家公司所占市场份额较少,营业收入和净利润平稳缓慢上升,但是神雾节能的营业收入与净利润波段很大,呈现一定下滑趋势。
综上可知,在近几年中废弃资源综合利用业行业走势较好,营业收入整体呈现上升趋势,净利润大致也上升。观察两个指标可知格林美是该行业的强势企业,其他公司与之相比不够优秀。
从时间序列图上来看,在10家上市公司中,尽管上市时间有所不同,但如格林美、东江环保、屹通新材、浩通科技、英科再生、卓越新能的营业收入都呈现上升趋势,而神雾节能等波动幅度巨大。
归属于上市公司股东的净利润走势基本与营业收入成正相关,但在近两年却呈现相反的状态,波动幅度较大。
综合来看上,2021年到2022年废弃资源综合利用业的公司营业收入大部分呈现上升趋势,格林美的上涨势头尤其盛,但归属于股东的净利润除了该行业的领头企业格林美是增加以外,别的企业几乎都有所下降, 这种现象可能是因为该行业的领头企业具有一定的垄断地位,而其它企业则处于竞争激烈的局面中。领头企业由于掌握更多资源和更先进的技术,可以更好地适应市场需求并获得更高的市场份额,从而获得更多的利润和收入。 相比之下,其他企业则需要在竞争激烈的市场中为了保持市场份额而面临更高的成本和风险。这可能会导致它们利润出现下滑的趋势。
通过撰写本次实验报告,我获益良多。期间经历了无数次各种各样的报错,但是经过对错误进行分析,不懂的请教同学老师或上网查询,终是磕磕绊绊地完成了。此次作业的顺利完成离不开老师的指导和同学的帮助,在此表达感谢:
首先,感谢吴燕丰老师在课堂中的指导下,让我对python语言有了更深入的认识,对于爬虫、制作网页、利用正则表达式进行数据处理等技术有了更多的了解,对于代码的编写有了一定的进步。
其次,十分感谢张艺轩同学在代码方面对我的帮助,对于我的许多疑问进行了耐心的回答,帮助我解决了写代码时遇到的一些困难。另外,本次实验报告的页面布局也是应用了张艺轩同学的模板,十分感谢。
最后,此门课已经结束,但对于python的学习不应停止,希望自己能够利用这门课所学到的知识,继续努力地学习python语言编程,不断加深自己的理论与实践层面的认识,在未来能够更好的进行实践应用。