from time import sleep
from selenium.webdriver.common.by import By
from selenium import webdriver
options = webdriver.ChromeOptions()
out_path = r'E:\py_projects\data'
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': out_path}
options.add_experimental_option('prefs', prefs)
def spider(stock):
driver = webdriver.Chrome(options=options)
driver.maximize_window()
url = "https://www.szse.cn/disclosure/listed/notice/index.html"
driver.implicitly_wait(10)
driver.get(url)
sleep(5)
code = driver.find_element(By.XPATH, '//*[@id="input_code"]')
code.clear()
code.send_keys(stock)
driver.implicitly_wait(10)
driver.find_element(By.XPATH, '//*[@id="c-typeahead-menu-1"]').click()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="select_gonggao"]/div/div/a/span[1]').click()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="c-selectex-menus-3"]/li[1]/a').click()
sleep(1)
driver.find_element(By.XPATH, '//*[@id="query-btn"]').click()
sleep(1)
for page in range(1, 22):
driver.find_element(By.XPATH,
'//*[@id="disclosure-table"]/div/div[1]/div/table/tbody/tr[' + str(
page) + ']/td[3]/div/a/span[3]').click()
sleep(5)
driver.execute_script(f'window.scrollTo(0,200)')
print(stock + '/公司年报下载完成!')
sleep(1)
driver.quit()
# '000039', '000055'
# '000778', '000890', '000969', '002026', '002032', '002084', '002132', '002135 '
list = ['002132']
for li in list:
sipder(li)
import re
import pandas as pd
import fitz
import PyPDF2
import re
import pandas as pd
def search_keyword(data, keyword):
pattern = re.compile(keyword, re.IGNORECASE)
found_indexes = []
for index, item in enumerate(data):
if re.search(pattern, str(item)):
found_indexes.append(index)
return found_indexes
li_meigu = []
li_yingye = []
def read_pdf1(file_path1):
with open(file_path1, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
def meigu():
# 获取基本每股收益
page = pdf_reader.pages[6]
page_text = page.extract_text()
lines = page_text.split('\n')
ree = search_keyword(lines, '基本每股收益')
# print(lines[ree[0] + 1])
index = lines[ree[0] + 1]
value = index.split(" ")
filtered_data = [x for x in value if x is not None and x != '']
print('2022年每股收益', filtered_data[1])
print('2021年每股收益', filtered_data[2])
print('2020年每股收益', filtered_data[4])
# li_meigu.append(filtered_data[1])
# li_meigu.append(filtered_data[2])
# li_meigu.append(filtered_data[4])
def yingye():
# 获取营业收入
page = pdf_reader.pages[6]
page_text = page.extract_text()
lines = page_text.split('\n')
# first_line = lines[12]
ree = search_keyword(lines, '营业收入')
# print(ree)
index = lines[ree[0]]
value = index.split(" ")
print(value)
filtered_data = [x for x in value if x is not None and x != '']
print('2022年营业收入', filtered_data[1])
print('2021年营业收入', filtered_data[2])
print('2020年营业收入', filtered_data[4])
# li_yingye.append(filtered_data[1])
# li_yingye.append(filtered_data[2])
# li_yingye.append(filtered_data[4])
meigu()
yingye()
# file_path1 = "data/新兴铸管:2022年年度报告.PDF" # 替换为实际的PDF文件路径
# read_pdf1(file_path1)
def read_pdf2(file_path2):
with open(file_path2, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
def meigu():
# 获取基本每股收益
page = pdf_reader.pages[11]
page_text = page.extract_text()
lines = page_text.split('\n')
ree = search_keyword(lines, '归属于母公司股东的基本每股收益')
# print(lines[ree[0] + 1])
index = lines[ree[0] + 1]
value = index.split(" ")
filtered_data = [x for x in value if x is not None and x != '']
print('2017年每股收益', filtered_data[1])
print('2016年每股收益', filtered_data[2])
print('2015年每股收益', filtered_data[4])
li_meigu.append(filtered_data[1])
li_meigu.append(filtered_data[2])
li_meigu.append(filtered_data[4])
def yingye():
# 获取营业收入
page = pdf_reader.pages[10]
page_text = page.extract_text()
lines = page_text.split('\n')
ree = search_keyword(lines, '营业收入')
index = lines[ree[0]]
value = index.split(" ")
print(value)
filtered_data = [x for x in value if x is not None and x != '']
print('2017年营业收入', filtered_data[1])
print('2016年营业收入', filtered_data[2])
print('2015年营业收入', filtered_data[4])
li_yingye.append(filtered_data[1])
li_yingye.append(filtered_data[2])
li_yingye.append(filtered_data[4])
meigu()
yingye()
return li_meigu, li_yingye
# file_path2 = "data/新兴铸管:2019年年度报告.PDF" # 替换为实际的PDF文件路径
# read_pdf2(file_path2)
def file():
date = []
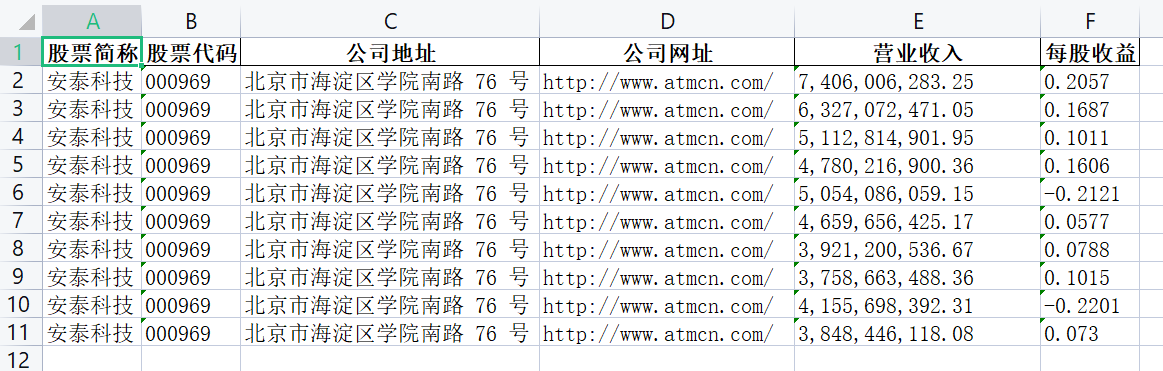
li = ['北京市海淀区学院南路 76 号', '000969', '安泰科技',
'http://www.atmcn.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['7,406,006,283.25', '6,327,072,471.05', '5,112,814,901.95', '4,780,216,900.36',
'5,054,086,059.15', '4,659,656,425.17', '3,921,200,536.67', '3,758,663,488.36',
'4,155,698,392.31', '3,848,446,118.08']
li_meigu1 = ['0.2057', '0.1687', '0.1011', '0.1606', '-0.2121',
'0.0577', '0.0788', '0.1015', '-0.2201',
'0.073']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
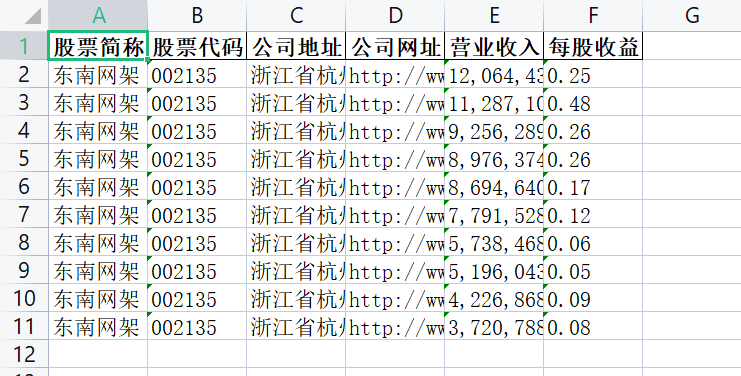
li = ['浙江省杭州市萧山区衙前镇衙前路 593 号', '002135', '东南网架',
'http://www.dongnanwangjia.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['12,064,434,647.04', '11,287,107,272.03', '9,256,289,931.66', '8,976,374,629.37',
'8,694,640,505.76', '7,791,528,910.40', '5,738,468,159.88', '5,196,043,096.55',
'4,226,868,489.63', '3,720,788,318.32']
li_meigu1 = ['0.25', '0.48', '0.26', '0.26', '0.17',
'0.12', '0.06', '0.05', '0.09',
'0.08']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['江苏省江阴市澄江中路 165 号', '000890', '法尔胜',
'https://www.chinafasten.cn/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['677,575,109.69', '667,468,092.57', '467,058,989.47', '1,003,609,325.63',
'1,698,089,206.54', '2,004,295,820.98', '1,906,735,239.66', '1,426,542,116.44',
'1,552,094,711.88', '1,566,444,923.84']
li_meigu1 = ['-0.03 ', '0.10', '0.04', '-2.05', '-0.38',
'0.38', '0.37', '0.0146', '0.0137',
'0.0169']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['深圳市南山区龙珠四路 2 号方大城 T1 栋 39 层', '000055', '方大集团',
'http://www.fangda.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['3,846,975,948.44', '3,557,724,397.54', '3,000,191,773.63', '3,005,749,558.66',
'3,048,680,152.06', '2,947,470,813.58', '4,203,866,173.72', '2,550,467,494.78',
'1,938,324,435.51', '1,747,620,845.74']
li_meigu1 = ['0.26', '0.21', '0.35', '0.310', '1.91',
'0.97', '0.91', '0.14', '0.13',
'0.11']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['广州市番禺区沙头街禺山西路 363 号联邦工业城内', '002084', '海鸥住工',
'http://www.seagullgroup.cn/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['3,294,840,644.48', '4,125,639,722.35', '3,340,050,002.51', '2,569,424,298.56',
'2,224,695,145.25', '2,070,648,154.20', '1,786,562,163.94', '1,714,909,434.79',
'1,649,972,494.54', '1,675,669,916.22']
li_meigu1 = ['0.0734', '0.1319', '0.2830', '0.2634', '0.0828',
'0.1816', '0.1862', '0.1102', '0.1013',
'0.1']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['河南省巩义市恒星工业园区', '002132', '恒星科技',
'https://www.hengxingchinese.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['4,417,416,588.93 ', '3,396,281,106.63', '2,832,759,589.33', '3,386,147,599.09',
'3,014,331,960.05', '3,046,175,236.90', '2,064,455,574.55', '1,735,798,925.07',
'1,876,574,822.39', '1,749,087,962.71']
li_meigu1 = ['0.14', '0.11', '0.10', '0.07', '-0.11 ',
'0.05', '0.09', '0.04', '0.08',
'0.06']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['山东省威海临港经济技术开发区苘山镇中韩路 2 号', '002026', '山东威达',
'http://www.weidapeacock.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['2,467,176,580.78', '3,309,710,388.26', '2,165,052,831.80', '1,575,109,439.78',
'1,661,996,645.79', '1,469,380,404.82', '1,180,581,447.47', '837,445,261.00',
'837,445,261.00', '718,220,284.14']
li_meigu1 = ['0.47', '0.89', '0.60', '-0.28', '0.37',
'0.30', '0.26', '0.25', '0.34',
'0.2011']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
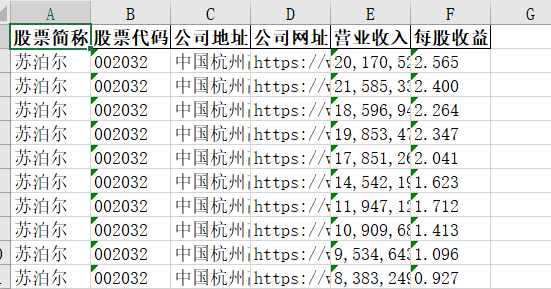
li = ['中国杭州高新技术产业区江晖路 1772 号苏泊尔大厦 15 层', '002032', '苏泊尔', 'https://www.supor.com.cn/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['20,170,527,516.66', '21,585,331,407.47', '18,596,944,289.02', '19,853,477,882.97',
'17,851,264,801.72', '14,542,193,769.70', '11,947,123,201.12', '10,909,686,625.90',
'9,534,643,945.84', '8,383,249,626.61']
li_meigu1 = ['2.565', '2.400', '2.264', '2.347', '2.041',
'1.623', '1.712', '1.413', '1.096',
'0.927']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
def file():
date = []
li = ['河北省武安市上洛阳村北(2672 厂区)', '000778', '新兴铸管', 'https://www.xinxing-pipes.com/']
for i in range(2013, 2023):
date.append(i)
date.reverse()
li_yingye1 = ['47,760,058,256.98', '53,301,106,059.49', '42,960,921,062.41', '40,889,707,108.27',
'40,547,120,305.78', '41,266,372,331.97', '52,159,883,504.68', '50,030,639,751.47',
'60,793,273,381.55', '63,014,443,991.26']
li_meigu1 = ['0.4200', '0.5028', '0.4541', '0.3751', '0.5265', '0.2779', '0.1208', '0.1646', '0.2292', '0.5263']
# print(date)
# print(li_meigu, li_yingye)
data = {
'股票简称': li[2],
'股票代码': li[1],
'公司地址': li[0],
'公司网址': li[3],
'营业收入': li_yingye1,
'每股收益': li_meigu1
}
df = pd.DataFrame(data, columns=['股票简称', '股票代码', '公司地址', '公司网址', '营业收入', '每股收益'])
df.to_excel('表格/' + li[2] + '.xlsx', index=False, encoding='utf-8')
file()
import pandas as pd # 导入数据统计模块
import matplotlib # 导入图表模块
import matplotlib.pyplot as plt # 导入绘图模块
import numpy as np
# 避免中文乱码
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
matplotlib.rcParams['axes.unicode_minus'] = False # 设置正常显示字符,使用rc配置文件来自定义
date = []
for i in range(2013, 2023):
date.append(i)
date.reverse()
# comInfoList = []
name = ['中集集团', '新兴铸管', '苏泊尔', '山东威达', '恒星科技', '海鸥住工', '方大集团', '法尔胜', '东南网架', '安泰科技']
def zhexian_yingye():
plt.figure()
for i in range(len(name)):
data = pd.read_excel('表格/' + str(name[i]) + '.xlsx') # 读取csv数据
li = []
df_yingye = data['营业收入']
for j in range(0, 10):
y = round(float(df_yingye[j].replace(',', '')) / 1000000, 2)
li.append(y)
# df_meigu = data['每股收益']
plt.plot(date, li, label=name[i])
# 添加图例
plt.legend()
# 设置标题和轴标签
plt.title('2013-2020年营业收入折线图')
plt.xlabel('年份')
plt.ylabel('营业收入(百万元)')
plt.show()
def zhexian_meigu():
plt.figure()
for i in range(len(name)):
data = pd.read_excel('表格/' + str(name[i]) + '.xlsx') # 读取csv数据
li = []
df_yingye = data['每股收益']
# for j in range(0, 10):
# y = round(float(df_yingye[j].replace(',', '')) / 1000000, 2)
# li.append(y)
plt.plot(date, df_yingye, label=name[i])
# 添加图例
plt.legend()
# 设置标题和轴标签
plt.title('2013-2020年每股收益折线图')
plt.xlabel('年份')
plt.ylabel('元')
plt.show()
def bar_meigu():
categories = date
li = []
for i in range(len(name)):
data = pd.read_excel('表格/' + str(name[i]) + '.xlsx') # 读取csv数据
df_yingye = data['每股收益']
li.append(df_yingye)
# print(len(li))
values = []
for j in range(len(li)):
values.append(li[j])
# 设置柱状图的宽度
bar_width = 0.1
# 创建一个新的图形
plt.figure()
# 计算每个柱状图的位置
x = np.arange(len(categories))
# 循环绘制十个柱状图
for i in range(len(values)):
plt.bar(x + i * bar_width, values[i], width=bar_width, label=name[i])
# 设置x轴标签和刻度
plt.xlabel('年份')
plt.xticks(x + (len(values) / 2 - 0.5) * bar_width, categories)
# 设置y轴标签
plt.ylabel('元')
# 添加图例
plt.legend()
# 设置标题
plt.title('每股收益柱状图')
# 显示图形
plt.show()
def bar_yingye():
categories = date
li = []
for i in range(len(name)):
data = pd.read_excel('表格/' + str(name[i]) + '.xlsx') # 读取csv数据
df_yingye = data['营业收入']
lt = []
for j in range(0, 10):
y = round(float(df_yingye[j].replace(',', '')) / 1000000, 2)
lt.append(y)
li.append(lt)
values = []
for j in range(len(li)):
values.append(li[j])
# 设置柱状图的宽度
bar_width = 0.1
# 创建一个新的图形
plt.figure()
# 计算每个柱状图的位置
x = np.arange(len(categories))
# 循环绘制十个柱状图
for i in range(len(values)):
plt.bar(x + i * bar_width, values[i], width=bar_width, label=name[i])
# 设置x轴标签和刻度
plt.xlabel('年份')
plt.xticks(x + (len(values) / 2 - 0.5) * bar_width, categories)
# 设置y轴标签
plt.ylabel('百万')
# 添加图例
plt.legend()
# 设置标题
plt.title('营业收益柱状图')
# 显示图形
plt.show()
# bar_yingye()
# bar_meigu()
zhexian_meigu()
zhexian_yingye()
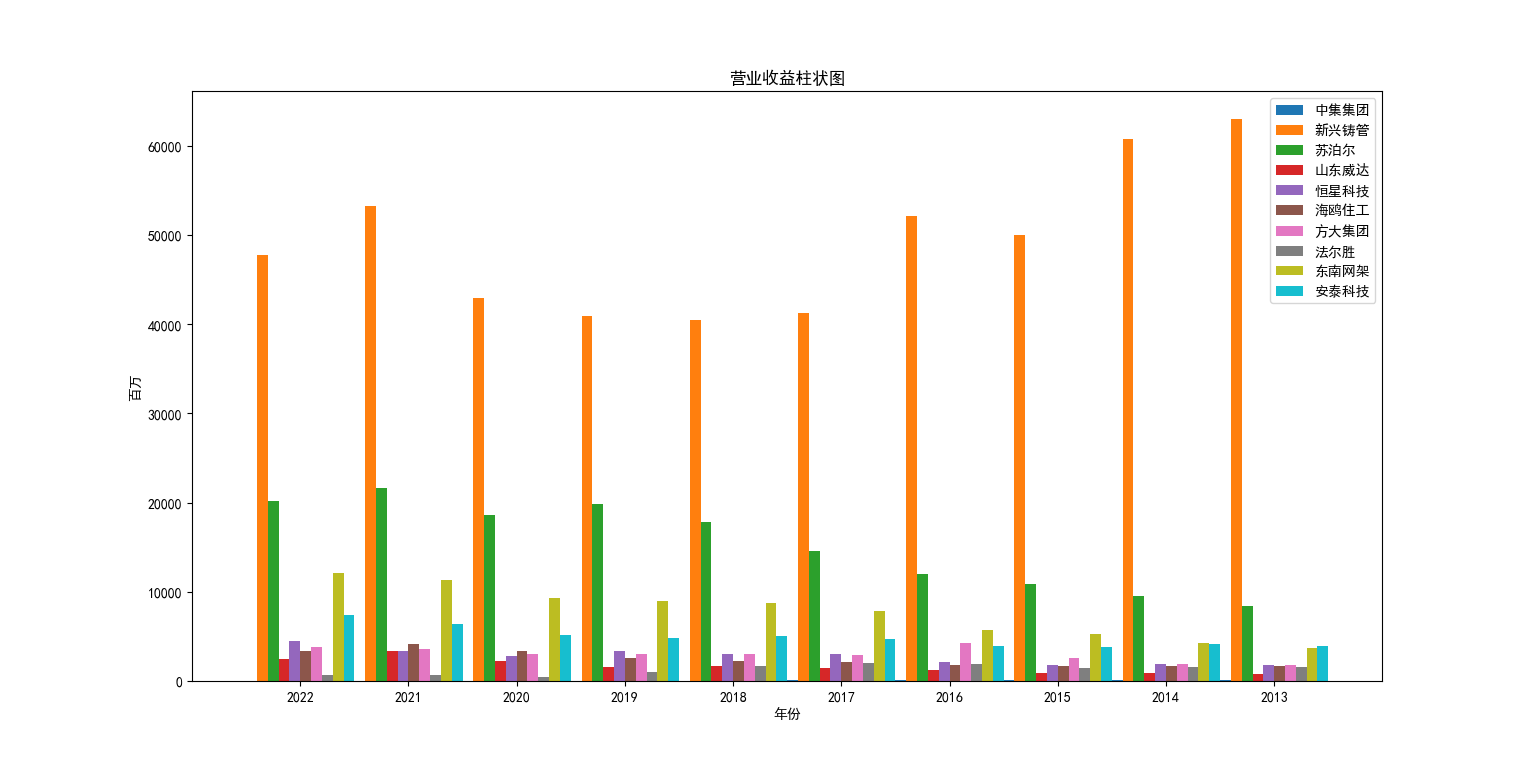
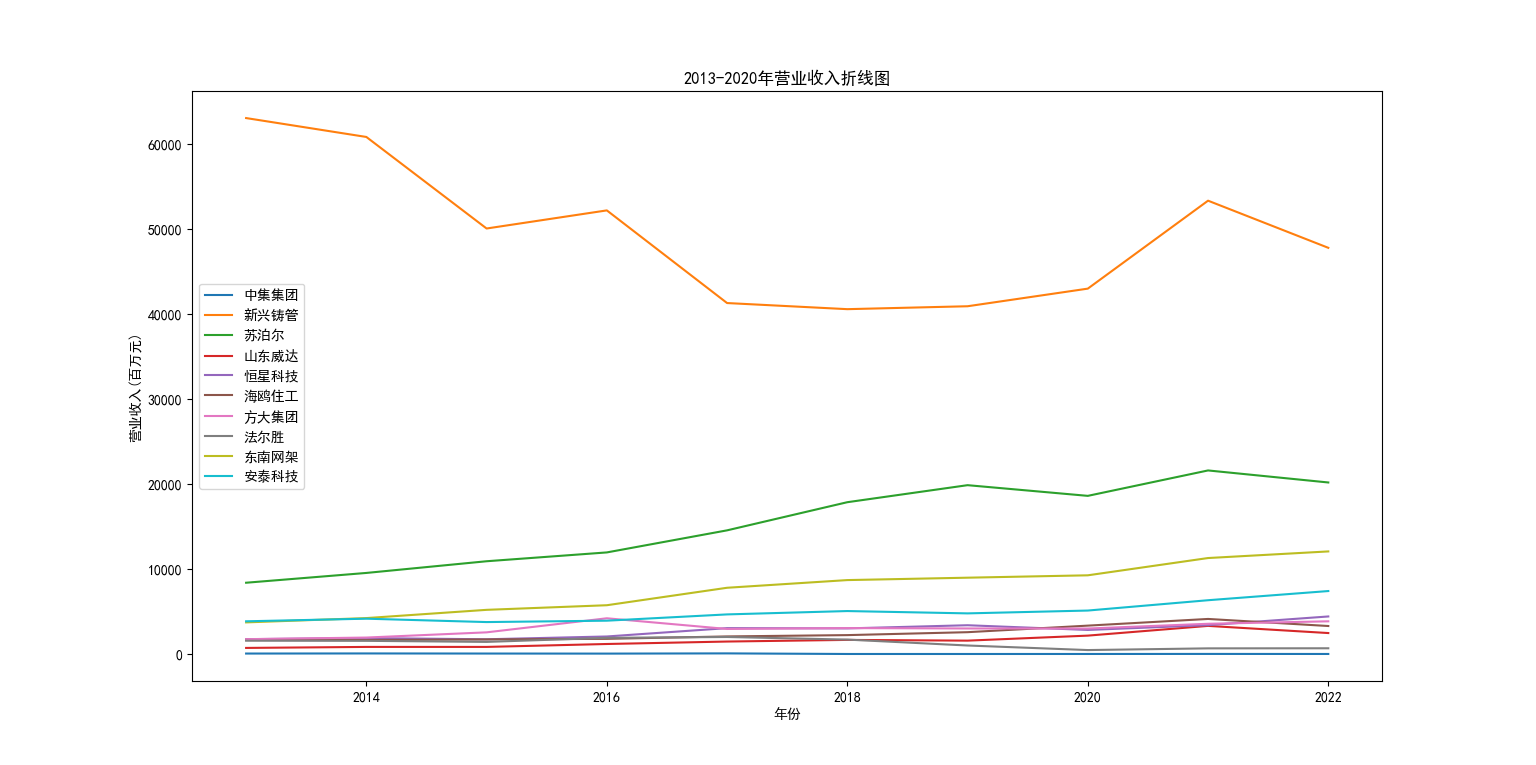
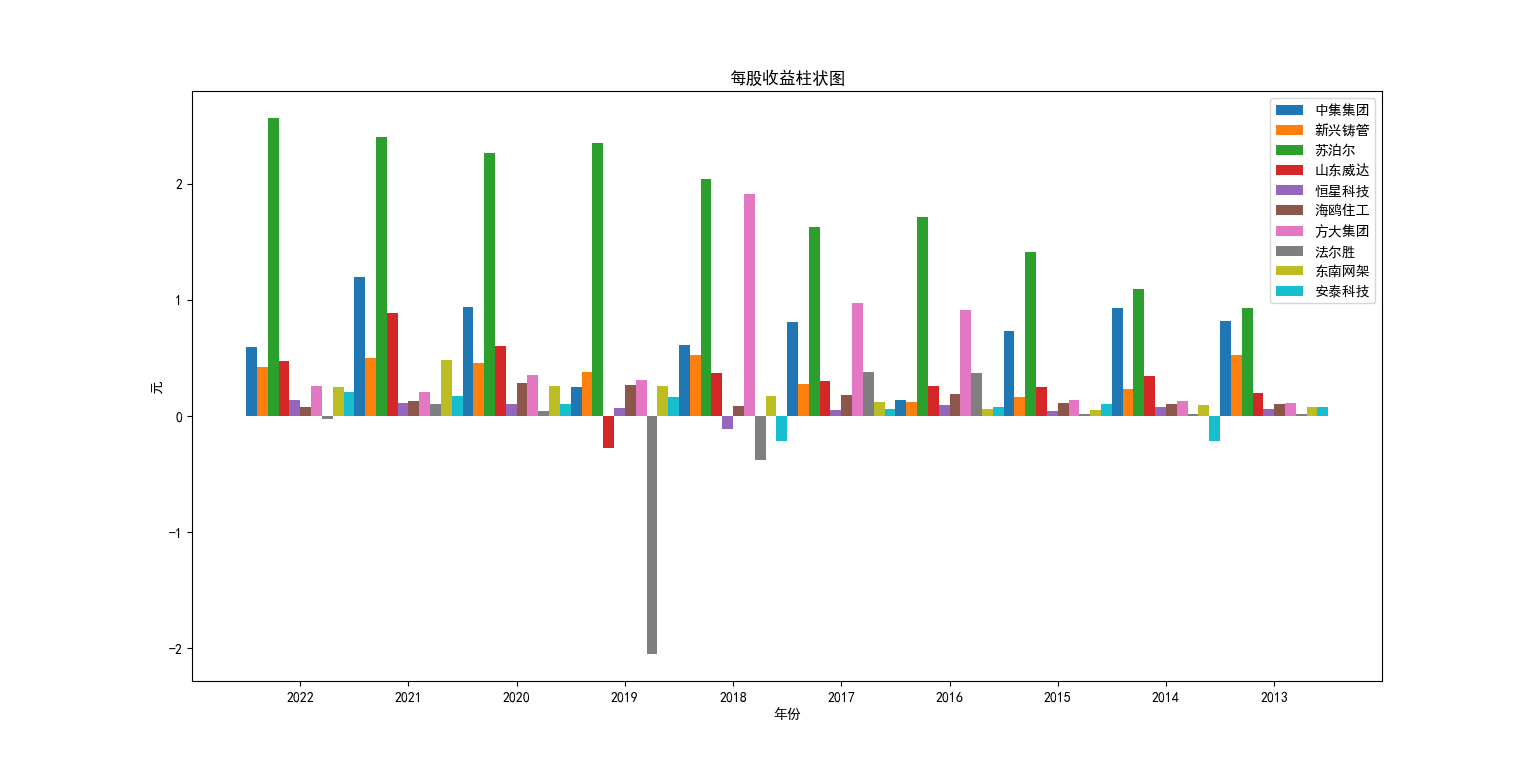
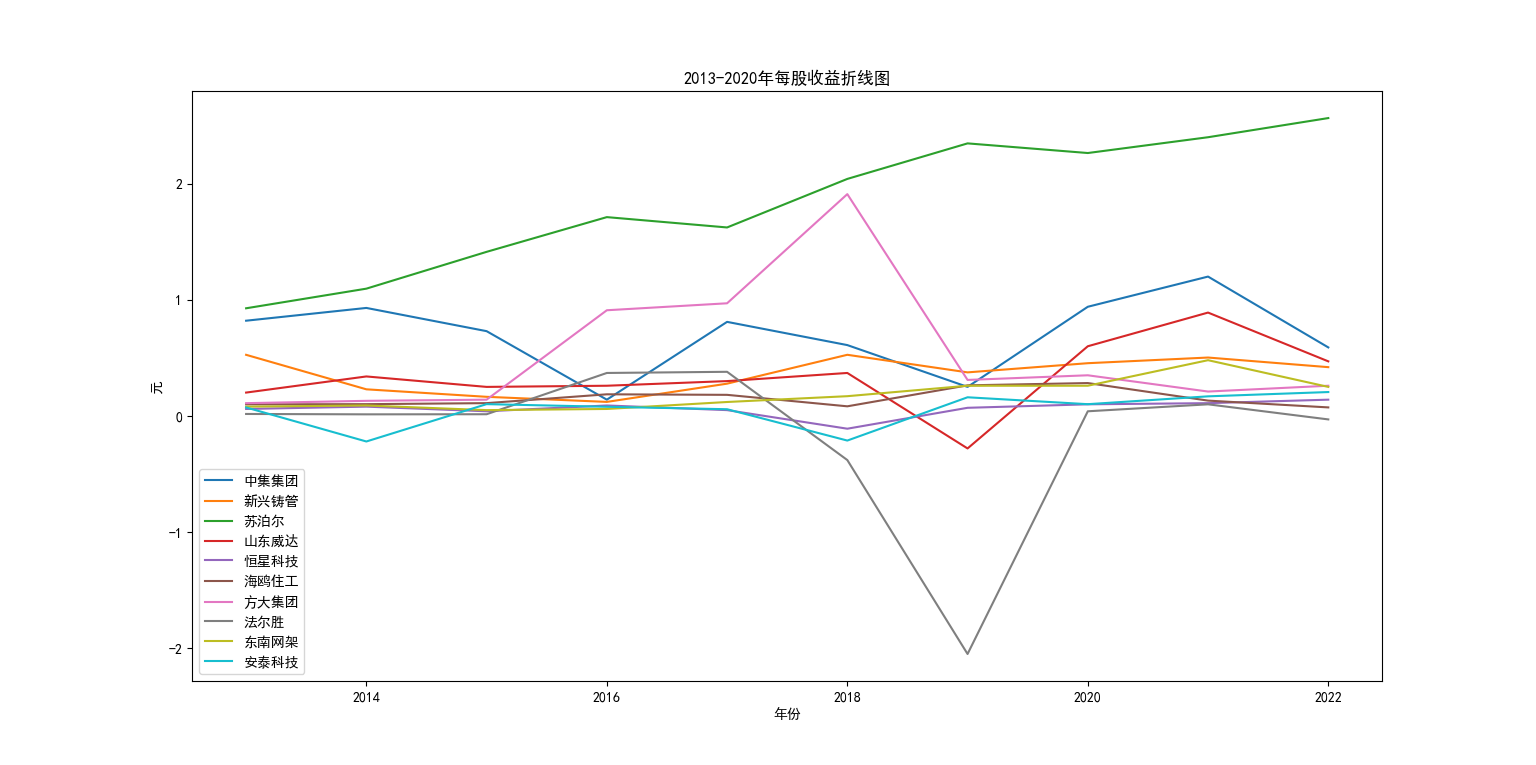
从营业收益柱状图来看,新兴铸管以绝对的优势领先其余九家企业,甚至是于排在第二的苏泊尔的几倍甚至于10倍营业收入,势头较为明显的还有苏泊尔和东南网架,其余几家差异较小。从营业收益折线图来看,新兴铸管虽然遥遥领先,但10年来呈现向下的趋势,纵观其余9家企业,虽然营业收入势头不明显,但在10年大都呈现向上的趋势。 从每股收益的柱状图分析,与营业收入呈相反趋势,苏泊尔跃升首位,与其他公司差异显著。并且可以明显看出新兴铸管的每股收益相对其他九家企业较低。方大集团在2017年以前的每股收益不断爬升,并在2018年达到峰值但在2018年后每股收益不断下降。从每股收益的折线图来看,苏泊尔在的每股收益在10年来不断升高。中集集团和法尔胜10年来波动性较大分别于2018年和2019年呈现较为剧烈的波动。 综合以上分析,新兴筹管的营业收入数倍于其他企业,但每股收益走势平平,可以推测其留存收益较高,注重公司的长远发展。特征较为明显的苏泊尔,无论是营业收入还是每股收益,表现都优于大多企业,发展公司的同时提高股东收益。除了方大集团与法尔胜波动性较大之外,其余企业10年来数值上的表现呈现相同的走势。
此次大作业可以说是大学以来难度最高的一次作业,但是老师上课非常细心并且会认真解答每一个有疑惑的同学,上课虽然是三节课,但是每次都感觉时光飞逝,同时每个学到的知识点都是很有用的干货。入学以来第一次如此深入的学习python知识并实际操作。了解如何从深交所/上交所获取需要的信息,如何用函数爬取需要的数据,可以说是开启了爬虫领域的大门。金融、计算机、数学,三者密不可分,这门课的学习让我通过实际操作,接触到书本上学到过的公式和会计分录,按照书本学和实际操作处理有很大不同,贴近实际的操作更能感受到数据的走势与变化。很幸运选了这门课,也很感谢吴老师的耐心教学!