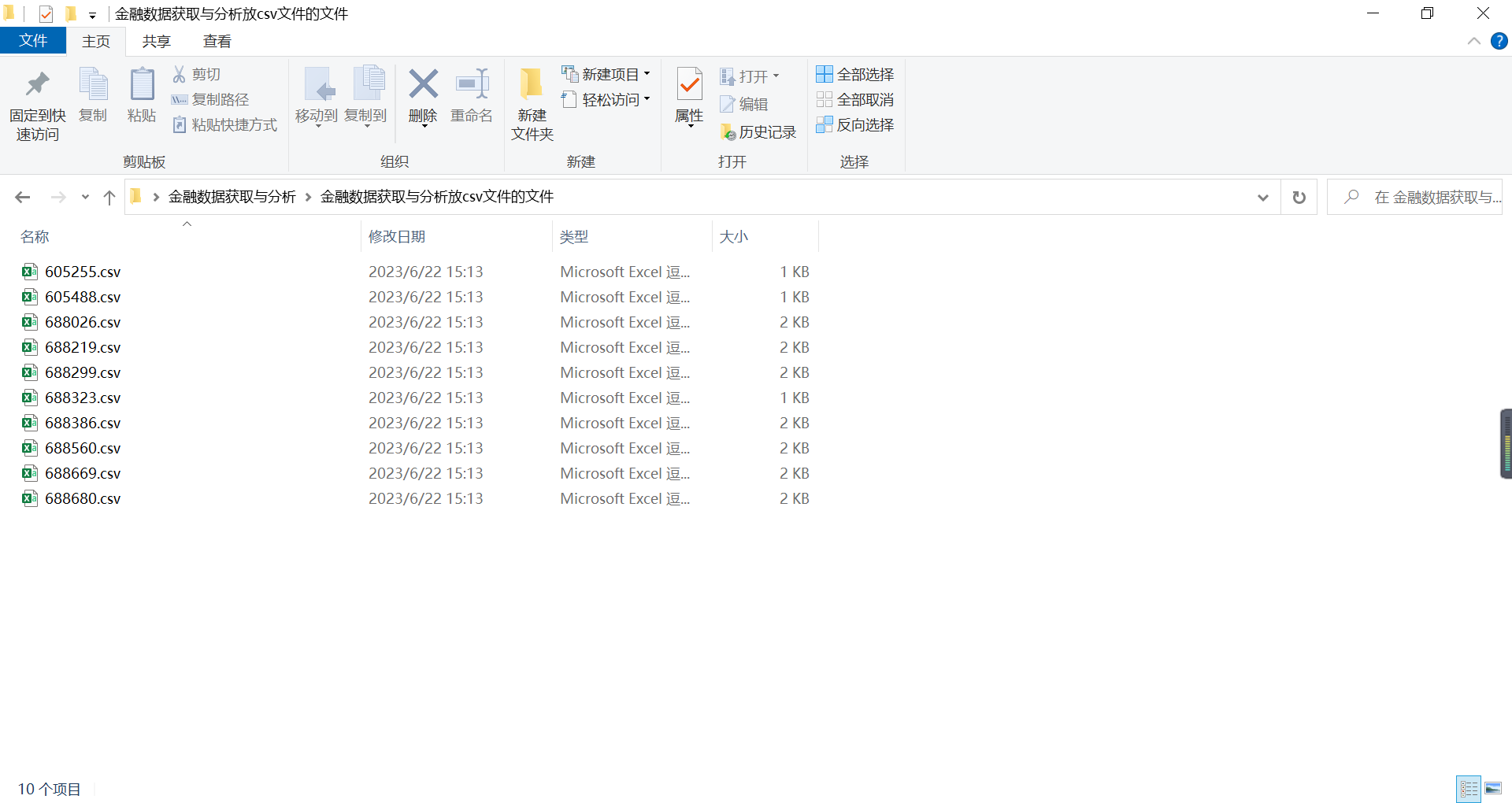
605255天普股份,605488福莱新材,688026洁特生物,688219会通股份,688299长阳科技,688323瑞华泰,688386泛亚微透,688560明冠新材,688669聚石化学,688680海优新材
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
def get_table_sse(code):
browser = webdriver.Edge() #启动浏览器驱动
browser.set_window_size(1550,830) #实现全屏
url='http://www.sse.com.cn/disclosure/listedinfo/regular/'#上证交易所主页网址
browser.get(url) #打开上证交易所主页
time.sleep(3) #设置等待网页加载时间,否则可能无法获取数据
browser.find_element(By.ID, "inputCode").click() # ID定位到搜索框
browser.find_element(By.ID, "inputCode").send_keys(code) #输入股票代码
time.sleep(3)
selector=".sse_outerItem:nth-child(4) .filter-option-inner-inner"
browser.find_element(By.CSS_SELECTOR, selector).click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(3)
selector="body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, selector)
table_html=element.get_attribute('innerHTML')
fname=f'D:/数据处理大作业/{code}.html'
f=open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
#执行循环,将10家公司的年报链接下载下来
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
get_table_sse(code)
def get_data(tr):
'''
定义一个函数提取网页内我们所需要的信息:包括代码、公司名字、年报链接、年报名称、发布日期
'''
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_table(table_html):
'''
定义一个函数将我们所需要的信息放进二维数据表DateFrame中
----------
table_html : 前面通过selenium所提取出来的所需信息的网页文件
-------
'''
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
for code in codes:
f = open(f'D:/数据处理大作业/{code}.html', encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
df.to_csv(f'D:/数据处理大作业/DateFrame/{code}.csv')
# codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
# list_df=[]
# for code in codes:
# locals()[f'df_{code}']=pd.read_csv(f'D:/数据处理大作业/DateFrame/{code}.csv')
#我们发现,下载的上市公司年报里混有年报摘要,此时需要将年报摘要删除,保留年报
def filter_links(df,words):
#删除包含关键词的列表
----------
df : DateFrame
words : 需摘除的无关链接中年报标题所含的关键字
-------
df1 : DateFrame
d = []
for index, row in df.iterrows(): #实现遍历操作
title = row[4]
for word in words:
a = re.search(word, title)
if a != None:
d.append(index) #将包含有不需要的年报标题关键字的链接对应索引加入d
df1 = df.drop(d).reset_index(drop = True)
return df1
words=['摘要','财务报表','专项审核说明','鉴证报告']
df1=filter_links(df,words) '''
def filter_links(words,df,include=True):
定义一个筛选保留年报链接的函数
----------
words : 保留或删除包含关键词列表
df : DataFrame
include : TYPE, optional(kepp or exclude), The default is False.
-------
'''
ls=[]
for word in words:
if include:
ls.append([word in f for f in df['title']])
else:
ls.append([word not in f for f in df['title']])
index=[]
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag=flag or ls[c][r]
else:
flag=flag and ls[c][r]
index.append(flag)
df2=df[index]
return(df2)
# words=['摘要']
# df2=filter_links(words,df,include=False).reset_index(drop=True)
from datetime import datetime
def filter_nb_10y(df):
'''
定义一个筛选出近十年来上市公司年报链接的函数
----------
start : 开始时间
end : 结束时间
df : DateFrame
-------
'''
dt_now=datetime.now()
current_year=dt_now.year
start=f'{current_year-9}-01-01'
end=f'{current_year}-12-31'
date=df['date']
v=[d >= start and d <= end for d in date]
df_new=df[v]
return(df_new)
import requests
def download_pdf(href,code,year):
'''
下载单份年报,自动命名保存
----------
href : 下载链接
code : 证券代码
year : 年报年份
-------
'''
r=requests.get(href,allow_redirects=True)
fname=f'D:/数据处理大作业/pdf/{code}_{year}.pdf'
f=open(fname,'wb')
f.write(r.content)
f.close()
r.close()
def download_pdfs(hrefs,code,years):
for i in range(len(hrefs)):
href=hrefs[i]
year=years[i]
download_pdf(href,code,year)
time.sleep(30)
return()
def download_pdfs_codes(list_hrefs,codes,list_years):
for i in range(len(list_hrefs)):
hrefs=list_hrefs[i]
years=list_years[i]
code=codes[i]
download_pdfs(hrefs,code,years)
return()
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
df=pd.read_csv(f'D:/数据处理大作业/DateFrame/{code}.csv')
#通过观察csv文件中'title'列发现不属于年报的pdf文件中含有以下关键字
words=['摘要','财务报表','修订版','关于','述职报告','专项报告','财务决算报告','专项审计说明']
df1=filter_links(words,df,include=False).reset_index(drop=True) #筛选年报
'''所分配到的10家上市公司上市时间均未达到10年,所以不需要对年报时间进行筛选,如有超过
10年的年报,则需用前文的filter_nb_10y(df)函数进行筛选'''
#在df1中加入一列年份,便于提取years,首先将df1中的'date'列提取出前4个字符,获取年份列
#并加入df1中,但是上市公司是第二年初发布上一年的年报,所以需要对year列同时减去1年
def extractFirst6(s):
return s[:4]
df1['year']=df1['date'].apply(lambda s:extractFirst6(s)) #使用lambda函数式编程实现
df1['year']= df1['year'].astype('int') #将字符转为数值
df1['year'] = df1['year'].map(lambda x: x-1)
hrefs=df1['href']
years=df1['year']
download_pdfs(hrefs,code,years)
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首尾页码
start_pageno=0
end_pageno=len(doc)-1
#
lb,ub=bounds
#获取左界页码
for n in range(len(doc)):
page=doc[n]
txt=page.get_text()
if lb in txt:
start_pageno=n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno=n
break
#获取小范围内字符串
txt=''
for n in range(start_pageno,end_pageno+1):
page=doc[n]
txt += page.get_text()
return(txt)
#获取表头
def get_th_span(txt):
nianfen='(20\d\d|199\d)\s*?年' #2016和年之间是空格,而2016年和2015年之间是空格
s=f'{nianfen}\s*{nianfen}.*?{nianfen}'
p=re.compile(s,re.DOTALL) #re.DOTALL指.遇到换行符也是可以的
matchobj=p.search(txt)
#
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2) == 1) and (int(year2)-int(year3) == 1)
#
while (not flag):
matchobj=p.search(txt[end:])
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=(int(year1)-int(year2) == 1)
flag=flag and (int(year2)-int(year3) ==1)
return(matchobj.span())
#获取表格边界
def get_bounds(txt):
th_span_1st=get_th_span(txt)
end=th_span_1st[1]
th_span_2nd=get_th_span(txt[end:])
th_span_2nd=(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'): #如果最后一个不是数字
e=e-1
return(s,e+1)
#获取‘营业收入’和‘归属于上市公司股\n东的净利润’
def get_account_data(account,txt):
p_txt='%s\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)' % account #%s是占位符,用‘account’替换,\D是非数字,\d{1,3}是数字1或2或3个,*可重复,?非贪婪,()内是所要的数字,小数点后\d+表示小数点后至少一位数字
p=re.compile(p_txt)
matchobj=p.search(txt)
amt=matchobj.group(1)
return(amt)
#获取整张表格
# subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
def get_keywords(txt):
p=re.compile(r's\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)')
keywords=p.findall(txt)
return(keywords)
def parse_key_fin_data(subtxt,keywords):
# keywords=['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss=[]
s=0
for kw in keywords:
n=subtxt.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtxt))
data=[]
p=re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2=re.compile('\s')
for n in range(len(ss)-1):
s=ss[n]
e=ss[n+1]
line=subtxt[s:e]
#获取可能换行的账户名称
matchobj=p.search(line)
account_name=p2.sub('',matchobj.group())
#获取三年数据
amnts=line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
'''通过遍历10家上市公司年报文件所在的文件夹,将各年份年报中我们所需的信息提取出来
放入创建的表格中并存为csv文件,只需将下方代码中的股票代码改成其他股票代码即可实现
10家信息的获取'''
import re
import glob
###比如股票代码为605255的公司
# 文件所在文件夹
filepath =r'C:/Users/hp/Desktop/金融数据获取与分析/放pdf文件的文件/605255'
files = glob.glob(filepath+r'\*.pdf')
#创建一个空的DataFrame存放营业收入和归属于上市公司股东的净利润
df_605255=pd.DataFrame(pd.DataFrame(index=range(2019,2023),
columns=['营业收入','归属于上市公司股东的净利润']))
#遍历文件提取数据
for file in files:
doc=fitz.open(file)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
data=parse_key_fin_data(subtxt, keywords)
R=float(data[0][1].replace(',','')) #转化为浮点数并去掉分隔号“,”
Pro=float(data[1][1].replace(',',''))
text=''
for i in range(len(doc)): #读取每份年报内容
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
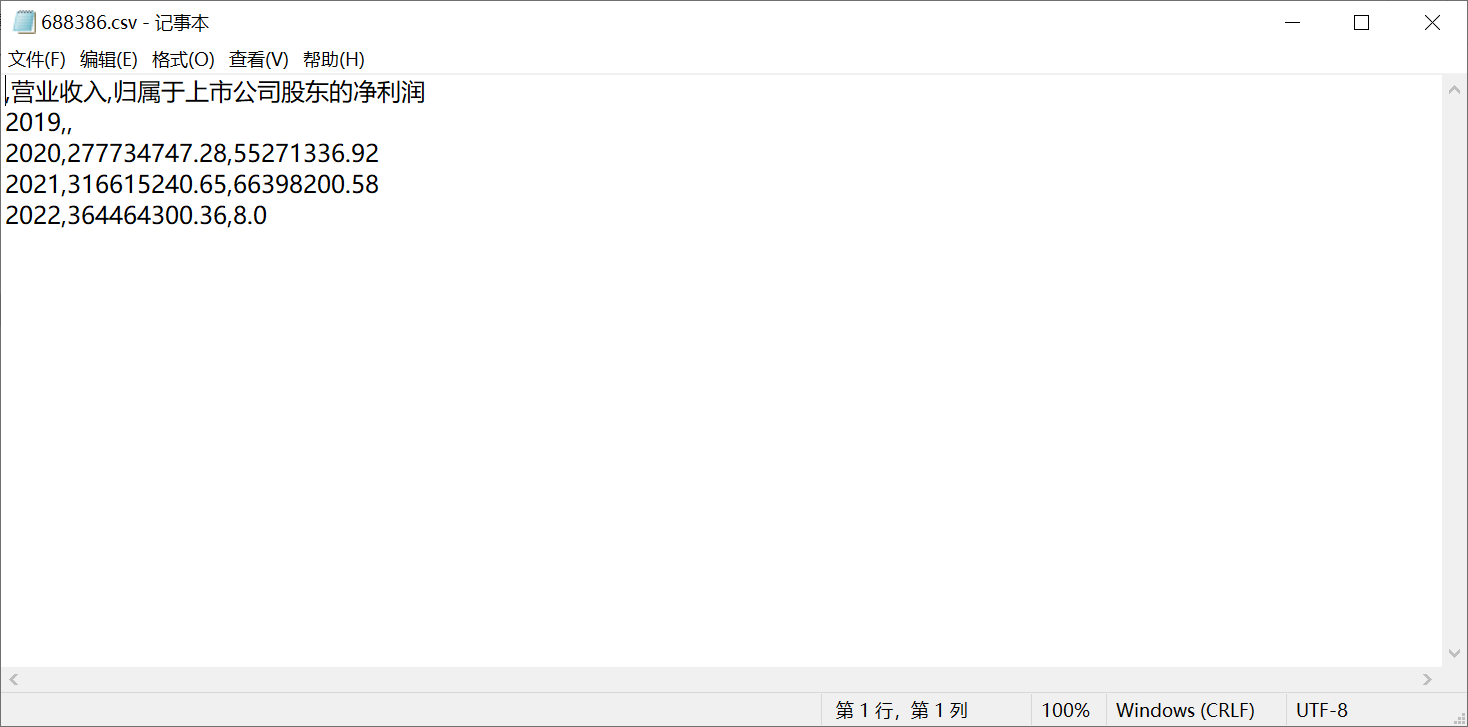
df_605255.loc[year,'营业收入']=R
df_605255.loc[year,'归属于上市公司股东的净利润']=Pro
df_605255.to_csv(r'C:/Users/hp/Desktop/金融数据获取与分析/表格数据/605255.csv')
###如此遍历,只需更改股票代码便可提取出所想要的数据
#画图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']#仿宋字体显示中文
mpl.rcParams['axes.unicode_minus']=False #在图像中正常显示负号
#将10家公司得数据导入为DataFrame
codes=['688680','688669','688560','688386','688323','688299','688219','688026','605488','605255']
for code in codes:
locals()[f'df_{code}']=pd.read_csv(f'C:/Users/hp/Desktop/金融数据获取与分析/表格数据/{code}.csv',
sep=',',encoding="utf-8")
locals()[f'df_{code}'].columns =['时间','营业收入','归属于上市公司股东的净利润']
locals()[f'df_{code}'].set_index('时间',inplace=True) #将时间列作为索引
plt.figure(figsize=(9,6))
plt.plot(df_688299['营业收入'],marker='p')
plt.xlabel(u'时间',fontsize=15)
plt.ylabel(u'营业收入(元)',fontsize=15)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.title(u'宁波长阳科技股份有限公司2019年—2022年营业收入时间趋势变化图',fontsize=15)
plt.grid()
plt.savefig("C:/Users/hp/Desktop/金融数据获取与分析/数据结果显示图片/p1")
plt.show()
plt.figure(figsize=(9,6))
plt.plot(df_688299['归属于上市公司股东的净利润'],marker='p')
plt.xlabel(u'时间',fontsize=15)
plt.ylabel(u'归属于上市公司股东的净利润(元)',fontsize=15)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.title(u'宁波长阳科技股份有限公司2019年—2022年归属于上市公司股东的净利润时间趋势变化图',fontsize=15)
plt.grid()
plt.savefig("C:/Users/hp/Desktop/金融数据获取与分析/数据结果显示图片/p2")
plt.show()
plt.figure(figsize=(15,10))
plt.plot(df_688680['营业收入'],label='海优新材',marker='p',markersize=10)
plt.plot(df_688669['营业收入'],label='聚石化学',marker='p',markersize=10)
plt.plot(df_688560['营业收入'],label='明冠新材',marker='p',markersize=10)
plt.plot(df_688386['营业收入'],label='泛亚微透',marker='p',markersize=10)
plt.plot(df_688323['营业收入'],label='瑞华泰',marker='p',markersize=10)
plt.plot(df_688299['营业收入'],label='长阳科技',marker='p',markersize=10)
plt.plot(df_688219['营业收入'],label='会通股份',marker='p',markersize=10)
plt.plot(df_688026['营业收入'],label='洁特生物',marker='p',markersize=10)
plt.plot(df_605488['营业收入'],label='福莱新材',marker='p',markersize=10)
plt.plot(df_605255['营业收入'],label='天普股份',marker='p',markersize=10)
plt.xlabel(u'时间',fontsize=17)
plt.ylabel(u'营业收入(亿元)',fontsize=17)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.title(u'10家公司2019年—2022年营业收入时间趋势变化图',fontsize=22)
plt.grid()
plt.legend(fontsize=15)
plt.savefig("C:/Users/hp/Desktop/金融数据获取与分析/数据结果显示图片/p3")
plt.show()
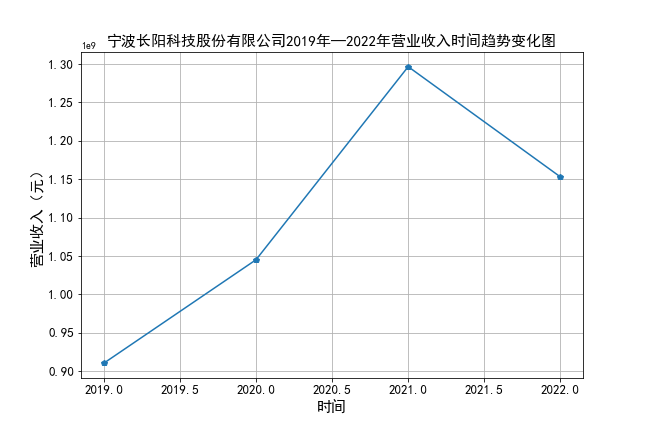
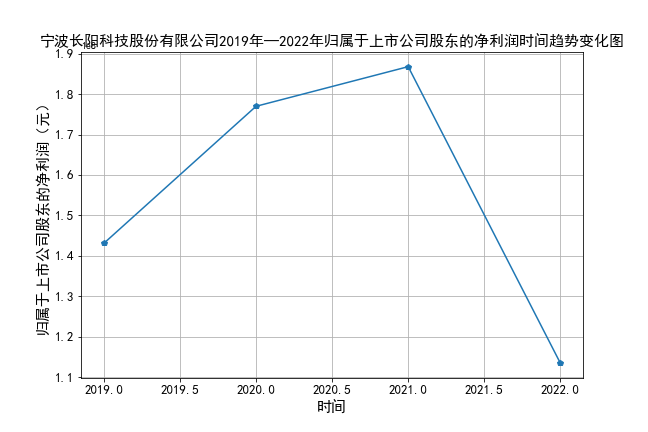
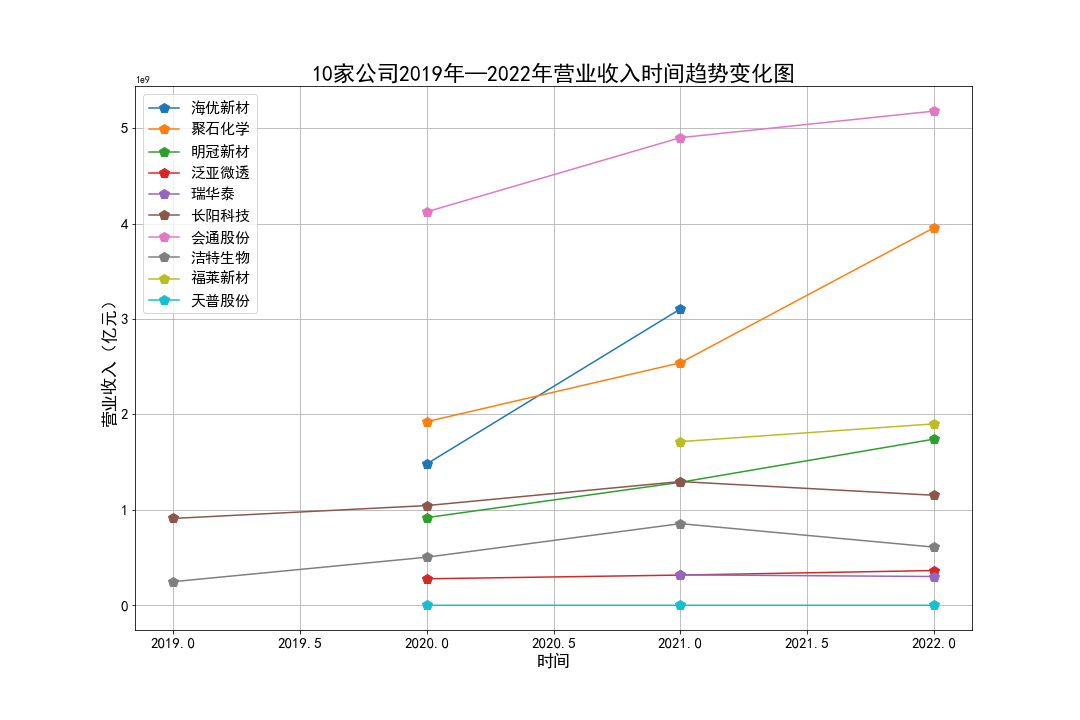
营业收入: 大部分公司总体上涨,部分公司波动较大,且长阳科技、洁特生物主要呈现下降的趋势。
感觉过程真的很难很难,从最开始爬取年报就出现了很多问题(第一次看到成功爬取真的很震惊!!!),了解如何从上交所爬取需要的信息,包括有一些年报存在一些问题,除了正常年报外,有异常(特殊)的年报需要手动进行更改(非常感谢雪鹏同学的帮助!)。包括后面读取年报数据,采取了手动更换股票代码,修改十次,最终得到结果。非常感谢老师的教导,这是第一次如此深入的学习python知识并实际操作,在完成实验的过程中,对Python爬虫有了最初的认识和运用,不过不够熟练,还有很多不懂的地方!以后会继续不断加深学习!