from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import requests
import time
# from parse_disclosure_table import DisclosureTable
import re
import requests
import pandas as pd
# import fitz
import csv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from urllib.parse import urljoin # 用于拼接 URL
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
# 报告类型选择
# 选择年度报告类型
element = browser.find_element(By.CSS_SELECTOR, "#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(1)
firm = [
['002292' ,'奥飞娱乐'],
['002301' ,'齐心集团'],
['002348' ,'高乐股份'],
['002574' ,'明牌珠宝'],
['002678' ,'珠江钢琴'],
['002740' ,'爱迪尔'],
['002899' ,'英派斯'],
['300329' ,'海伦钢琴'],
['300640' ,'德艺文创'],
['300651' ,'金陵体育'],
]
# 自动控制浏览器选择所取的公司
# 手动一个一个获取
for i in range(len(firm)):
name = firm[i][1]
code = firm[i][0]
f = open('inner_HTML_%s.html' %name,'w',encoding='utf-8')
element = browser.find_element(By.ID, "input_code").click()
element = browser.find_element(By.ID,'input_code').send_keys('%s' %code)
time.sleep(0.5)
element = browser.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
element = browser.find_element(By.ID,'disclosure-table')
time.sleep(0.5)
innerHTML = element.get_attribute('innerHTML')
f.write(innerHTML)
time.sleep(0.5)
f.close()
element = browser.find_element(By.CSS_SELECTOR, ".selected-item:nth-child(2) > .icon-remove").click()
time.sleep(0.5)
browser.quit()
# 将获取的公司年报地址存入csv文件中
for i in range(len(firm)):
name = firm[i][1]
f = open('inner_HTML_%s.html' %name,encoding='utf-8')
t = f.read()
soup = BeautifulSoup(t, 'html.parser')
# print(type(t))
comments = soup.find_all('div', {'class': 'text-title-box'})
data_list = []
for item in comments:
content = item.find('span', {'class': 'pull-left title-text ellipsis'})
# print(content.text)
if content.text[-5:] != f"年年度报告":
continue
print(content.text)
# 找到报告的下载地址和名称
link = item.find("a", {"attachformat": "pdf"})
url = urljoin("https://www.szse.cn", link.get("href"))
name = link.find("span", {"class": "title-text"}).get("title")
# 将报告名和下载地址追加到 CSV 文件中
with open(f"{firm[i][1]}.csv", "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([name, url])
f.close()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
for i in range(len(firm)):
name = firm[i][1]
df = pd.read_csv(f'{name}.csv')
urls = df.iloc[:, 1].tolist()
for j in range(len(urls)):
ann_url = urls[j]
# 创建 WebDriver 对象
driver = webdriver.Chrome()
# 打开深交所网站并进入目标页面
driver.get(ann_url)
# 等待下载按钮可单击
download_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "a#annouceDownloadBtn[href*='info/download']")))
# 点击 "公告下载"
download_btn.click()
# 等待下载并关闭浏览器
time.sleep(10)
driver.quit()
# 在pdf中获取数据
import PyPDF2
import pandas as pd
# 打开PDF文件
for i in range(10):
name = firm[i]
for j in range(2012,2023):
with open(f'{name}{j}年年度报告.pdf', 'rb') as pdf_file:
# 创建文件阅读器
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
# 获取PDF中文本内容(一般情况下,表格一般在最后一页)
page_text = pdf_reader.getPage(pdf_reader.getNumPages()-1).extractText()
# 把文本内容分割成行
lines = page_text.split('\n')
# 提取表格数据
data = []
for line in lines:
# 通过判断年份来确定新的一行开始
if line.strip().isdigit():
year = line.strip()
continue
# 判断行是否包含股票代码,以此判断是否属于表格数据
if 'SH' in line or 'SZ' in line:
# 分割行中的数据,并在末尾添加年份
row_data = line.split()
row_data.append(year)
data.append(row_data)
# 创建DataFrame,并设置列名
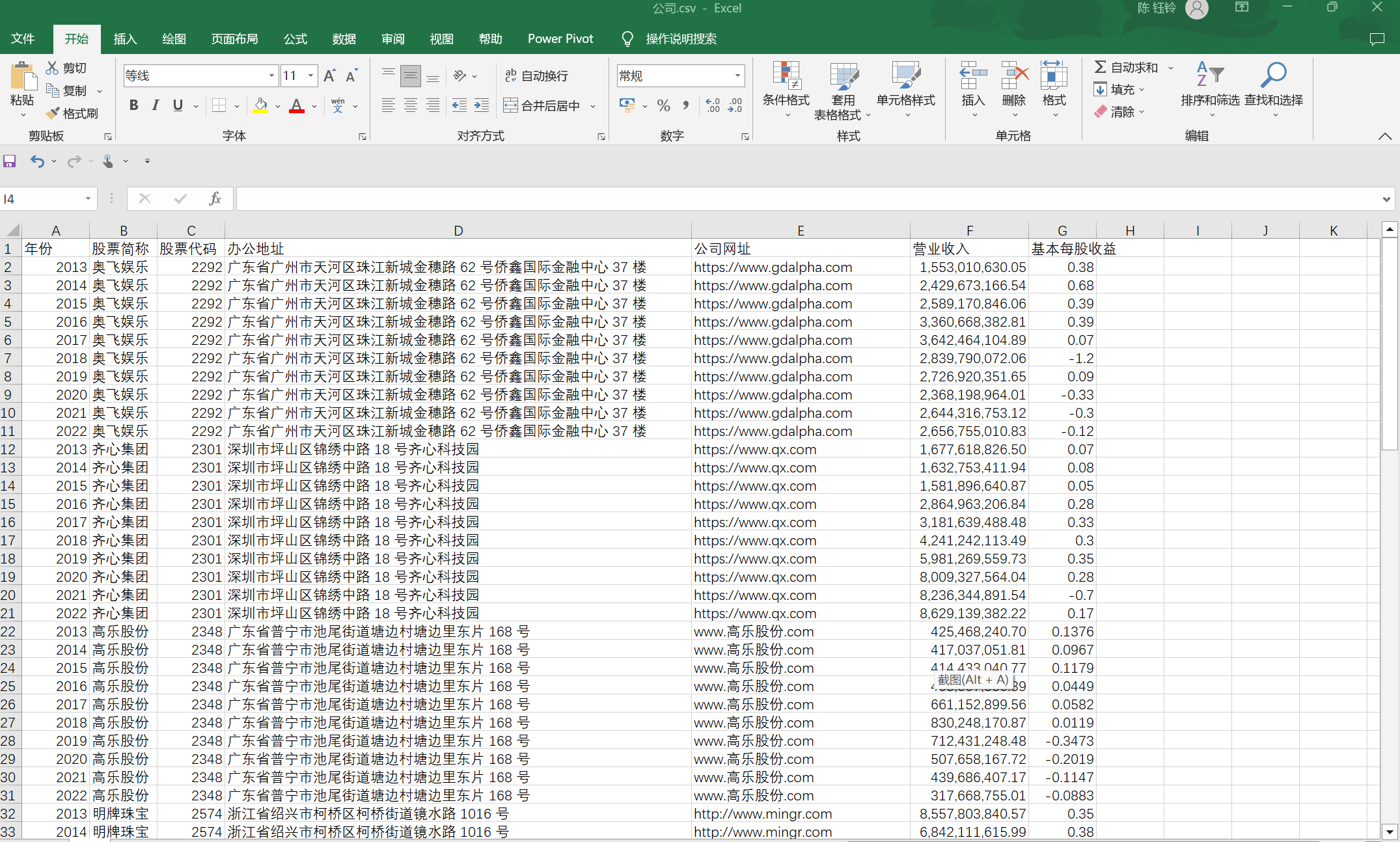
df = pd.DataFrame(data, columns=['股票代码', '股票简称', '办公地址', '公司网址', '营业收入', '基本每股收益', '年份'])
# 将DataFrame数据写入CSV文件
df.to_csv('公司.csv', index=False, encoding='utf-8')

# 可视化
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司.csv', usecols=['年份', '营业收入', '基本每股收益'])
plt.figure()
plt.plot(df['年份'], df['营业收入'], 'o-', label='营业收入', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.title('金陵体育近十年营业收入变化趋势图')
plt.legend()
plt.show()
plt.figure()
plt.plot(df['年份'], df['基本每股收益'], 'x-', label='基本每股收益', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.title('金陵体育近十年基本每股收益变化趋势图')
plt.legend()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司.csv', usecols=['年份', '股票简称', '股票代码', '办公地址', '公司网址', '营业收入', '基本每股收益'])
# 1. 按年份制图
grouped = df.groupby(['年份'])
for name, group in grouped:
plt.figure(figsize=(12, 6))
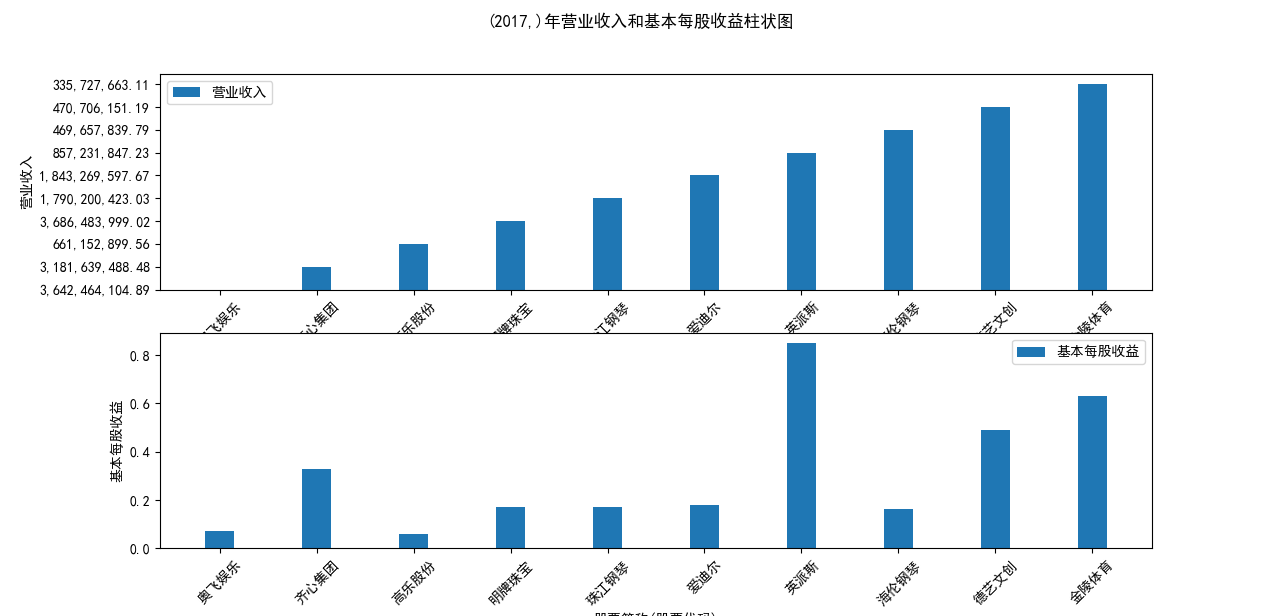
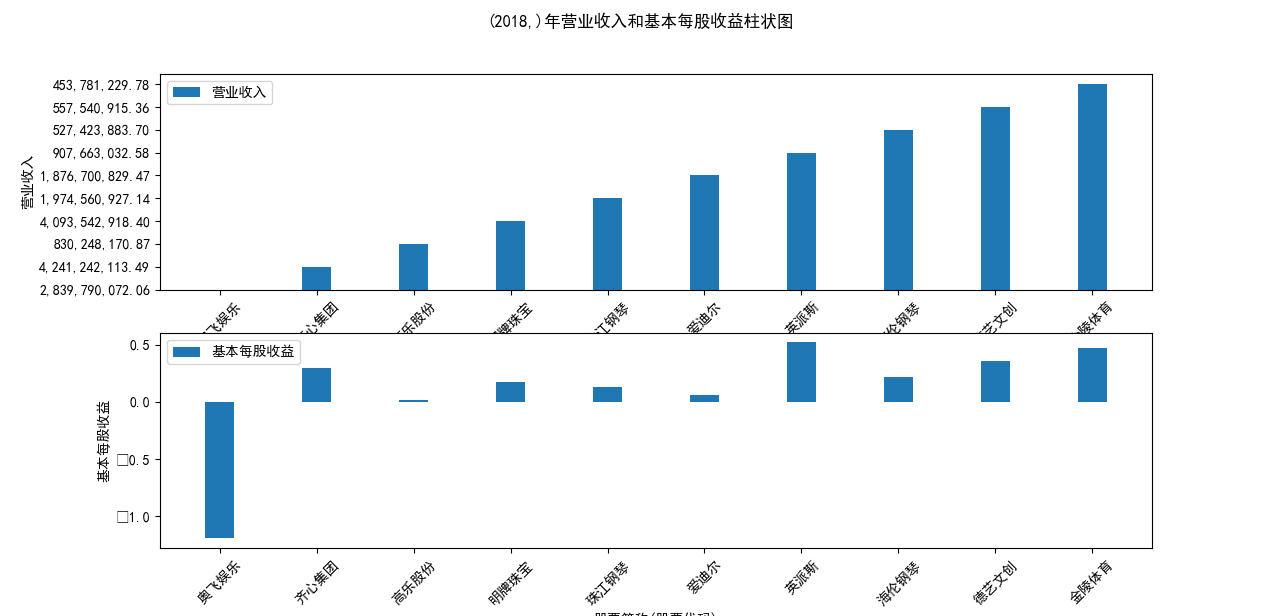
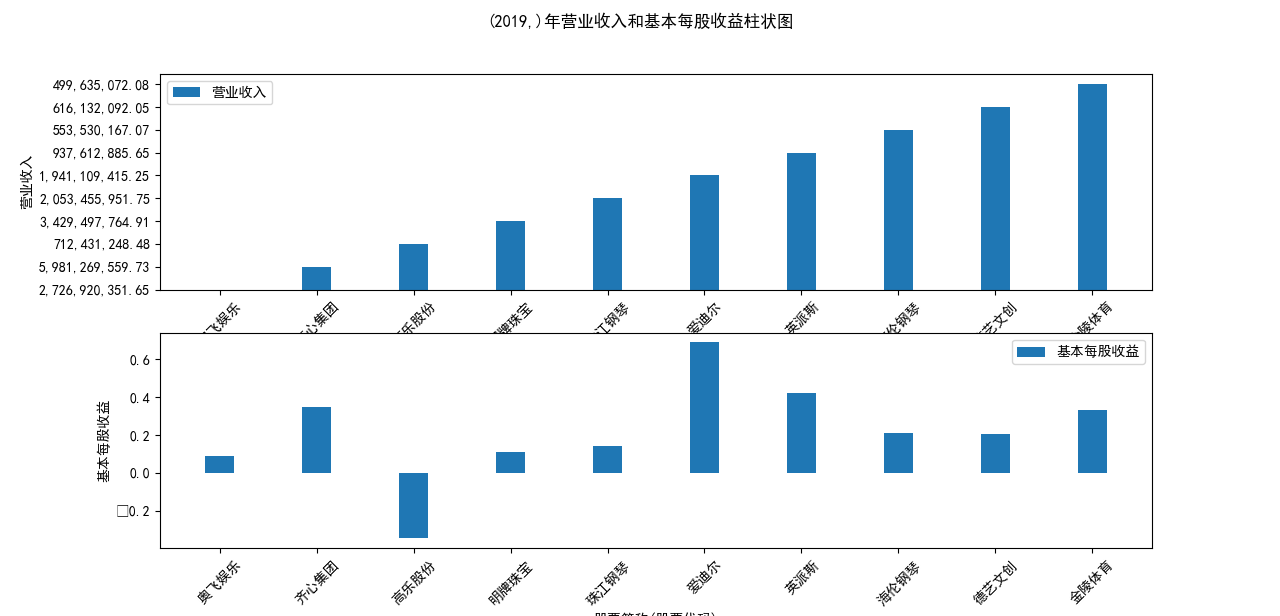
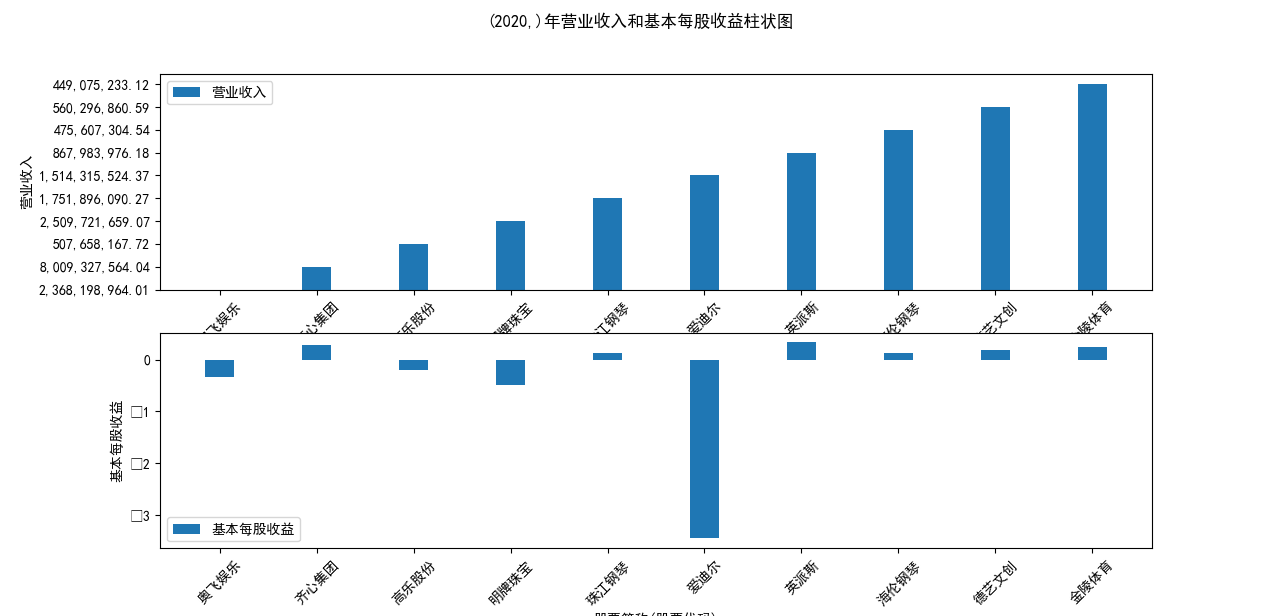
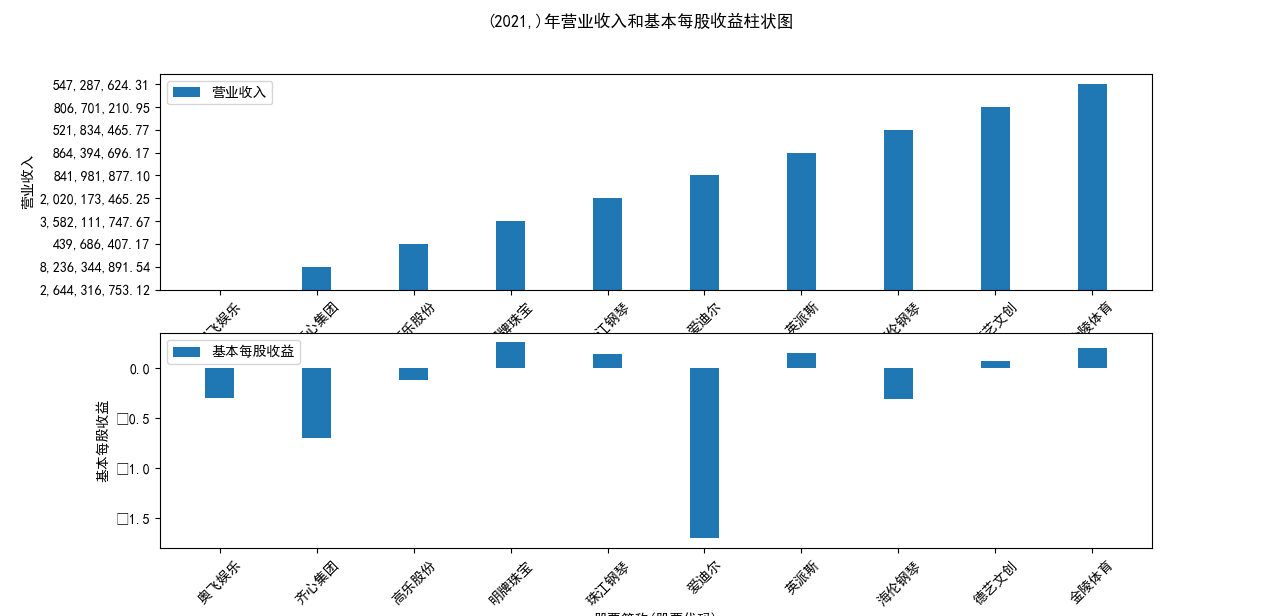
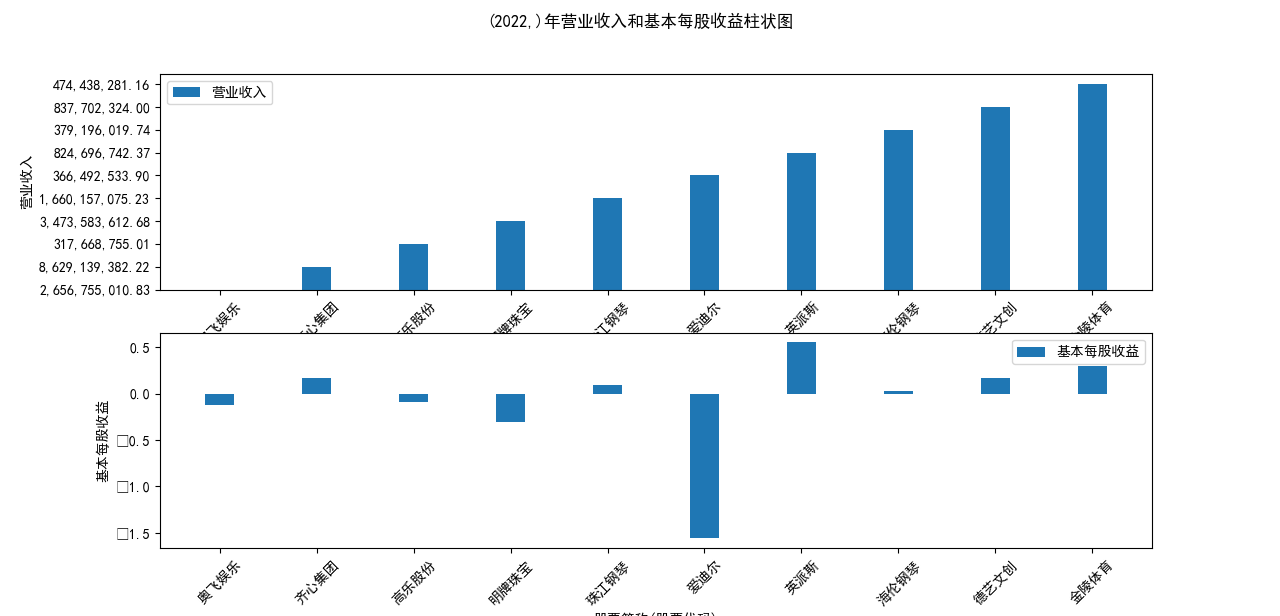
plt.suptitle(f"{name}年营业收入和基本每股收益柱状图")
plt.subplot(211)
plt.bar(group['股票简称'], group['营业收入'], width=0.3, label='营业收入')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('营业收入')
plt.legend()
plt.subplot(212)
plt.bar(group['股票简称'], group['基本每股收益'], width=0.3, label='基本每股收益')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('基本每股收益')
plt.legend()
plt.show()
data = pd.read_csv('公司.csv')
# # 2. 所有绘制在同一张图-折线
#按年份从小到大排序
data = data.sort_values('年份')
#获取全部的股票信息
stocks = data['股票简称'].unique()
#按年份从小到大排序
data = data.sort_values('年份')
#获取全部的股票信息
stocks = data['股票简称'].unique()
fig, ax1 = plt.subplots(figsize=(12, 6))
# 绘制每个公司的营业收入
for stock in stocks:
stock_data = data[data['股票简称'] == stock]
# 将字符串中的逗号替换为空格,并将列类型转换为浮点数
stock_data['营业收入'] = stock_data['营业收入'].str.replace(',', '')
stock_data['营业收入'] = stock_data['营业收入'].str.replace(' ', '').astype(float)
ax1.plot(stock_data['年份'], stock_data['营业收入'], label=stock)
# 添加y轴标签、图例和标题
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入', color='tab:red')
ax1.tick_params(axis='y', labelcolor='tab:red')
ax1.legend(loc='upper left', bbox_to_anchor=(1.02, 1), borderaxespad=0)
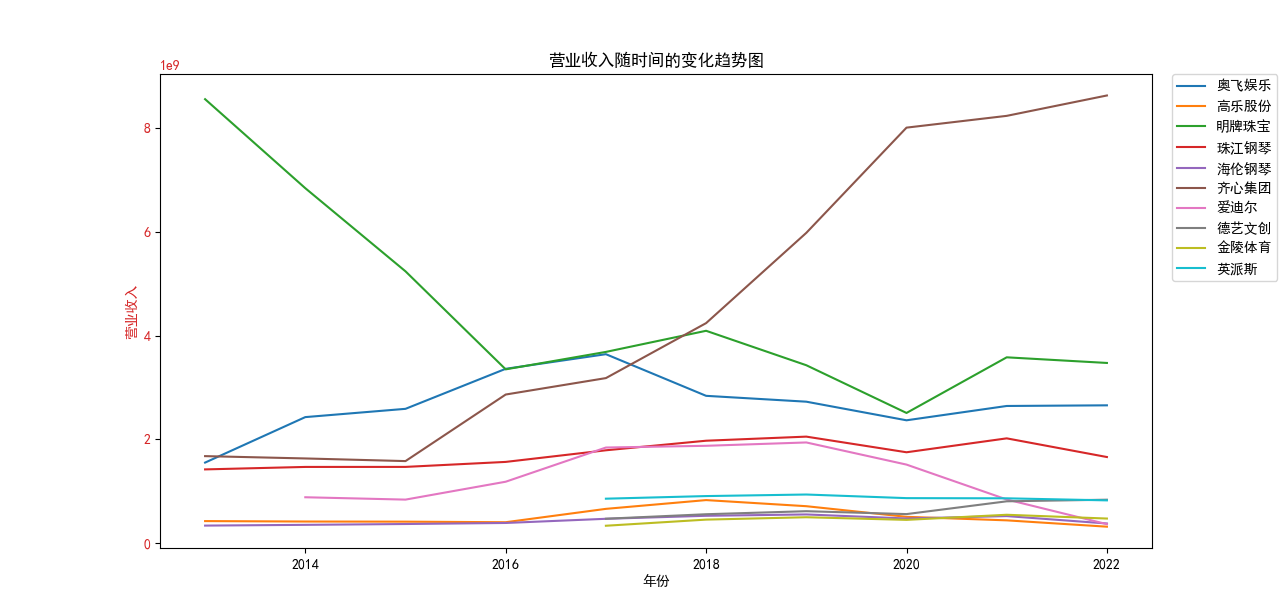
ax1.set_title('营业收入随时间的变化趋势图')
# 显示图形
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司_4.csv') # 读取文件
# 3. 所有绘制在一张图上-柱形图
# 将字符串中的逗号替换为空格,并将列类型转换为浮点数
df['营业收入'] = df['营业收入'].str.replace(',', '')
df['营业收入'] = df['营业收入'].str.replace(' ', '').astype(float)
df['基本每股收益'] = df['基本每股收益'].astype(float)
# 获取不同年份的营业收入情况
year_revenue = df.pivot_table(index='年份', columns='股票简称', values='营业收入')
year_revenue.plot(kind='bar')
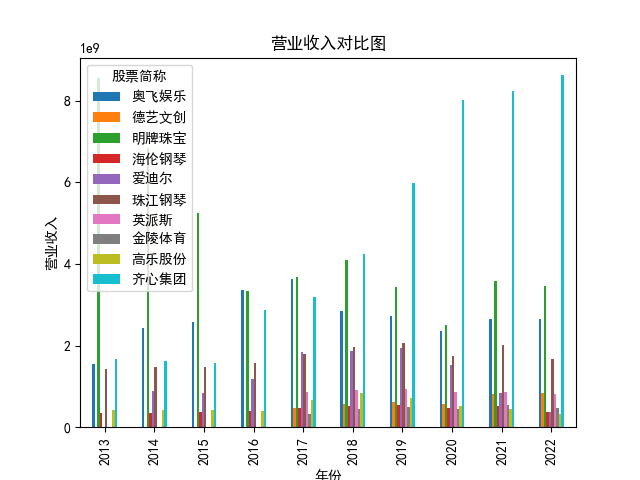
plt.title('营业收入对比图')
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.show()
# 获取不同年份的基本每股收益情况
year_eps = df.pivot_table(index='年份', columns='股票简称', values='基本每股收益')
year_eps.plot(kind='bar')
plt.title('基本每股收益对比图')
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.show()

随着社会的不断发展,文体业行业正在呈现出日益繁荣的态势。文体业行业包括电影、电视、音乐、体育、文学等,它为人们提供了丰富的精神文化生活,是社会精神文明建设的重要组成部分。 互联网技术的发展,政府相关政策的支持,人们不断增加的精神文化需求,为文体业行业的发展提供了广阔的市场空间。 随着疫情态势的好转,社会面解封,人们越来越注重精神文化生活,愿意投入更多的时间和金钱去观看电影、比赛、演唱会等,这为文体业行业的发展带来了全新的机遇与挑战。
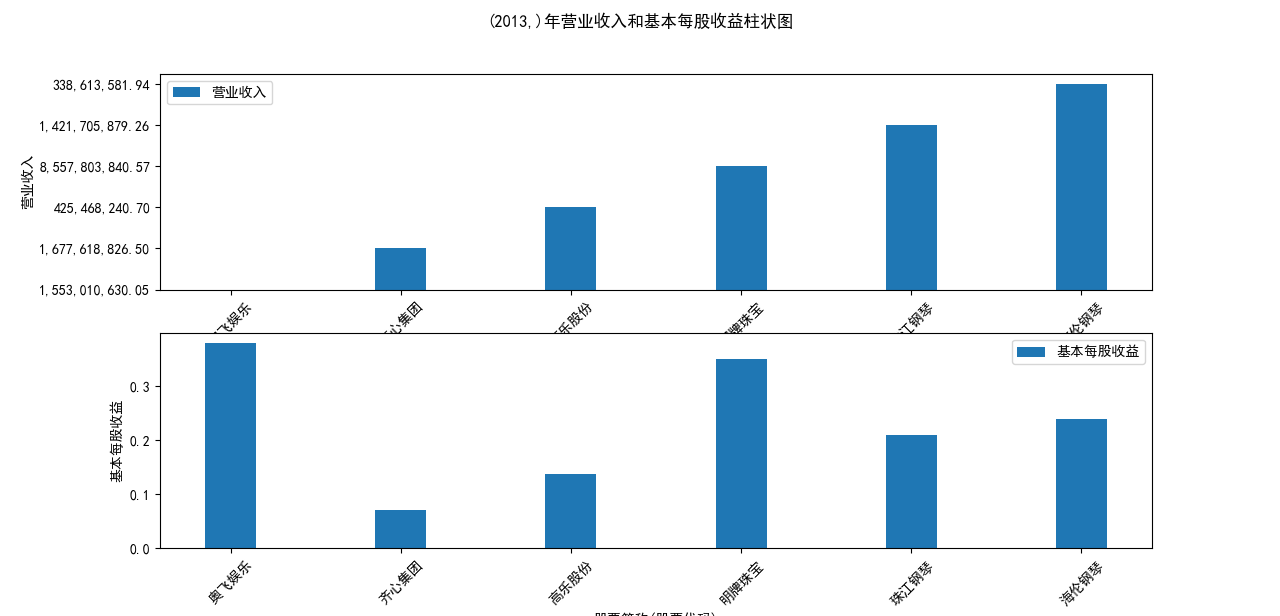
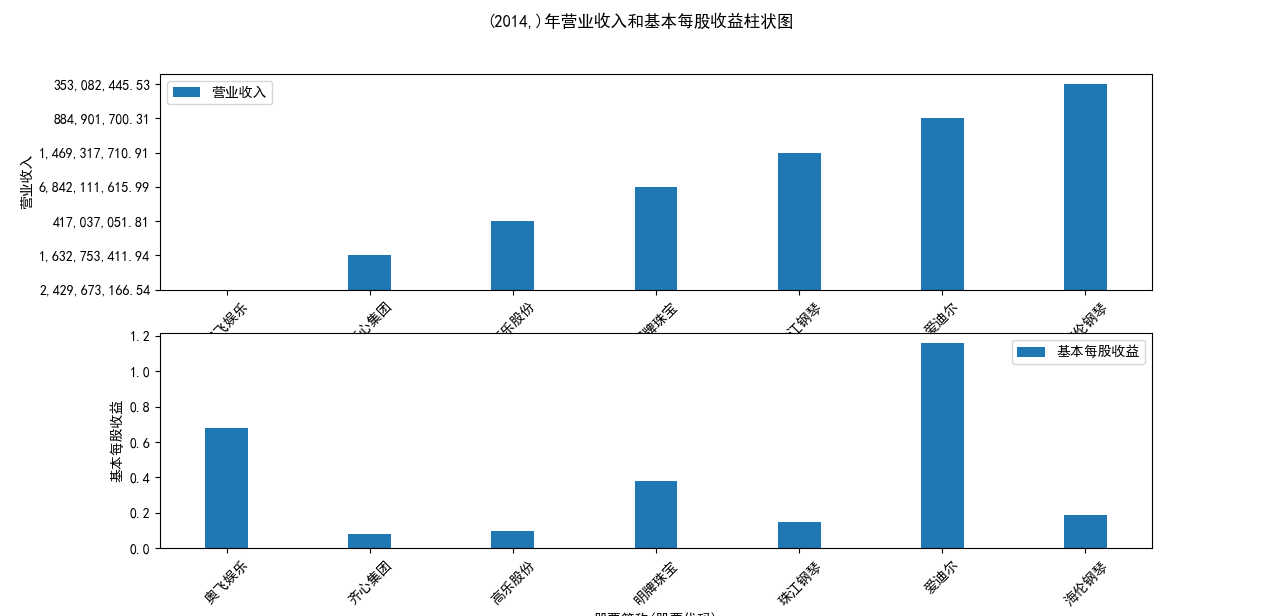
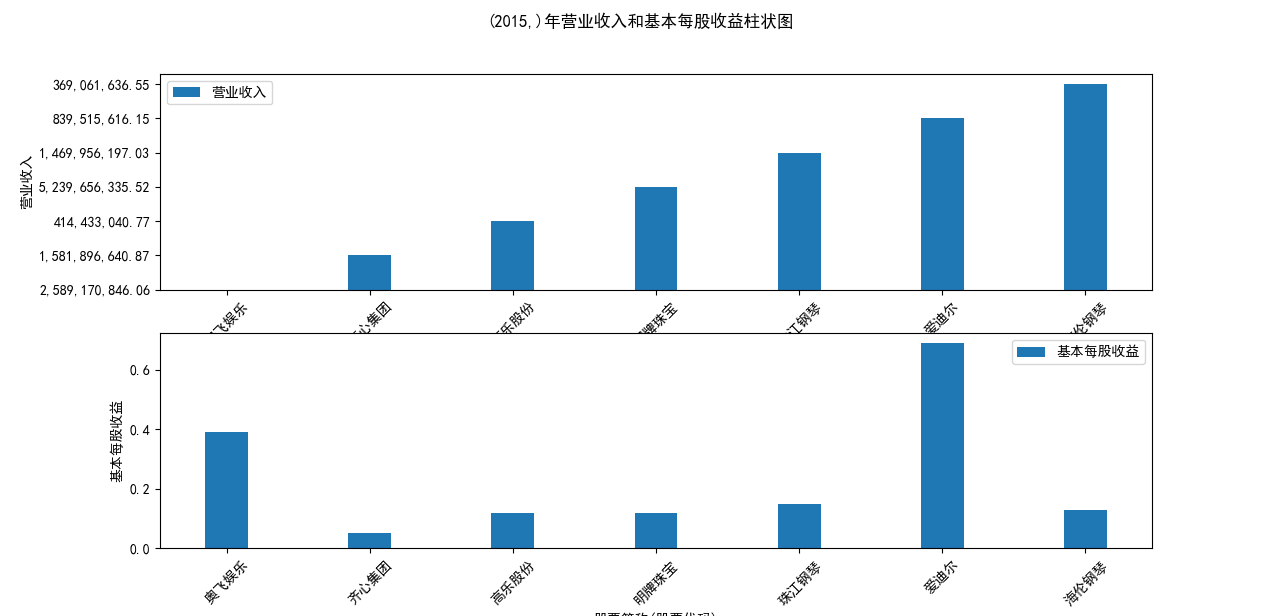
营业收入解读,根据绘图结果可知,文体行业的几家头部公司近十年来营业收入在稳步上升,总体上上升平稳,同时,又不断涌现的新兴企业加入其中, 齐心集团更是从十年前的中下规模一直以高速度增长冲击行业龙头。此外还可以观察到在2020年行业内各上市公司的营业收入大都有所下滑,并在2021年又迎来了营业 收入增长的高峰,表明在2021年度国家的疫情防控政策下,稳中有进。
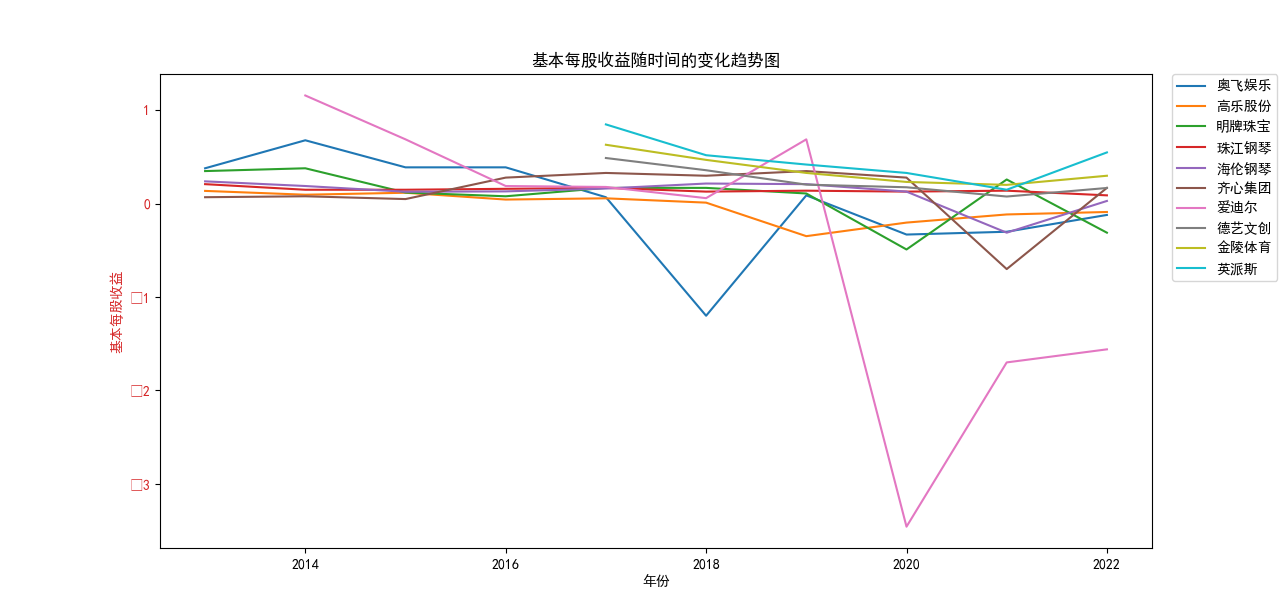
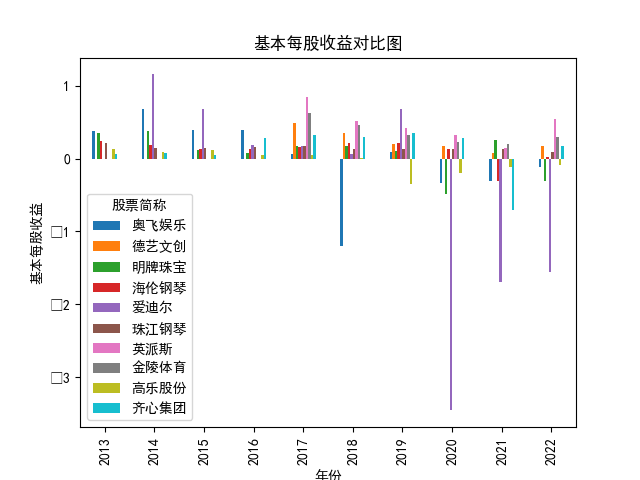
基本每股收益解读,根据绘图结果可知,十家上市公司前五年均保持正向营收,企业发展态势良好;但在2018年,奥飞娱乐基本每股收益大幅下跌,但其于2019年又回升到了正常水平。 自2020年以来,受疫情冲击,文体行业迎来“小寒冬”,多家公司收益跌到负值,其中爱迪尔公司下跌尤其剧烈,仍保持正收益的企业增长速度也不容乐观,体现了疫情对文体行业的影响之大。
这次的实验报告花费了很多的时间,期间也遇到包括年报爬取格式问题,数据清洗与处理问题等等的麻烦,好在收获了朋友和同学的帮助,在和同学一起写代码时,也能收获不同的思路方式,有时候 想不明白的点子一下就贯通了,从中也让我深深意识到自己在Python的学习中还有很多基础不扎实的地方和不足,希望在未来可以不断进步,继续在这个领域学习和探索。
同时感谢吴老师的悉心教导和帮助,这门课的教学方式非常独特,老师有自己个人的教学平台,我们也有机会实操一把设计自己网页的机会,是十分难得的。而且老师 上课始终坚持讲练结合,并且时不时下来解答我们的问题,run不出来的地方每次都耐心帮我检查纠错,以及非常贴心地准备了各种教学资料、错误总结等等,为课后的自主学习提供了很大的助益!
本学期学习了很多的知识,例如正则表达式,贪婪与非贪婪,数据存储,年报获取与处理,数据筛选与清洗等等,也应用了很多新的软件,学习自动化获取年报时,我真的很惊讶于它的智能程度,这门课让我们接触了 新的领域,并且收获了很多实用的知识,相信在以后的学习和工作中,这门课的收获将不断给我们提供帮助!