import re
import tool
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import requests
def download_pdf_from_szse(url):
options = webdriver.ChromeOptions()
download_path = "D:\\CS\\py_fi\\scores_3\\nianbao\\src\\pdf"
profile = {"plugins.plugins_list": [{"enabled": False, "name": "Chrome PDF Viewer"}],
"download.default_directory": download_path}
options.add_experimental_option("prefs", profile)
browser = webdriver.Chrome(chrome_options=options)
browser.get(url)
time.sleep(3)
browser.set_window_size(1552, 840)
browser.find_element(By.ID, "annouceDownloadBtn").click()
#简便起见,直接使用sleep函数等待下载.但最好还是想办法循环判断是否下载完成
time.sleep(15)
print(url + '\n下载完成')
def get_pdf_link_from_szse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('',re.DOTALL)
links = pattern.findall(html)
#得到的url包含英文版年报或者摘要,需要将这两种年报链接去除
full_links = []
for lk in links:
if '摘要' in lk[1] or '英文' in lk[1]:
continue
else:
full_links.append(lk[0])
for i in range(0,len(full_links)):
full_links[i] = 'https://www.szse.cn' + full_links[i]
'''
以上是获取所有的下载链接
下面是下载,需要调用download_pdf模块
'''
for i in range(0,min(len(full_links),10)):
try: download_pdf_from_szse(full_links[i])
except: print('股票'+code+'缺失,请到'+
full_links[i]+'重新下载')
def download_pdf_from_sse(url):
fname = '../pdf/' + url.split('/')[-1]
with open(fname,'wb') as pdf:
pdf.write(requests.get(url).content)
print(url + '\n下载完成')
def get_pdf_link_from_sse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('class="table_titlewrap" href="(.*?)" target="_blank">(.*?)
5.read_data.py
import re
import pandas as pd
import os
import tool
import pdfplumber
def is_fin_number(string):
if string == '':
return False
try:
string = string.strip()
string = string.replace(',','')
except: return False
for s in string:
if s.isdigit() == True or s == '-' or s == '.' or s == ' ' or s == '\n':
continue
else:
return False
return True
def get_data(row,name_mode):
rc = re.compile(name_mode,re.DOTALL)
bound = 0
for i in range(0,len(row)):
rs = None
try:
rs = rc.search(row[i]) #row[i]可能是None
except:
continue
if rs is None:
continue
else:
bound = i
break
if rs is None: #意味着没有找到
return -1
for i in range(bound,len(row)):
if is_fin_number(row[i]) == True:
return row[i]
return 'other row' # 说明虽然匹配到了文字,但数据不在当行
#该页是否是主要会计数据和财务指标
def is_this_page(text):
mode = '\n.*?主+要+会+计+数+据+和+财+务+指+标+.*?\n'
if re.search(mode,text) is None:
return False
else:
return True
def get_twin_data(fname):
earnings = -1
try: #未知原因, 打开文件时会出现assert error
with pdfplumber.open('../pdf/' + fname) as pdf:
s = 0
for i in range(0,len(pdf.pages)):
text = pdf.pages[i].extract_text()
if is_this_page(text) == True:
s = i
break
else:
continue
page_index = 0
bound = 0
for i in range(s,s+2): #deterministic
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
for j in range(0,len(table)):
e = get_data(table[j],'.*?营业收入.*?')
#此时文字和数据错行,需要继续往上搜索
if e == 'other row':
for k in range(j-1, 0,-1):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
e = table[k][h]
break
else:
continue
else:
if is_fin_number(e) == True:
break
if e != -1:
earnings = e
bound = j
break
else:
continue
if earnings == -1:
continue
page_index = i
break
#循环结束仍然没有获得营业收入
if earnings == 0:
return None
net_income = -1
for i in range(page_index,page_index + 2):
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
ni_mode = '.*?归属于.*?(所有者|股东)?的?.?净?.?利?.?润?.*?'
if i == page_index: #说明此时还没有换页
for j in range(bound + 1,len(table)):
ni = get_data(table[j], ni_mode)
#此时文字和数据错行,需要继续往下搜索
if ni == 'other row':
for k in range(j, len(table)):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
net_income = table[k][h]
return [earnings,net_income]
else:
continue
if ni == 'other row':
return 'data is at the next page'
elif ni != -1:
net_income = ni
break
else:
continue
else: #此时换页
for j in range(0,len(table)):
ni = get_data(table[j], ni_mode)
if ni != -1:
net_income = ni
break
else:
continue
if net_income == -1: continue
else: return [earnings,net_income]
except: print(fname+'出现AssertionError')
'''
import read_data
read_data.get_twin_data('../pdf/晨鸣纸业:2012年年度报告.PDF')
'''
#该函数需要在pdf目录下查找对应的文件名
def read_all_data(df):
#df为包含两列(code_list和name_list)的dataframe
filename_list = []
year_list = []
data_list = []
for index,row in df.iterrows():
for filepath,dirnames,filenames in os.walk('../pdf'):
for filename in filenames:
#print(filename)
if (row['name_list'] in filename) or (row['code_list'] in filename):
print(filename)
data = get_twin_data(filename)
if data is not None:
filename_list.append(filename)
year_list.append(tool.get_year(filename,row['code_list']))
data_list.append(get_twin_data(filename))
print(filename + ' completed')
rt_list,ni_list = zip(*data_list)
df_data = {'filename':filename_list,'year':year_list,
'营业收入':rt_list,'净利润':ni_list}
df_data = pd.DataFrame(df_data)
return df_data
6.tool.py
import os
import re
import pandas as pd
def get_No():
print('程序开始前的注意事项:\n')
print("1.请先下载好相关模块,并在网络通畅的情况下运行本程序;\n")
print("2.本程序的爬虫部分使用的是chrome浏览器,请下载对应的webdriver;\n")
print('3.下载时间较长,请耐心等待;\n')
print('4.由于爬取深交所的代码的下载路径是绝对路径,请先创建如下目录路径:')
print("D:\\CS\\py_fi\\scores_3\\nianbao\\src\\pdf\n")
print('\n\n\n--------程序开始--------\n\n\n')
return int(input("请输入你的序号:"))
def to_wan(num):
return num/10000
def to_yi(num):
return num/100000000
def is_year(string):
if len(string) == 4:
return True
else:
return False
def to_num(string):
if type(string) == type('str'):
string = string.replace(',','')
string = string.replace('\n','')
return float(format(to_yi(float(string)), '.3f'))
else:
return string
def to_year_list(str_list):
for i in range(0,len(str_list)):
str_list[i] = str(str_list[i])
def to_num_list(str_list):
for i in range(0,len(str_list)):
str_list[i] = to_num(str_list[i])
def which_market(code):
if code[0:2] == '60' or code[0:3] == '688' or code[0:3] == '900':
return 'sse'
elif code[0:2] == '00' or code[0:3] == '200' or code[0:2] == '30':
return 'szse'
def clean_pdf():
for filepath,dirnames,filenames in os.walk('../pdf'):
for filename in filenames:
if '取消' in filename:
os.remove('../pdf/'+ filename)
print(filename + '+ deleted')
def get_year_sse(fname):
year = re.search('\d{6}_(\d{4}).*?\.pdf',fname,re.IGNORECASE)
return year.group(1)
def get_year_szse(fname):
year = re.search('.*?(\d{4}).*?\.pdf',fname,re.IGNORECASE)
return year.group(1)
def get_year(fname,code):
m = which_market(code)
if m == 'sse':
return get_year_sse(fname)
elif m == 'szse':
return get_year_szse(fname)
def be_contigious(this_data):
#对于某个公司的绘图数据,我们只取从最近时间到最远时间的连续数据
length = len(this_data)
last = int(this_data['year'][length - 1])
for i in range(length-2, -1, -1):
nxt = int(this_data['year'][i])
if last - nxt != 1:#说明不连续
return this_data.loc[i+1 : length]
else:
continue
return this_data
def seperate_df(df_code,data):
seperated_data = {}
for j,row1 in df_code.iterrows():
name = row1['name_list']
code = row1['code_list']
this_data = pd.DataFrame(columns = ['year','营业收入','净利润'])
for i,row2 in data.iterrows():
fn = row2['filename']
if name in fn or code in fn:
data_dict = {'name': name,
'year': row2['year'],
'营业收入':row2['营业收入'],
'净利润':row2['净利润']}
this_data = this_data.append(data_dict,ignore_index=True)
be_contigious(this_data)
seperated_data[code] = this_data
return seperated_data
7.draw_pics.py
import matplotlib.pyplot as plt
import numpy as np
import tool
def draw_pics_twinx(df):
plt.rcParams['figure.dpi'] = 200
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图片显示中文
x = df['year']
tool.to_year_list(x)
y_rt = df['营业收入']
tool.to_num_list(y_rt)
y_ni = df['净利润']
tool.to_num_list(y_ni)
fig = plt.figure()
ax1 = fig.subplots()
ax1.plot(x, y_rt,'steelblue',label="营业收入",linestyle='-',linewidth=2,
marker='o',markeredgecolor='pink',markersize='2',markeredgewidth=2)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_rt[i],(y_rt[i]),fontsize = '10')
ax1.legend(loc = 6)
ax2 = ax1.twinx()
ax2.plot(x, y_ni, 'orange',label = "归属于股东的净利润",linestyle='-',linewidth=2,
marker='o',markeredgecolor='teal',markersize='2',markeredgewidth=2)
ax2.set_ylabel('归属于股东的净利润(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_ni[i],(y_ni[i]),fontsize = '10')
ax2.legend(loc = 2)
'''
title部分必须放最后,否则会出现左边的y轴有重复刻度的问题
'''
title = df['name'][0] + '历年' + '财务数据'
plt.title(title)
plt.savefig('../pics/' + title + '.png')
plt.show()
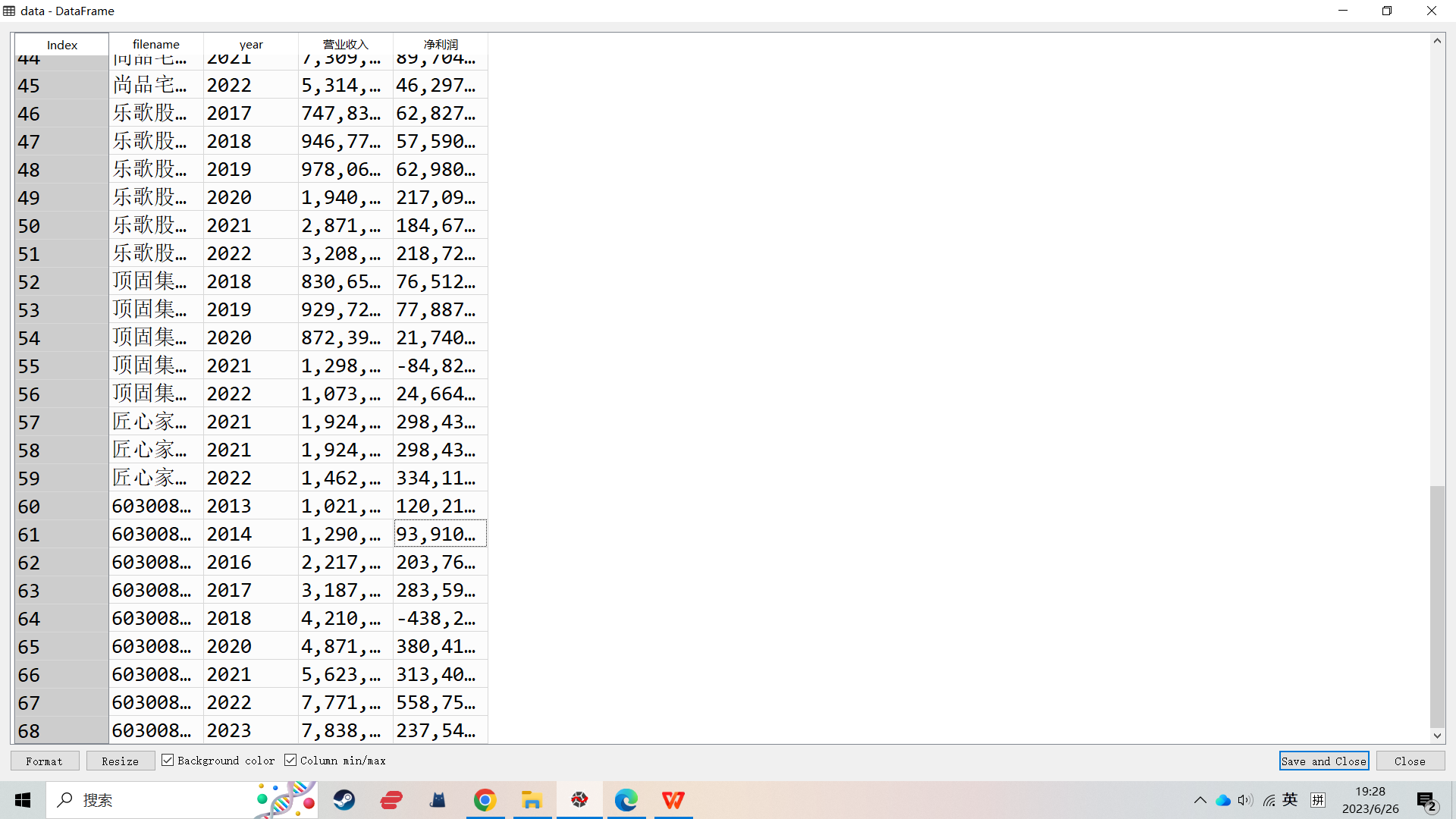
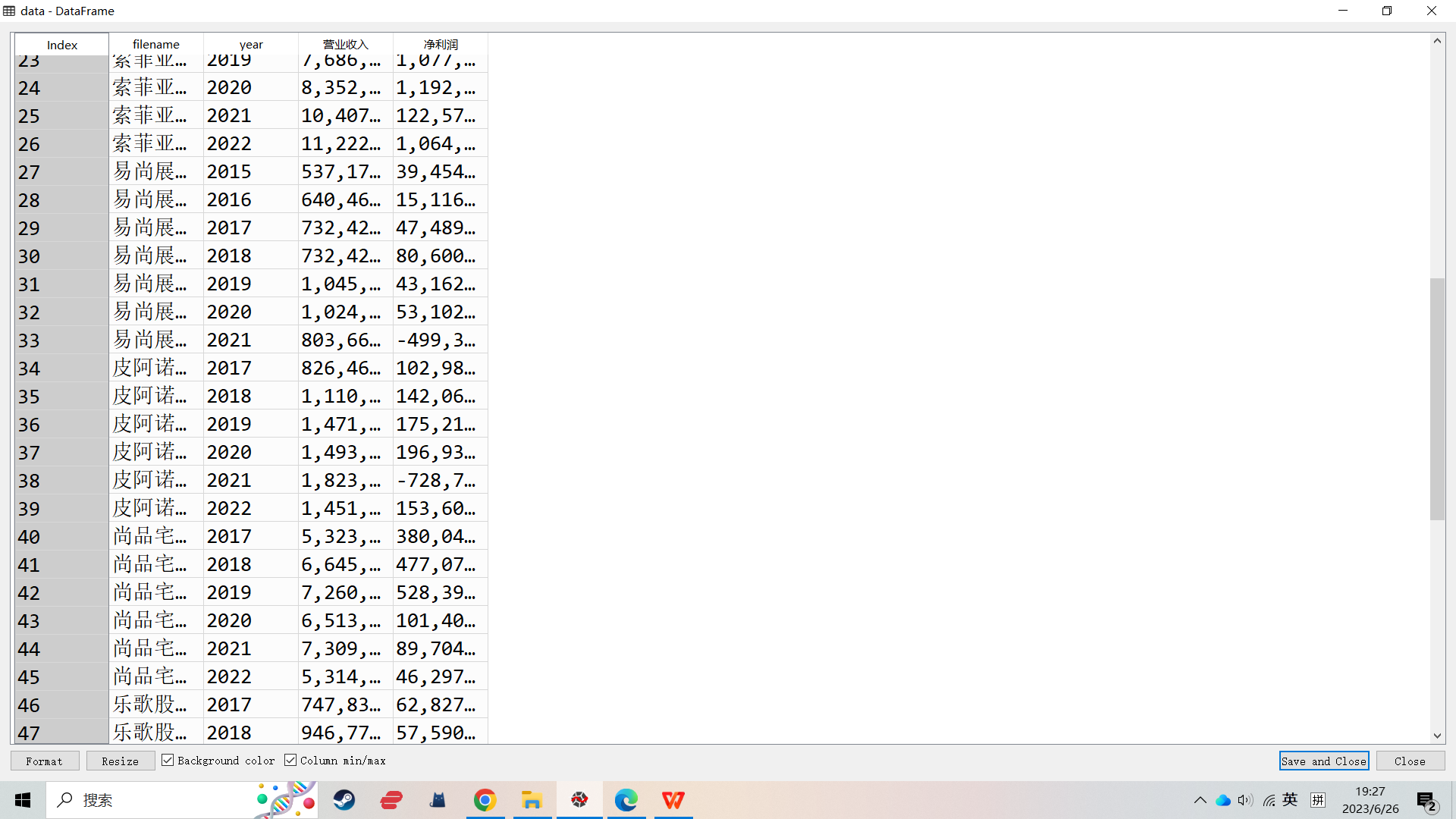
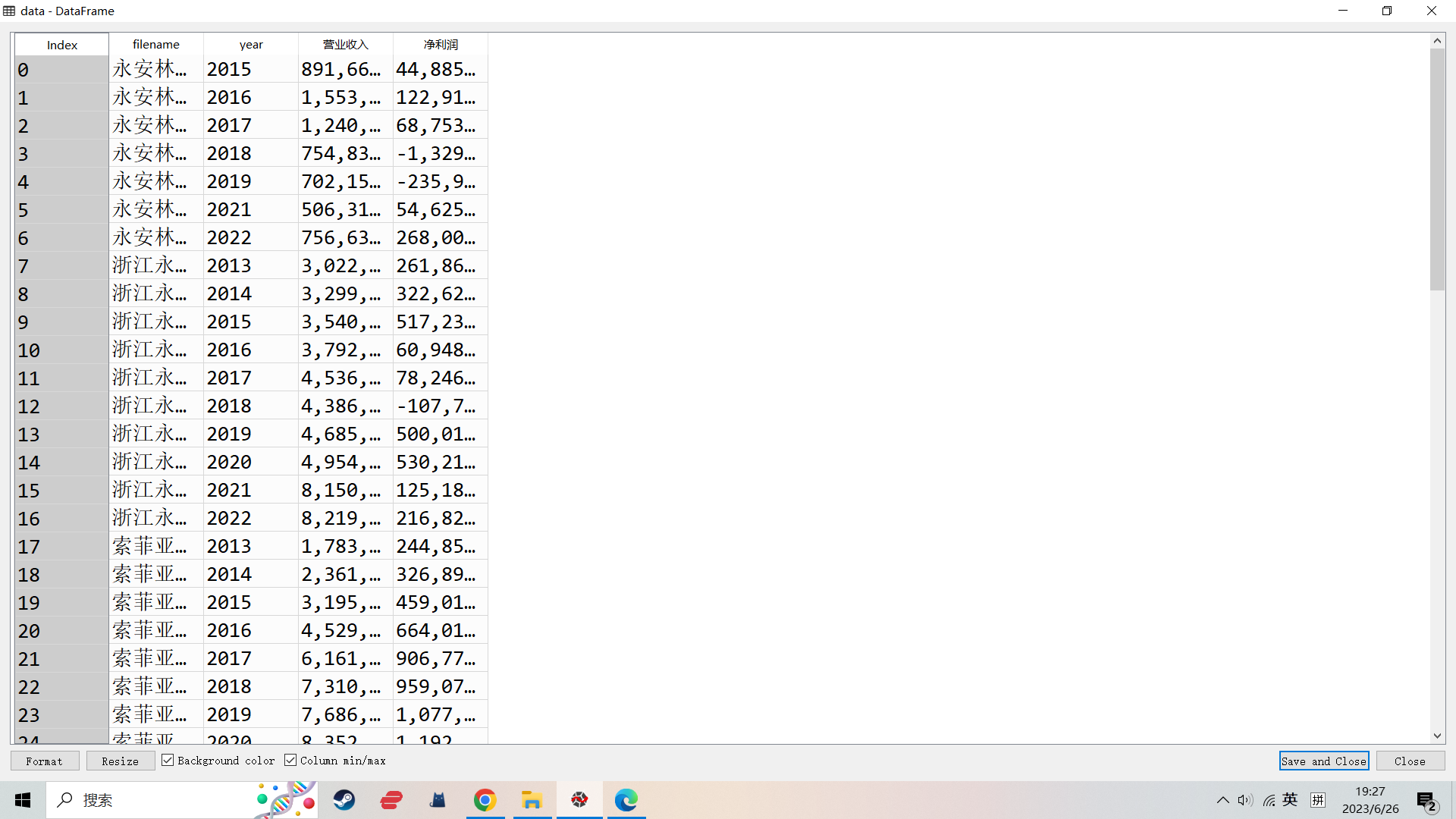
结果(部分)
1.行业及财务数据
2.html和pdf年报



3.财务数据走势图
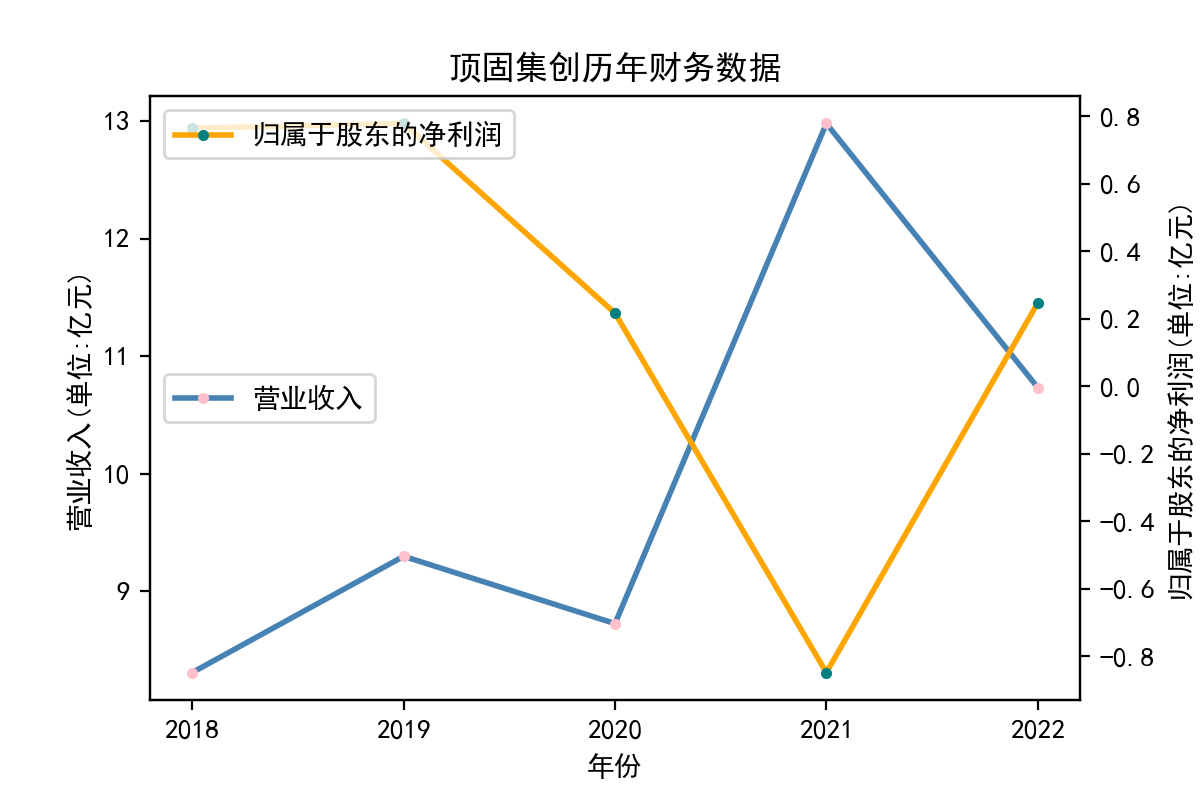
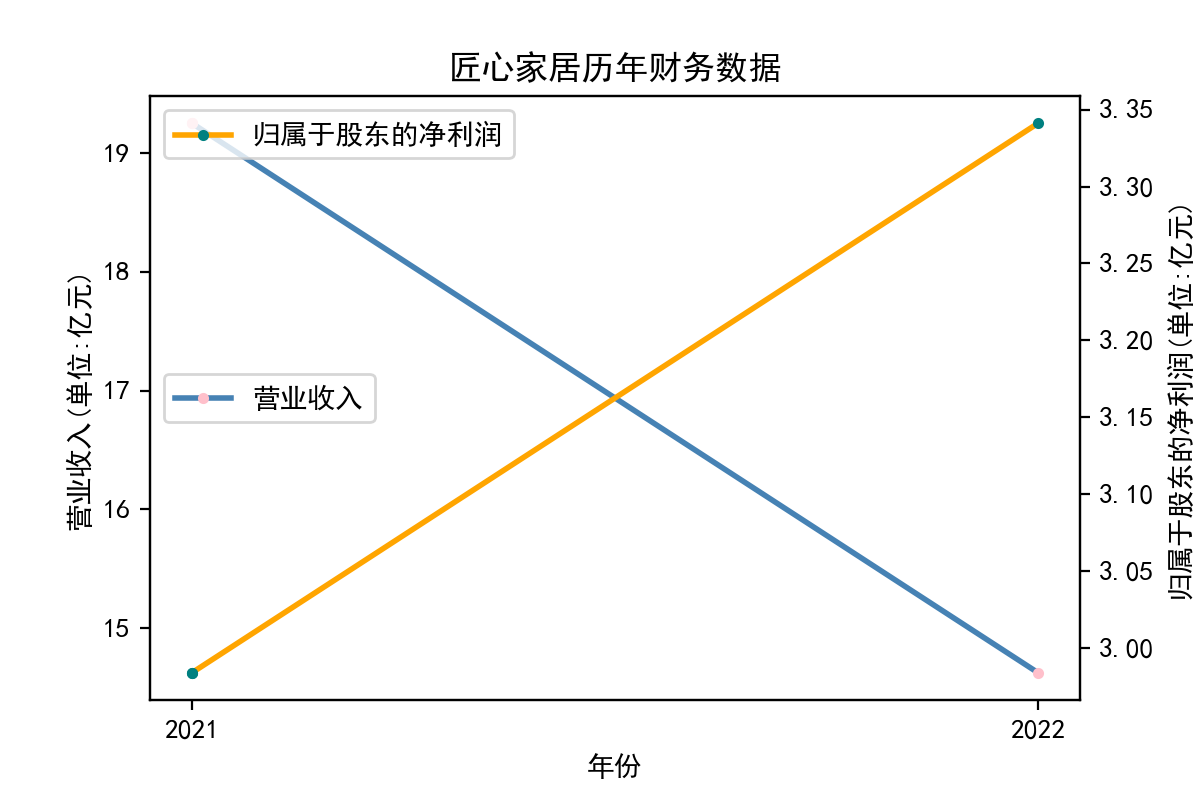
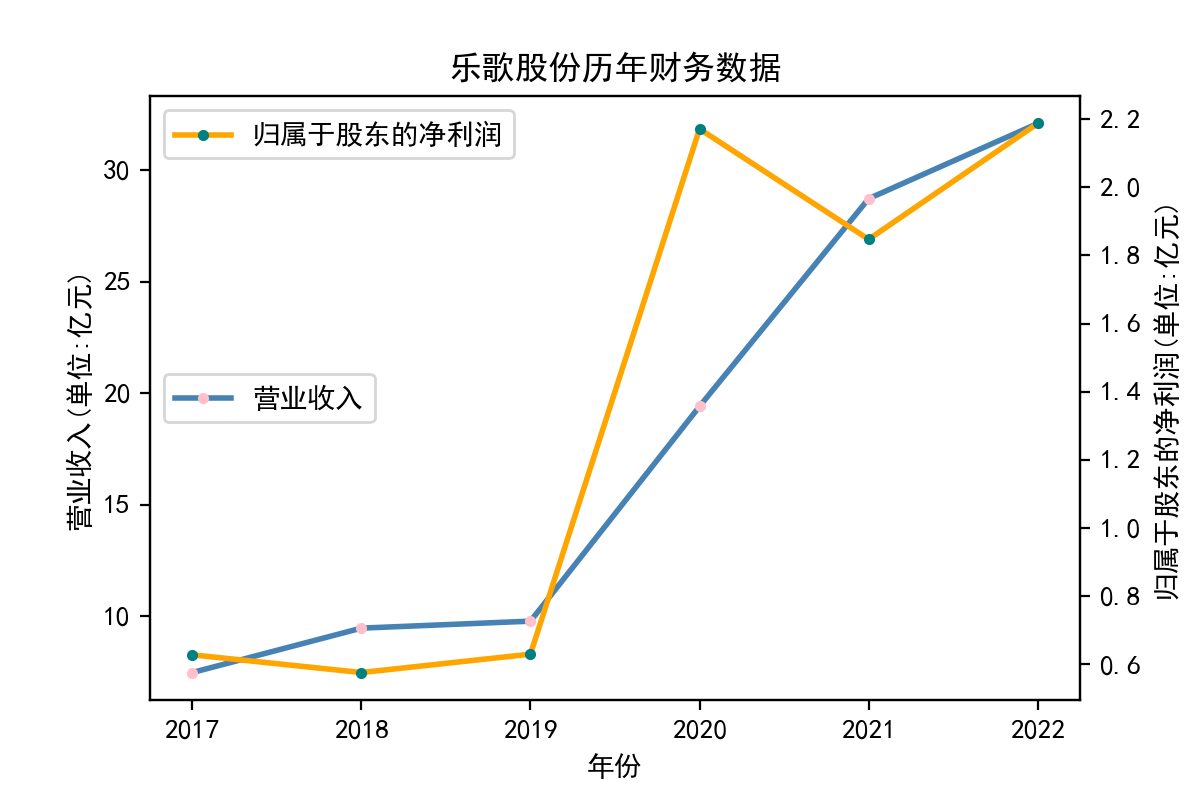
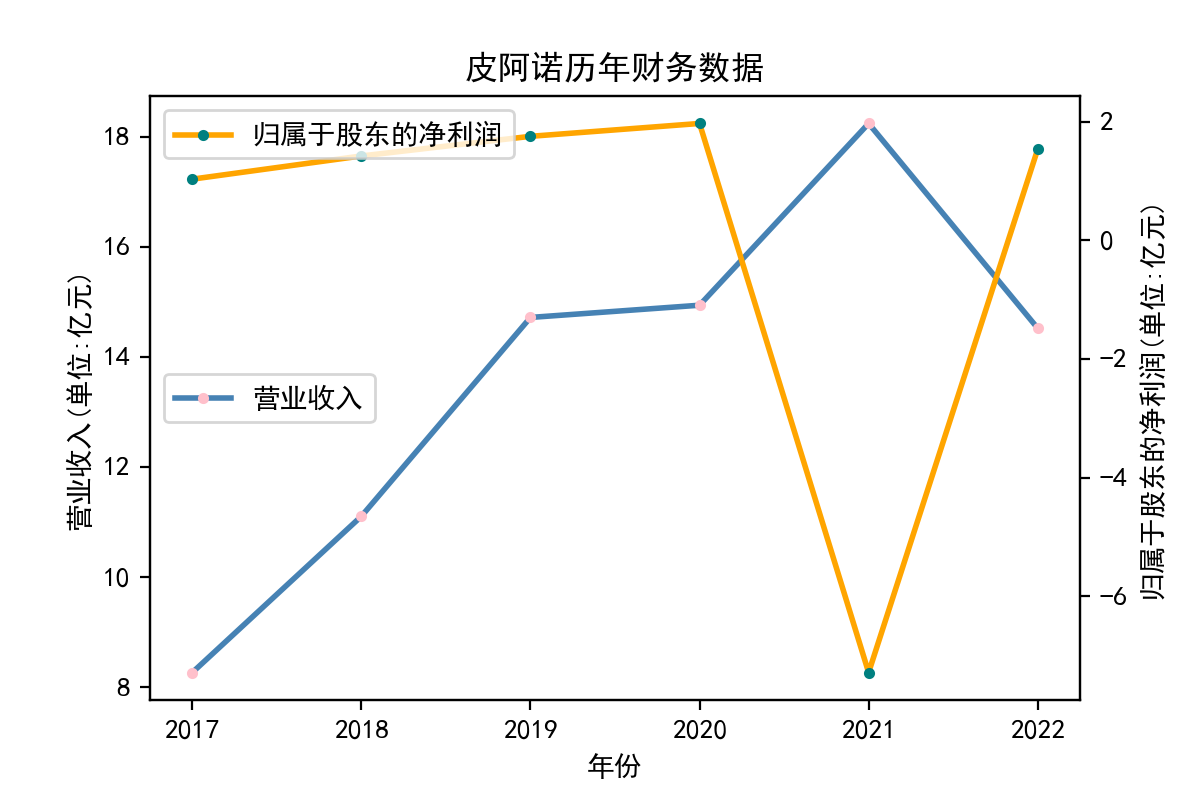
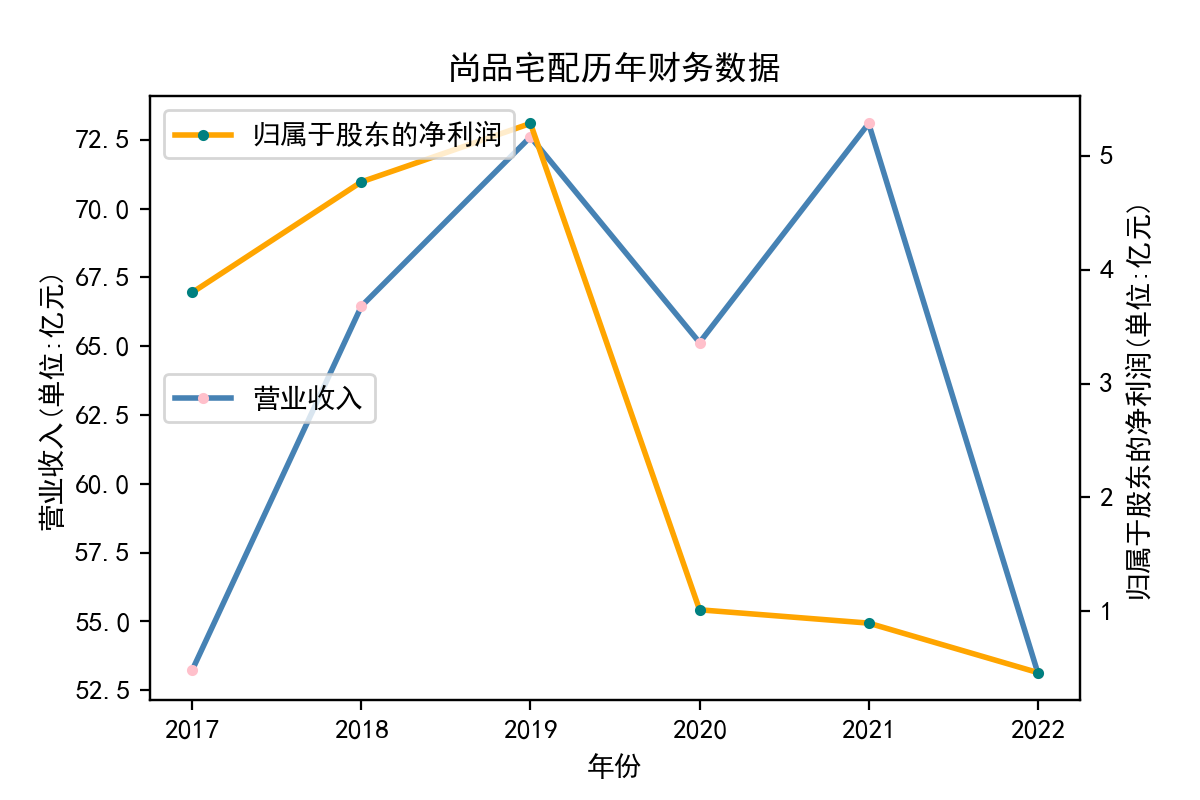
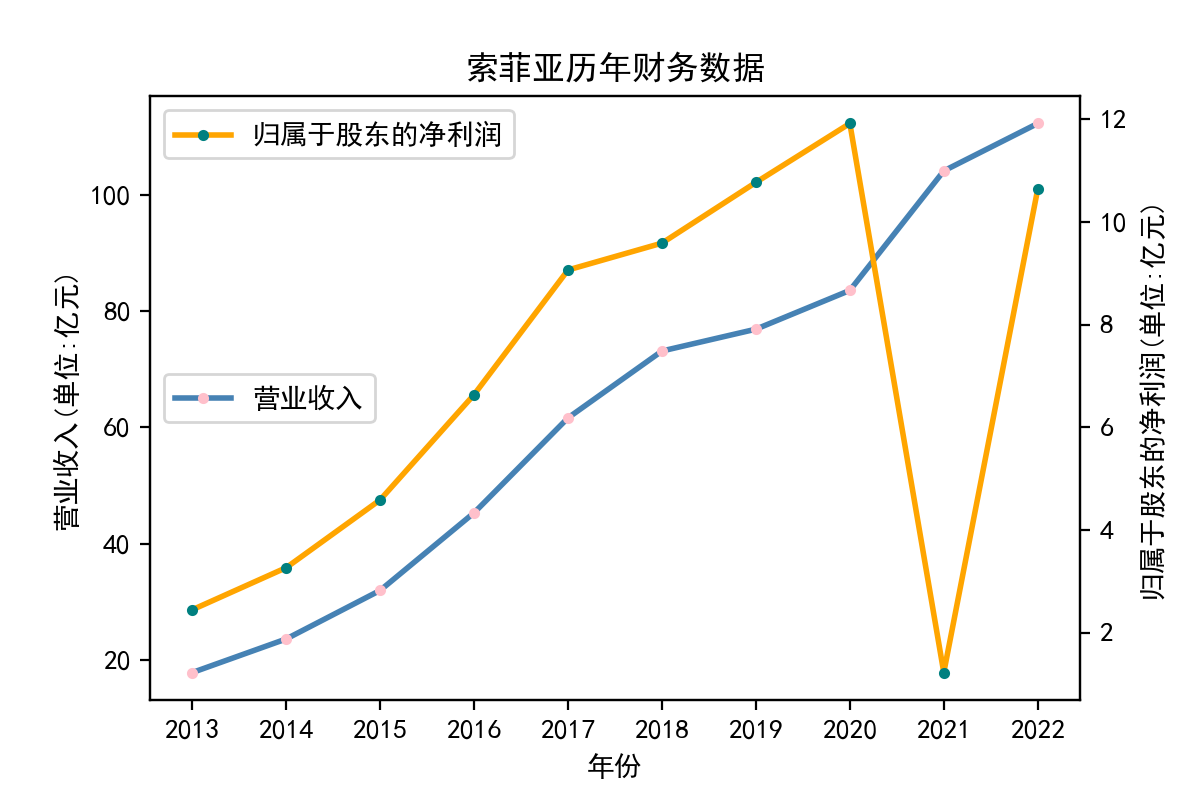
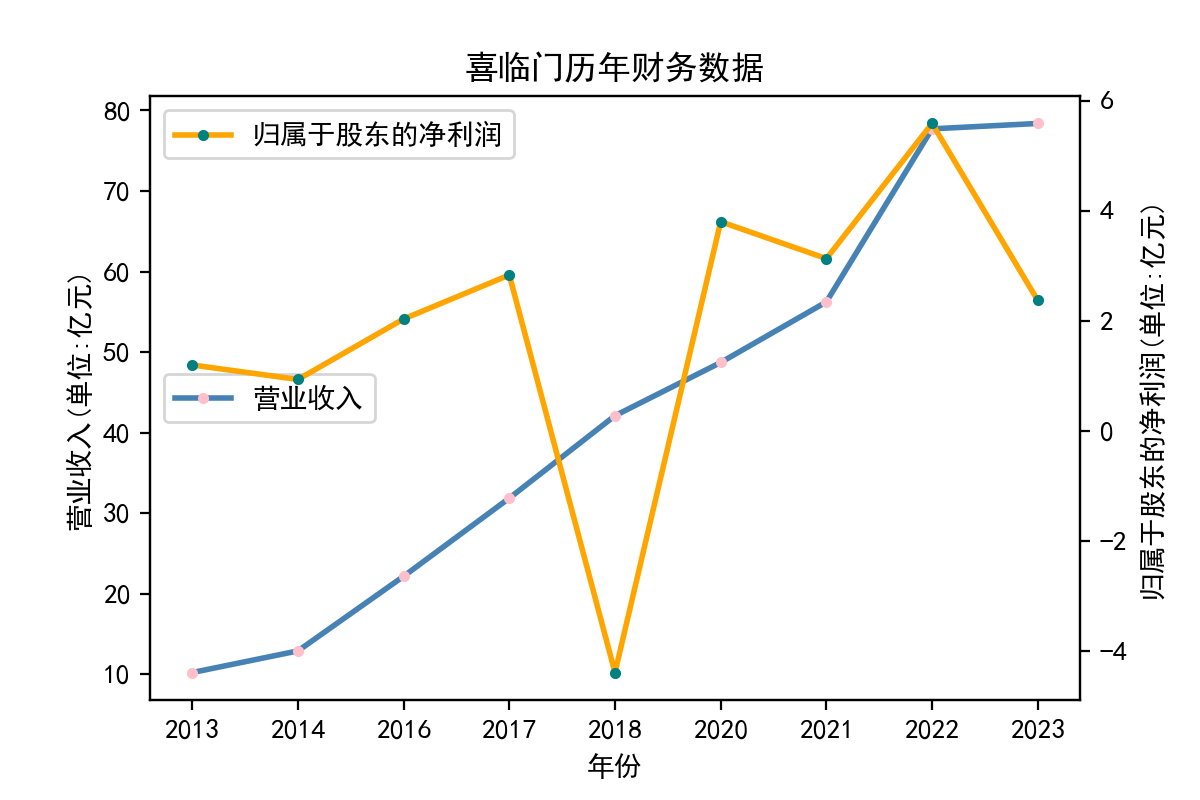
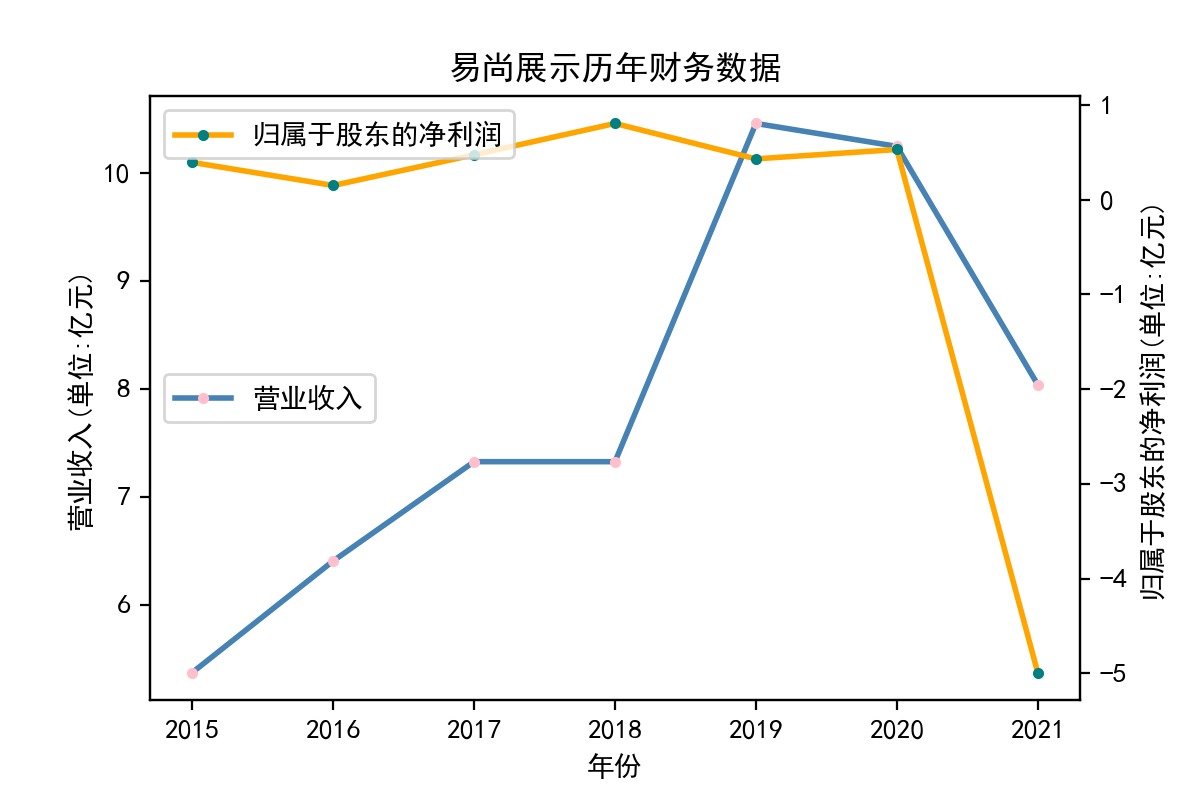
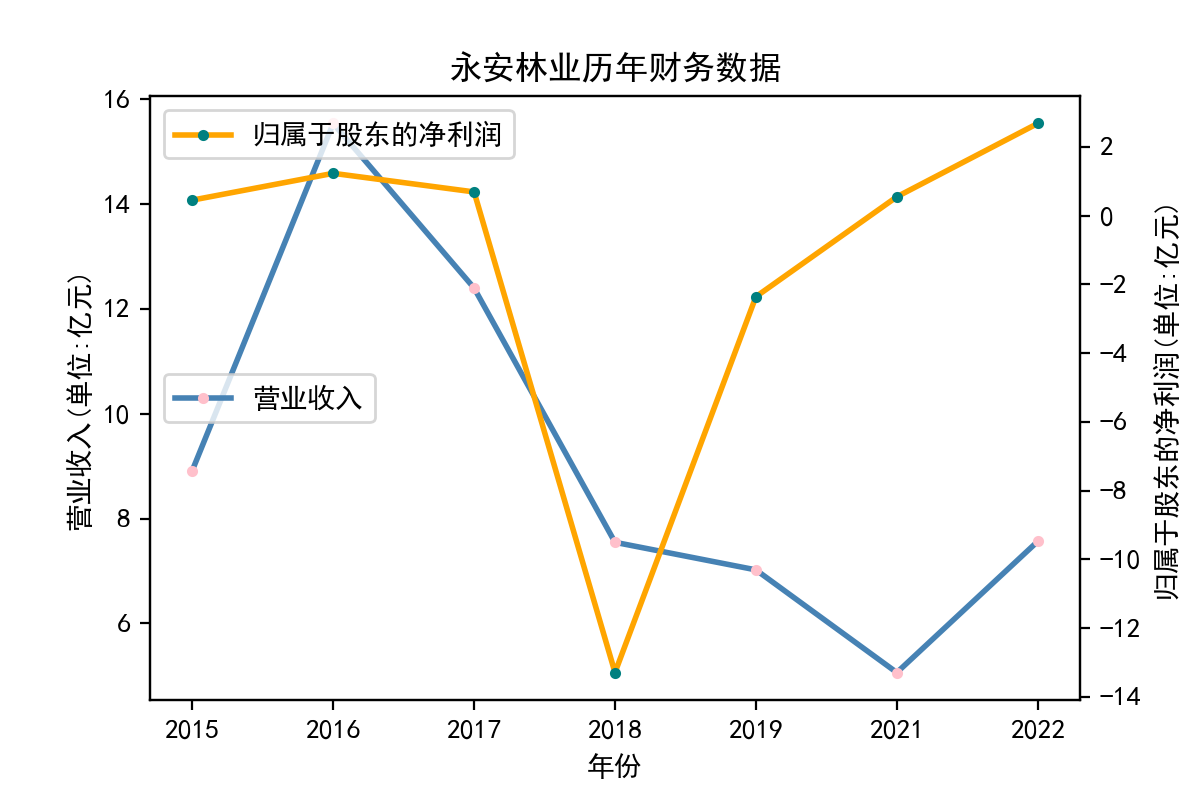
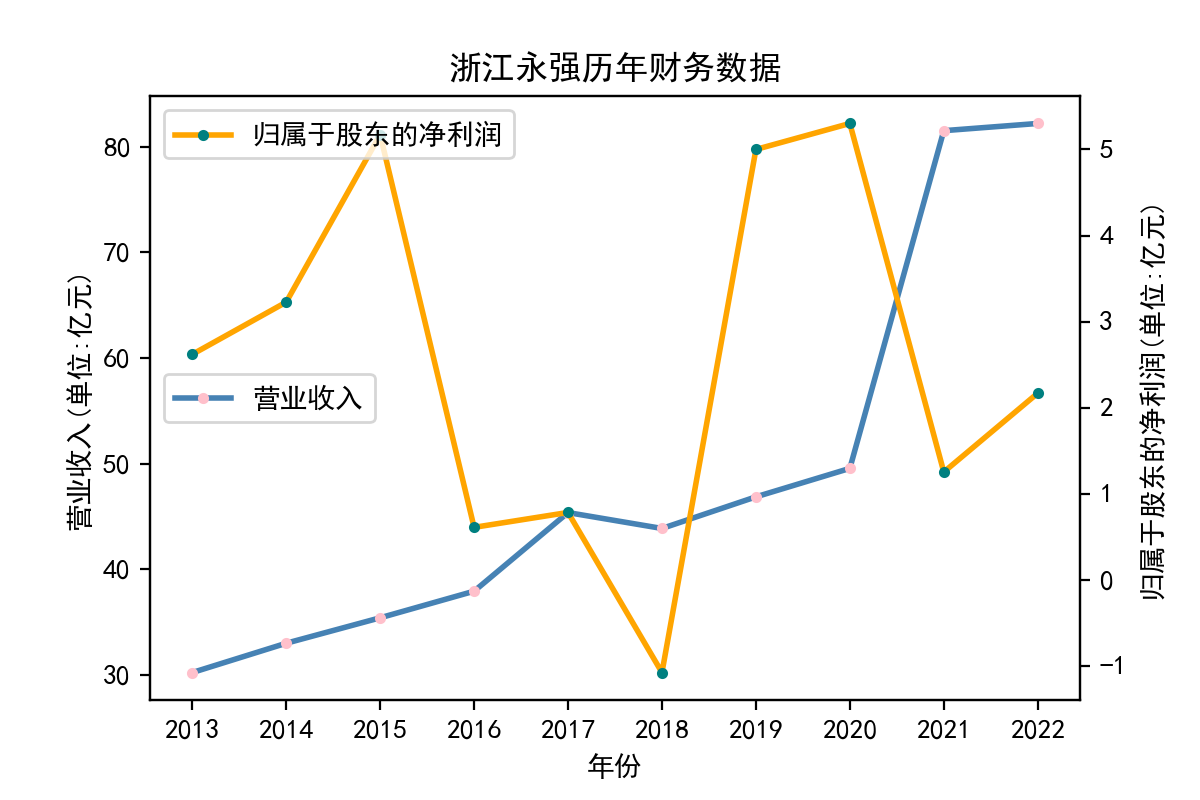
解释
整体思路(main函数)
1.输入自己的序号,从行业分类表中找到自己对应的行业,并返回包括该行业下的股票代码和公司名称的dataframe.
2.根据股票代码,利用selenium,requests库等爬虫技术,获取对应的html文档信息,其中包括了该股票历年年报的下载地址.
3.根据下载地址,再次利用爬虫技术获取对应的pdf年报,并清理掉一些无用的pdf年报(如:已取消的年报).
4.从年报中提取主要会计数据和财务指标,以dataframe的格式返回,并存储在磁盘(因为提取耗时较长).
5.从磁盘中读取财务数据,并绘图,保存.
行业分析
从走势图中,我们能明显看到,我国家具制造企业的数量呈稳步增长发展态势,但整体来看增速有所放缓。受疫情的影响,家具上游木材供应及下游需求都在萎缩,导致行业企业产量下降,但随着疫情发展态势得到有效控制,国内家具产量逐渐恢复;此外,国外疫情使得一部分国外家具订单转移到中国,这也推动了2022年中国总体家具产量持续上升
实验心得
这门课对于我来说是有一定难度的,好在在老师和同学的帮助下,我解决了一个又一个问题,能够运用这个软件去做一些对于金融学习有关的事情,所以我觉得这门课的学习能帮助我在学习的道路上走得更远。