import fitz
import re
import pandas as pd
doc = fitz.open('行业及其代码.pdf')
whole_text = ''
for page in doc:
whole_text += page.get_text()
p = re.compile(r'食品制造业.(?:\d{6}.\*?\w+.)*',re.DOTALL)#把食品制造行业的公司名称和代码抓取出来
toc = p.findall(whole_text)
toc1 = ''.join(toc)
p1 = re.compile(r'.(?:\d{6}.)',re.DOTALL)#把代码单独抓取出来
toc2 = p1.findall(toc1)
p2 = re.compile(r'(?<=\d{6}\s).+?(?=\n)')#把公司名称提取出来
toc3 = p2.findall(toc1)
#找到前十家公司代码和公司名称,并保存为csv文件
szse_code = toc2[:10]
szse_code = [x.strip() for x in szse_code if x.strip()]
szse_name = toc3[:10]
df_company = pd.DataFrame({'股票代码':szse_code,'公司名称':szse_name})
df_company.to_csv('df_company.csv')
深交所食品行业前十家公司的代码与名称的csv文件
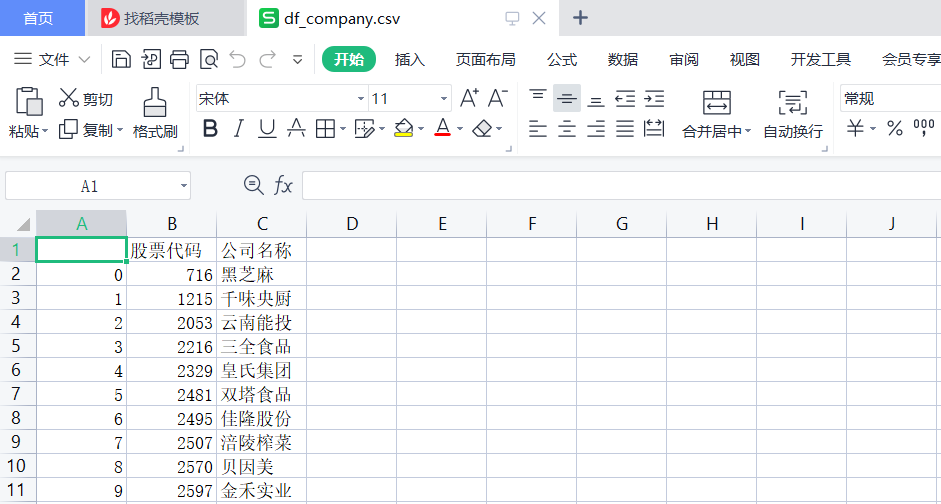
#因为前十家公司均在深交所上市,故只需要从深交所网站爬取链接
# 定义获取深交所年报HTML的函数
import re
import pandas as pd
from _init_ import szse_code
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
#利用Selenium实现自动化网页数据抓取
def get_table_szse(code):
browser = webdriver.Chrome()
browser.set_window_size(1287, 697)
url = "http://www.szse.cn/disclosure/listed/fixed/index.html"
browser.get(url)
time.sleep(3) #使电脑休息
browser.find_element(By.ID, "input_code").click()
browser.find_element(By.ID, "input_code").send_keys(code)
selector = ".active:nth-child(1) > a"
browser.find_element(By.CSS_SELECTOR,selector).click()
selector = "#select_gonggao .c-selectex-btn-text"
browser.find_element(By.CSS_SELECTOR,selector).click()
time.sleep(3)
browser.find_element(By.LINK_TEXT, "年度报告").click()
#
element = browser.find_element(By.ID, 'disclosure-table')
time.sleep(3)
#
table_html = element.get_attribute('innerHTML')
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
#
browser.quit()
class DisclosureTable_sz():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称':[td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
#利用正则表达式获取PDF的attachpath,href,title
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'href': [prefix + aht[0] for aht in ahts],
'attachpath': [prefix_href + aht[1] for aht in ahts],
'公告时间': times})
self.df_data = df
return(df)
import pandas as pd
import datetime
'''
筛掉一些不必要的连接
根据关键词和时间筛选最近10年年报
:param df: DataFrame
:param keep_words: 筛选保留包含关键词
:param exclude_words: 筛选剔除包含关键词
:param start: 筛选起始年份,格式:'YYYY-mm-dd'
:param end: 筛选结束年份,格式:'YYYY-mm-dd'
:return: a dataframe
:rtype: DataFrame
'''
def filter_nb_10y(df,
keep_words=['年报', '年度报告', '年度报告(更新后)'],
exclude_words=['摘要', '年度报告(已取消)'],
start='', end=''):
date_col = '公告时间'
df[date_col] = pd.to_datetime(df[date_col], format='%Y-%m-%d') # 转换时间列为时间类型
if start: # 如果提供了起始时间,需要筛选掉早于起始时间的数据
start_date = pd.Timestamp(start)
df = df[df[date_col] >= start_date]
if end: # 如果提供了结束时间,需要筛选掉晚于结束时间的数据
end_date = pd.Timestamp(end)
df = df[df[date_col] <= end_date]
# 使用str.contains方法进行关键词筛选
kw_mask = df['公告标题'].str.contains('|'.join(keep_words), case=False, na=False)
exc_mask = df['公告标题'].str.contains('|'.join(exclude_words), case=False, na=False)
# 使用~符号反向掩码并返回筛选结果
return df[kw_mask & (~exc_mask)]
def prepare_hrefs_years(df):
hrefs = df['href'].to_list()
df['公告时间'] = pd.to_datetime(df['公告时间'])
df['公告时间'] = df['公告时间'].apply(lambda t: t.strftime('%Y-%m-%d'))
years = [int(d[:4])-1 for d in df['公告时间']]
return((hrefs,years))
'''
下载年报
to be finished!
'''
import requests
import time
def download_pdf(href, code, year):
'''
下载单份年报,自动命名保持
'''
r = requests.get(href,allow_redirects=True)
fname = f'{code}_{year}.pdf' #每份年报的命名
f = open(fname, 'wb')
f.write(r.content)
f.close()
#
r.close()
def download_pdfs(hrefs, code, years):
for i in range(len(hrefs)):
href = hrefs[i]
year = years[i]
download_pdf(href, code, year)
time.sleep(30)
return()
'''
测试所写代码
'''
#用from...import..引用前面所定义的函数
from filter_url import filter_nb_10y,prepare_hrefs_years
import pandas as pd
from szse import get_table_szse,DisclosureTable_sz
from _init_ import szse_code
from bs4 import BeautifulSoup
from download import download_pdf,download_pdfs
'''
定义函数:
自动爬取网页数据获得有下载链接的html
根据html获得处理好的下载链接并保存为csv文件
根据要求筛选链接
最后下载十家公司十年的年报
'''
def get_table_szse_codes(codes):
for code in codes:
get_table_szse(code)
fname = f'{code}.html'
f = open(fname,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html,features = 'lxml')#美化html,更易操作
html_prettified = soup.prettify()
dt = DisclosureTable_sz(html_prettified)
df = dt.get_data()
df.to_csv(f'{code}.csv')
df = pd.read_csv(f'{code}.csv')
df_filtered = filter_nb_10y(df, start='2014-01-01', end='2023-12-31')
hrefs, years = prepare_hrefs_years(df_filtered )
download_pdfs(hrefs,code,years)
'''
输入食品制造业前十家公司的代码,得到十家公司年报的下载链接csv文件和十家公司2013-2022十年的年报
'''
codes = szse_code
get_table_szse_codes(codes)
1、通过selenium获取的HTML
2、获得的下载链接csv:
3、获得的处理后的下载链接:
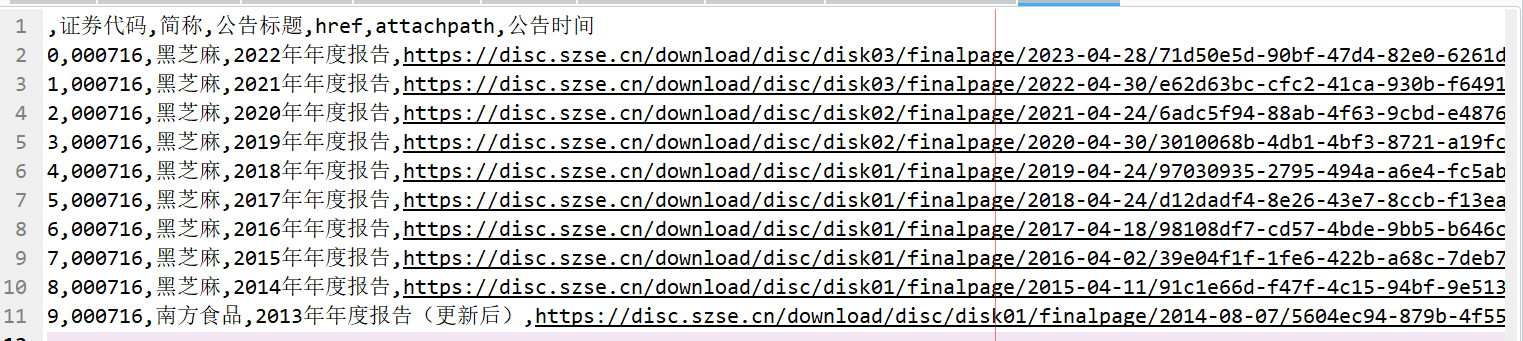
4、公司年报pdf:
'''
解析年报
'''
import re
import pandas as pd
import fitz
def get_subtxt(doc, bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首尾页码
short_pageno = 0
end_pageno = len(doc) - 1
#
lb, ub = bounds #lb:lower bound(下界); ub: upper bound(上界)
# 获取左界页码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
def get_th_span(txt):
nianfen = '(20\d\d|199\d)\s*年末?' #199\d
s = f'{nianfen}\s*{nianfen}.*?{nianfen}'
p = re.compile(s,re.DOTALL)
matchobj = p.search(txt)
#
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
#
while (not flag):
matchobj = p.search(txt[end:])
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
flag = (int(year1) - int(year2) == 1)
flag = flag and (int(year2) - int(year3) == 1)
#
return(matchobj.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])
th_span_2nd = (end + th_span_2nd[0], end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'):
e = e-1
return(s,e+1)
def get_keywords(txt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext, keywords):
# kwds = ['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
#
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
# 获取可能换行的账户名称
matchobj = p.search(line)
account_name = p2.sub('',matchobj.group())
#获取三年数据
amnts = line[matchobj.end():].split()
#加上账户名称
amnts.insert(0, account_name)
#追加到总数据
data.append(amnts)
return(data)
# 测试所写爬取财务信息函数,并将每家公司十年的营业收入和归属于股东的净利润存为csv文件,方便后续作图
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
codes = ['000716','002216','002503','002329','002481','002495','002507','002570','002597','001215']
revenue = []
profit = []
for year in years:
for code in codes:
filename = f'{code}_{year}.pdf'
if os.path.exists(filename):
doc = fitz.open(filename)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt, keywords)
revenue.append(data[0][1])
profit.append(data[1][1])
if not os.path.exists(filename):#若有缺失文件可继续循环
continue
revenue = [float(s.replace(',', '')) for s in revenue]
profit = [float(s.replace(',', '')) for s in profit]
df = pd.DataFrame({'营业收入(元)':revenue,'归属于上市公司股东净利润(元)':profit})
#保存十家公司十年的营业收入csv
df1 =pd.DataFrame('营业收入(元)':revenue)
df1.insert(0,'年份',years)
df1.to_csv('食品行业十家公司十年营业收入信息')
#分别保存十家公司的financial data
num_rows = len(df.index) #获取 DataFrame 的总行数
new_dfs = [] #定义一个空的列表,用于存储每个前十行的 DataFrame
for i in range(0, num_rows, 10):
temp_df = pd.DataFrame(df.iloc[i:i+10], columns=df.columns)
temp_df.insert(0,'年份',years)
new_dfs.append(temp_df)
for i, df in enumerate(new_dfs):
df.to_csv(f"fin_data_{i}.csv", index=False)#手动更名,更名为'fin_data_{code}.csv'的形式
十家公司财务信息csv文件:
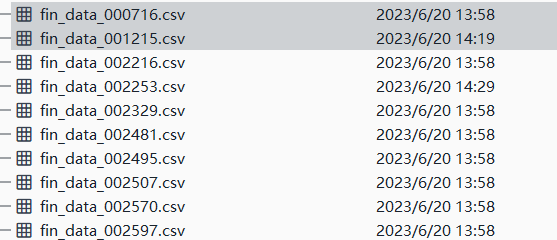
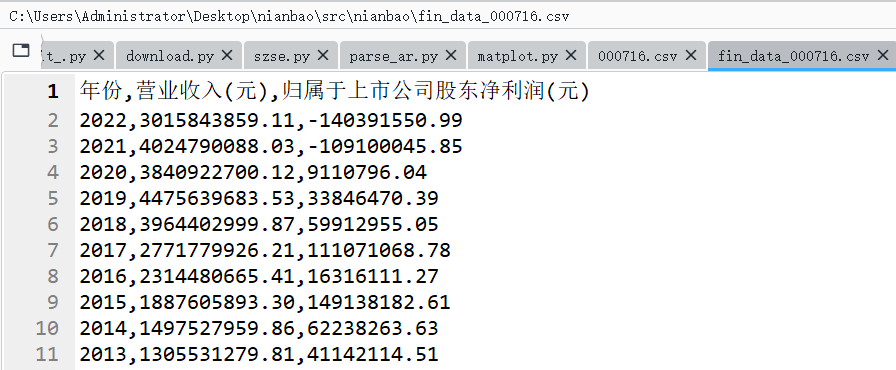
000176的财务信息具体内容(篇幅有效,仅展示一家公司):
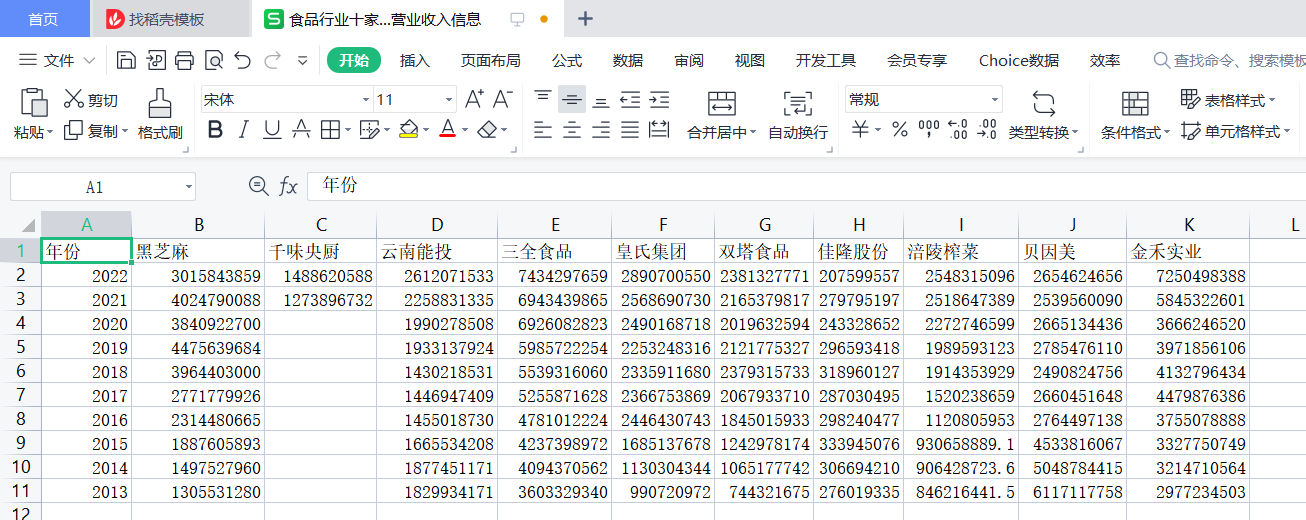
十家公司财务信息中的营业收入信息:
# 定义函数获取PDF页码中的内容
def getText(pdf):
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.get_text()
doc.close()
return(text)
#定义函数获取股票代码,股票简称,办公地址,公司网址,电子信箱,董秘姓名,董秘电话
def get_basic(pdf):
# pdf=list_rp[22]
text = getText(pdf)
p1 = re.compile('\w{1,2}、公司信息(.*?)(?=\w{1,2}、联系人)',re.DOTALL)
subtext = p1.findall(text)
if subtext[0] is None:
p1 = re.compile('\w{1,2}、\s+公司信息(.*?)(?=\w{1,2}、联系人)',re.DOTALL)
subtext = p1.findall(text)
subtext = subtext[0].replace('\n','')
p2 = re.compile('(?<=股票简称)(.*?)(?=股票代码)')
co_name = p2.findall(subtext)
p3 = re.compile('(?<=股票代码)(.*?)(?=股票)')
code = p3.findall(subtext)
p4 = re.compile('(?<=办公地址)(.*?)(?=办公地址的)')
ad = p4.findall(subtext)
p5 = re.compile('(?<=公司网址)(.*?)(?=电子信箱)')
web = p5.findall(subtext)
p6 = re.compile('电子信箱\s*([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})', re.DOTALL)
email = p6.findall(subtext)
#
p1_ = re.compile('二、联系人和联系方式(.*?)三、信息披露及备置地点', re.DOTALL)
subtxt = p1_.findall(text)
if subtxt[0] is None:
p1_ = re.compile('二、联系人和联系方式(.*?)三、信息披露及备置地点', re.DOTALL)
subtxt = p1_.findall(text)
subtxt = subtxt[0].replace('\n','')
p2_ = re.compile('(?<=姓名)(.*?)(?=联系地址)')
dm_name = p2_.findall(subtxt)
p3_ = re.compile('(?<=电话)(.*?)(?=传真)')
dm_pho = p3_.findall(subtxt)
return co_name,code,ad,web,email,dm_name,dm_pho
#测试所写爬取公司信息函数,并将每家公司的公司信息存为csv文件
df_com = pd.read_csv('df_company.csv')
df3 = pd.DataFrame(index=range(len(df_com)))
df3['股票简称'] = ''
df3['股票代码'] = ''
df3['办公地址'] = ''
df3['公司网址'] = ''
df3['电子信箱'] = ''
df3['董秘姓名'] = ''
df3['董秘电话'] = ''
df3.to_csv('公司基本信息.csv')
files = ['000716_2022.pdf','002216_2022.pdf','002053_2022.pdf','002329_2022.pdf','002481_2022.pdf','002495_2022.pdf','002507_2022.pdf','002570_2022.pdf','002597_2022.pdf','001215_2022.pdf' ]
list_rp = [c for c in files ]
# 将股票简称,股票代码,办公地址,公司网址,电子信箱,董秘姓名,董秘电话列为标题并保存为'公司基本信息'名称的csv文件
for i in range(len(list_rp)):
list3 = get_basic(list_rp[i])
for l in range(7):
while ' ' in list3[l][0]:
list3[l][0] = list3[l][0].replace(' ','')
df3['股票简称'][[i]] = list3[0][0]
df3['股票代码'][[i]] = list3[1][0]
df3['办公地址'][[i]] = list3[2][0]
df3['公司网址'][[i]] = list3[3][0]
df3['电子信箱'][[i]] = list3[4][0]
df3['董秘姓名'][[i]] = list3[5][0]
df3['董秘电话'][[i]] = list3[6][0]
df3.to_csv('公司基本信息.csv')
爬取的十家公司的公司信息
'''
财务信息可视化
'''
import pandas as pd
import numpy as np
from pylab import plt, mpl
plt.style.use('seaborn')
mpl.rcParams['savefig.dpi'] = 300
mpl.rcParams['font.sans-serif'] = 'KaiTi'
plt.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
#绘制一家公司十年营业收入与净利润折线图
url = 'fin_data_000716.csv'
data = pd.read_csv(url, index_col=0, parse_dates=True)
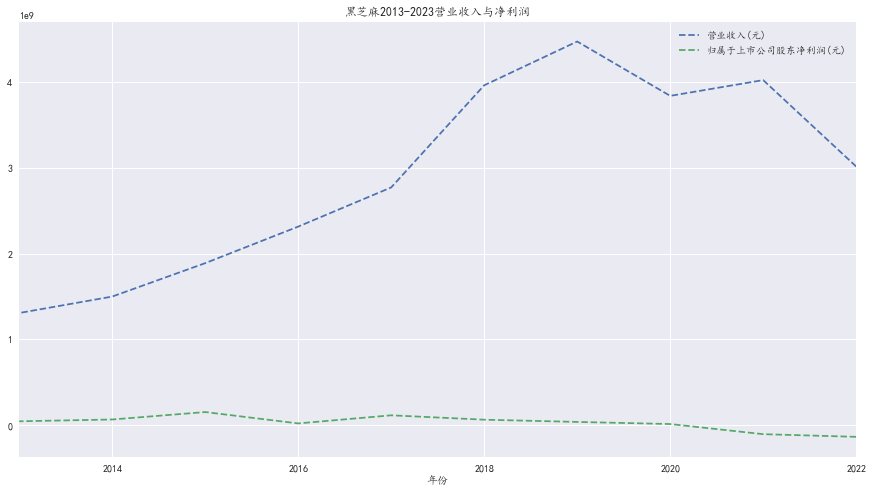
data[['营业收入(元)', '归属于上市公司股东净利润(元)']].plot(figsize=(10, 6), style='--',title='黑芝麻2013-2023营业收入与净利润')
黑芝麻十年营业收入,净利润折线图
import pandas as pd
import numpy as np
plt.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
url = '食品行业十家公司十年营业收入信息.csv'
dt = pd.read_csv(url, index_col=0, encoding='GB2312')
fig,ax = plt.subplots(figsize = (14,8), dpi = 300)
index = np.arange(len(dt))
plt.bar(index,dt['黑芝麻'],width=0.05)
plt.bar(index+0.08,dt['千味央厨'],width=0.08)
plt.bar(index+0.16,dt['云南能投'],width=0.08)
plt.bar(index+0.24,dt['三全食品'],width=0.08)
plt.bar(index+0.32,dt['皇氏集团'],width=0.08)
plt.bar(index+0.40,dt['双塔食品'],width=0.08)
plt.bar(index+0.48,dt['佳隆股份'],width=0.08)
plt.bar(index+0.56,dt['涪陵榨菜'],width=0.08)
plt.bar(index+0.64,dt['贝因美'],width=0.08)
plt.bar(index+0.72,dt['金禾实业'],width=0.08)
plt.legend(['黑芝麻','千味央厨','云南能投','三全食品','皇氏集团','双塔食品',
'佳隆股份','涪陵榨菜','贝因美','金禾实业'])
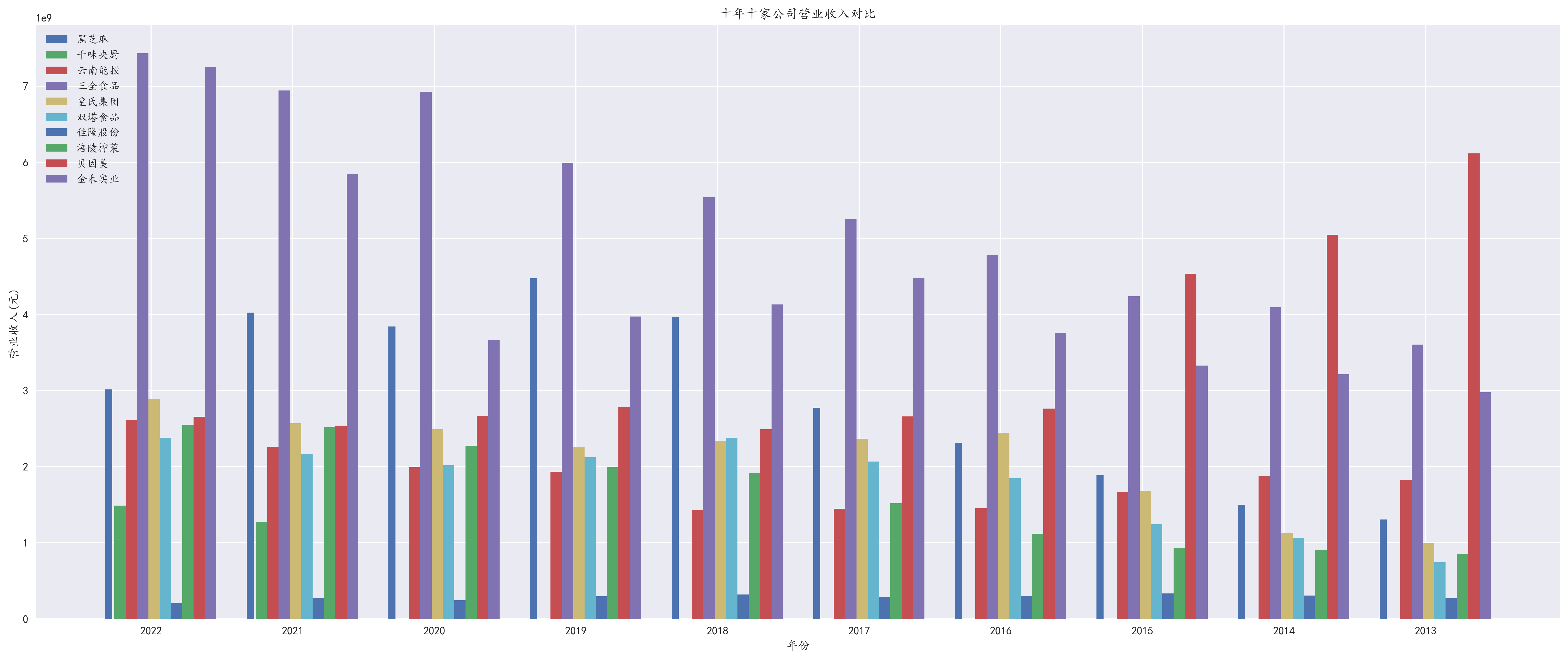
plt.title('十年十家公司营业收入对比')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.xticks(index+0.3,dt.index)
食品行业十年十家公司营业收入对比
总体来说,黑芝麻作为一家食品企业,营收和利润增长情况均较为平稳,并且财务状况良好
黑芝麻近两年营业收入下降可能与一:同行竞争激烈有关。黑芝麻行业内竞争激烈,已经有许多企业开始进行相关业务的拓展,这包括一些新茶、休闲零食等行业内企业
也可能与二:原材料价格上涨有关。黑芝麻的价格一直以来都存在较大波动,近两年,原材料的采购成本有可能过高,导致公司采购的成本增加,失败发扬抵消其更高的营收额
由于因销售费用增加,黑芝麻2019年净利润下滑四成。并且2019年起疫情对经济的冲击也使得黑芝麻的净利润下降。
选取的十家公司均为食品行业的公司,对于食品行业的发展:从宏观来看,近年来,我国居民人均可支配收入和人均消费支出逐年增多,并且食品属于刚需,尽管疫情带来了一定影响,但总体增长势头不改,食品的市场规模也是逐年增加。从微观来看, 品牌竞争日益激烈,随着消费者需求的不断提高,品牌竞争也日益激烈。许多知名品牌通过不断创新和营销手段的提升,取得了市场的领先地位。
黑芝麻在十年中营业收入情况较为平稳,金禾实业的营收表现最好,千味央厨、云南能投、三全食品、皇氏集团等公司营业收入都有不同程度的增长 但也有一些企业营业收入增长不明显或处于波动状态,如贝因美、涪陵榨菜、佳隆股份、双塔食品等
总的来说,这十家公司的营业收入差异较大,但整体趋势是增长的,表明食品行业在过去的十年内有一定的发展前景。
本学期的python课是我所上过的python课中最实用的,本次实验的要求虽然特别清晰,但是在实践过程中就有各种问题。首先是提取所选行业的前十家代码,因为是pdf,所以也使用了正则表达式爬取,对于写正则表达式来说确实是比较困难,花费了一定的时间。其次是下载年报这部分,因为前十家公司都是深交所的所以从获取html到从html中获取链接,只能自己借助老师上课所讲和之前学生的作业来写,在写的过程中也尝试着解决了问题,在解析深交所链接的代码中,刚开始发现用的正则表达式爬的链接总是空的,经过一步步的排查,发现写的正则表达式匹配太广,通过修改正则表达式,成功解决。对于筛选链接这一步,用了自己写的代码,需要注意的就是使用时间戳之后数据的转换。在下载这一步第一次下载发现文件损坏,后与同学老师的交流,发现爬取的href和attachpath弄反了,在调换后成功下载了年报
下载完成后,提取财务信息我也遇到了不少问题。首先是使用的正则表达式提取账户名称,使用老师给的正则表达式会出现账户名称后面粘连数据的情况,经过排查发现对于group2中后半部分无限制,但是奈何水平有限,使用自己改写的正则表达式解决了粘连问题,但是数据容易爬错。其次是千味央厨只有两年的年报所以之间循环会报错,这时候引入continue成功解决问题。对于提取公司信息,主要问题出现在提取独董姓名,因为独董姓名后面紧接着就是证券事务代表姓名所以很难用正则表达式解决,我觉得或许可以用pandas将这个表格爬下来的方法,因为时间有限,所以没有尝试,等有时间会尝试的。
通过这次实验,收获了很多:首先是学会了使用函数来代替循环解决,使得代码更加简洁好看。其次是使用Python解决问题的能力,老师上课讲解非常细致,带着我们发现问题、解决问题,在做中学,确实更容易吸收。最后是提供了很多学习的网站,对于python的学习来说,确实需要个人的努力,比如正则表达式这个东西,需要多练才能向老师一样写的非常迅速
起初是上一届的一个学长推荐我选吴老师,说吴老师的讲解很细致,每次问老师问题,老师都非常耐心,很感谢吴老师对我在这门课中的帮助!