吴诗一的作业三
代码
from bs4 import BeautifulSoup
import re
import pandas as pd
f = open('002295.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open('002295_prettified.html','w', encoding='utf-8')
f.write(html_prettified)
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open('disclosure-table_prettified.html','w', encoding='utf-8')
f.write(html_prettified)
f.close()
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html_prettified)
p1 = re.compile('(.*?年度报告".*?)', re.DOTALL)
td1 = [p1.findall(tr) for tr in trs[1:]]
tds = [td for td in td1 if td!=[] ]
p2 = re.compile('(.*?年度报告摘要".*?)', re.DOTALL)
td2 = [p2.findall(tr) for tr in trs[1:]]
tds1 = [td for td in td2 if td!=[] ]
tds.extend(tds1)
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[0])[0] for td in tds]
p_pub_time = re.compile('.*?finalpage/(.*?)/.*?')
p_times = [p_pub_time.search(td[0]).group(1) for td in tds]
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = pd.DataFrame({'证券代码': tds,
'简称': tds1,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [lf[0].strip() for lf in link_ftitles],
'href': [lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
data = df.sort_values(by = '公告标题',ascending = False)
df.to_csv('data.csv')
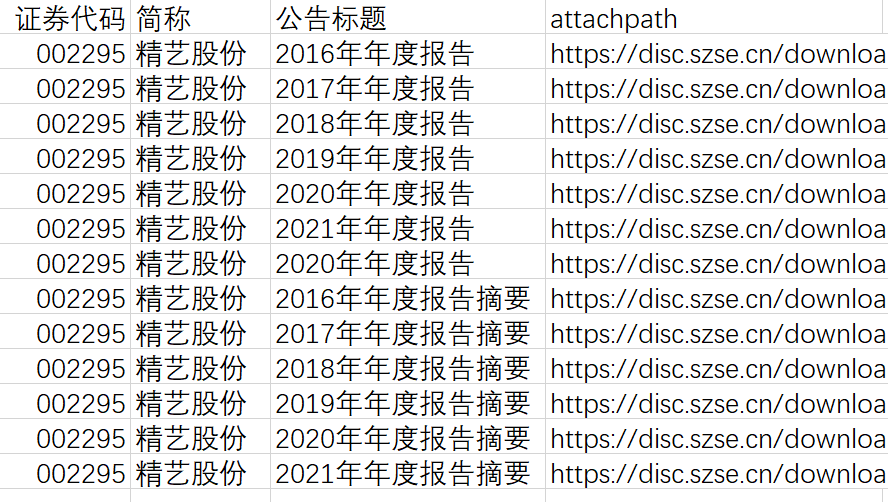
结果