import json
import os
from time import sleep
from urllib import parse
import requests
import time,random
from fake_useragent import UserAgent
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent':userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
list = ['000012','000023','000401','000672','000786','000789','000795','000877','000935','002066']
for company in list:
os.mkdir(company)
orgId, plate, code=get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")
import pdfplumber
import re
import os
import numpy as np
import sys
import csv
import time,datetime
path1="D:\期末实验报告\年报下载\000012"#定义上一步存放pdf所在文件夹
path2="D:\期末实验报告\数据获取"#定义提取后的数据存放文件夹
temfilename = "数据"
name_list=os.listdir(path1)#利用os库获取路径1下的pdf文件名称
print(name_list)
x='000012'
def creat_csv(x,csv_head):
path = str(path2+"\\"+"(%s).csv" % (x))
with open(path,'w',newline='' ,encoding='utf-8_sig') as f:
csv_write = csv.writer(f)
csv_write.writerow(csv_head)
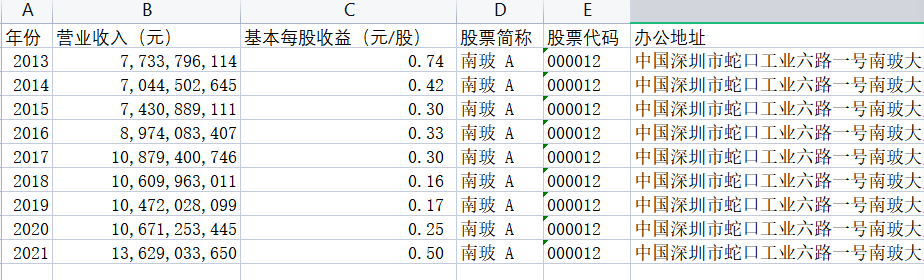
csv_head = ["营业收入(元)","基本每股收益(元/股)","股票简称",
"股票代码","办公地址","公司网址"]
creat_csv(x,csv_head)
def write_csv(x,data_row):
path = str(path2+"\\"+temfilename+"(%s).csv" % (x))
with open(path,mode="a",newline = "",encoding="utf-8_sig") as f:
csv_write = csv.writer(f)
csv_write.writerow(data_row)
import fitz
import re
import pandas as pd
doc = fitz.open('2021年度报表.pdf')
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
os.chdir('..\\')#为了后续将图片保存在父文件夹中
name_list = ['2021',"2020","2019","2018","2017","2016","2015","2014",'2013','2012']
list_name_1 = ['000012','000023','000401','000672','000786','000789','000795','000877','000935','002066']
def y_ticks(list_row,list_name_1):
num_list_1 = list_row
rects = plt.barh(range(len(list_row)),num_list_1,color='rgby')
N = 10
index = np.arange(N)
plt.yticks(index,name_list)
plt.title(list_name_1+" 2012—2021营业收入对比")
plt.xlabel("年份")
plt.ylabel("营业收入(亿元)")
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(list_name_1 +".png",dpi = 600)
plt.show()
for i in range(len(list_row)):
y_ticks(list_row_1[i], list_name_1[i])
def x_ticks2(list_columns_profit,name_list):
num_list = list_columns_profit
rects = plt.bar(range(len(list_columns_profit)),num_list,color="rgb",width = 1,tick_label=list_name_1)
plt.title(name_list+"不同公司每股净收益对比")
plt.xlabel("每股净收益(元)")
plt.ylabel("公司名称")
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(name_list +"净收益.png",dpi = 600)
plt.show()
for i in range(len(list_columns_profit)):
x_ticks2(list_columns_profit[i], name_list[i])
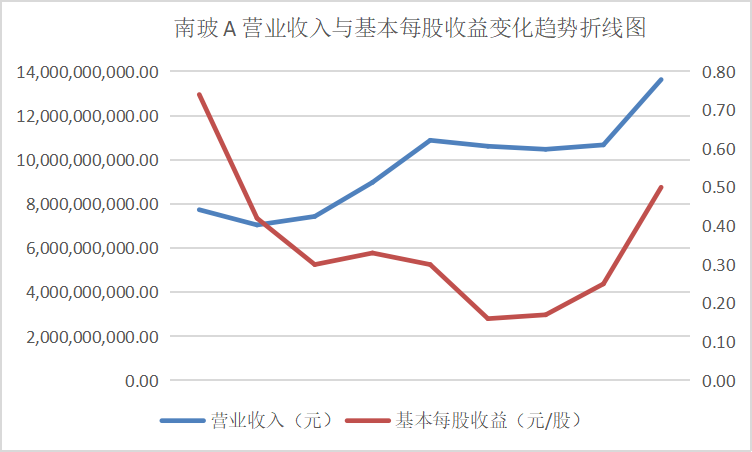
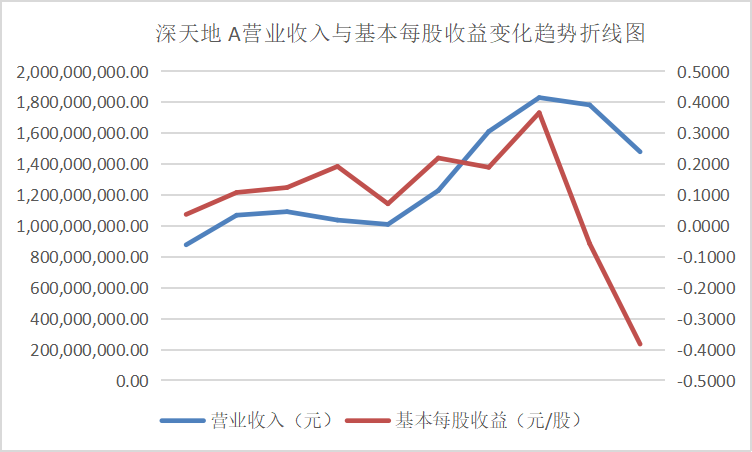
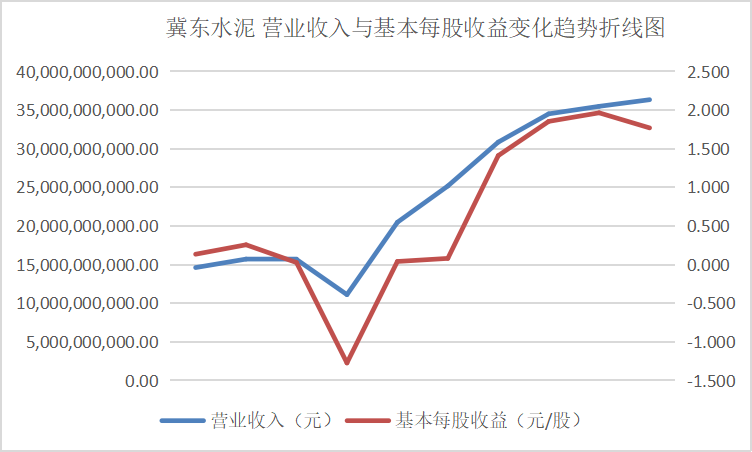
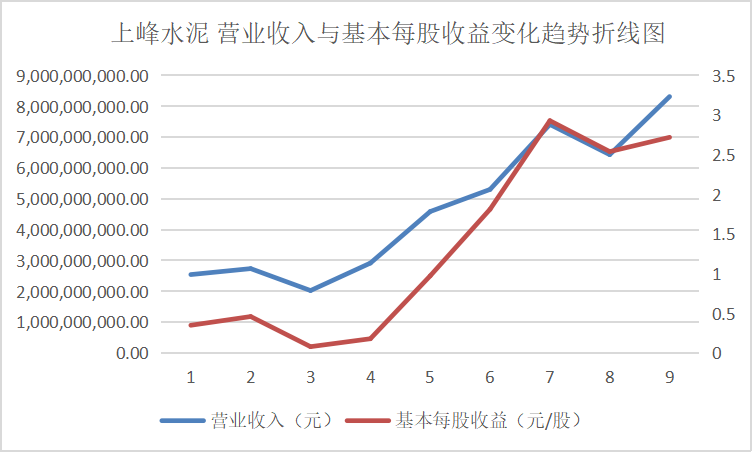
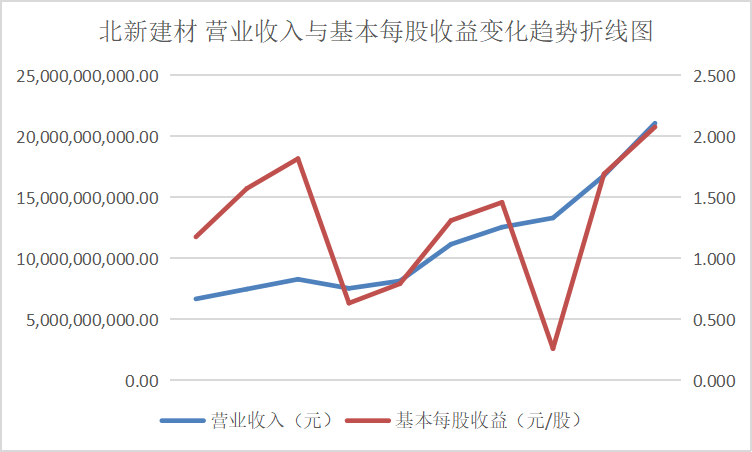
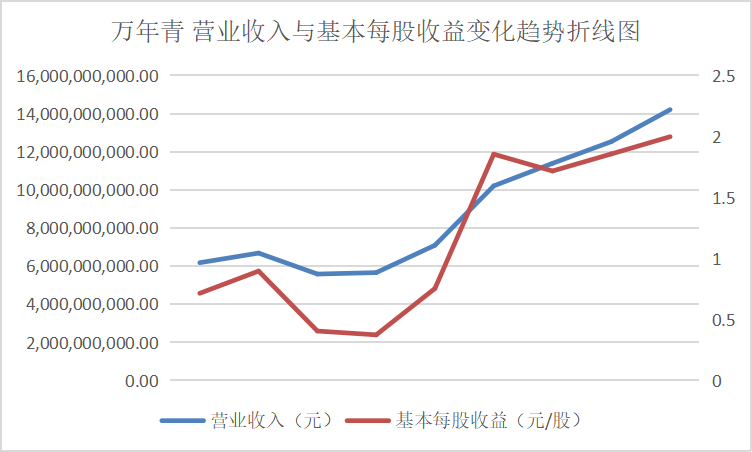
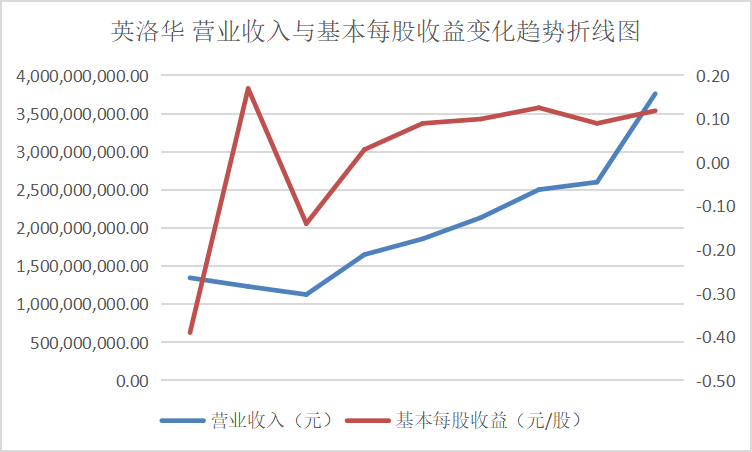
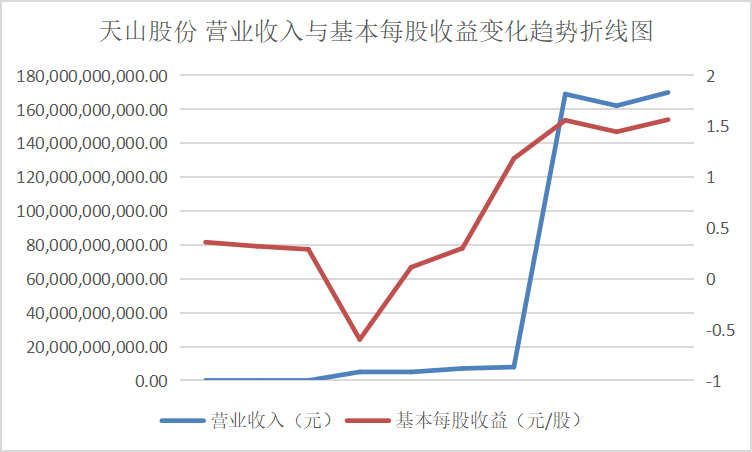

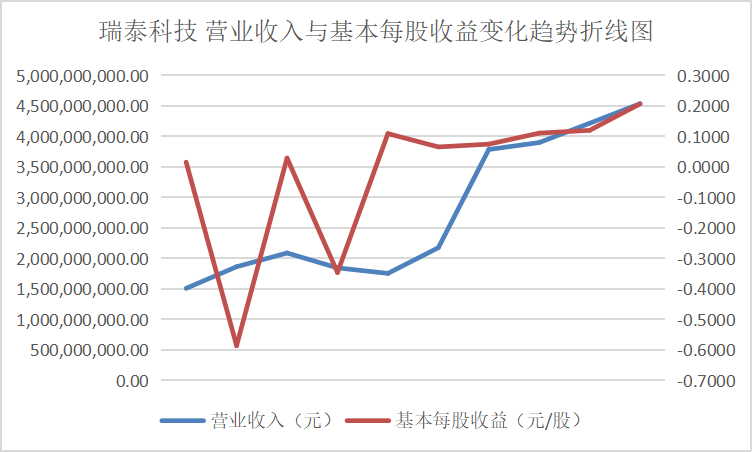
从营业收入与基本每股收益变化趋势折线图中可以看出这些行业的领头企业,在近十年的发展过程中一直保持这稳步上升的势头,并且观察变动趋势可以得出其在2016、2017年左右出现较大幅度的增长,通过经济学方面的知识与素养猜测可能与那几年的房地产热有关。从总体来看该行业仍然保持着增长的势头,但却由于生态环保的需要也面临着巨大的转型压力。