import json
import os
from time import sleep
from urllib import parse
import requests
import time,random
from fake_useragent import UserAgent
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent':userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
list = ['601515','603058','603429','603499']
for company in list:
os.mkdir(company)
orgId, plate, code=get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import pdfplumber
import pandas as pd
import re
import time
import os
import requests
if not os.path.exists("sz"):
os.mkdir("sz")#深交所
if not os.path.exists("sh"):
os.mkdir("sh")#上交所
def GetShHtml(code, name):
browser = webdriver.Chrome()
browser.get("http://www.sse.com.cn//disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
html = browser.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
time.sleep(3)
f = open(name +'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
time.sleep(3)
browser.quit()
def GetSzHtml(name):
driver = webdriver.Chrome()
driver.get("https://www.szse.cn/disclosure/listed/fixed/index.html")
driver.set_window_size(683, 657)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
html = driver.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
time.sleep(3)
f = open(name +'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
time.sleep(3)
driver.quit()
df = pd.read_excel("company.xlsx")
for index, row in df.iterrows():
a = row['Flag']
name = row['上市公司简称']
code = row['上市公司代码']
if a == 1:
os.chdir("sh")
GetShHtml(code, name)
os.chdir('../')
else:
os.chdir("sz")
GetSzHtml(name)
os.chdir('../')

import re
import pandas as pd
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Read_html(filename):
f = open(filename+'.html', encoding='gbk')
html = f.read()
f.close()
return html
def Clean(df): #清除“摘要”型、“(已取消)”型文件、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Load_pdf(df): #下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
os.chdir(r"C:\Users\楚门\py大作业\html_sz")
for company in ('滨海能源','陕西金叶','东港股份','劲嘉股份','鸿博股份','盛通股份','新宏泽','金时科技','天元股份'): #下载深圳证券交易所的年报
html = Read_html(company)
dt = DisclosureTable(html)
dt1 = dt.get_data()
df = Clean(dt1)
df.to_csv("../../html/"+company+".csv",encoding="gbk")
os.makedirs("../../年报_sz/"+company,exist_ok=True)
os.chdir("../../年报_sz/"+company)
Load_pdf(df)
os.chdir("../../html/html_sz")
import os
import re
import pandas as pd
import requests
import fitz
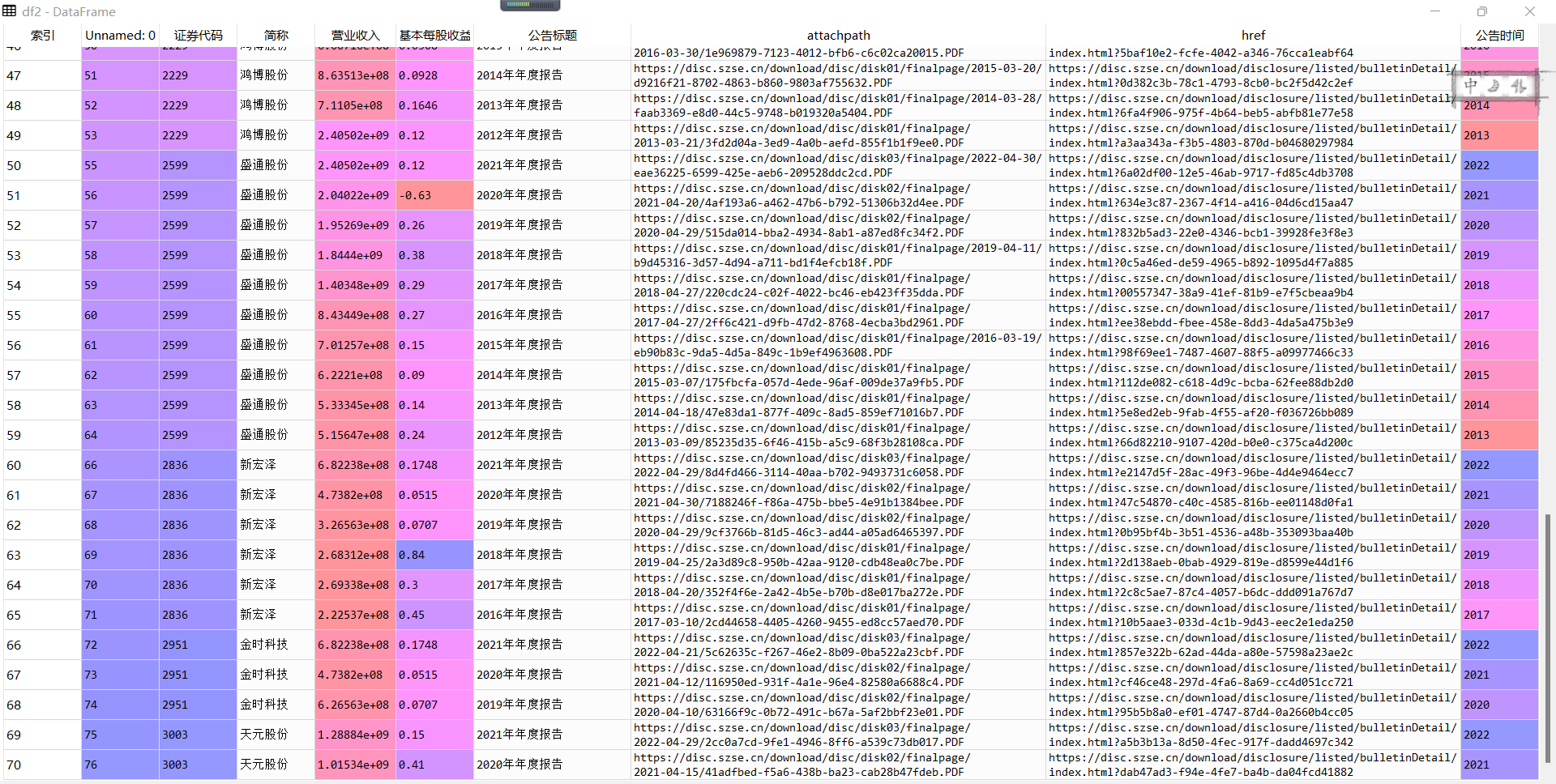
Company = pd.read_excel(r'C:\Users\楚门\py大作业\companysh.xlsx')
company = Company.iloc[:,2].tolist()
t=0
for com in company:
t+=1
os.chdir(r"C:\Users\楚门\py大作业\csv_sh")
df = pd.read_csv(com+'.csv',converters={'证券代码':str})
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2012,2021),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)):
os.chdir(r"C:/Users/楚门/py大作业/年报sh")
title = df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(20):
page = doc[j]
text += page.get_text()
p_year = re.compile('.*?\n?(20\d{2})\s?.*?\n?年\n?度\n?报\n?告\n?.*?')
year = int(p_year.findall(text)[0]) #运行时偶尔会出现问题,有待进一步解决
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web = re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue = float(p_rev.search(text).group(1).replace(',',''))
eps = p_eps.search(text).group(1)
final.loc[year,'营业收入(元)'] = revenue
final.loc[year,'基本每股收益(元/股)'] = eps
final.to_csv('%s数据.csv' %com,encoding='utf-8-sig')
site = p_site.search(text).group(1)
web = p_web.search(text).group(1)
with open('%s数据.csv'%com,'a',encoding='utf-8-sig') as f:
content = '股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)

import os
import re
import pandas as pd
import requests
import sh包
os.chdir("sh")
a = os.getcwd()
for i,j,k in os.walk(a):
sh = k
class WashData():
def __init__(self, html):
self.html = html
self.p_txt = re.compile("(.*?)", re.DOTALL)
self.p_tr = re.compile("(.*?) ", re.DOTALL)
self.p_base = re.compile('(.*?)',re.DOTALL)
self.p_title = re.compile('(.*?)

import pandas as pd
df1 = pd.read_excel("sh.xlsx")
df2 = pd.read_excel("sz.xlsx")
df3 = pd.concat([df1,df2],ignore_index=True)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
#按股票分组
group_stock = df3.groupby('简称')
for key, value in group_stock:
y1 = value['营业收入'].tolist()
y2 = value['基本每股收益'].tolist()
x = value['公告时间'].tolist()
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(x, y1)
ax1.set_ylabel('Revenue')
ax1.set_title(key)
ax2 = ax1.twinx() # this is the important function
ax2.plot(x, y2, 'r')
ax2.set_ylabel('Share_earning')
ax2.set_xlabel('year')
plt.savefig(key+".png")
#按年度分组
group_year_Revenue = df3.groupby('公告时间')
for key, value in group_year_Revenue:
y1 = value['营业收入'].tolist()
y2 = value['基本每股收益'].tolist()
x = value['简称'].tolist()
plt.title(key)
plt.xlabel('简称')
plt.ylabel('营业收入')
plt.bar(x, y1)
plt.savefig(str(key)+"收益.png")
group_year_Share_earning = df3.groupby('公告时间')
for key, value in group_year_Share_earning:
y1 = value['基本每股收益'].tolist()
x = value['简称'].tolist()
plt.title(key)
plt.xlabel('简称')
plt.ylabel('营业收入')
plt.bar(x, y1)
plt.savefig(str(key)+"每股收益.png")
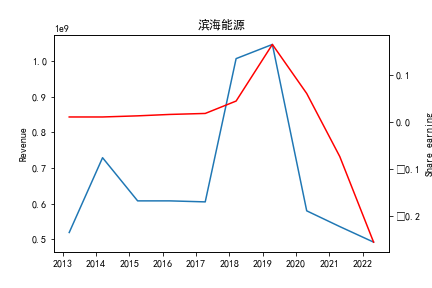
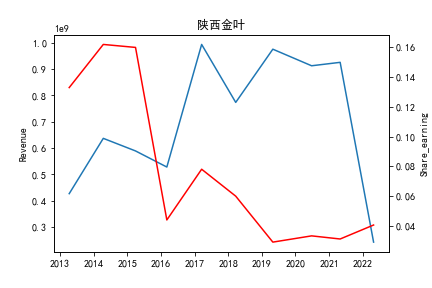
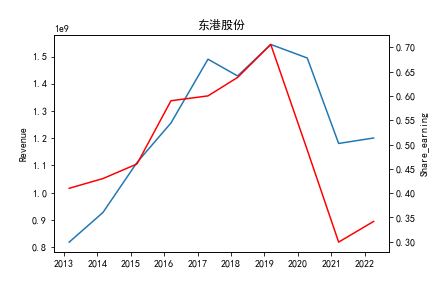
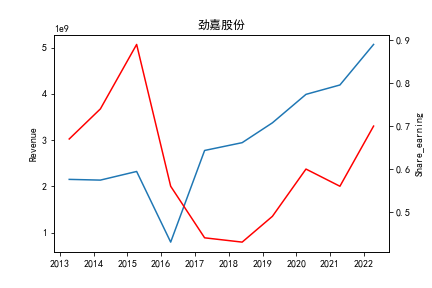
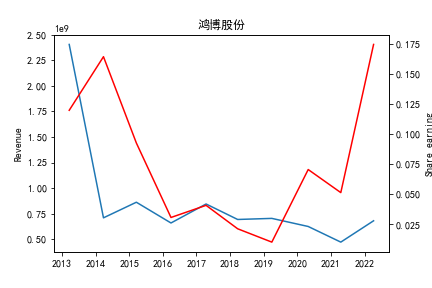
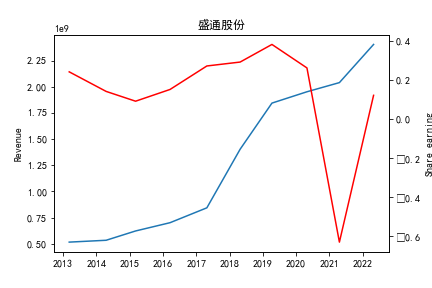
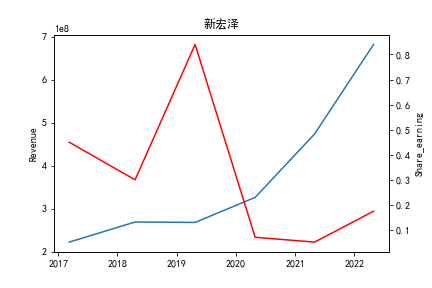
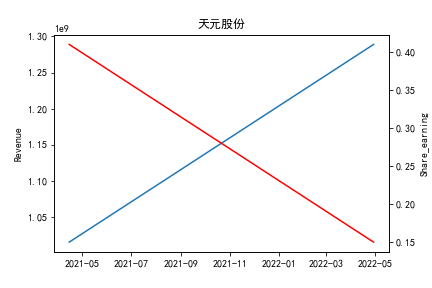
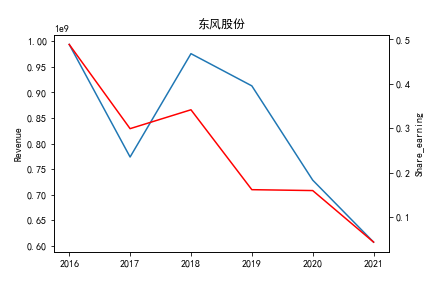
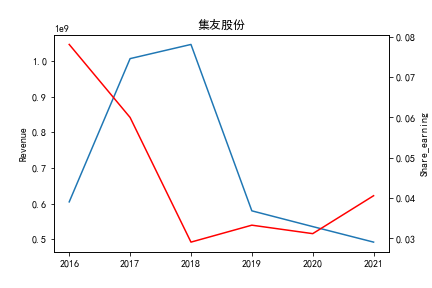
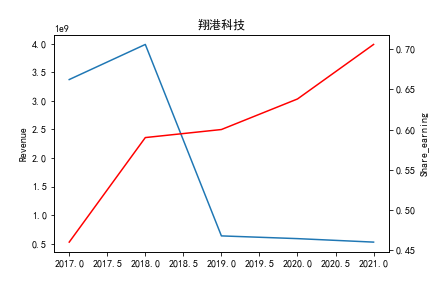
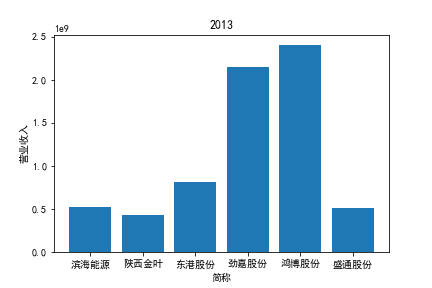
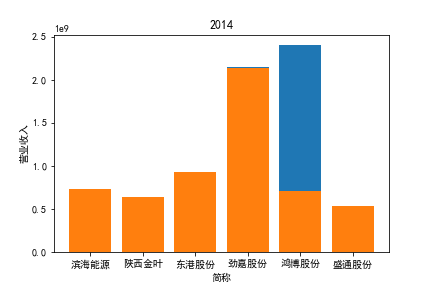
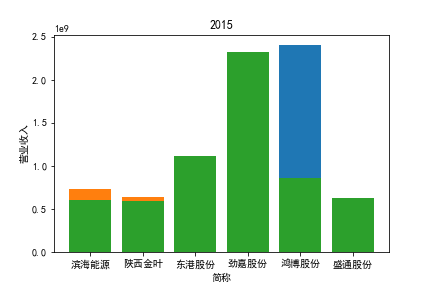

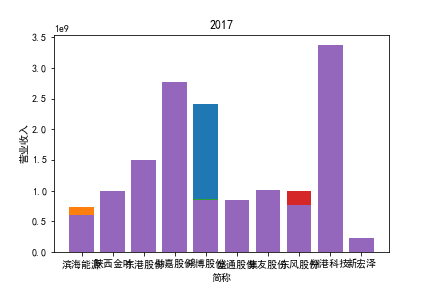
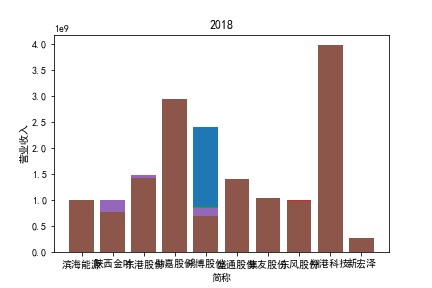
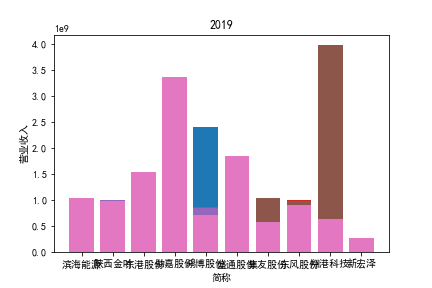
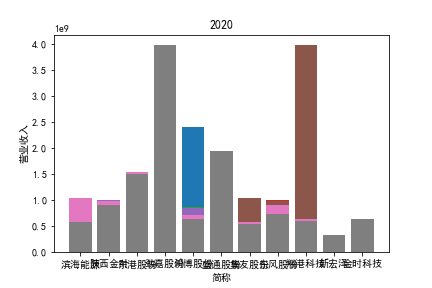
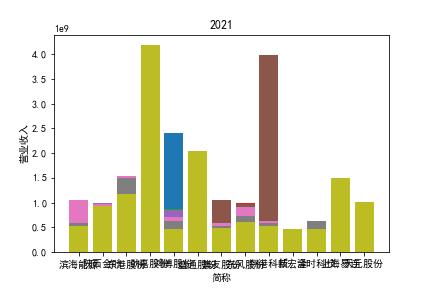
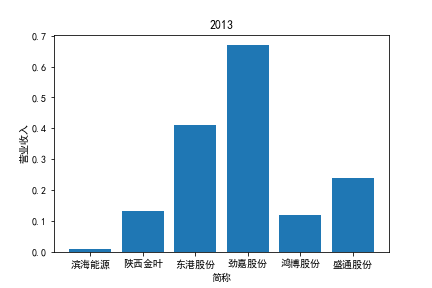
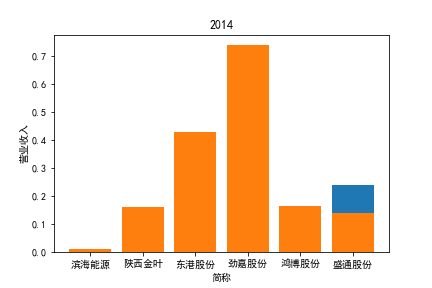
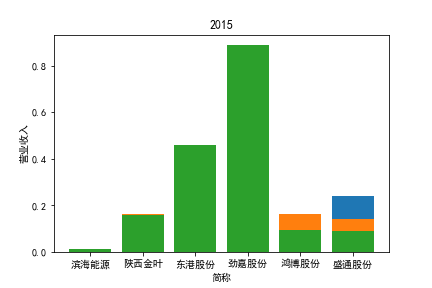
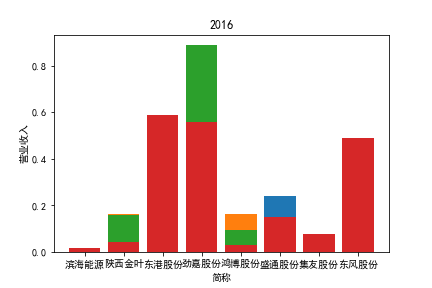
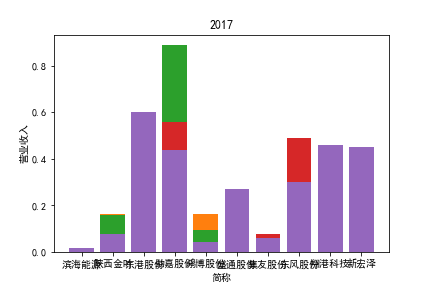
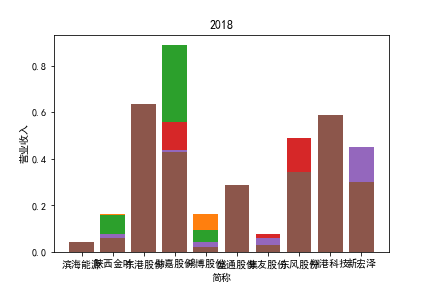
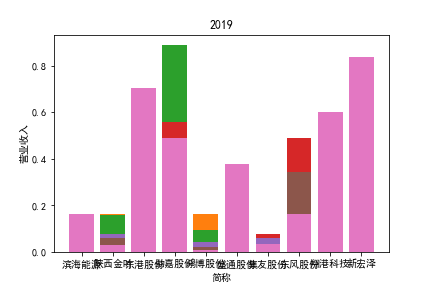

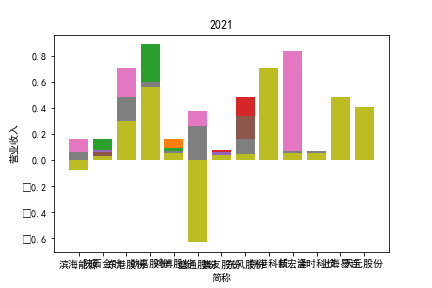
从整体上看,我国印刷包装行业规模以上企业数量(年主营业务2000万元及以上全部工业法人企业)呈稳步上升的趋势,足见随着行业入局者的逐渐增多,这一领域的市场竞争正变得愈加激烈。
新冠疫情冲击对印刷包装下游消费市场造成短期压制,订单萎缩,上游原材料价格上涨,且传统印刷包装企业线上线下闭环缺失,导致销售订单和生产环节脱节,因此,2020年,全国印刷包装细分行业累计营业收入出现同比下降的情况。几乎每一家公司在2019年末到2021年营业收入和基本每股收益都有较大的下降趋势。
2017年前,劲嘉股份和鸿博股份一直是行业的龙头,而17年之后,市场上逐渐出现如新宏泽,东风股份和翔港科技这样的后起之秀,营业收入和基本每股收益突飞猛进显著上升。
这次作业对我来说本是一项不可能完成的任务,但是一步一步静下心来仔细思考,多方面自学,拓展知识,耐心调错,最终呈现出这一份报告让人觉得有前所未有的自豪感,一切都是值得的。
刚开始看到作业的这些要求根本想都不敢想,虽然都是我们上课学过的知识的延伸,但对于我们自身知识点的掌握情况和对于正则表达式、Python爬虫各种库的应用的熟练程度有非常高的要求。思路清晰后,又面临实操问题,不管是每一种函数的调用,还是各种各样的小细节,费劲千辛万苦改正一个报错后,一个又一个报错接连蹦出来消磨我的耐心,调错真的快调疯了!!这个过程异常痛苦,但得到运行结果的那一刻真的会有种喜极而泣的冲动。同时这也反映出我在学习Python的过程中不注重细节,犯了很多低级错误,更是提醒我们学习并非纸上谈兵,只有真真切切自己动手才能发现问题并得到真正意义上的提升。
最后感谢吴老师的悉心教导,耐心解答。在吴老师的言传身教下我真正意义上的认识了Python的强大,并对深入探索其中的奥秘产生浓厚兴趣。今后我愿意继续深入学习金融数据获取与处理的相关知识,努力将所学运用到实践。