# -*- coding: utf-8 -*-
import os
#输入姓名,即可确定该学生所需要爬取的股票名称,并导出表格
os.system("python Target.py")
#根据导出的表格,进行网页爬取,并分深沪市存储(二者的网页解析不同)
os.system("python GetHtml.py")
#根据储存结果,分别相应网页的解析-年报下载-数据提取
os.system("python download_sz.py")
os.system("python download_sh.py")
#合并结果
import pandas as pd
df1 = pd.read_excel("sh.xlsx")
df2 = pd.read_excel("sz.xlsx")
df3 = pd.concat([df1,df2],ignore_index=True)
#绘图前期准备
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
#按股票分组绘图保存
group_stock = df3.groupby('Name')
for key, value in group_stock:
y1 = value['Revenue'].tolist()
y2 = value['Share_earning'].tolist()
x = value['Year'].tolist()
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(x, y1)
ax1.set_ylabel('Revenue')
ax1.set_title(key)
ax2 = ax1.twinx() # this is the important function
ax2.plot(x, y2, 'r')
ax2.set_ylabel('Share_earning')
ax2.set_xlabel('year')
plt.savefig(key+".png")
#按年度分组收益率柱状图
group_year_Revenue = df3.groupby('Year')
for key, value in group_year_Revenue:
y1 = value['Revenue'].tolist()
y2 = value['Share_earning'].tolist()
x = value['Name'].tolist()
plt.title(key)
plt.xlabel('name')
plt.ylabel('Revenue')
plt.bar(x, y1)
plt.savefig(key+"收益率.png")
#按年度分组每股收益柱状图
group_year_Share_earning = df3.groupby('Year')
for key, value in group_year_Share_earning:
y1 = value['Share_earning'].tolist()
x = value['Name'].tolist()
plt.title(key)
plt.xlabel('name')
plt.ylabel('Share_earning')
plt.bar(x, y1)
plt.savefig(key+"每股收益.png")
# -*- coding: utf-8 -*-
import pdfplumber
import pandas as pd
pdf = pdfplumber.open(r"E:\桌面整理\各式材料\金融科技196\212学期\金融数据获取与处理\industry.pdf")
sz = ['200','300','301','00','080']
sh = ['600', '601', '603', '605', '688']
csv = pd.read_csv(r'E:\桌面整理\各式材料\金融科技196\212学期\金融数据获取与处理\001班行业安排表.csv',converters={'行业':str})[['行业','完成人']]
def OrderStudent(csv):
name = str(input('请输入姓名:'))
num = csv[csv.完成人 == name].index.tolist()
a = str(num[0])
return a
def GetTable(pdf):
page_count = len(pdf.pages)
data = []
for i in range(page_count):
data += pdf.pages[i].extract_table()
pdf.close()
d1 = pd.DataFrame(data,columns=data[0]).iloc[:,1:]
d1 = d1.ffill()
data = d1.drop(d1[d1['行业大类代码'] == '行业大类代码'].index)
return data
def MarchStudentTable(a, data):
df = data.loc[data['行业大类代码']==a]
return df
def ClassifyBourse(data):
sz = {}
sh = {}
data1 = data.copy()
data1['CODE'] = data1['上市公司代码'].astype(str)
data1['Flag'] = ''
for index, row in data1.iterrows():
if row['CODE'].startswith('6'):
row['Flag'] = 1
sh[row['上市公司代码']] = row['上市公司简称']
else:
row['Flag'] = 0
sz[row['上市公司代码']] = row['上市公司简称']
return data1, sz, sh
num = OrderStudent(csv)
df1 = GetTable(pdf)
data = MarchStudentTable(num, df1)
pre_company, sz_company, sh_company = ClassifyBourse(data)
df = pre_company.drop(columns=['行业大类代码', '行业大类名称', "CODE"])
df.to_excel("pre_company.xlsx", encoding = 'utf-8')
# -*- coding: utf-8 -*-
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import pdfplumber
import pandas as pd
import re
import time
import os
import requests
#由于深沪二市html完全不一致,所以分不同文件夹储存
if not os.path.exists("sz"):
os.mkdir("sz")#存深圳股票
if not os.path.exists("sh"):
os.mkdir("sh")#存上海股票
def GetShHtml(code, name):
browser = webdriver.Chrome()
browser.get("http://www.sse.com.cn//disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
html = browser.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
time.sleep(3)
f = open(name +'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
time.sleep(3)
browser.quit()
def GetSzHtml(name):
driver = webdriver.Chrome()
driver.get("https://www.szse.cn/disclosure/listed/fixed/index.html")
driver.set_window_size(683, 657)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
html = driver.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
time.sleep(3)
f = open(name +'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
time.sleep(3)
driver.quit()
df = pd.read_excel("pre_company.xlsx")
for index, row in df.iterrows():
a = row['Flag']
name = row['上市公司简称']
code = row['上市公司代码']
if a == 1:
os.chdir("sh")
GetShHtml(code, name)
os.chdir('../')
else:
os.chdir("sz")
GetSzHtml(name)
os.chdir('../')
# -*- coding: utf-8 -*-
import os
import re
import pandas as pd
import requests
import fitz
import nianbao_sz
os.chdir("sz")
a = os.getcwd()
for i,j,k in os.walk(a):
sz = k
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
f = open(filename, encoding='utf-8')
html = f.read()
f.close()
return html
def tidy(df):#清除“摘要”型、“(已取消)”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
def GetData(df_final):
a = os.getcwd()
pdfs = os.listdir(a)
for pdf in pdfs:
fun = nianbao_sz.GetInfor(pdf)
year = fun.year
name, code, location, web = fun.GetName()
revenue, share_earning = fun.GetFin()
lst = [year, name, code, location, web, revenue, share_earning]
df_final.loc[len(df_final)] = lst
return df_final
df_final = pd.DataFrame(columns=['Year','Name','Code', 'Location', 'Web', 'Revenue', 'Share_earning'])
#下载年报
for name in sz:
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(sz),'所公司。当前第',sz.index(name)+1,'所。')
os.chdir('../')
#提取年报
for name in sz:
os.chdir(name)
df_final = GetData(df_final)
print(name+'年报已提取。共',len(sz),'所公司。当前第',sz.index(name)+1,'所。')
os.chdir('../')
df_final.to_excel("sz.xlsx")
# -*- coding: utf-8 -*-
import os
import re
import pandas as pd
import requests
import nianbao_sh
os.chdir("sh")
a = os.getcwd()
for i,j,k in os.walk(a):
sh = k
class WashData():
def __init__(self, html):
self.html = html
self.p_txt = re.compile("(.*?)", re.DOTALL)
self.p_tr = re.compile("(.*?) ", re.DOTALL)
self.p_base = re.compile('(.*?)',re.DOTALL)
self.p_title = re.compile('(.*?)
# -*- coding: utf-8 -*-
import os
import re
import pandas as pd
import requests
import fitz
class GetInfor():
def __init__(self, pdf):
self.pdf = pdf
self.year = self.pdf[0:4]
doc = fitz.open(self.pdf) #打开pdf
self.text = [page.get_text() for page in doc]
self.text = ''.join(self.text)
#self.GetName()
#self.name, self.code, self.address, self.web = GetName()
#self.revenue, self.share_earning = GetFin()
def GetName(self):
p_basic_information = re.compile(r'(?<=\n)\w{1,2}、.*?公司信息\s*?(?=\n)')#匹配小节的标题
section_match = p_basic_information.search(self.text)#抓取小节的标题
s_idx = section_match.start()#定位小节的标题
#获取公司名称&股票代码
p_name = re.compile('股票简称(.*?)股票代码(.*?)[公司的中文名称|股票上市证券交易所]',re.DOTALL)
name = p_name.search(self.text[s_idx:]).group(1)
code = p_name.search(self.text[s_idx:]).group(2)
#获取办公地址
p_location = re.compile('办公地址(.*?)办公地址的邮政编码',re.DOTALL)
location = p_location.search(self.text[s_idx:]).group(1)
#获取公司网址
p_web = re.compile('网址\s*(.*?)电子信箱',re.DOTALL)
web = p_web.search(self.text[s_idx:]).group(1)
return(name, code, location, web)
def GetFin(self):
#营业收入&每股收益
p = re.compile(r'(?<=\n)\w{1,2}、.*?会计数据和财务指标\s*?(?=\n)') #匹配小节的标题
section_match = p.search(self.text) #抓取小节的标题
s_idx = section_match.start() #定位小节的标题
#获取营业收入
p_r = re.compile('营业收入(.*?)归属于',re.DOTALL) #匹配年报中营业收入
data_line_r = p_r.search(self.text[s_idx:]).group()
data_line_r = data_line_r.replace('\n', '') #有些年报格式不标准,数字有了换行,所以把换行符替换掉。
p_digit_r = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字,获取所有','和0-9的数字,直到小数点后2位为止。
revenue = p_digit_r.search(data_line_r).group() #搜寻data_line中的p_digit内容
revenue = revenue.replace(',','') #把revenue里的逗号去掉
#获取每股收益
p_s = re.compile('基本每股收益[(元/股)|(元/\n股)](.*?)[稀释]',re.DOTALL)
data_line_s = p_s.search(self.text[s_idx:]).group()
p_digit_s = re.compile(r'(-)?\d[0-9]*?\.\d{1,4}')
share_earning = p_digit_s.search(data_line_s).group()
return(revenue, share_earning)
# -*- coding: utf-8 -*-
import os
import re
import pandas as pd
import requests
import fitz
class GetInfor():
def __init__(self, pdf):
self.pdf = pdf
doc = fitz.open(self.pdf) #打开pdf
self.text = [page.get_text() for page in doc]
self.text = ''.join(self.text)
p_year = re.compile("(.*?)年年度报告",re.DOTALL)
self.year = p_year.search(self.text).group(1)
#self.GetName()
#self.name, self.code, self.address, self.web = GetName()
#self.revenue, self.share_earning = GetFin()
def GetName(self):
p_basic_information = re.compile(r'(?<=\n)\w{1,2}、.*?公司信息\s*?(?=\n)')#匹配小节的标题
section_match = p_basic_information.search(self.text)#抓取小节的标题
s_idx = section_match.start()#定位小节的标题
#获取公司名称&股票代码
p_name = re.compile('公司简称:(.*?)\n',re.DOTALL)
name = p_name.search(self.text).group(1)
p_code = re.compile('代码:(.*?)\s+',re.DOTALL)
code = p_code.search(self.text).group(1)
#获取办公地址
p_location = re.compile('办公地址(.*?)办公地址的邮政编码',re.DOTALL)
location = p_location.search(self.text[s_idx:]).group(1)
#获取公司网址
p_web = re.compile('网址\s*(.*?)电子信箱',re.DOTALL)
web = p_web.search(self.text[s_idx:]).group(1)
return(name, code, location, web)
def GetFin(self):
#营业收入&每股收益
p = re.compile(r'(?<=\n)\w{1,2}、.*?会计数据和财务指标\s*?(?=\n)') #匹配小节的标题
section_match = p.search(self.text) #抓取小节的标题
s_idx = section_match.start() #定位小节的标题
#获取营业收入
p_r = re.compile('营业收入(.*?)[扣除与|归属于]',re.DOTALL) #匹配年报中营业收入
data_line_r = p_r.search(self.text[s_idx:]).group()
data_line_r = data_line_r.replace('\n', '') #有些年报格式不标准,数字有了换行,所以把换行符替换掉。
p_digit_r = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字,获取所有','和0-9的数字,直到小数点后2位为止。
revenue = p_digit_r.search(data_line_r).group() #搜寻data_line中的p_digit内容
revenue = revenue.replace(',','') #把revenue里的逗号去掉
#获取每股收益
p_s = re.compile('基本每股收益(.*?)稀释',re.DOTALL)
data_line_s = p_s.search(self.text[s_idx:]).group()
p_digit_s = re.compile(r'(-)?\d[0-9]*?\.\d{1,4}')
share_earning = p_digit_s.search(data_line_s).group()
return(revenue, share_earning)
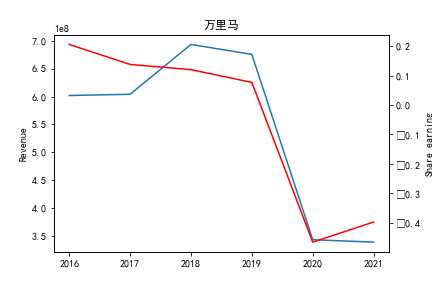
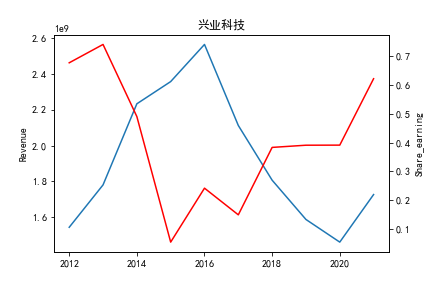
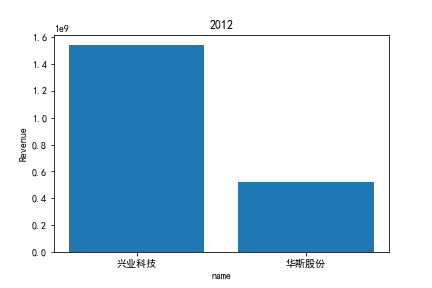
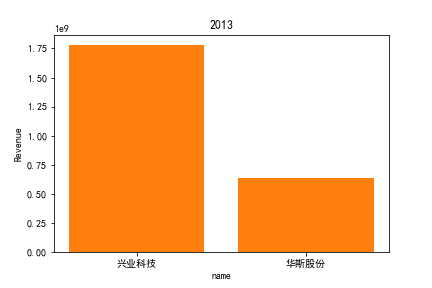
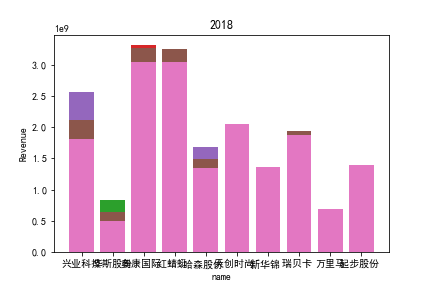
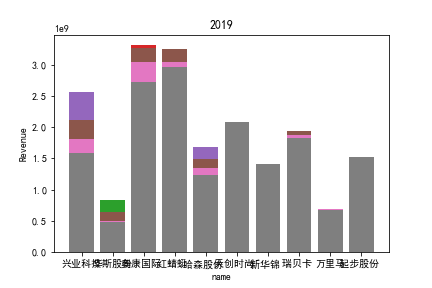
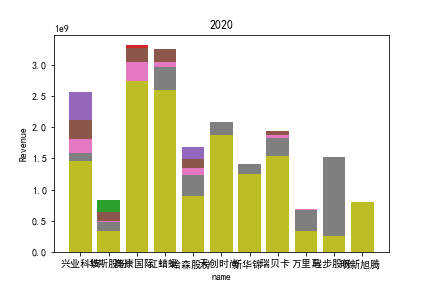
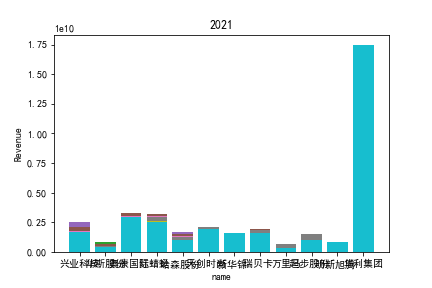
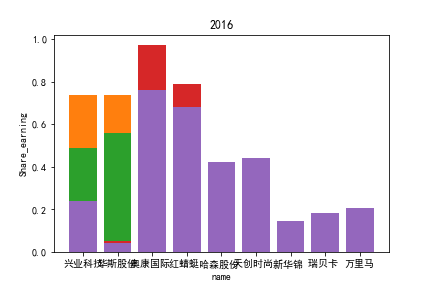
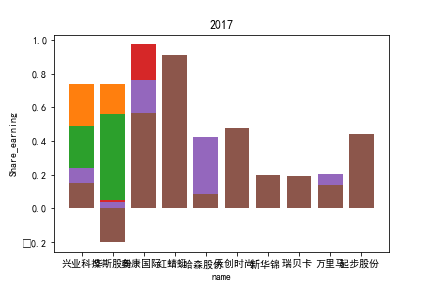
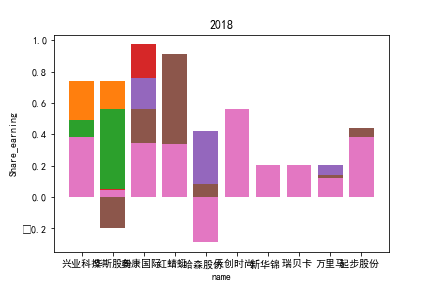
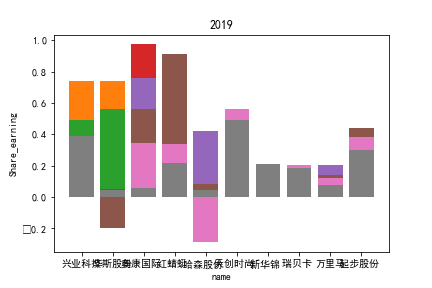
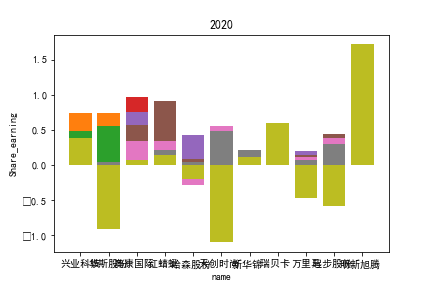
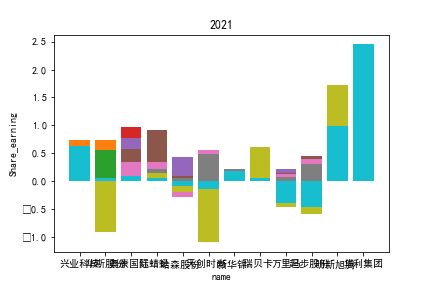
因为路径配置等问题,该代码可能出现在其他设备上难以运行的情况
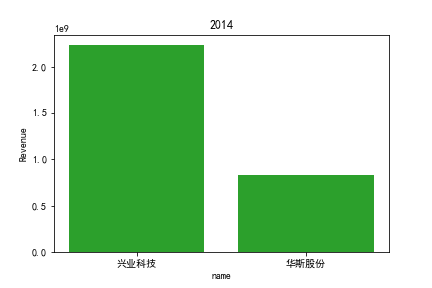
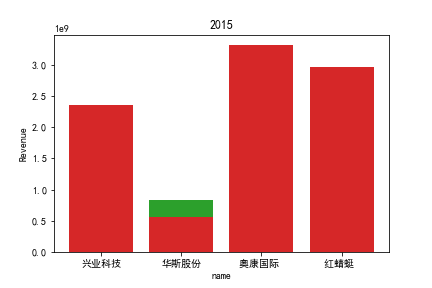
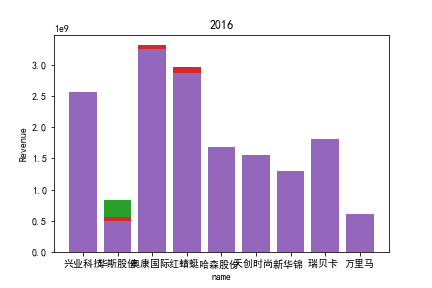
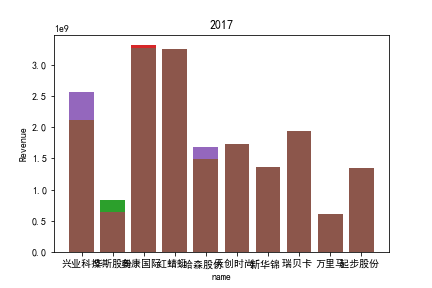
1.营业收入解读
同年度不同公司进行对比可以发现当华利集团上市之后,该股市的营业收入立即表现出遥遥领先的优势,可以看出该公司在行业的领先地位。 大致可以将公司表现分为三个水平。
分别是华利集团作为第一层次,老牌的红蜻蜓、奥康国际和兴业科技作为第二层次,剩下的上市公司作为第三层次。这三个层次的公司反映了较大差距的营业水平收入表现。 可以发现,除了异军突起的华利集团之外,剩下的作为第二层次且与第三层次存在较大差距的红蜻蜓,奥康国际和兴业科技均为生耕该行业多年的企业,该行业他们往往具有较强的上下游产业链聚合能力以及良好的品牌形象。
在上市年限较久的公司中,除华斯股份表现不加外,对营业收入而言均有较为良好的表现。说明该行业存在较大的先发优势,或者说率先抢占市场份额对于该行业有着较为大的良性影响,侧面反映出该行业技术壁垒不强,企业的护城河,主要围绕自然垄断建立。衣物、皮革等制造行业确实也不存在较高的技术难度,主要为劳动密集型产业。
但华利集团的表现也向我们证明,比起曾经大水漫灌式的业务销售或许垂直投送业务与某一特定领域也可以突破重围,创出一片新天地。
同公司不同年度进行分析则发现无论上市早晚,公司均在2020年度产生业绩上的重大减值,由于分析行业为皮草衣物类,为劳动密集型产业,技术壁垒较低,生产品为生活一般消费品。所以该行业受到疫情冲击影响较大。不仅2020年度许多公司营业收入受到重创,即使2021年度营业收入也没有完全恢复,说明疫情带来的对该行业的冲击影响较为长久。
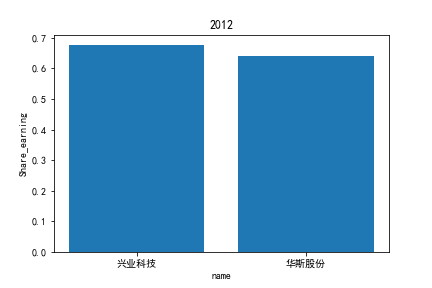
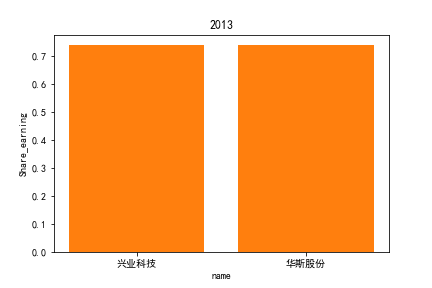
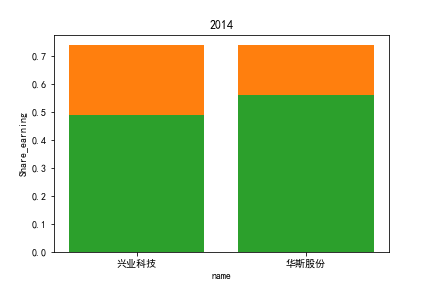
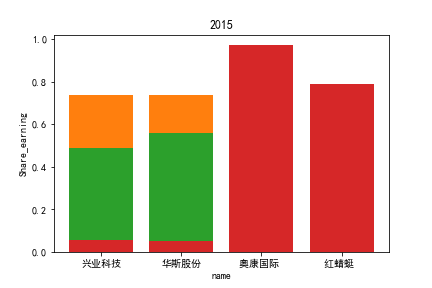
2.每股收益解读
同年度不同公司进行对比可以发现当华利集团上市之后,该股市的每股收益也表现出遥遥领先的优势,可以看出该公司在行业的领先地位。
同样可以将公司表现分为三个水平。分别是华利集团作为第一层次,兴业科技和明新旭腾作为第二层次,剩下的上市公司作为第三层次。这三个层次的公司反映了较大差距的营业水平收入表现。
这或许也与公司的主营业务相关。例如华利集团,其主营业务为生产运动装备;兴业科技和明新旭腾则专注于汽车内饰的制作;剩下的企业则多集中在生产普通服饰和鞋类。这也反映出在服装皮革行业出现的新的经济形势:不能够再像之前增量市场那样通过增加普通服饰和鞋类等产品的数量来提高每股收益;在存量市场上更重要的是垂直投放自己的产品在某一个领域做到最优,提高自己的核心竞争力甚至于达到局部垄断的地位。
同公司不同年度进行分析则发现无论上市早晚,公司均在2020年度产生业绩上的重大减值,由于分析行业为皮草衣物类,为劳动密集型产业,技术壁垒较低,生产品为生活一般消费品。所以该行业受到疫情冲击影响较大。不仅2020年度许多公司每股收益受到重创,即使2021年度每股收益也没有完全恢复,说明疫情带来的对该行业的冲击影响较为长久。