import requests
import re
x=requests.get('http://www.jxufe.edu.cn/')
html = x.text
p=re.compile("<.*?>(.*)<.*?>")
txts = p.findall(html)
st=""
for txt in txts:
st +=str(txt)#将列表转换为字符串
p2=re.compile(r"<[^>]+>",re.S) #字符串作为一个整体,在整体中进行匹配
result = p2.sub("",st)#将st中所有与p2匹配成功的字段替换为空
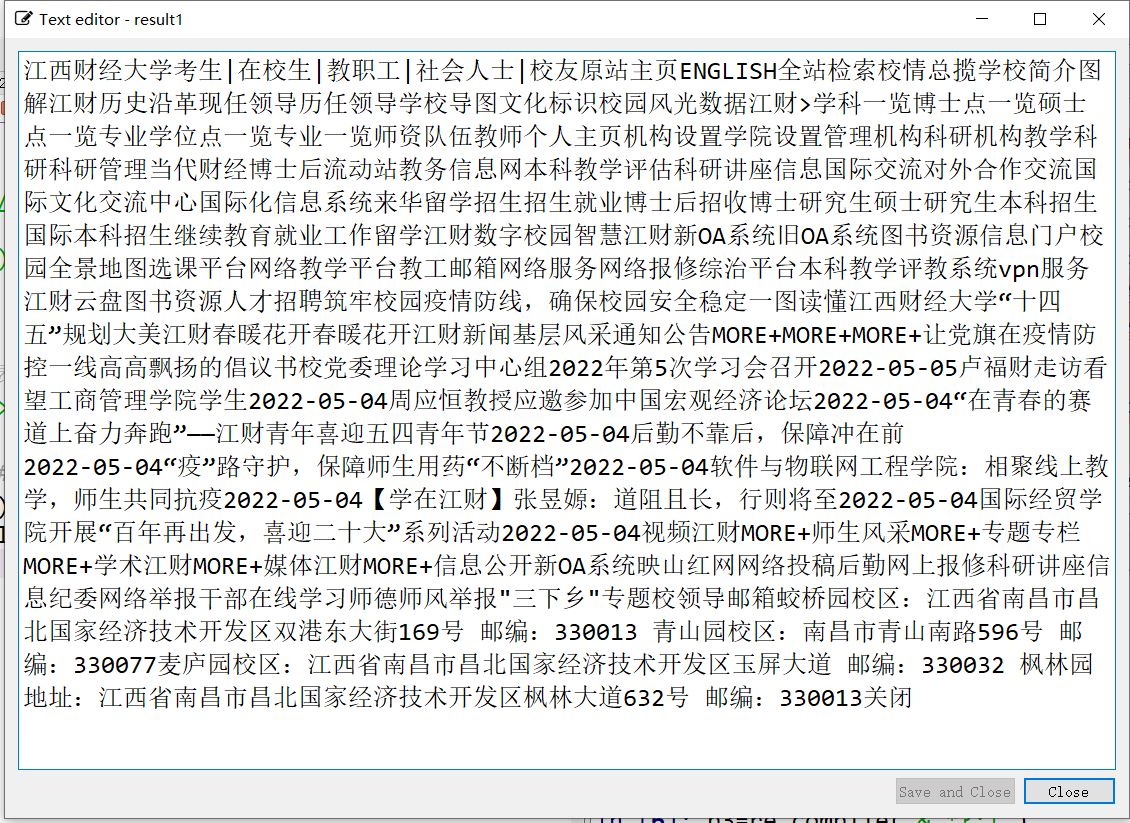
p3=re.compile("&.*?;|")
result1=p3.sub("",result)
先导入requests库和 re库
用requests.get方法抓取学校官网网页,将网页的源代码赋给html变量
定义正则表达式,取两边有<>标签中间的内容,用findall方法整理成了列表,用循环遍历将列表转化为字符串
运用前面的正则表达式匹配完后,可以看到txts里面还残留了<>类标签(是因为这些标签左右都有<>标签,因此留下了中间的<>标签},所以再用正则表达式将其替换为空
注意到匹配结果中还有“ |”标签,再用一次正则表达式,得到结果result1,如截图所示