#谢芷睿,胡江涵,郭漪亭小组作业
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code')
element.send_keys('黑芝麻' + Keys.RETURN)
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
browser.find_element(By.LINK_TEXT,'年度报告').click() # 网页上是点击选择,所以click
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML=element.get_attribute('innerHTML')
f=open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
for r in range(4):
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml')
html_prettified = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
tr = p.findall(html_prettified)
f = open('disclosure-table_prettified.html','w', encoding='utf-8')
prefix = 'https://disc.szse.cn/download'
prefix_href = 'http://www.szse.cn'
p2 = re.compile('(.*?)', re.DOTALL)
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html_prettified)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
p_code = re.compile('(.*?)', re.DOTALL)
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds]
p_pub_time = re.compile('(.*?)', re.DOTALL)
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [lf[0].strip() for lf in link_ftitles],
'href': [lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
df.to_csv('sample_data_from_szse.csv')
os.mkdir('%s年度报告'%name)
os.chdir(r'C:\Users\86187\Desktop\食品制造业10年内年度报告\%s年度报告'%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df['简称'][0]
rename = name1 + ye
for a in range(len(df)):
if df['name'][a] == '%s年年报'%rename:
href0 = df.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
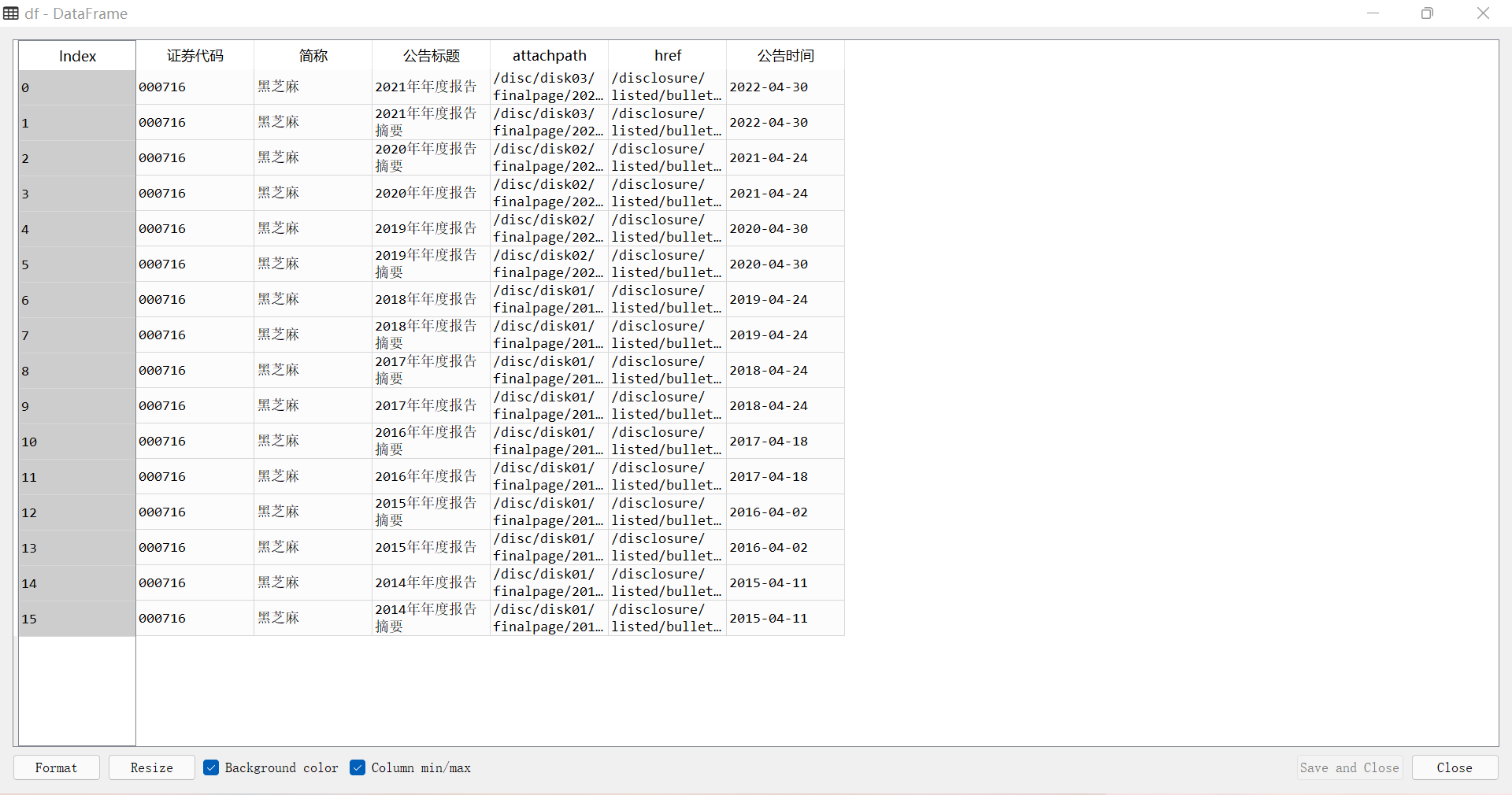
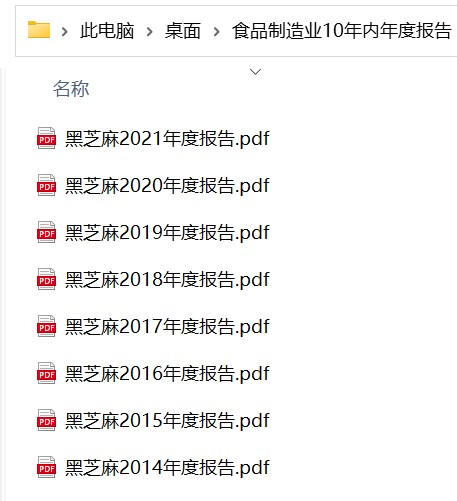


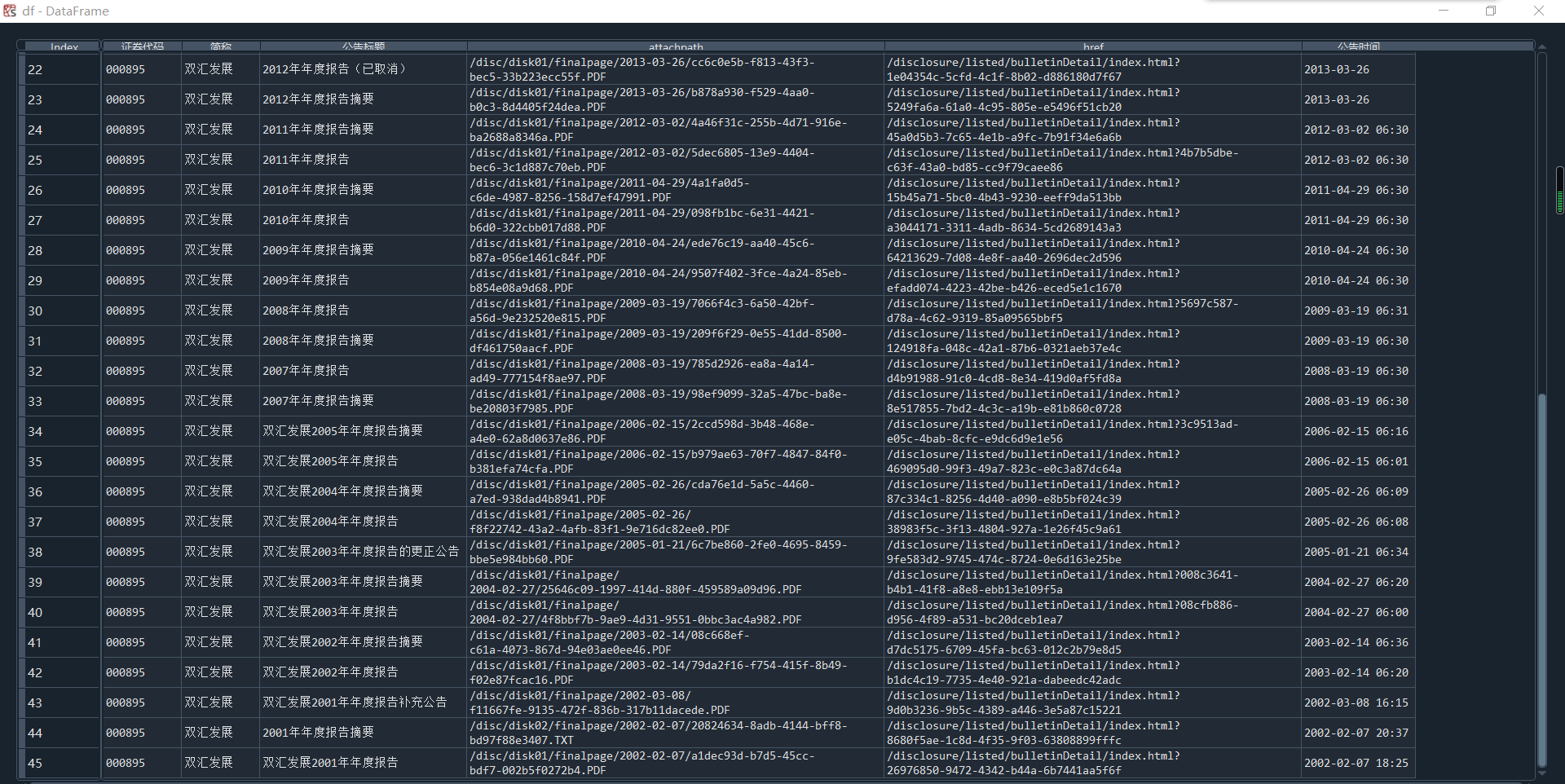
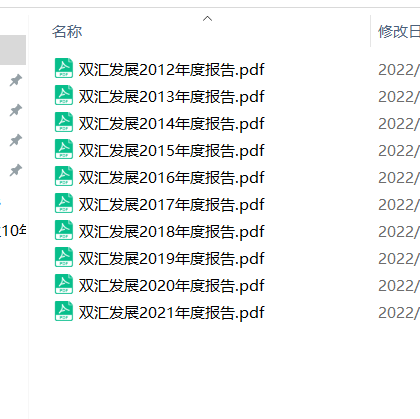
首先导入所需的模块,再读取写入网页内容成为html文件,对于读取内容进行分页的判断,接下来使用bs解码,按照操作分别写入tr,trs中,然后再分别读取企业代码,企业名称以及时间,最终写入dataframe中,加入本地文件,打印pdf