基础准备部分
import re
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import requests
from bs4 import BeautifulSoup
import time
import fitz
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib qt5
print(fitz.__doc__)
os.chdir(r'C:\Users\Admin\Desktop\期末作业')
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
doc = fitz.open('行业分类.pdf')
doc.page_count #将作业素材文件中的对应模块导入
page3 = doc.load_page(3)
text3 = page3.get_text()
page4 = doc.load_page(4)
text4 = page4.get_text() #在文件中选取对应的公司,由于公司需要跨页,所以分开提取
p1 = re.compile(r'农副食品加工业(.*?)600275', re.DOTALL)
toc = p1.findall(text3)
toc1 = toc[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc2 = p2.findall(toc1)
p3 = re.compile(r'农副食品加工业(.*?)味知香', re.DOTALL)
toc3 = p3.findall(text4)
toc4 = toc3[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc5 = p2.findall(toc4) #在提取过程中选择上限和下限
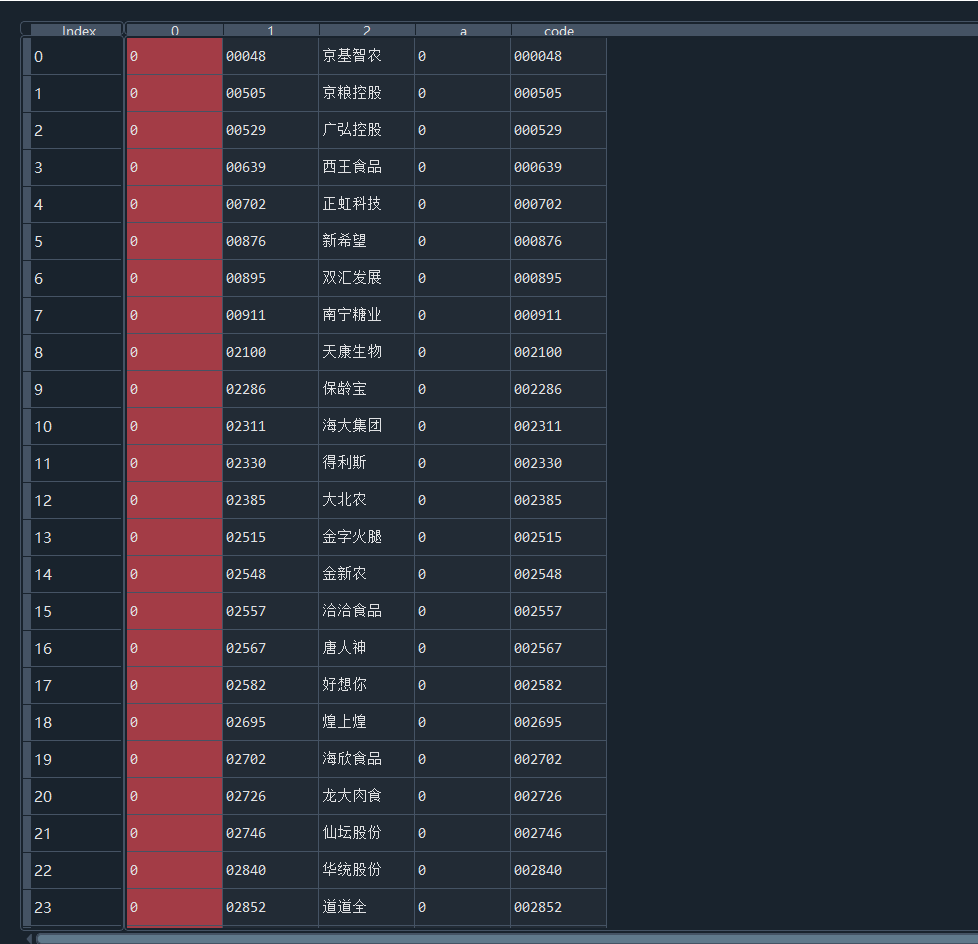
hb = toc2 + toc5
hb1 = pd.DataFrame(hb)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021']}
dy = pd.DataFrame(year)
hb1[0] = hb1[0].astype(int)
hb1['a'] = hb1[0].astype(str)
hb1['code'] = hb1['a'] + hb1[1]
sse = hb1.loc[(hb1[0]==6)]
szse = hb1.loc[(hb1[0]==0)]
sse['code'] = '6' + sse[1]
sse['code'] = sse['code'].astype(int)
sse = sse.reset_index(drop=True)
driver_url = r"C:\Users\Admin\Downloads\edgedriver_win64\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory':r'C:\Users\Admin\Desktop\农副产品加工业10年内年度报告'}
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
driver = webdriver.Edge(executable_path=driver_url, options=options) #对应环境变量
深交所部分
driver = webdriver.Edge()
driver.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
element = driver.find_element(By.ID, 'input_code')
element.send_keys('洽洽食品' + Keys.RETURN)
for i in range(len(szse)):
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告")
name = szse[2][i]
button = driver.find_element(By.CLASS_NAME, 'btn-clearall')
button.click()
element = driver.find_element(By.ID, 'input_code')
element.send_keys('%s'%name + Keys.RETURN)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element = driver.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML_%s.html'%name,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML_%s.html'%name,encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df['简称'] = name
df['公告时间'] = pd.to_datetime(df['公告时间'])
df['year'] = df['公告时间'].dt.year
df['year'] = df['year'] - 1
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df)):
a = p_zy.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df)):
b1 = p_nb.findall(df['公告标题'][i])
b2 = p_nb2.findall(df['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
df = df.drop_duplicates('year', keep='first', inplace=False)
df = df.reset_index(drop=True)
df['year_str'] = df['year'].astype(str)
df['name'] = name + df['year_str'] + '年年报'
name1 = df['简称'][0]
df.to_csv('%scsv文件.csv'%name1)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df['简称'][0]
rename = name1 + ye
for a in range(len(df)):
if df['name'][a] == '%s年年报'%rename:
href0 = df.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close() #将深交所的相关年报爬下来
上交所部分
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
p_a = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
p_span = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_data(df_txt):
prefix_href = 'http://www.sse.com.cn/'
df = df_txt
ahts = [get_link(td) for td in df['公告标题']]
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['名称']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
})
return(df)
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
dropdown = driver.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
time.sleep(1)
for i in range(len(sse)):
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告")
code = sse['code'][i]
driver.find_element(By.ID, "inputCode").clear()
driver.find_element(By.ID, "inputCode").send_keys("%s"%code)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "全部").click()
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
soup = BeautifulSoup(innerHTML)
html = soup.prettify()
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
n = len(trs)
for i in range(len(trs)):
if n >= i:
if len(trs[i]) == 5:
del trs[i]
n = len(trs)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'名称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
df_data = get_data(df)
df_data = pd.concat([df_data, df['公告时间']], axis=1)
df_data['公告时间'] = pd.to_datetime(df_data['公告时间'])
df_data['year'] = df_data['公告时间'].dt.year
df_data['year'] = df_data['year'] - 1
name = df_data['简称'][0]
df_data['简称'] = name
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df_data)):
a = p_zy.findall(df_data['公告标题'][i])
if len(a) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df_data)):
b1 = p_nb.findall(df_data['公告标题'][i])
b2 = p_nb2.findall(df_data['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_bnb = re.compile('.*?(半年).*?')
for i in range(len(df_data)):
c = p_bnb.findall(df_data['公告标题'][i])
if len(c) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.drop_duplicates('year', keep='first', inplace=False)
df_data = df_data.reset_index(drop=True)
df_data['year_str'] = df_data['year'].astype(str)
df_data['name'] = name + df_data['year_str'] + '年年报'
name1 = df_data['简称'][0]
df_data.to_csv('%scsv文件.csv'%name1)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']}
dy = pd.DataFrame(year)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df_data['简称'][0]
rename = name1 + ye
for a in range(len(df_data)):
if df_data['name'][a] == '%s年年报'%rename:
href0 = df_data.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close() #利用自动化将上交所对应文件中的年报爬下来
hbcwsj = pd.DataFrame(index=range(2012,2021),columns=['营业收入','基本每股收益'])
hbsj = pd.DataFrame()
解析年报部分,以得利斯公司为例
#由于涉及公司较多,以下截图结果以一家公司为例
for i in range(len(hb1)):
name2 = hb1[2][i]
code = hb1['code']
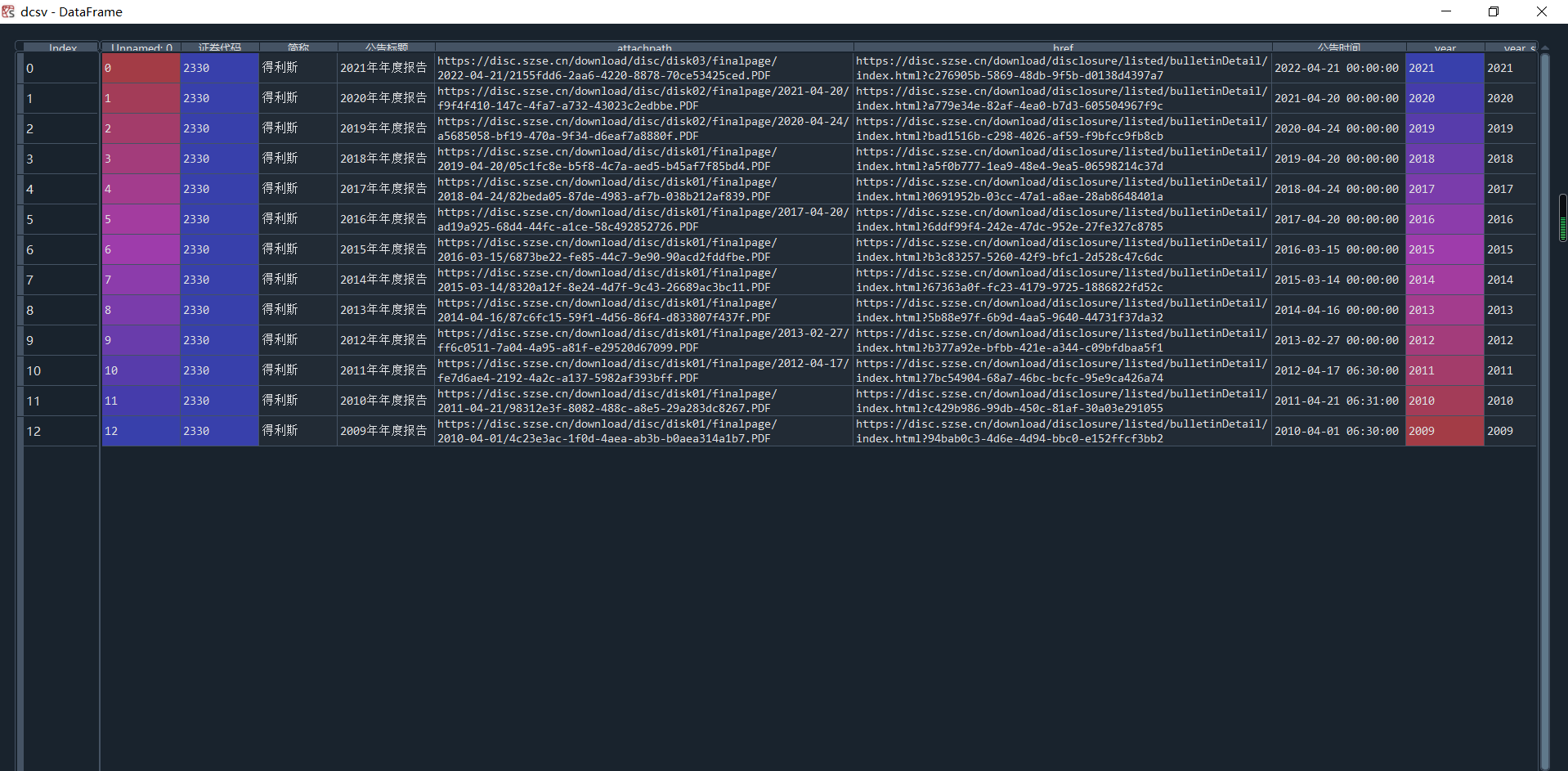
dcsv = pd.read_csv(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\%scsv文件.csv"%name2)
dcsv['year_str'] = dcsv['year'].astype(str)
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\%s年度报告"%name2)
#r = 0
for r in range(len(dcsv)):
year_int = dcsv.year[r]
if year_int >= 2012:
year2 = dcsv.year_str[r]
aba = name2 + year2
doc = fitz.open(r'%s年度报告.PDF'%aba)
text=''
for j in range(22):
page = doc[j]
text += page.get_text()
p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)')
revenue = float(p_rev.search(text).group(1).replace(',',''))
p_eps = re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)')
eps = float(p_eps.search(text).group(1))
p_web = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)')
web = p_web.search(text).group(1)
p_site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)')
site = p_site.search(text).group(1)
hbcwsj.loc[year_int,'营业收入'] = revenue
hbcwsj.loc[year_int,'基本每股收益'] = eps
hbcwsj = hbcwsj.astype(float)
hbcwsj.to_csv(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\%s财务数据.csv"%name2)
hbsj = hbsj.append(hbcwsj.tail(1))
绘制营业收入情况图和每股收益走势图
hbsj.index = Series(szse[2])
hbsj.sort_values(by='营业收入',axis=0,ascending=True)
hbsj2 = hbsj.head(10)
hbsj2['name'] = hbsj2.index
hbsj2 = hbsj2.reset_index(drop=True)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.grid(True)
plt.title('得利斯的营业收入情况图')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\得利斯财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['rev']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
os.chdir(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告")
plt.savefig('得利斯的营业收入情况图')
plt.clf()
plt.xlabel('年份')
plt.ylabel('每股收益')
plt.grid(True)
plt.title('得利斯公司的每股收益走势图')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\Admin\Desktop\农副食品加工业10年内年度报告\得利斯财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['eps']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
plt.savefig('得利斯公司的每股收益走势图')
plt.clf()



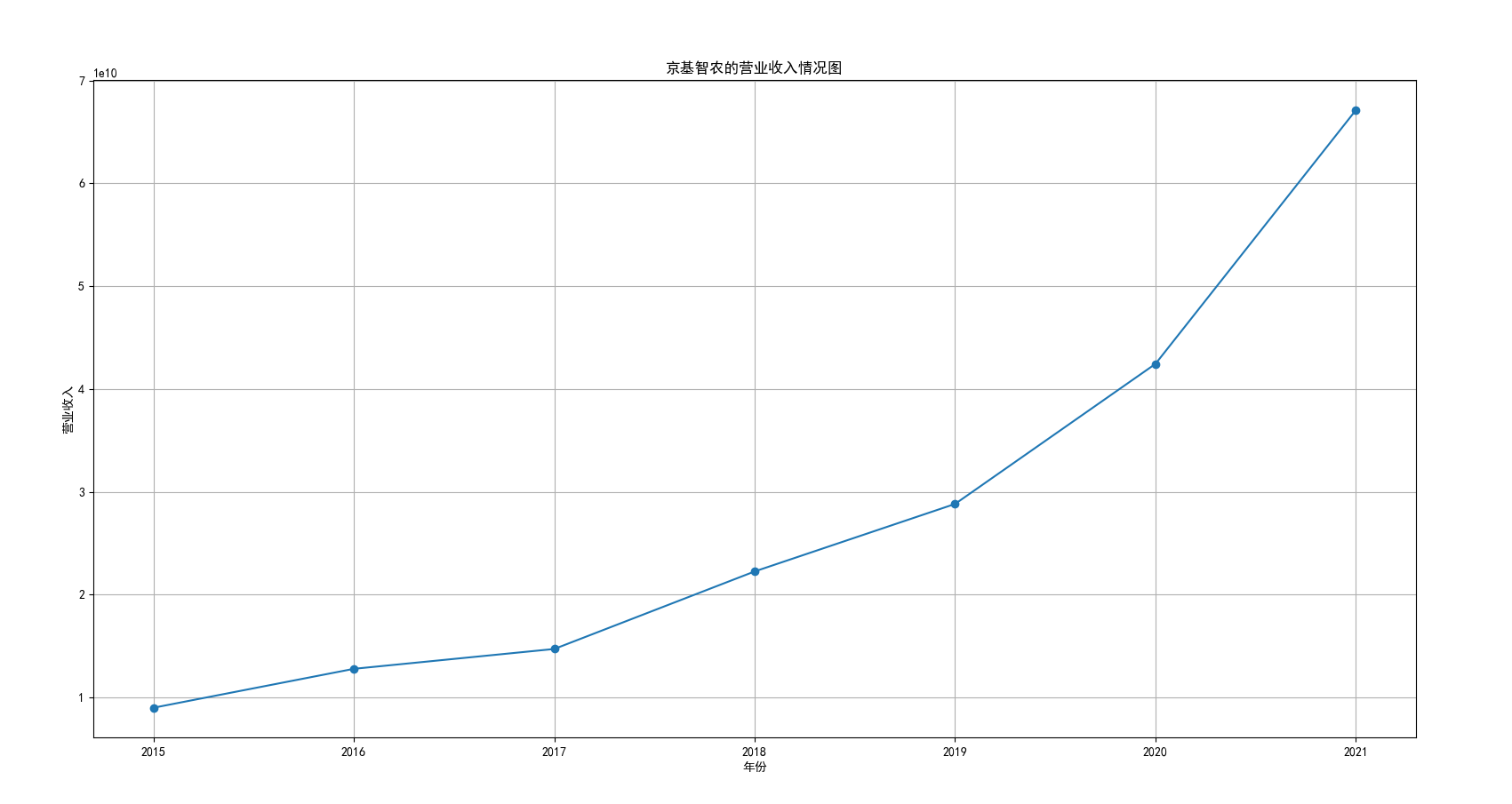

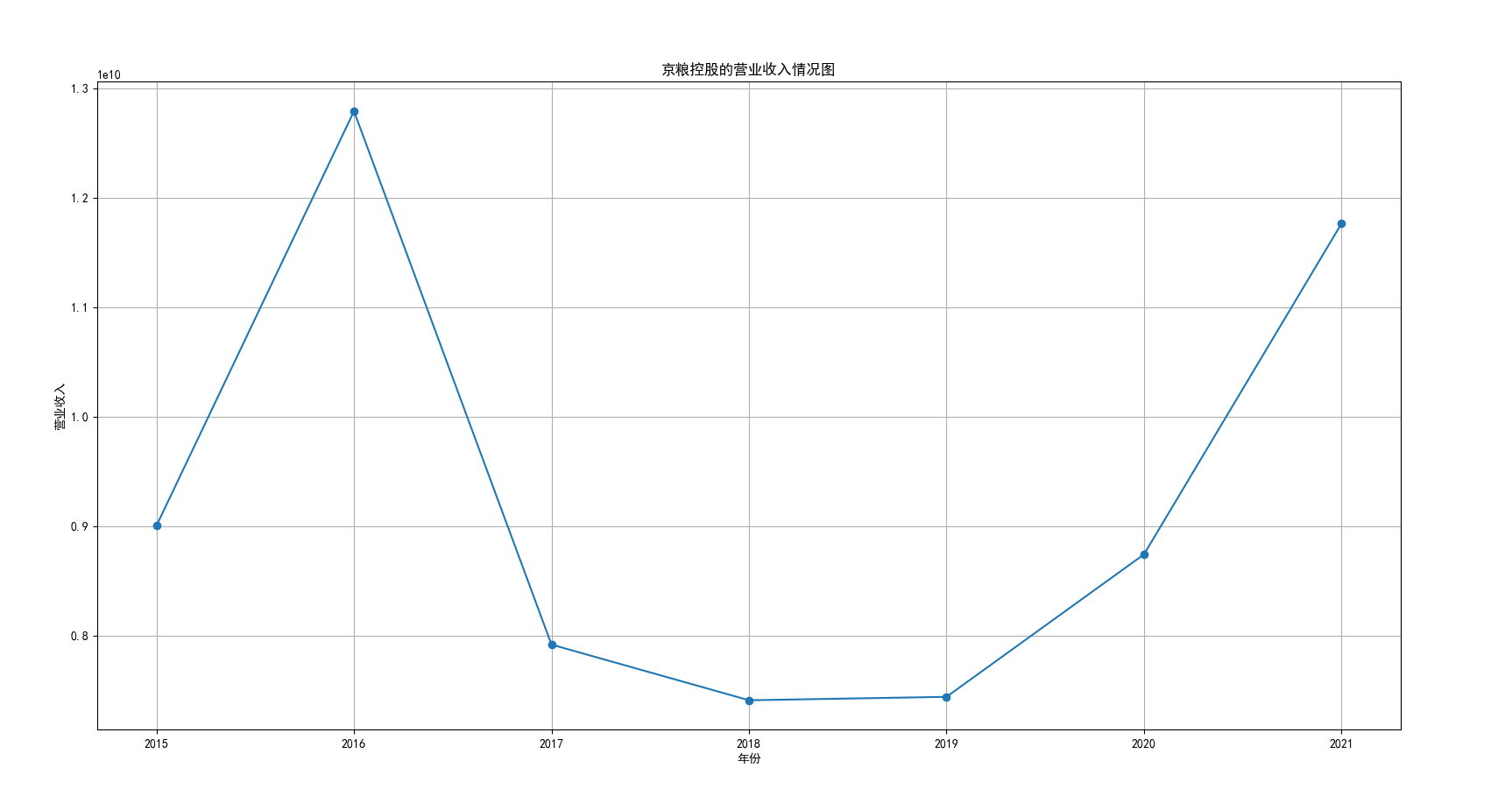
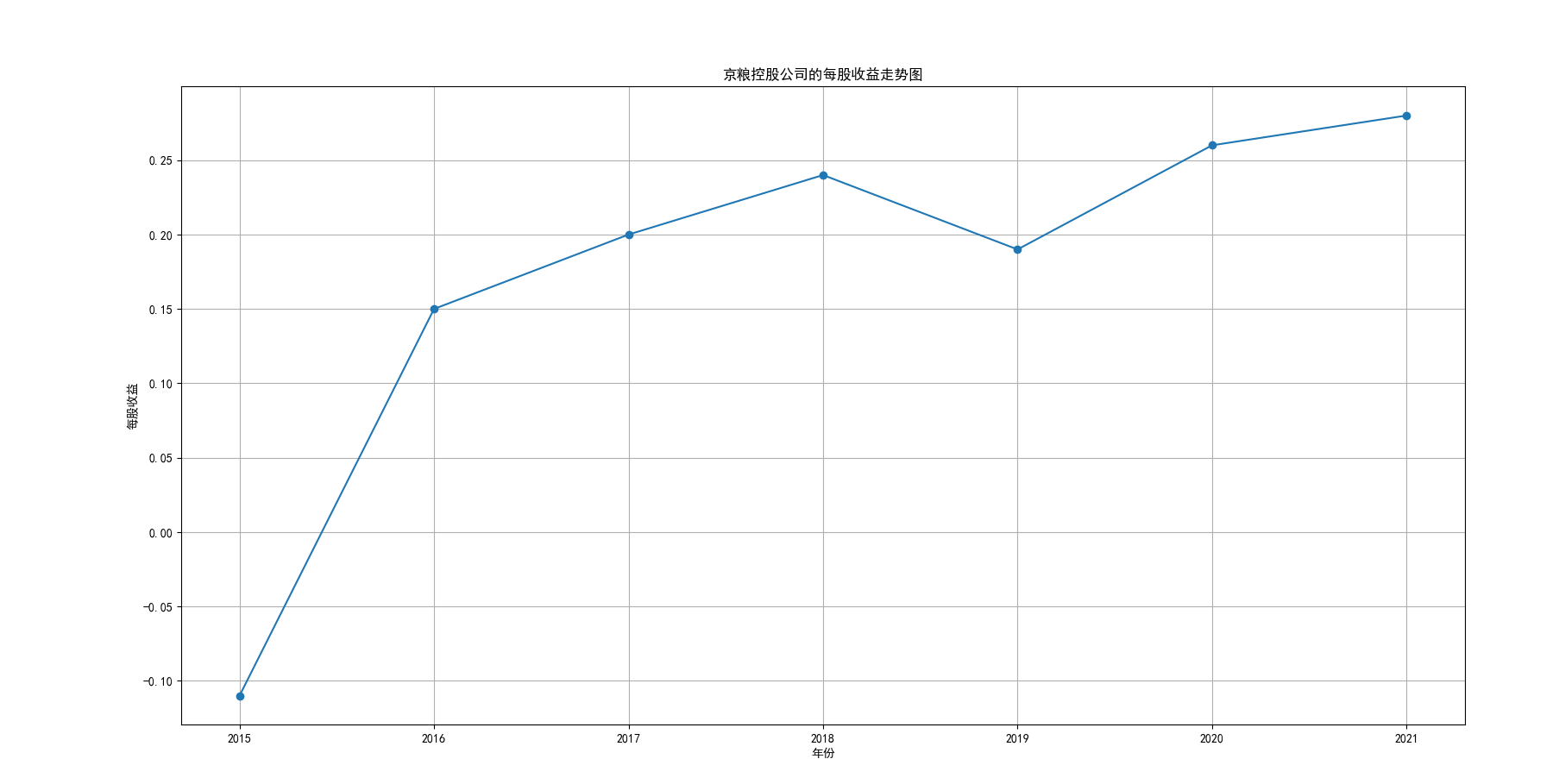
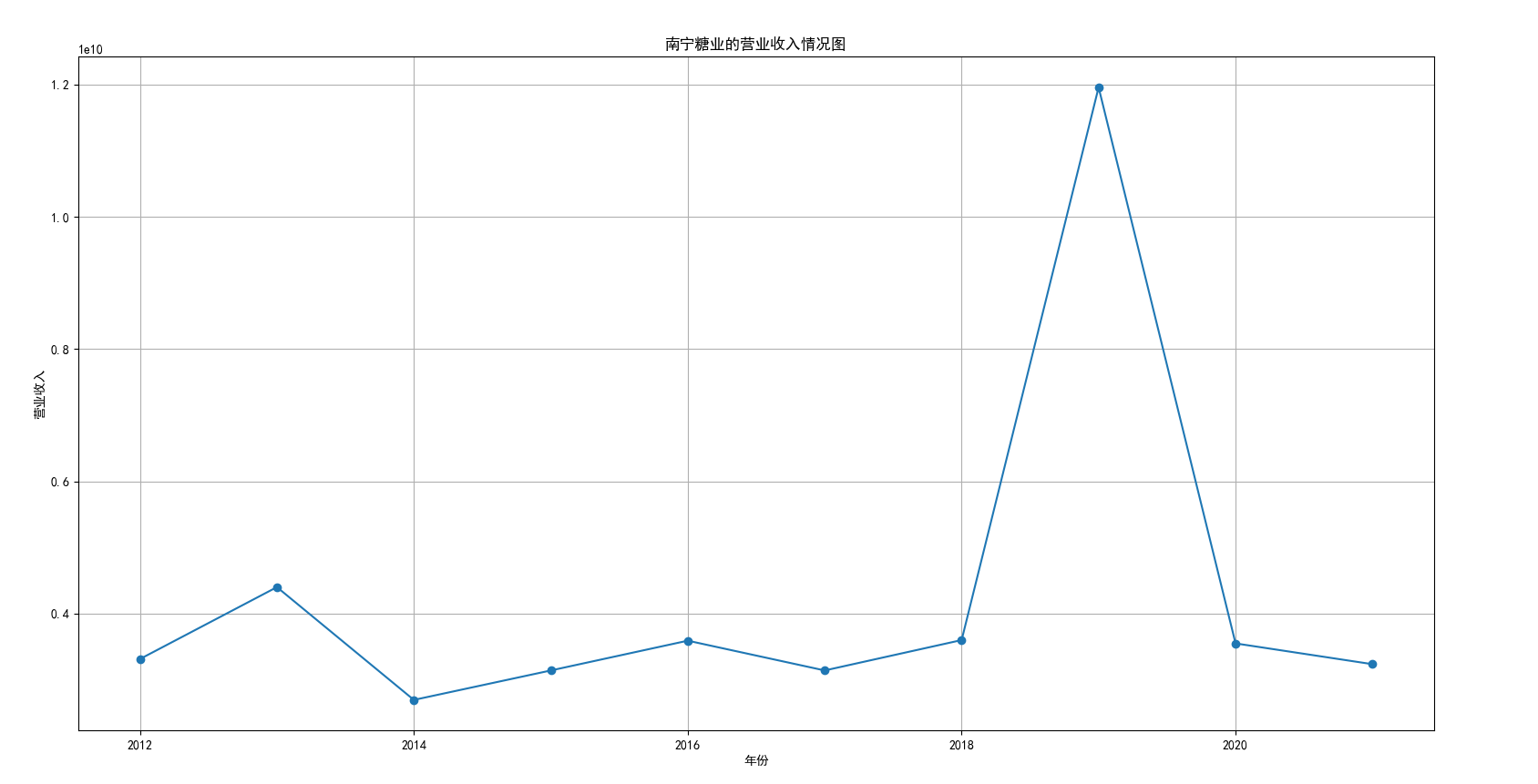
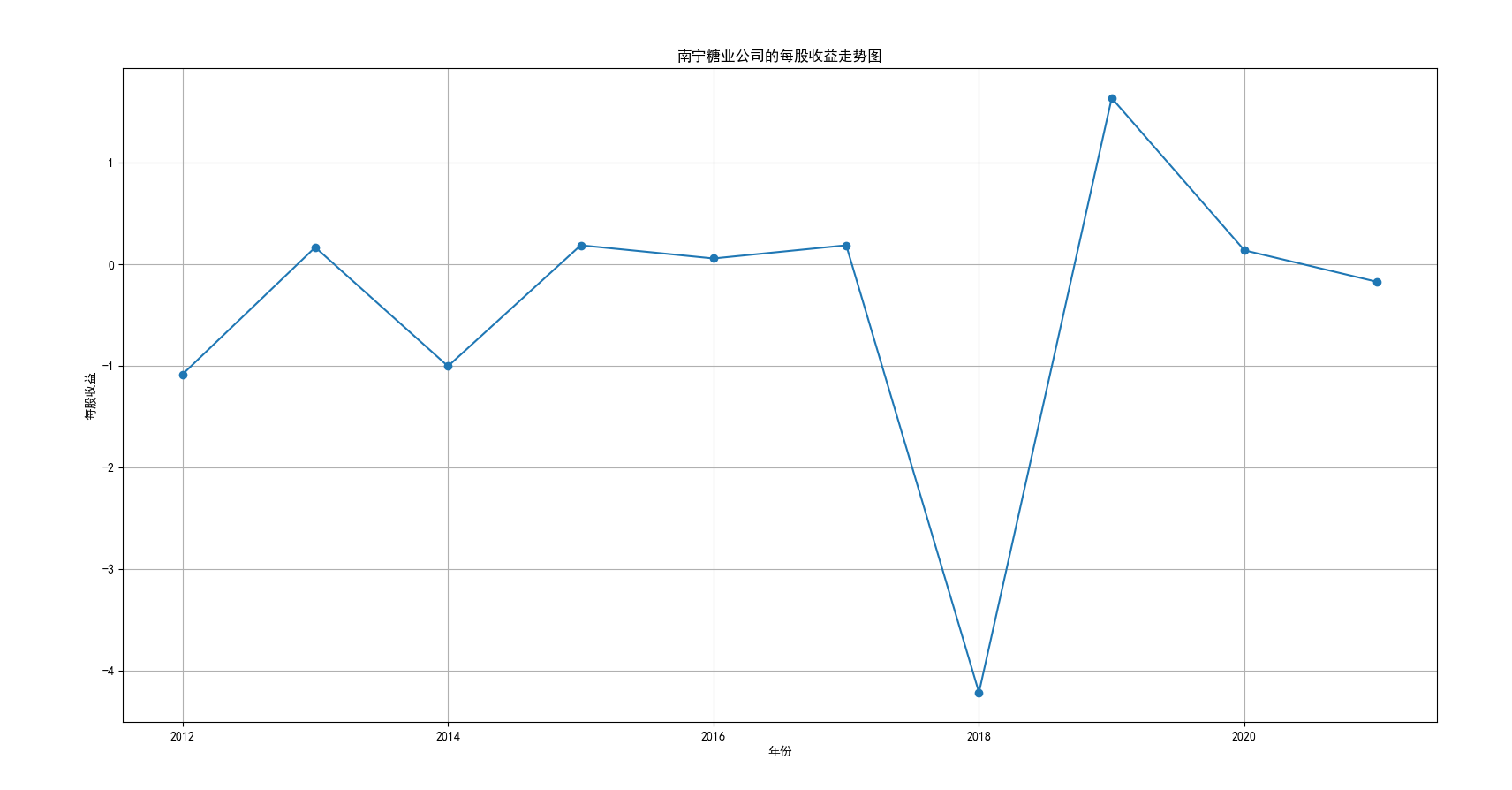
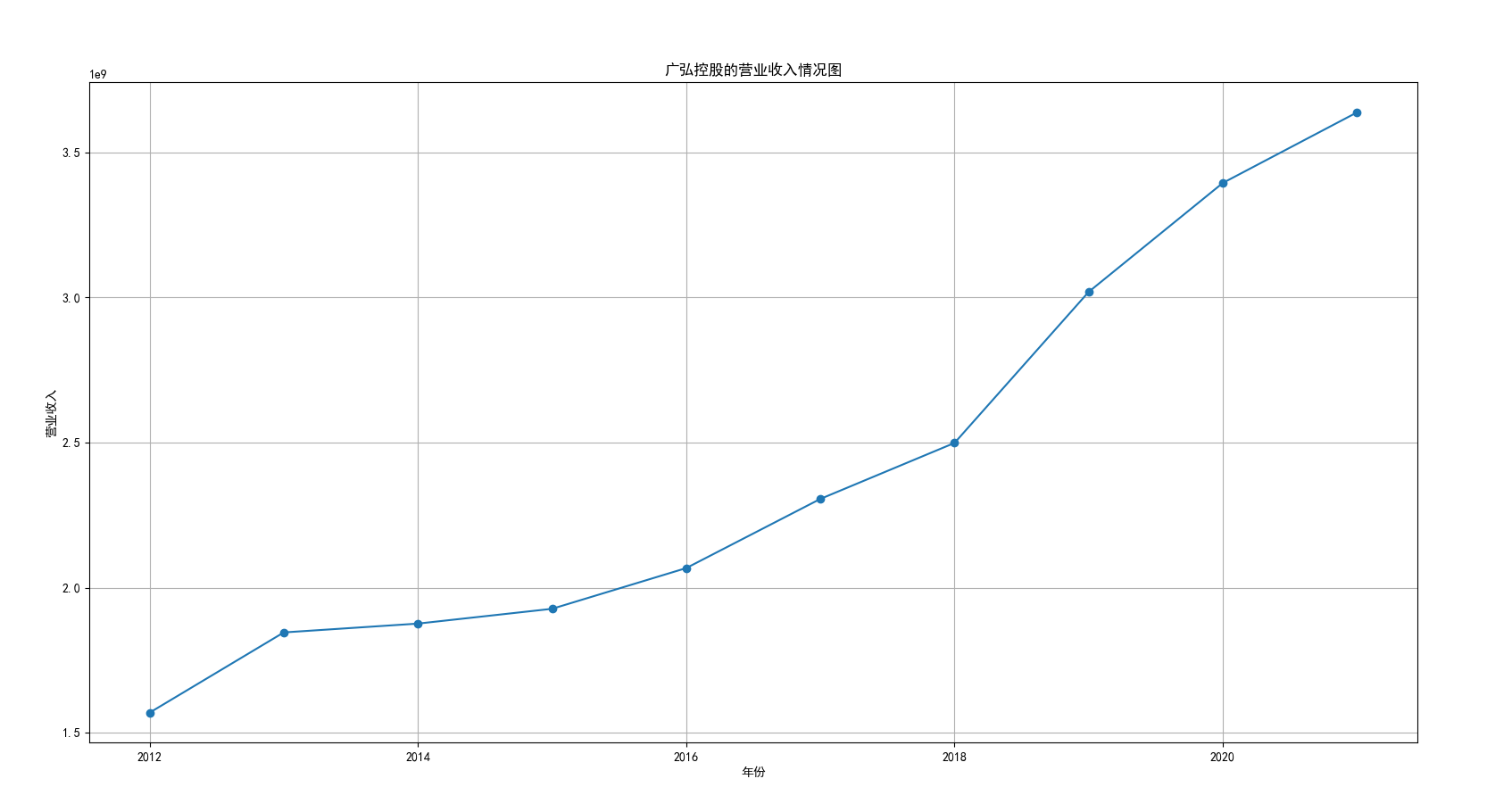

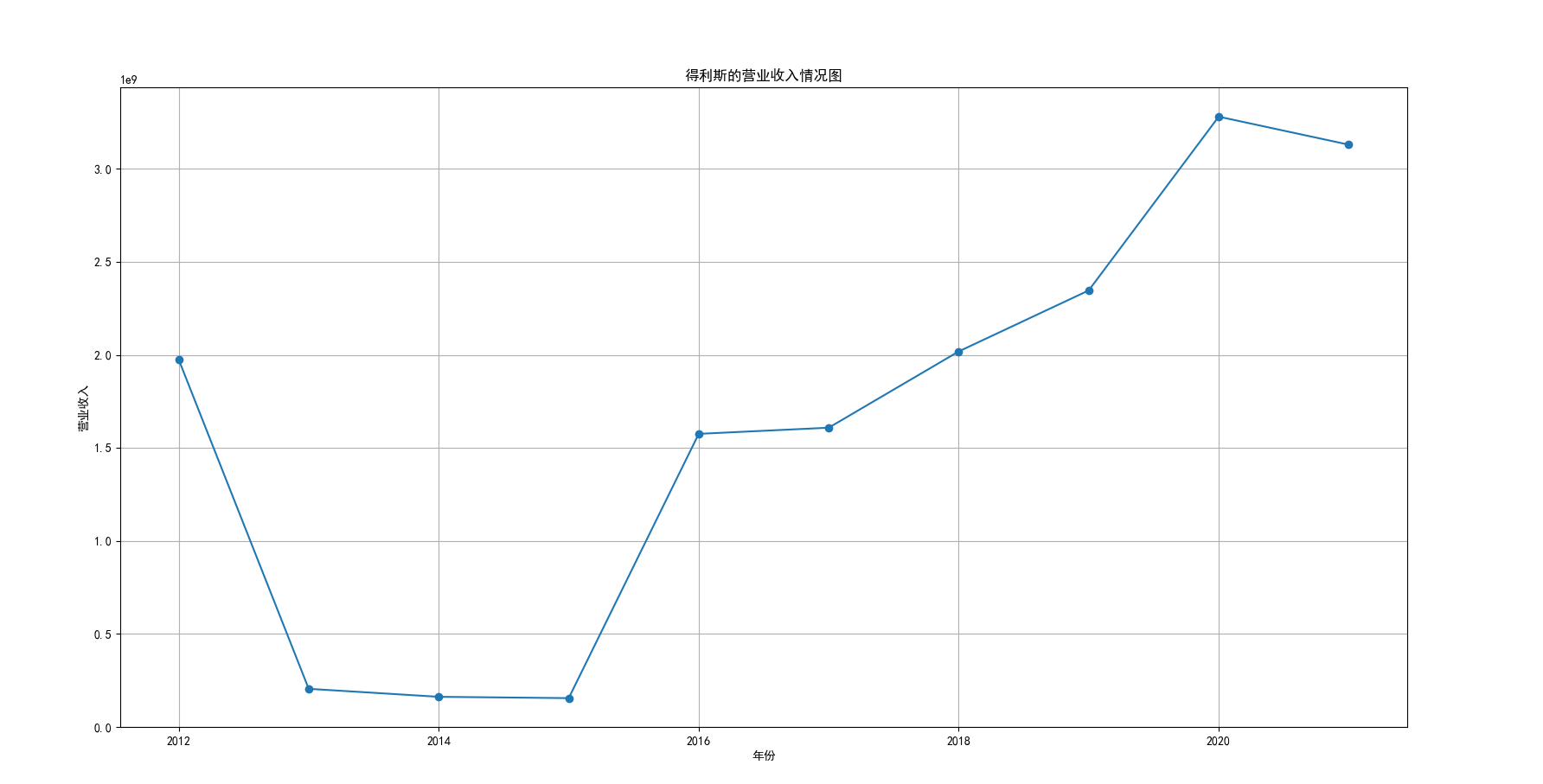
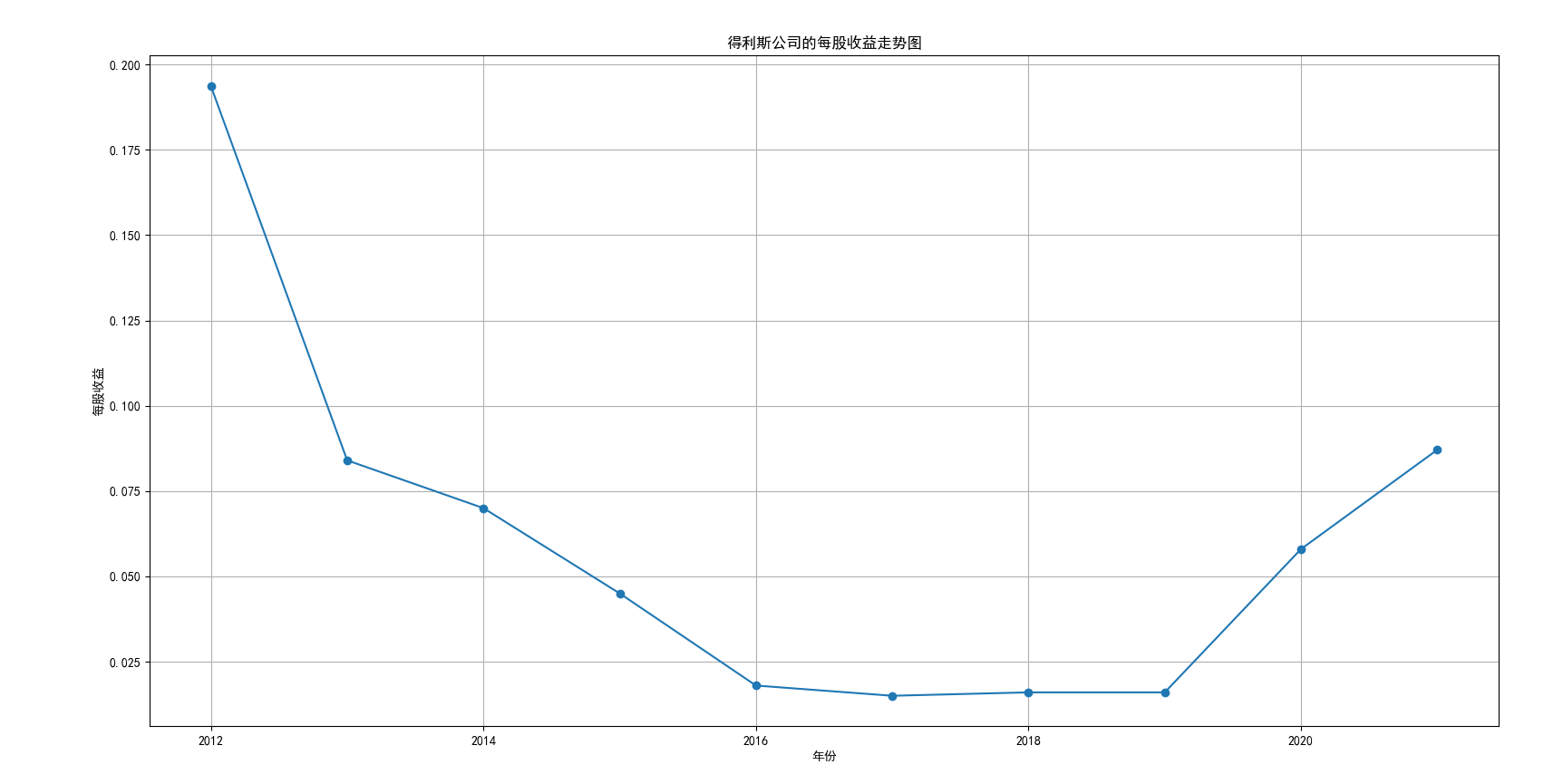
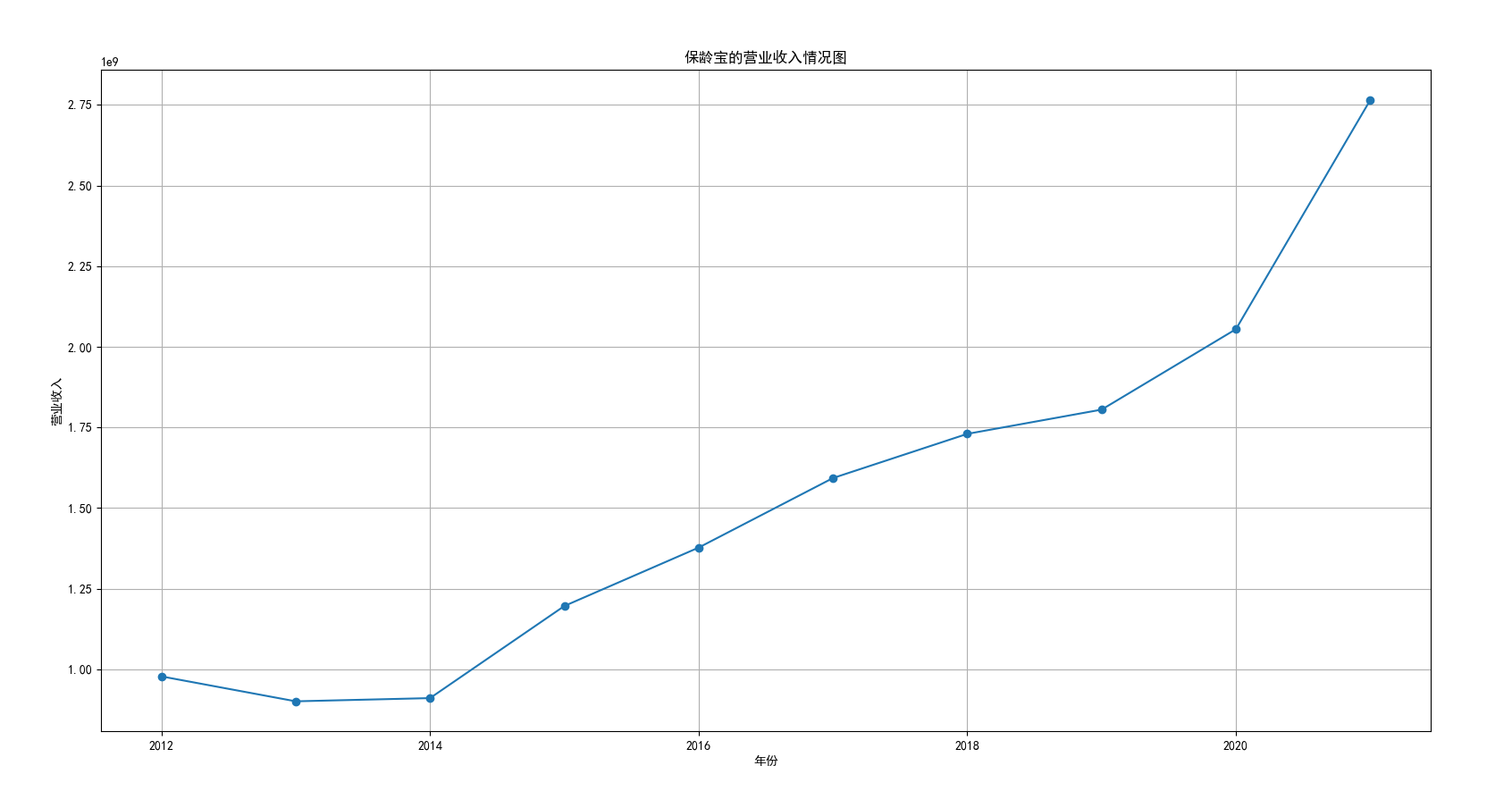
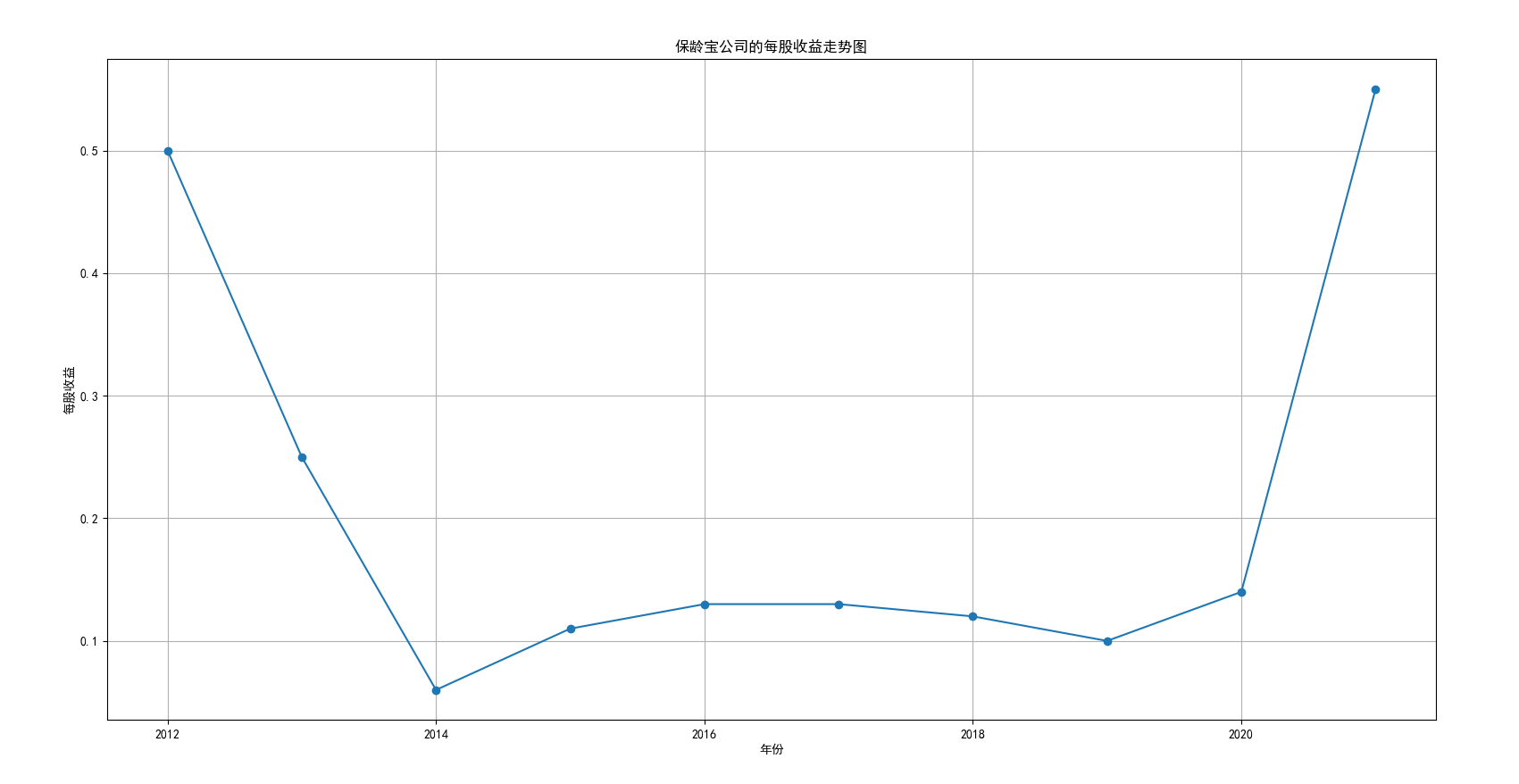
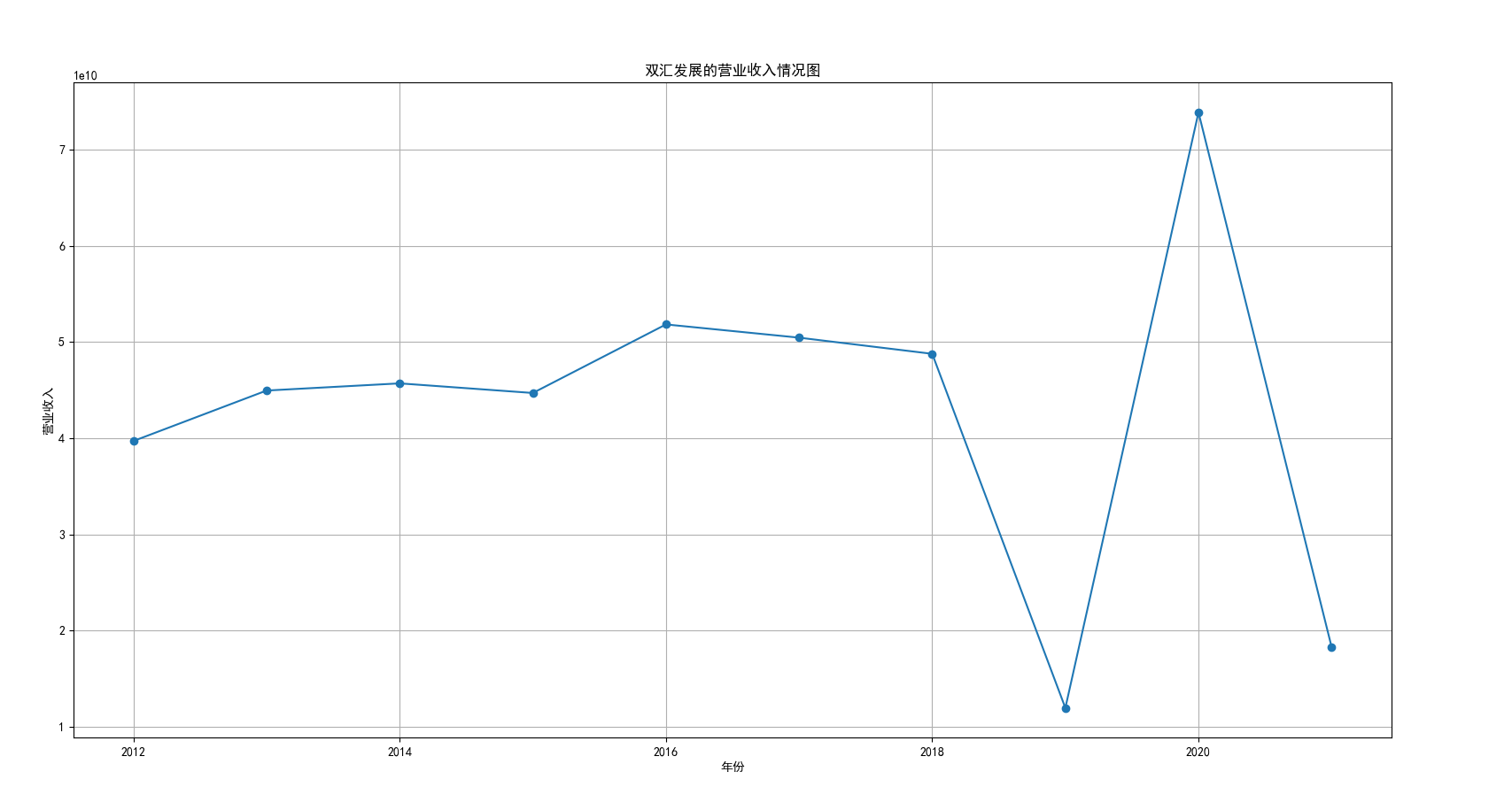
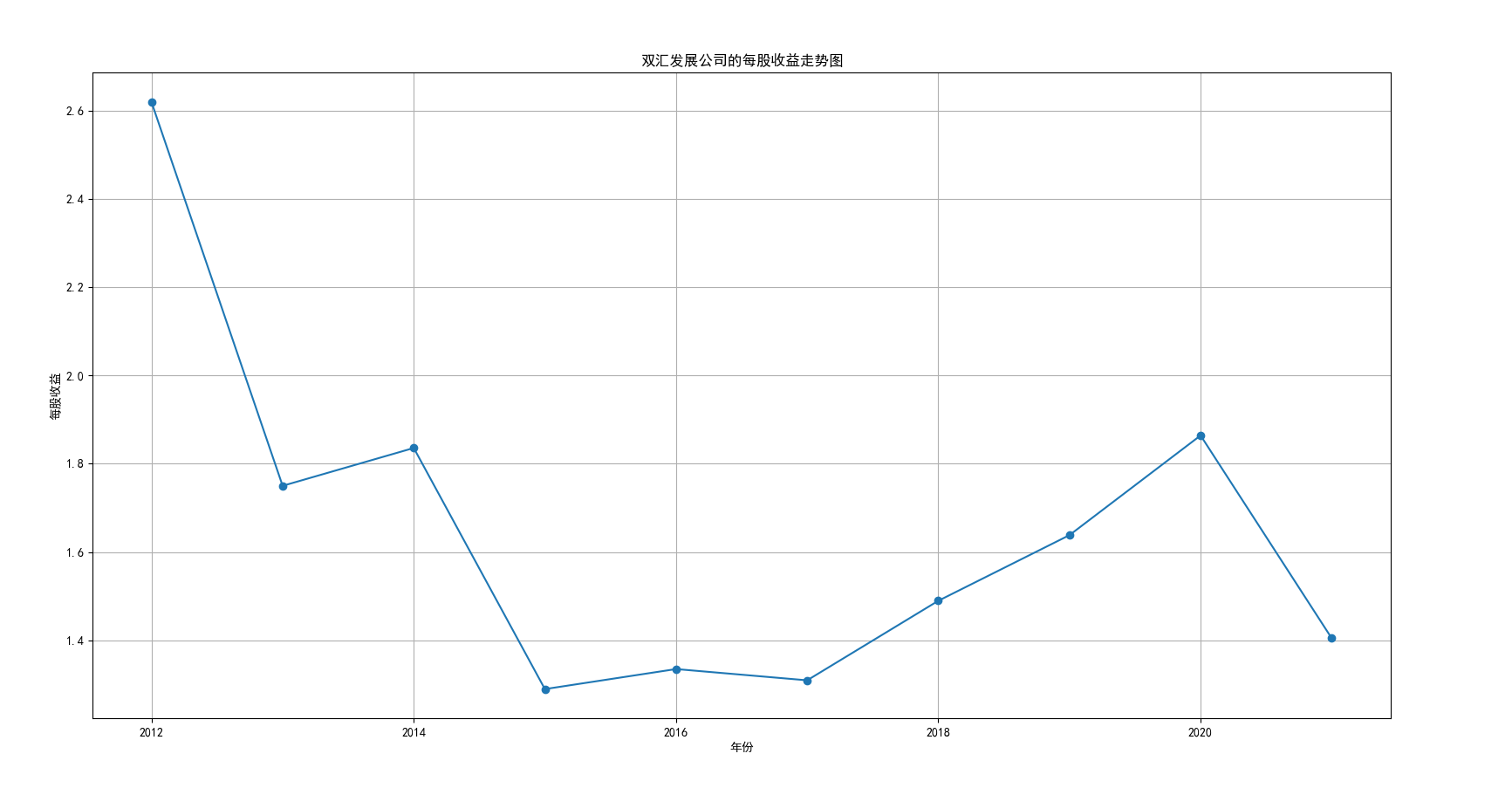
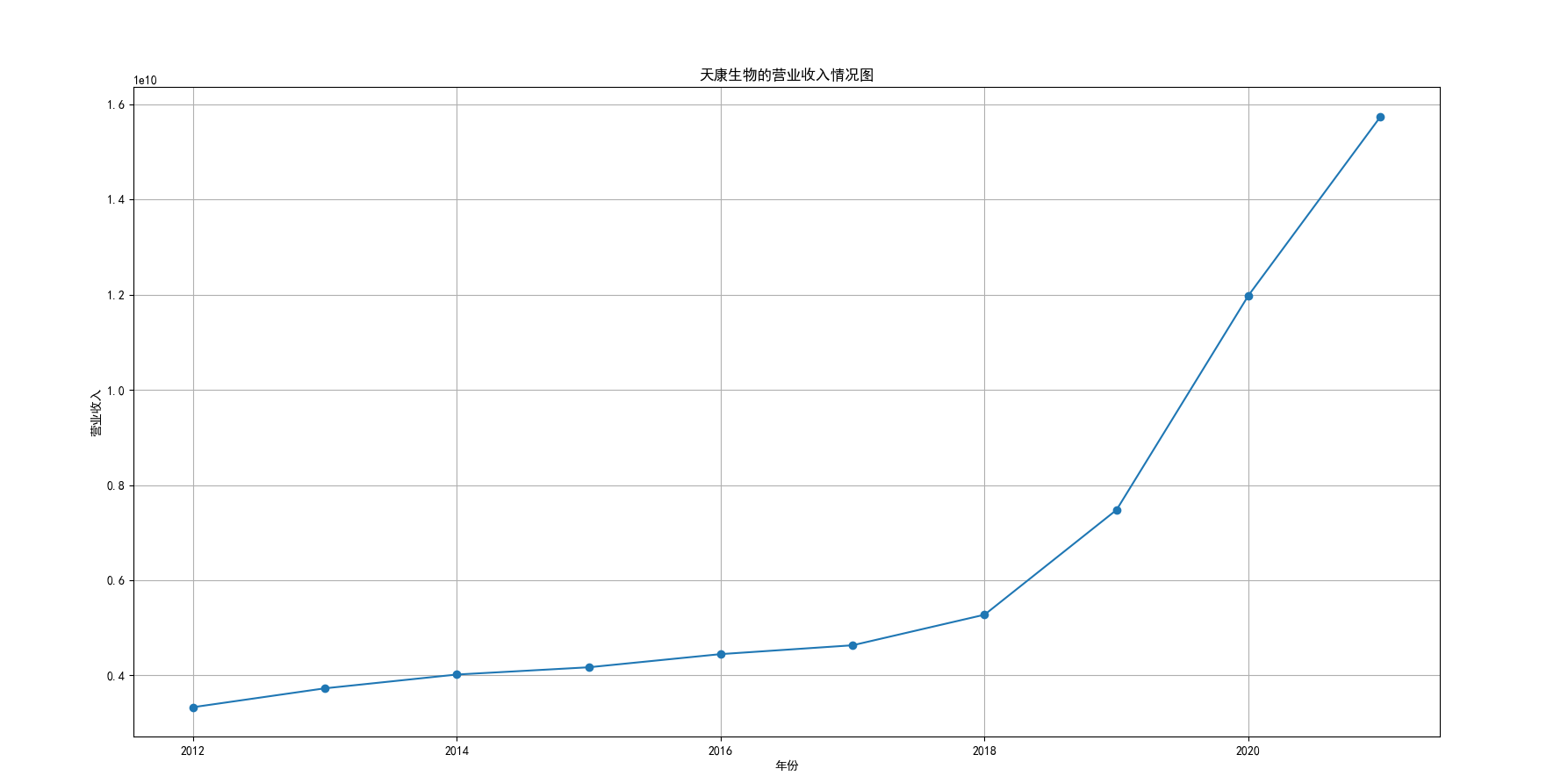
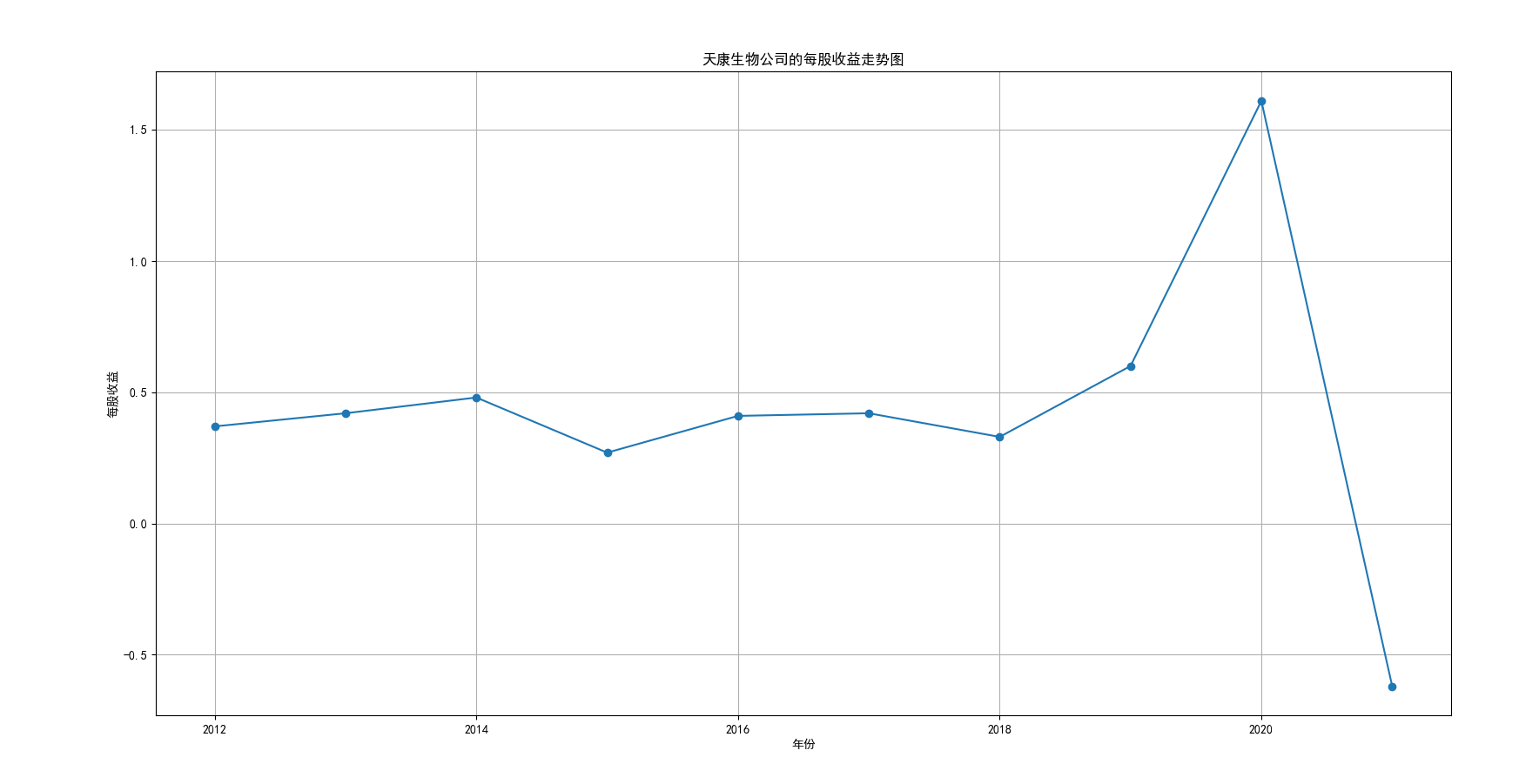
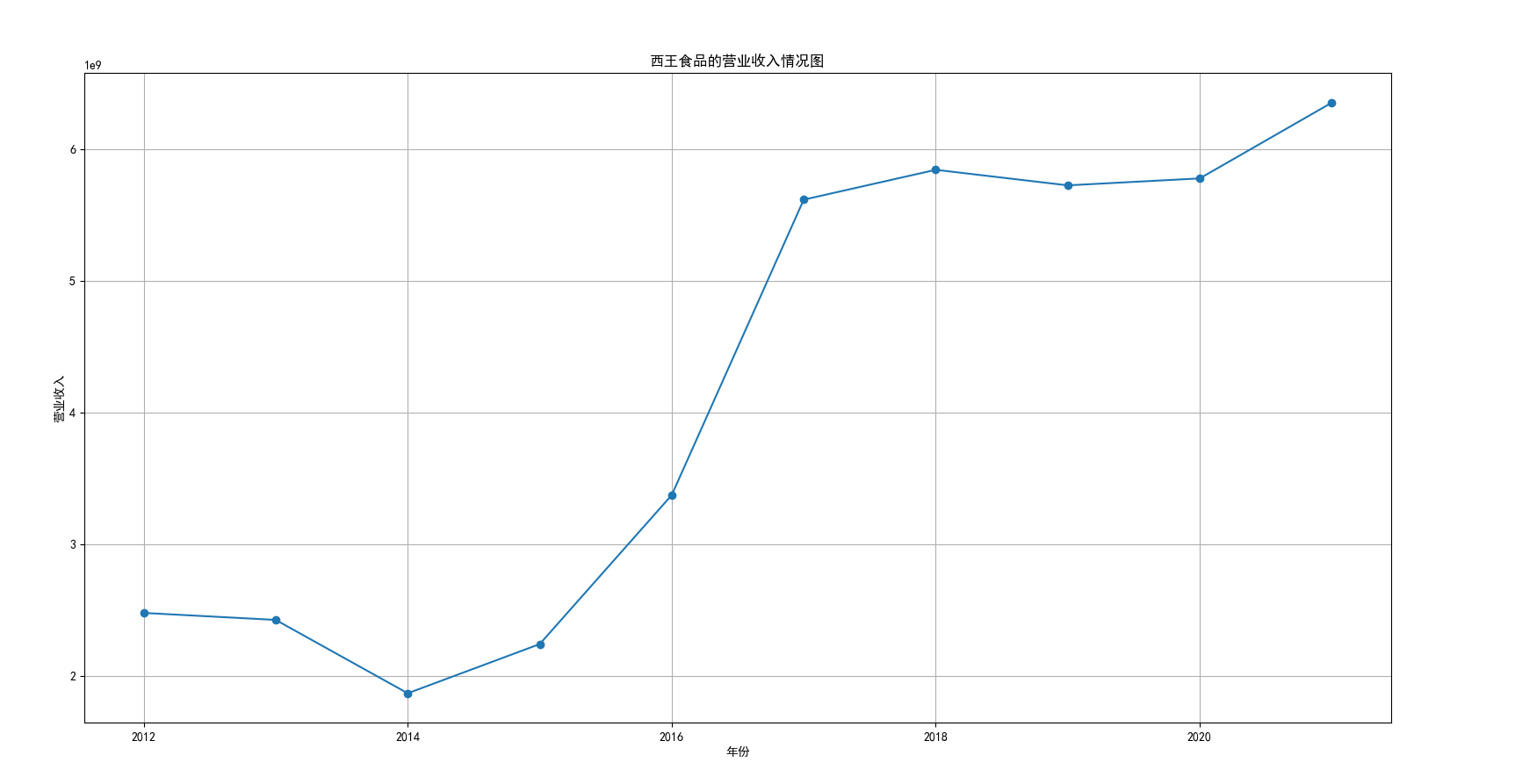
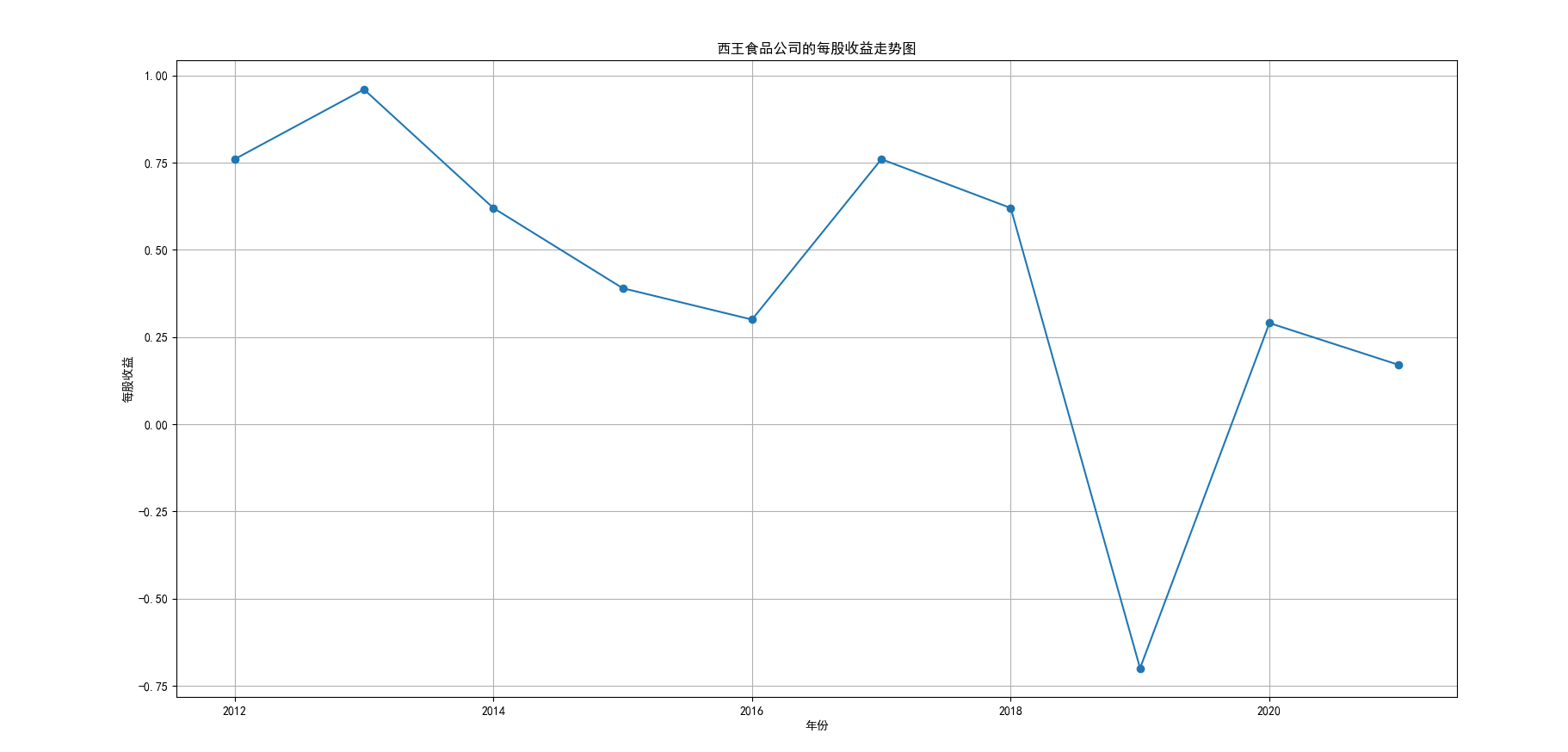
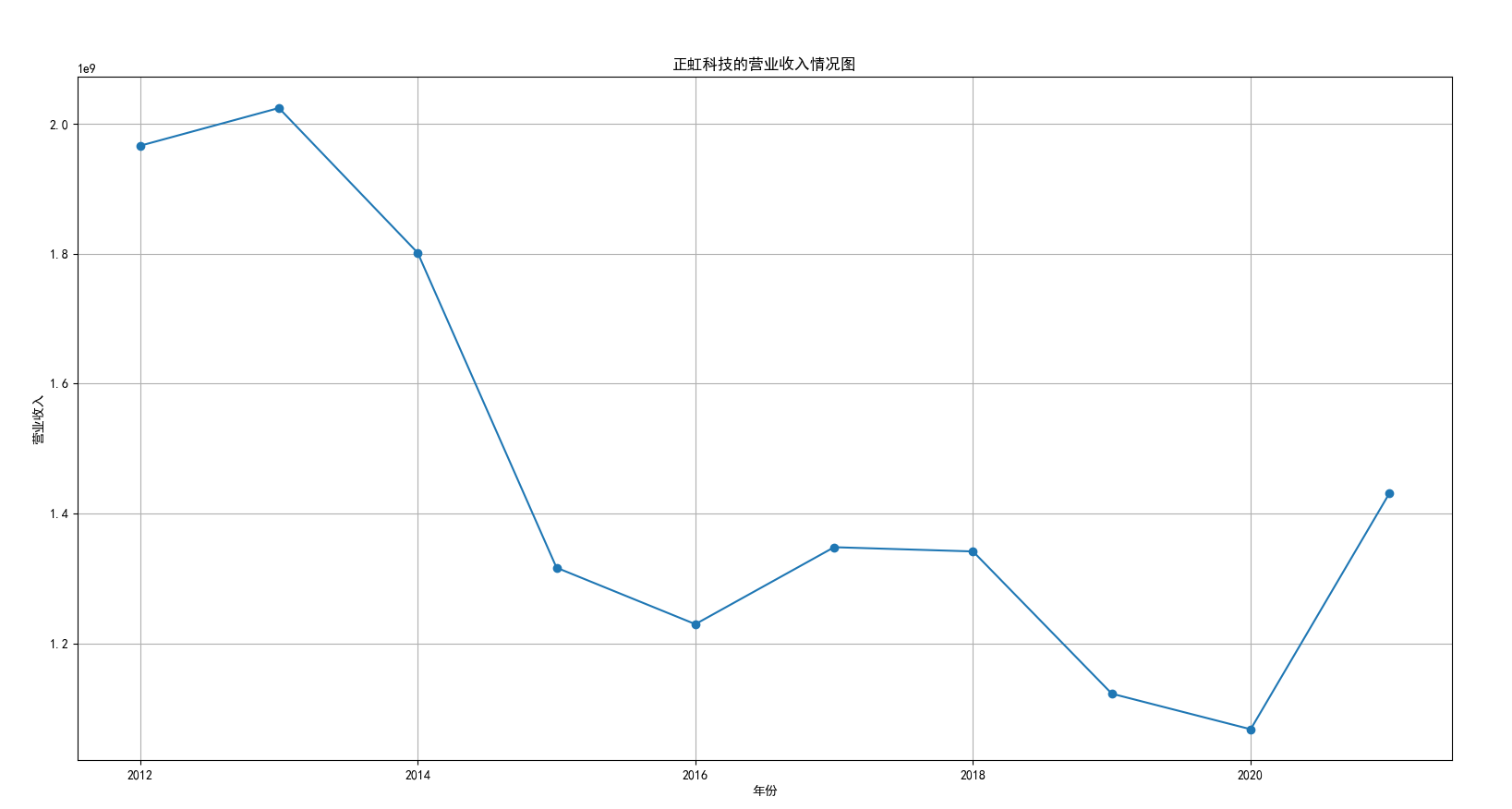
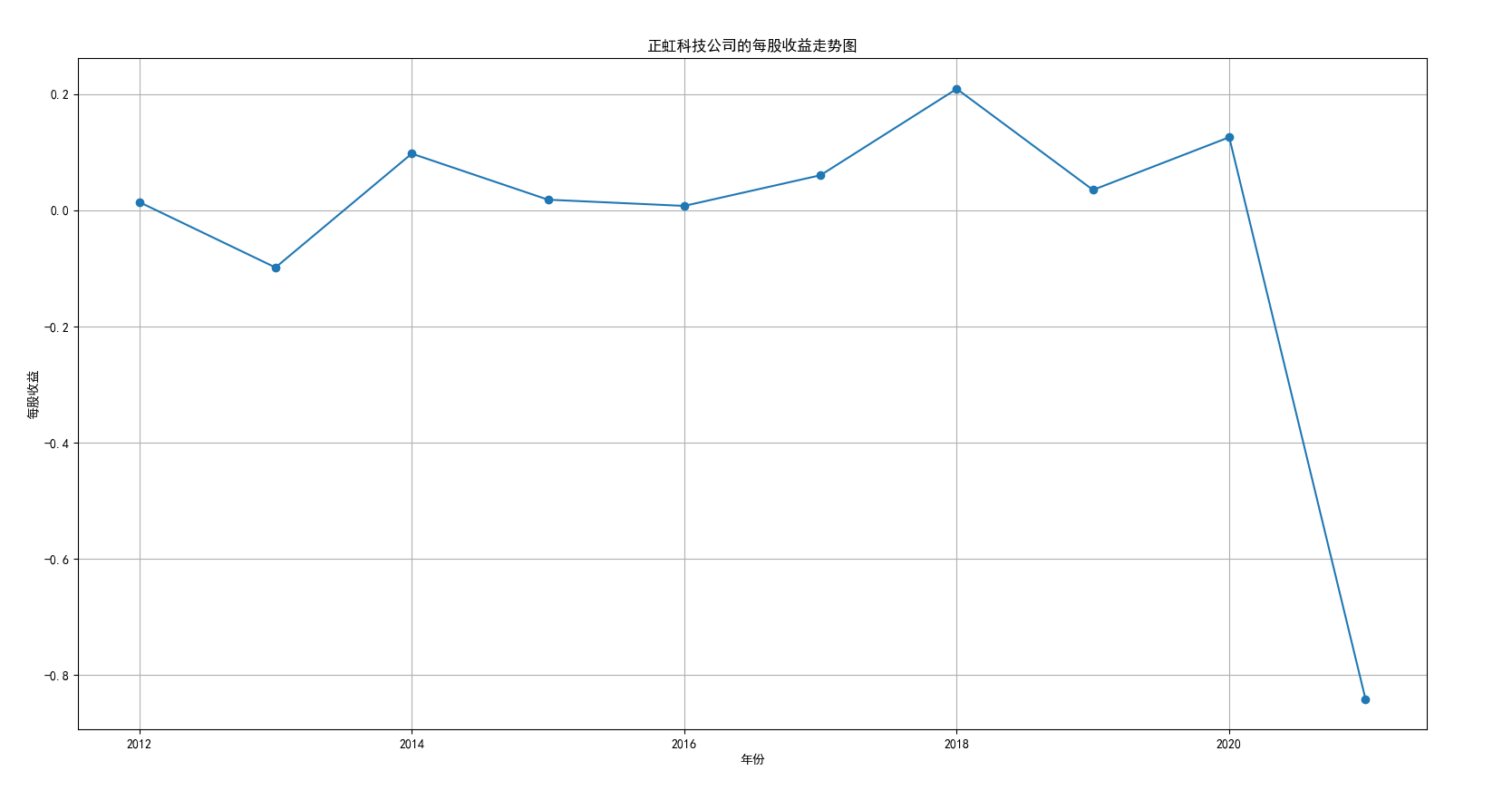
我国是一个农业大国,农业在我国的国民经济中有着举足轻重的作用。建国以来,我国在发展农业、增产粮食方面取得了巨大的成就,农业生产条件大幅改善、农副产品产量大幅增长、农民生活水平显著提高。但是,我国农副食品加工业也存在诸多问题:一方面,我国农副食品加工容易受到自然条件的制约,呈现一定的季节性;另一方面,我国农副产品加工基本处于低级、粗放、零散的状态,技术含量低;此外,我国农副食品加工增值的比重较低、利润薄,农产品加工损耗大。据统计,我国每年的粮食产后损失超过500亿斤,损失率达到8%-12%;蔬菜每年损失率超过20%,特别是叶菜类损失超过30%,远高于发达国家均值。以蔬菜为例,我国每年只有60%-70%可以得到有效利用。 从得到的营业收入情况图以及每股收益走势图可以看出,公司大多都是处于普通经营的状态,除了一些龙头企业。只有类似于广弘控股这样的公司才能够获得较高的营业收入,以及比较乐观的每股收益状态。这也是由于其曾停牌三年之久,而后才由深圳重新挂牌上市。农副食品深受我国消费者喜爱,其市场区域分布广泛。农副食品整体不具备明显的季节性。但个别农副食品因不同地区消费者消费习惯及消费水平影响呈现出明显的地域性。因此,对于生产加工单一品类的农副食品的企业,若要提高不同区域的市场占有率、扩大消费群体,则必须开发出适合不同地区市场、不同人群的产品,这对行业内的企业提出了较高的要求。目前我国的食储藏和果蔬产后损耗率25%,远高于发达国家水平;农产品产后产值与采收时自然产值之比仅为0.38;1;产品粗加工多;精加工少;初级产品多;深加工产品少;中低档产品多;高档产品少;而且农产品的深加工技术和装备普遍落后于发达国家10-20年,高新加工技术的应用较少。因此如果想要提升农副产品加工业的整体营业收入,也依旧是从技术入手,提升技术水平,提高工作效率,增加与一二级产业的关联程度,充分利用产业间的带动作用。