from bs4 import BeautifulSoup#导入模块
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Edge()#爬取有报喜鸟年报信息的网页
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
elem = browser.find_element(By.ID,'input_code')
elem.send_keys('报喜鸟' + Keys.RETURN)#在输入栏输入报喜鸟
browser.find_element_by_link_text("请选择公告类别").click()
browser.find_element_by_link_text("年度报告").click()#选择年度报告
element = browser.find_element(By.ID,"disclosure-table")
innerHTML = element.get_attribute("innerHTML")
f = open("作业三素材.html",'w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()#关闭浏览器
class DisclosureTable():#定义面向对象的函数
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('<a.*?>(.*?)</a> ', re.DOTALL)
p_span = re.compile('<span.*?>(.*?)</span> ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('<tr>(.*?)</tr> ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('<td.*?>(.*?)</td> ', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span> '
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
f = open('作业三素材.html',encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)#引用定义的函数
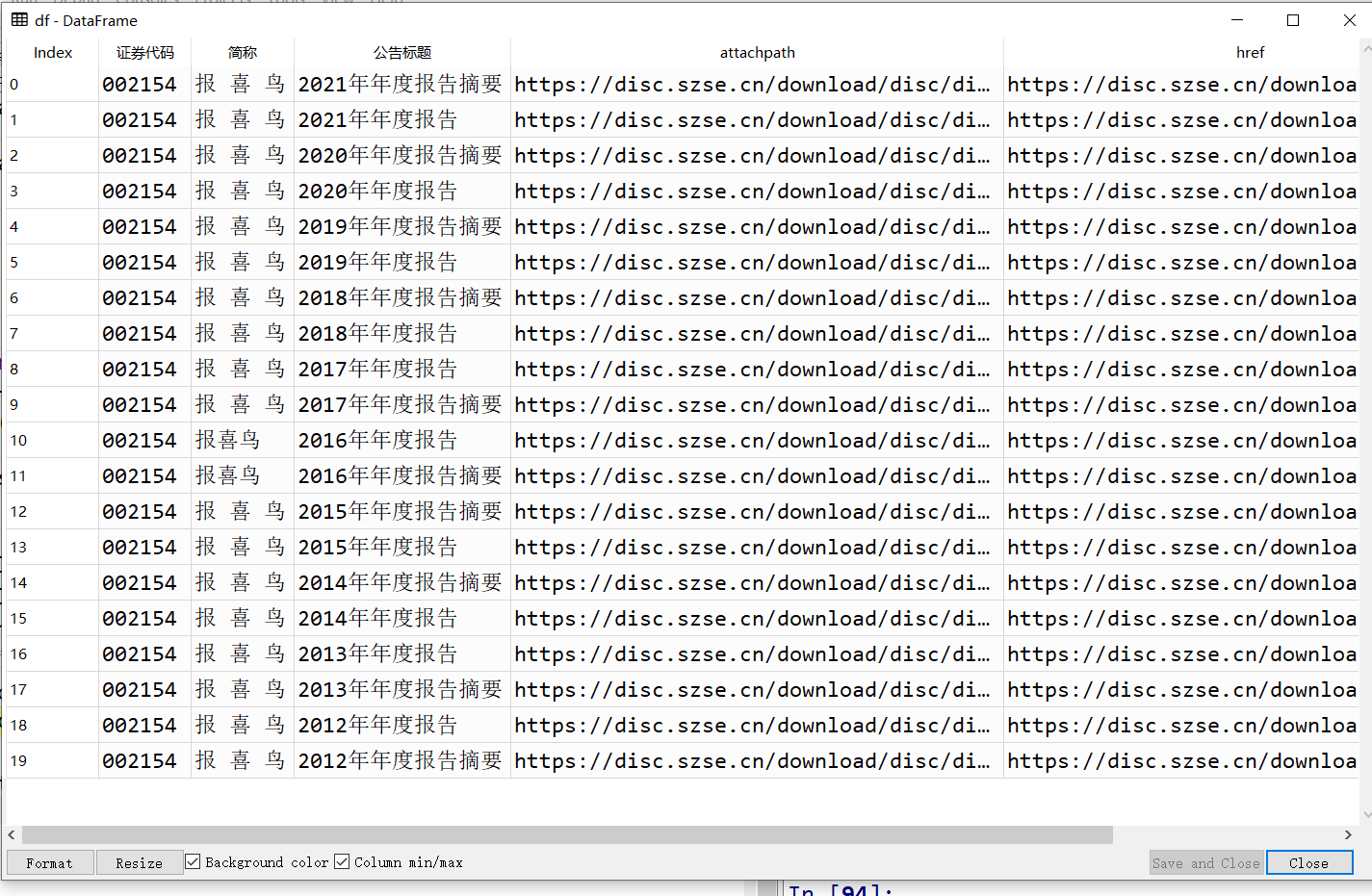
df = dt.get_data()
df=df.iloc[:20,]#截取前十年的年度报告数据
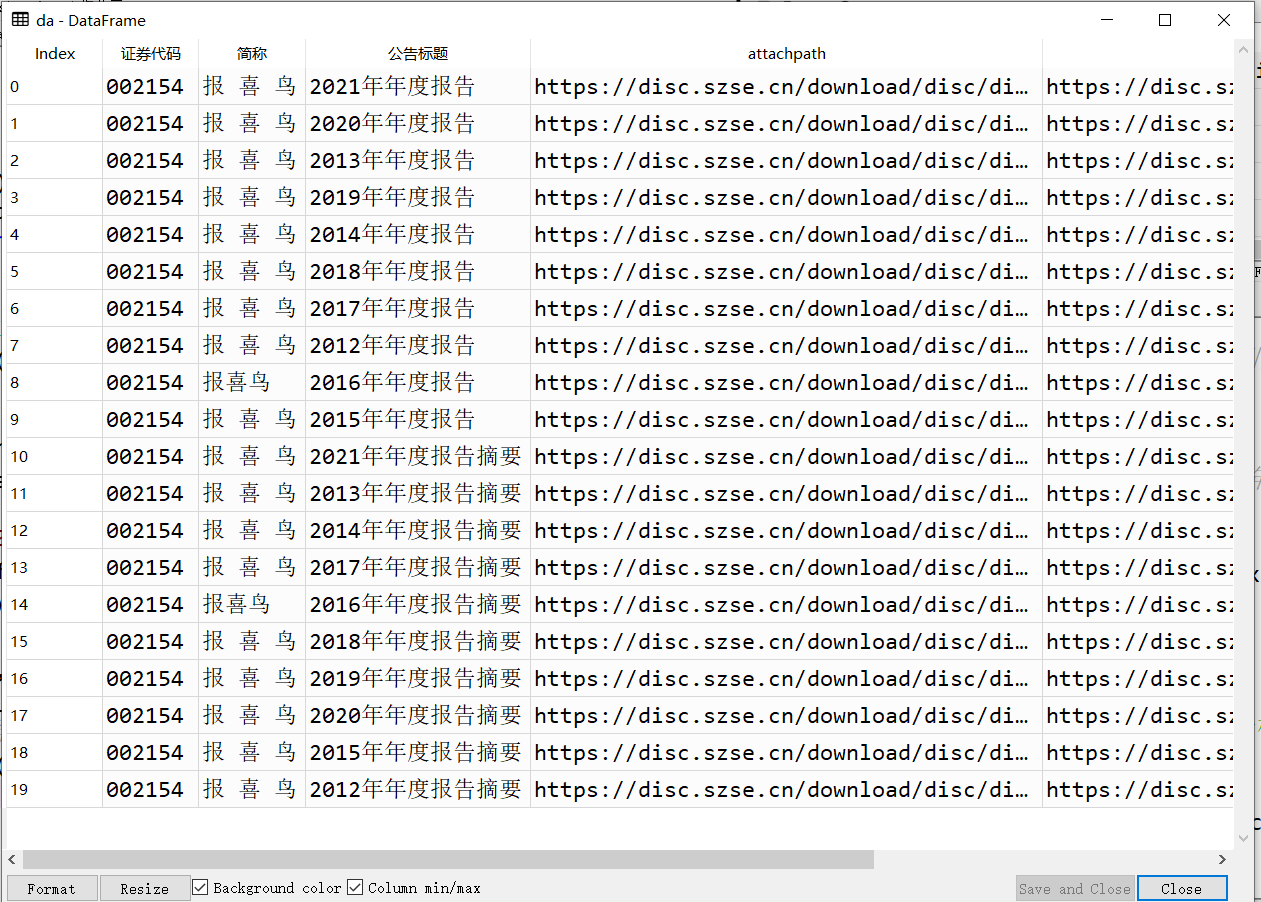
da=df.iloc[(df["公告标题"].str.len()).argsort()].reset_index(drop=True)#按公告标题字数的长度排序
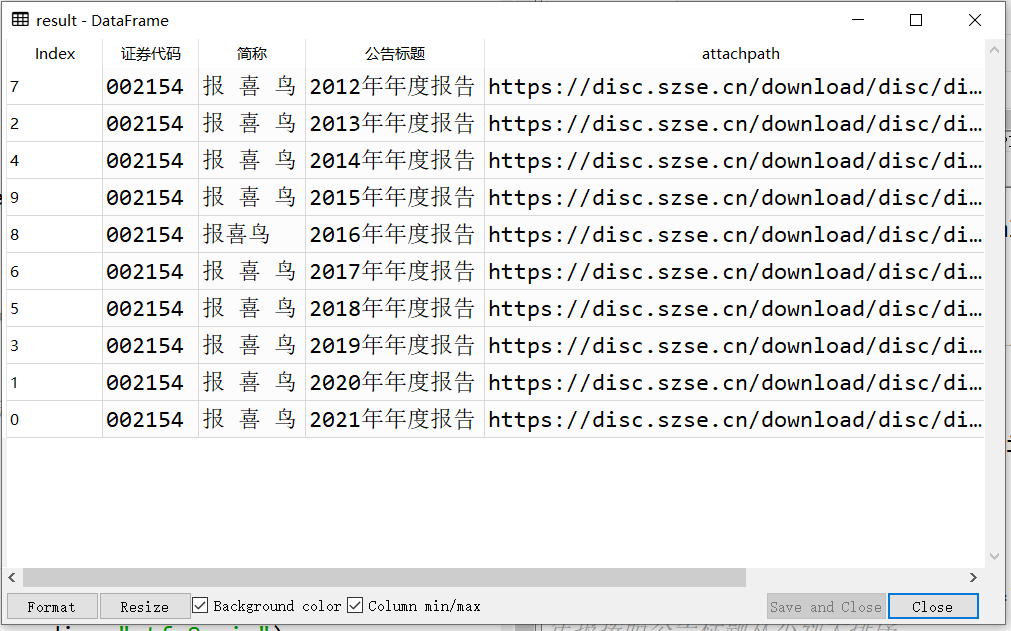
d=da.iloc[:10,]
result=d.sort_values(by="公告标题",ascending=True)#将年报按照公告标题从小到大排序
result.to_csv('clear.csv',encoding="utf-8-sig")
代码先导入模块,然后爬取有报喜鸟年报信息的网页
定义面向对象的函数,然后引用模块,得出结果,如截图所示
from bs4 import BeautifulSoup
import re
import pandas as pd
f = open('000798.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open('000798_prettified.html','w', encoding='utf-8')
f.write(html_prettified)
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open('disclosure-table_prettified.html','w', encoding='utf-8')
f.write(html_prettified)
f.close()
p = re.compile('<tr>(.*?)</tr> ', re.DOTALL)
trs = p.findall(html_prettified)
p1 = re.compile('<td.*?>(.*?年度报告".*?)</td> ', re.DOTALL)
td1 = [p1.findall(tr) for tr in trs[1:]]
tds = [td for td in td1 if td!=[] ]
p2 = re.compile('<td.*?>(.*?年度报告(更新后)".*?)</td> ', re.DOTALL)
td2 = [p2.findall(tr) for tr in trs[1:]]
tds1 = [td for td in td2 if td!=[] ]
tds.extend(tds1)
p_link_ftitle = re.compile('<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span> ',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[0])[0] for td in tds]
p_pub_time = re.compile('.*?finalpage/(.*?)/.*?')
p_times = [p_pub_time.search(td[0]).group(1) for td in tds]
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = pd.DataFrame({'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix + lf[0].strip() for lf in link_ftitles],
'href': [prefix_href + lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
data = df.sort_values(by = '公告标题',ascending = False)
df.to_csv('sample_data_from_szse.csv')
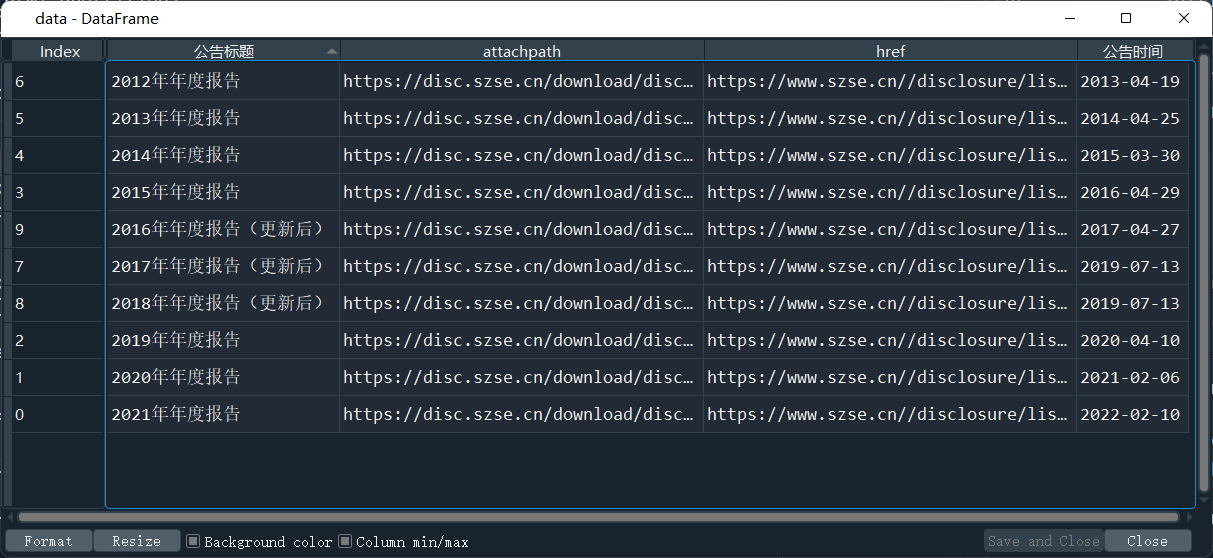
导入下载好的网页内容,用正则表达式将网址、日期等信息提取并放入数据框中
此方法没有发挥网络爬虫的作用,相比方法一需要手动操作的步骤较多,不够灵活