傅元娴的作业一
代码
f1 = open("作业一素材.txt", "r", encoding = "utf-8")
def newlines():
new_lines = []
for line in f1.readlines():
line = line.strip('.\n')
new_lines.append(line)
return new_lines
result = newlines()
#print(result)
last_line = result[-3]
#print(last_line)
last_line_list = last_line.split(sep = " ")
#print(last_line_list)
last_word = last_line_list[-1]
#print(last_word)
def count():
n = 0
for i in last_word:
n = n + 1
return n
length1 = count()
print("最后一个单词的长度是:{}".format(length1))
结果
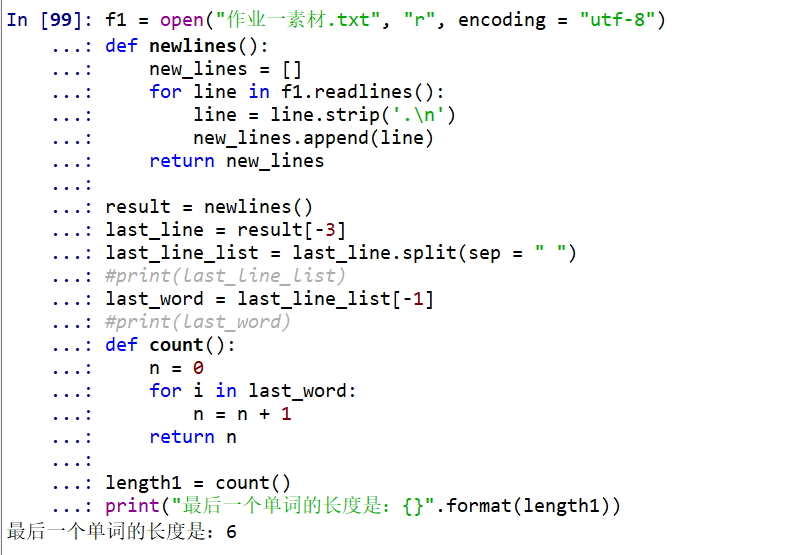
解释(步骤)
- 以只读模式打开作业一文本素材
- 定义函数将文本里面的换行符去掉,并以列表形式返回
- 取列表的最后一个元素,它包含最后一个单词
- 用split分隔单词
- 取最后一个单词
- 定义函数利用for循环计算最后一个单词的长度
附加题代码
f2 = open("作业一附加选做题素材.txt", "r", encoding = "utf-8")
def newlines2():
new_lines2 = []
for line in f2.readlines():
line = line.strip('\n')
new_lines2.append(line)
return new_lines2
result2 = newlines2()
last_part1 = result2[-4].split("。")[1]
last_part2 = result2[-3]
last_sen = last_part1 + last_part2
#print(last_sen)
def count():
n = 0
for i in last_sen:
n = n + 1
return n
length2 = count()
print("最后一个句子的长度是:{}".format(length2))
结果
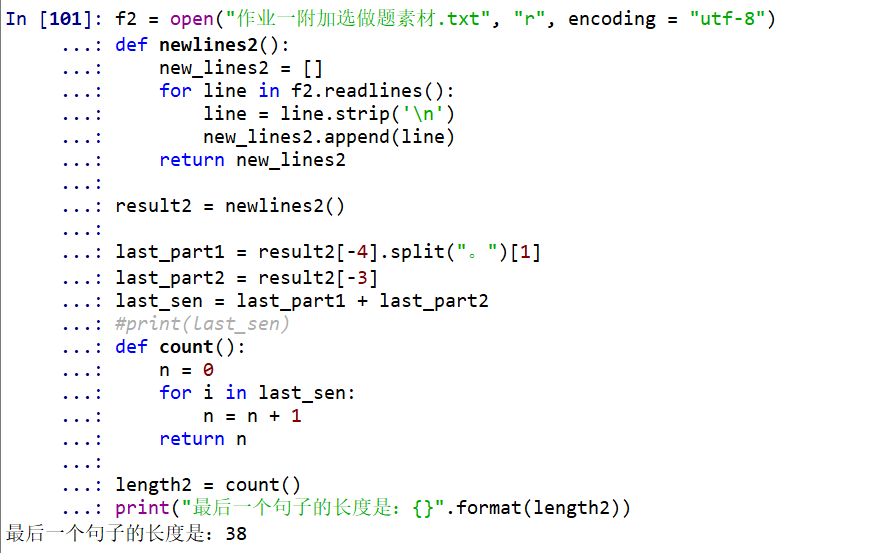
附加题解释(步骤)
- 以只读模式打开作业一附加题文本素材
- 定义函数将文本里面的换行符去掉,并以列表形式返回
- 将列表的最后两个元素分别取出,运用split函数将倒数第二个元素以句号分隔,并取出最后一个句子的前半句和后半句,最后合并成target句子
- 定义函数利用for循环计算最后一个句子的长度