王小庆的期末报告
代码
#引用必要模块
import pdfplumber
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from time import sleep
import os
from bs4 import BeautifulSoup
import re
import requests
import fitz
import csv
import matplotlib.pyplot as plt
#解析深交所并下载年报
driver_url = r"C:\edgedriver_win64\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory':'C\\Desktop\python\金融数据获取\现代投资'}
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
browser = webdriver.Edge(executable_path=driver_url, options=options)
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # Find the search box
element.send_keys('天茂集团' + Keys.RETURN)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
data_ele = browser.find_element(By.ID, 'disclosure-table')
innerHTML = data_ele.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
# html = to_pretty('innerHTML.html')
w = open('innerHTML.html',encoding='utf-8')
html = w.read()
w.close()
import re
import pandas as pd
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv('天茂集团.csv')
df = pd.read_csv('半导体行业.csv')
words = ['摘要','问询函','社会责任']
def filter_links(words,df,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df.f_name])
else:
ls.append([word not in f for f in df.f_name])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
df_all = filter_links(['摘要','问询函','社会责任'],df,include=False)
df_original = filter_links(['(','('], df_all)
words = ['摘要','问询函','社会责任']
include = False
for i in range(len(df['attachpath'])):
download_link = df['attachpath'][i]
browser.get(download_link)
try:
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
time.sleep(5) #这句一定要加,因为下载需要一点时间
browser.quit()
print('下载完毕')
except:
( '下载失败')
#解析上交所并下载年报
def sse_to_dataframe(filename):
f = open(filename+'.html',encoding='utf-8')
html = f.read()
f.close()
p_row=re.compile('(.*?)
',re.DOTALL)
trs=p_row.findall(html)
p_data=re.compile('(.*?)',re.DOTALL)
tds=[p_data.findall(t) for t in trs if p_data.findall(t)!=[]]
p_code=re.compile('(\d{6})')
p_name=re.compile('(\w+|-)')
p_href=re.compile('')
p_title=re.compile('(.*?)')
codes=[p_code.search(td[0]).group(1) for td in tds]
names=[p_name.search(td[1]).group(1) for td in tds]
links=[p_href.search(td[2]).group(1) for td in tds]
titles=[td[3][:4]+p_title.search(td[2]).group(1) for td in tds] #早年有的公司年报标题每年都一样,前面加一个发布年份以区分
pubtime=[td[3] for td in tds]
data=pd.DataFrame({'证券代码':codes,
'股票简称':names,
'公告标题':titles,
'公告链接':links,
'发布时间':pubtime})
for index,row in data.iterrows():
title=row[2]
time=row[-1][:4]
if ("年度报告" not in title and "年报" not in title) or (int(time))<2012:
data=data.drop(index=index)
return(data)
class DisclosureTable_sh():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'http://www.sse.com.cn'
p_code=re.compile('(\d{6})')
p_name=re.compile('(\w+|-)')
p_href=re.compile('')
p_title=re.compile('(.*?)')
self.get_code = lambda td: p_code.search(td).group(1)
self.get_name = lambda td: p_name.search(td).group(1)
self.get_href = lambda td: p_href.search(td).group(1)
self.get_title = lambda td: p_title.search(td).group(1)
self.txt_to_df() #调用txt_to_df(self),得到初始化dataframe用于后续匹配
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p_tr = re.compile('(.*?)
', re.DOTALL)
trs = p_tr.findall(html)
p_td = re.compile('(.*?)', re.DOTALL)
tds=[p_td.findall(td) for td in trs if p_td.findall(td)!=[]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'股票简称': [td[1] for td in tds],
'公告标题和链接': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt=df
def get_data(self):
get_code = self.get_code
get_name = self.get_name
get_href = self.get_href
get_title = self.get_title
df = self.df_txt
prefix = self.prefix
codes = [get_code(td) for td in df['证券代码']]
names = [get_name(td) for td in df['股票简称']]
links = [prefix+get_href(td) for td in df['公告标题和链接']]
titles = [td[3][:4]+get_title(td) for td in df['公告标题和链接']]
pubtime = [td for td in df['公告时间']]
data = pd.DataFrame({'证券代码':codes,
'股票简称':names,
'公告标题':titles,
'公告链接':links,
'公告时间':pubtime})
for index,row in data.iterrows():
title = row[2]
time = int(row[-1][:4])
if "年度报告" not in title and "年报" not in title:
data=data.drop(index=index)
if time<2011:
data_latest10=data.drop(index=index)
self.df_alldata = data
self.df_data = data_latest10
return data_latest10
for i in range(len(df_data)):
c = p_bnb.findall(df_data['公告标题'][i])
if len(c) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.drop_duplicates('year', keep='first', inplace=False)
df_data = df_data.reset_index(drop=True)
df_data['year_str'] = df_data['year'].astype(str)
df_data['name'] = name + df_data['year_str'] + '年报'
name1 = df_data['简称'][0]
df_data.to_csv('%.csv'%name1)
year = {'year': ['2012', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']}
dy = pd.DataFrame(year)
os.mkdir('%s年度报告'%name)
os.chdir(r'C:\Users\86191\Desktop\保险业\%s年度报告'%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df_data['简称'][0]
rename = name1 + ye
for a in range(len(df_data)):
if df_data['name'][a] == '%s年报'%rename:
href0 = df_data.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
#提取下载的年报的基本信息
hbcwsj = pd.DataFrame(index=range(2012,2021),columns=['营业收入','基本每股收益'])
hbsj = pd.DataFrame()
for i in range(len(hb1)):
name2 = hb1[2][i]
code = hb1['code']
dcsv = pd.read_csv(r'C:\Users\86191\Desktop\python\金融数据获取\保险业%scsv文件.csv'%name2)
dcsv['year_str'] = dcsv['year'].astype(str)
os.chdir(r'C:\Users\86187\Desktop\食品制造业10年内年度报告\%s年度报告'%name2)
#r = 0
for r in range(len(dcsv)):
year_int = dcsv.year[r]
if year_int >= 2012:
year2 = dcsv.year_str[r]
aba = name2 + year2
doc = fitz.open(r'%s年度报告.PDF'%aba)
text=''
for j in range(22):
page = doc[j]
text += page.get_text()
#p_year = re.compile('.*?(\d{4}) .*?年度报告.*?')
#year_int = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
#p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]*)\s?(?=\n)')
p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)')
revenue = float(p_rev.search(text).group(1).replace(',',''))
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n([-\d+,.]*)\s?(?=\n)')
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n.*?\n?([-\d+,.]+)\s?(?=\n)')
p_eps = re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)')
eps = float(p_eps.search(text).group(1))
#p_web = re.compile('(?<=\n)公司.*?网址.*?\n(.*?)(?=\n)')
p_web = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)')
web = p_web.search(text).group(1)
p_site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)')
site = p_site.search(text).group(1)
hbcwsj.loc[year_int,'营业收入'] = revenue
hbcwsj.loc[year_int,'基本每股收益'] = eps
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(20): #读取每份年报前20页的数据(一般财务指标读在前20页)
page = doc[j]
text += page.get_text()
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
pre_rev=final.loc[year-1,'营业收入(元)']
eps=p_eps.search(text).group(1)
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
site=p_site.search(text).group(1) #匹配办公地址和网址(由于取最近一年的,所以只要匹配一次不用循环匹配)
web=p_web.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='%s\n营业收入,%s\n基本每股收益,股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s\n营业收入,%s\n基本每股收益,'%(name,code,site,web,revenue,eps)
f.write(content)
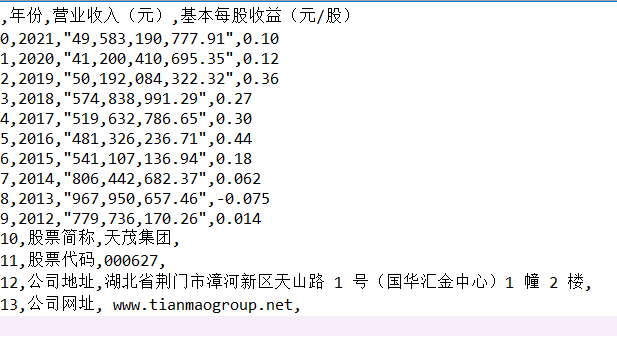
df = pd.read_csv('天茂集团.csv', header=None)
df.head()
x1=df[1]
a=x.tolist()
del a[0]
c=[x.replace(',','') for x in a]
d=[float(i) for i in c]
y1=df[0]
plt.xticks(rotation=45)
plt.xlabel("年份")
plt.ylabel("营业收入(元)")
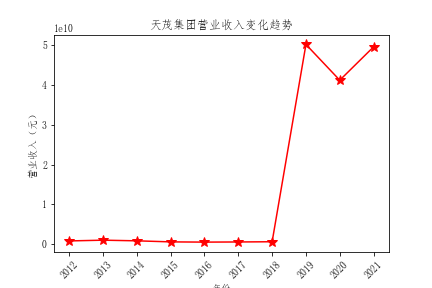
plt.title("天茂集团营业收入变化趋势")
plt.xticks(range(2011,2022))
plt.plot(x1, y1, "r", marker='*', ms=10, label="天茂集团")
plt.savefig("天茂集团营业收入变化趋势.png")
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('天茂集团.csv', header=None)
df.head()
x=df[2]
a=x.tolist()
del a[0]
c=[x.replace(',','') for x in a]
d=[float(i) for i in c]
y=df[0]
plt.xticks(rotation=45)
plt.xlabel("年份")
plt.ylabel("基本每股收益(元)")
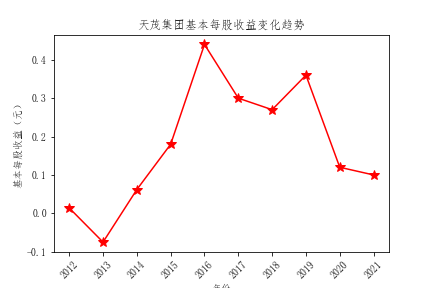
plt.title("天茂集团基本每股收益变化趋势")
plt.rcParams['font.sans-serif']=['FangSong']
plt.rcParams['axes.unicode_minus']=False
plt.xticks(range(2011,2022))
plt.plot(x, y, "r", marker='*', ms=10, label="a")
plt.savefig("天茂集团基本每股收益变化趋势.png")
plt.show()
#各上市公司营业收入比较绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
name=['天茂集团','中国人寿','中国太保','中国平安','新华保险','西水股份','中国人保']
shouru=[]
for i in name:
df = pd.read_csv(i+'.csv', header=None)
df.head()
x=df[1]
a=x.tolist()
del a[0]
c=[x.replace(',','') for x in a]
d=[float(i) for i in c]
shouru.append(d[9])
df1= pd.read_csv(name1+'.csv', header=None)
df1.head()
x1=df1[1]
a1=x1.tolist()
del a1[0]#
c1=[x.replace(',','') for x in a1]
d1=[float(i) for i in c1]
#加入各年数据
for i in name2:
df2 = pd.read_csv(i+'.csv', header=None)
df2.head()
x2=df2[1]
a2=x2.tolist()
del a2[0]
c2=[x.replace(',','') for x in a2]
d2=[float(i) for i in c2]
shouru.append(d2[5])
plt.xlabel('年份')
plt.xticks(rotation=45)
plt.ylabel('营业收入(元)')
plt.title("保险业营业收入对比")
plt.bar(x=name4,height=shouru)
plt.savefig('保险业营业收入对比.png')
plt.show()
#各上市公司基本每股收益比较绘图代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
name=['天茂集团','中国人寿','中国太保','中国平安','新华保险','西水股份','中国人保']
shouyi=[]
for i in name:
df = pd.read_csv(i+'.csv', header=None)
df.head()
x=df[2
a=x.tolist()
del a[0]
c=[x.replace(',','') for x in a]
d=[float(i) for i in c]
shouyi.append(d[9]
df1= pd.read_csv(name1+'.csv', header=None)
df1.head()
x1=df1[2]
a1=x1.tolist()
del a1[0]
c1=[x.replace(',','') for x in a1]
d1=[float(i) for i in c1]
shouyi.append(d1[6])
for i in name2:
df2 = pd.read_csv(i+'.csv', header=None)
df2.head()
x2=df2[2]
a2=x2.tolist()
del a2[0]
c2=[x.replace(',','') for x in a2]
d2=[float(i) for i in c2]
shouyi.append(d2[5])
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益(元)')
plt.title("2021年上市公司基本每股收益比较")
plt.plot(x=name4,height=shouyi)
plt.savefig('保险业基本每股收益对比.png')
plt.show()
结果


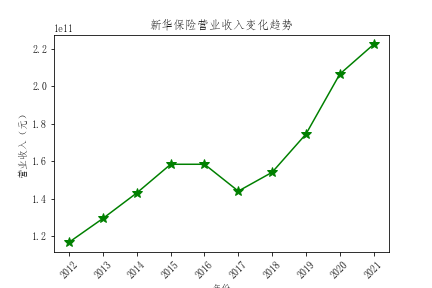
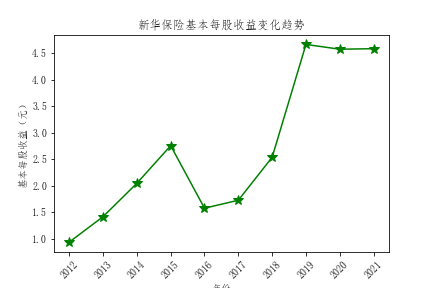
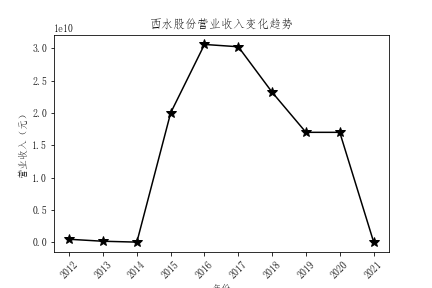
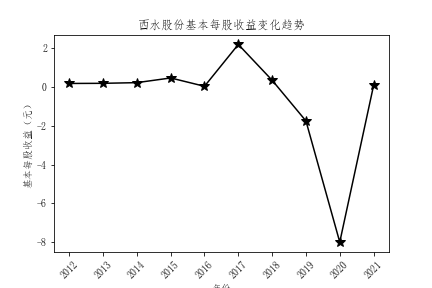
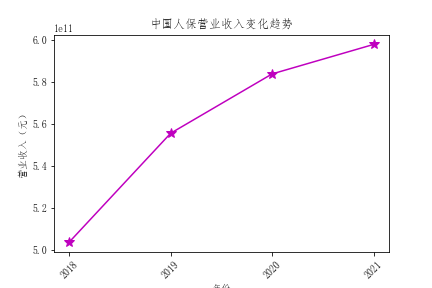
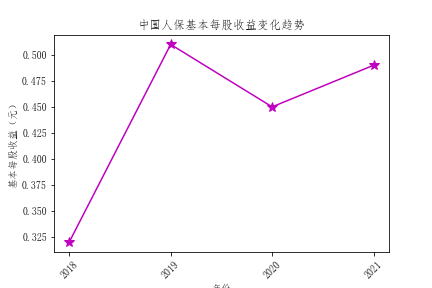
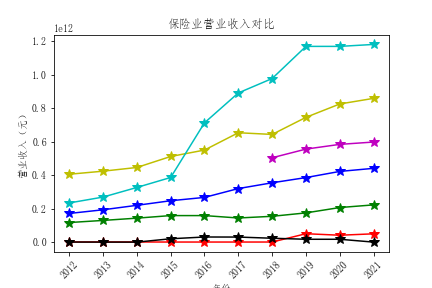
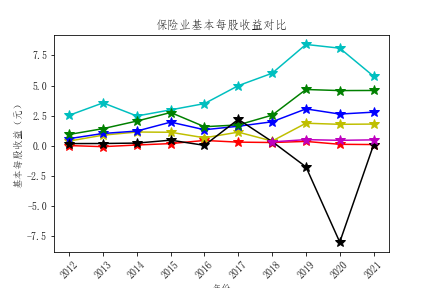
解读
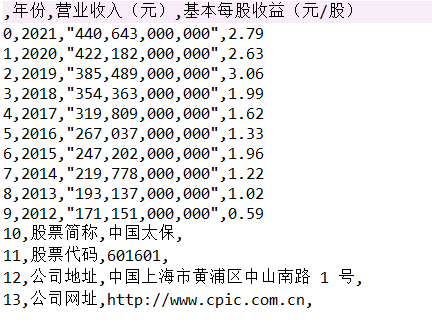
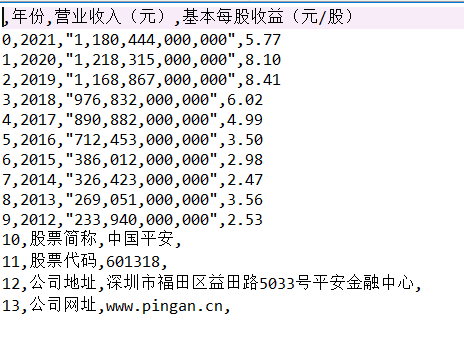
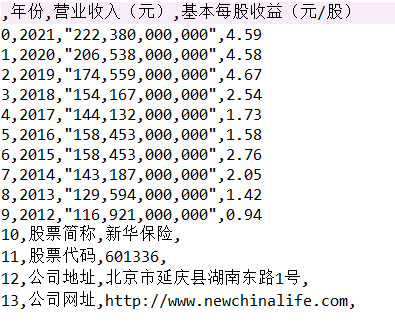
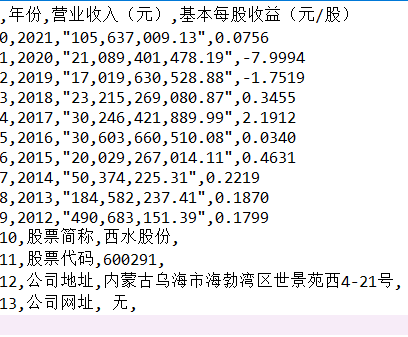
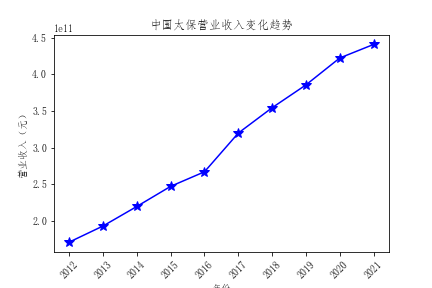
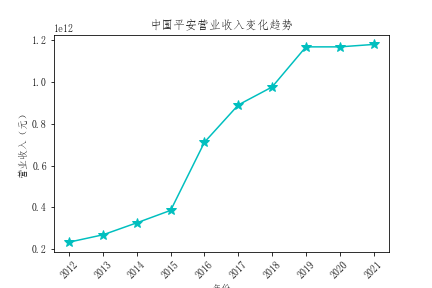
- 通过对比行业营业收入,我发现中国平安的营业收入远超过其他公司,并且增速迅速,具有活力
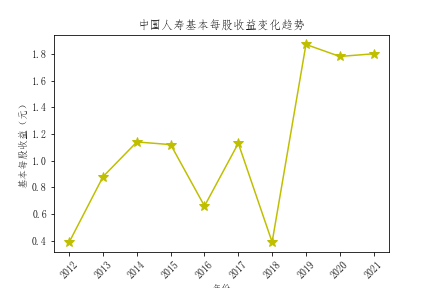
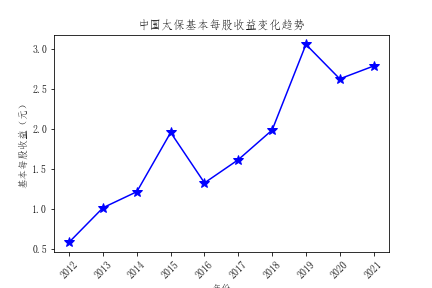
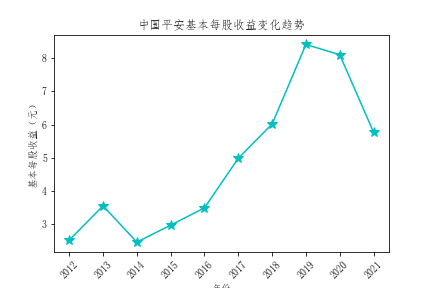
- 从基本每股收益的对比来看,也是中国平安的基本每股收益领先其他公司,投资者可以适当考虑中国平安的股票
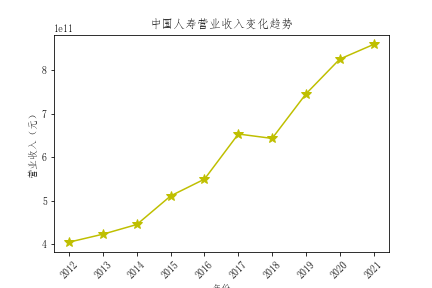
- 总体营业收入趋势来看,绝大多数公司营业收入都有增长,反映出保险行业在不断发展,但是行业内有两极分化倾向
感想
这次大作业对我而言是个巨大的挑战,也遇到了很多困难,写代码真的要自己亲自动手才知道程序员的不容易,频繁的报错真的很搞人心态,得益于自己的坚持和同学老师的帮助,我才完成了此次报告。
学习永无止境,我今后还是会提高对自己的要求的