'''
资本市场服务行业分析
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# browser = webdriver.Firefox()
driver_url = r"C:\edgedriver_win64\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory':r'D:\金融数据获取'}
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
browser = webdriver.Edge(executable_path=driver_url, options=options)
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # Find the search box
element.send_keys('东方财富' + Keys.RETURN)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
data_ele = browser.find_element(By.ID, 'disclosure-table')
innerHTML = data_ele.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
# html = to_pretty('innerHTML.html')
w = open('innerHTML.html',encoding='utf-8')
html = w.read()
w.close()
#解释:运用selenium控制浏览器检索某个上市公司信息,运用id进行元素定位,找到想要的信息。
#再写入innerHTML。由于能力有限,只能爬取深交所上市公司年报,上交所的公司年报没有爬取。
所以分析的只是深交所上市公司近十年营业收入和基本每股收益情况。
import re
import pandas as pd
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?) ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码':[td[0] for td in tds],
'简称':[td[1] for td in tds],
'公告标题':[td[2] for td in tds],
'公告时间':[td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码':codes,
'简称':short_names,
'公告标题':[aht[2] for aht in ahts],
'attachpath':[prefix + aht[0] for aht in ahts],
'href':[prefix_href + aht[1] for aht in ahts],
'公告时间':times
})
self.df_data = df
return(df)
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv('东方财富年报.csv')
#解释:把信息用源代码筛选后写入csv文件
for i in range(len(df['attachpath'])):
download_link = df['attachpath'][i]
browser.get(download_link)
try:
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
time.sleep(5) #这句一定要加,因为下载需要一点时间
browser.quit()
print('下载完毕')
except:
( '下载失败')
browser.quit()
#例如
 Company=pd.read_csv('东方财富年报.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
company=Company.iloc[:,1].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('D:/金融数据获取/%s/%s.pdf'%(com,title)
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?')
Company=pd.read_csv('东方财富年报.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
company=Company.iloc[:,1].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('D:/金融数据获取/%s/%s.pdf'%(com,title)
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?')
 #提取年报中的基本每股收益和营业收入
r1 = re.compile('\s营业[总]*收入(元)\s*(-?[\d,.]+)\s*',re.DOTALL)
r2 = re.compile('\s基本每股收益(元/股)\s*(-?[\d,.]+)\s*',re.DOTALL)
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
page_num = doc.page_count
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r1.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——营业收入.csv'.format(x),encoding='utf-8')
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
#name = df4.loc[n]
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r3.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——每股收益.csv'.format(x),encoding='utf-8')
#提取PDF文件中“股票简称”,“股票代码”,“办公地址”,“公司网址”
df2 = pd.DataFrame(columns=['股票简称','股票代码','办公地址','公司网址'])
for x in range(len(df4)):
name = df4['股票简称'][x]
doc = fitz.open('{0}_0.pdf'.format(name))
lst = ['股票简称','股票代码','办公地址','公司[国际互联网]*网址']
pages = {}
lst_text = {}
for i in lst:
try:
p = re.compile(i,re.DOTALL)
page_number = doc.page_count#获取文件页数
#对每一页进行遍历,匹配lst中的每一个元素
for page in range(page_number):
txt = doc[page].get_text()
match = p.findall(txt)
#若匹配到的macth不为空,则提取此时的页码
if len(match) != 0:
pages[i] = page
for k,v in pages.items():
text = doc[v].get_text()
r1 = re.compile('股票简称\s+(.+?)\n',re.DOTALL)
p1 = r1.findall(text)
lst_text['股票简称'] = p1[0]
r2 = re.compile('股票代码\s+(\d+)\s+',re.DOTALL)
p2 = r2.findall(text)
lst_text['股票代码'] = p2[0]
r3 = re.compile('办公地址\s+(.+?)\n',re.DOTALL)
p3 = r3.findall(text)
lst_text['办公地址'] = p3[0]
r4 = re.compile('公司[国际互联网]*网址\s+(.*?.+?)\s+',re.DOTALL)
p4 = r4.findall(text)
lst_text['公司网址'] = p4[0]
except Exception:
print('错误')
df2 = df2.append(lst_text,ignore_index=True)
#将提取的信息写入csv文件
df2.to_csv('上市公司基本信息.csv',encoding='utf-8')
#提取年报中的基本每股收益和营业收入
r1 = re.compile('\s营业[总]*收入(元)\s*(-?[\d,.]+)\s*',re.DOTALL)
r2 = re.compile('\s基本每股收益(元/股)\s*(-?[\d,.]+)\s*',re.DOTALL)
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
page_num = doc.page_count
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r1.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——营业收入.csv'.format(x),encoding='utf-8')
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
#name = df4.loc[n]
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r3.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——每股收益.csv'.format(x),encoding='utf-8')
#提取PDF文件中“股票简称”,“股票代码”,“办公地址”,“公司网址”
df2 = pd.DataFrame(columns=['股票简称','股票代码','办公地址','公司网址'])
for x in range(len(df4)):
name = df4['股票简称'][x]
doc = fitz.open('{0}_0.pdf'.format(name))
lst = ['股票简称','股票代码','办公地址','公司[国际互联网]*网址']
pages = {}
lst_text = {}
for i in lst:
try:
p = re.compile(i,re.DOTALL)
page_number = doc.page_count#获取文件页数
#对每一页进行遍历,匹配lst中的每一个元素
for page in range(page_number):
txt = doc[page].get_text()
match = p.findall(txt)
#若匹配到的macth不为空,则提取此时的页码
if len(match) != 0:
pages[i] = page
for k,v in pages.items():
text = doc[v].get_text()
r1 = re.compile('股票简称\s+(.+?)\n',re.DOTALL)
p1 = r1.findall(text)
lst_text['股票简称'] = p1[0]
r2 = re.compile('股票代码\s+(\d+)\s+',re.DOTALL)
p2 = r2.findall(text)
lst_text['股票代码'] = p2[0]
r3 = re.compile('办公地址\s+(.+?)\n',re.DOTALL)
p3 = r3.findall(text)
lst_text['办公地址'] = p3[0]
r4 = re.compile('公司[国际互联网]*网址\s+(.*?.+?)\s+',re.DOTALL)
p4 = r4.findall(text)
lst_text['公司网址'] = p4[0]
except Exception:
print('错误')
df2 = df2.append(lst_text,ignore_index=True)
#将提取的信息写入csv文件
df2.to_csv('上市公司基本信息.csv',encoding='utf-8')
 '''
绘制营业收入折线图
'''
dt0 = pd.read_csv('东北证券营业收入年报.csv',encoding='utf-8')
dt0 = dt0.rename(columns={'Unnamed: 0':'Data'})
dt0 = dt0.set_index('Data')
#删除重复列
del dt0['2020 年.1']
#将数据转换为浮点型
dt0.loc['东北证券'] = dt0.loc['东北证券'].str.replace(',','').astype(float)
dt1 = pd.read_csv('广发证券营业收入年报.csv',encoding='utf-8')
dt1 = dt1.rename(columns={'Unnamed: 0':'Data'})
dt1 = dt1.set_index('Data')
dt1.loc['广发证券'] = dt1.loc['广发证券'].str.replace(',','').astype(float)
dt2 = pd.read_csv('国海证券营业收入年报.csv',encoding='utf-8')
dt2 = dt2.rename(columns={'Unnamed: 0':'Data'})
dt2 = dt2.set_index('Data')
dt2.loc['国海证券'] = dt2.loc['国海证券'].str.replace(',','').astype(float)
dt3 = pd.read_csv('国元证券营业收入年报.csv',encoding='utf-8')
dt3 = dt3.rename(columns={'Unnamed: 0':'Data'})
dt3 = dt3.set_index('Data')
dt3.loc['国元证券'] = dt3.loc['国元证券'].str.replace(',','').astype(float)
dt4 = pd.read_csv('华西证券营业收入年报.csv',encoding='utf-8')
dt4 = dt4.rename(columns={'Unnamed: 0':'Data'})
dt4 = dt4.set_index('Data')
dt4.loc['华西证券'] = dt4.loc['华西证券'].str.replace(',','').astype(float)
dt5 = pd.read_csv('锦龙股份营业收入年报.csv',encoding='utf-8')
dt5 = dt5.rename(columns={'Unnamed: 0':'Data'})
dt5 = dt5.set_index('Data')
dt5.loc['锦龙股份'] = dt5.loc['锦龙股份'].str.replace(',','').astype(float)
dt6 = pd.read_csv('经纬纺机营业收入年报.csv',encoding='utf-8')
dt6 = dt6.rename(columns={'Unnamed: 0':'Data'})
dt6 = dt6.set_index('Data')
dt6.loc['经纬纺机'] = dt6.loc['经纬纺机'].str.replace(',','').astype(float)
dt7 = pd.read_csv('申万宏源营业收入年报.csv',encoding='utf-8')
dt7 = dt7.rename(columns={'Unnamed: 0':'Data'})
dt7 = dt7.set_index('Data')
dt7.loc['申万宏源'] = dt7.loc['申万宏源'].str.replace(',','').astype(float)
dt8 = pd.read_csv('中油资本营业收入年报.csv',encoding='utf-8')
dt8 = dt8.rename(columns={'Unnamed: 0':'Data'})
dt8 = dt8.set_index('Data')
#删除重复列
del dt8['2021 年.1']
dt8.loc['中油资本'] = dt8.loc['中油资本'].str.replace(',','').astype(float)
dt9 = pd.read_csv('东方财富营业收入年报.csv',encoding='utf-8')
dt9 = dt9.rename(columns={'Unnamed: 0':'Data'})
dt9 = dt9.set_index('Data')
dt9.loc['东方财富'] = dt9.loc['东方财富'].str.replace(',','').astype(float)
#绘制营业收入折线图
#显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#显示负号
plt.rcParams['axes.unicode_minus'] = False
# fname为你下载的字体库路径,
# 注意 SourceHanSansSC-Bold.otf
# 字体的路径
fname = "C:\Windows\Fonts\方正粗黑宋简体.ttf"
zhfont1 = fm.FontProperties(fname=fname)
#设置显示图片清晰度
plt.rcParams['figure.dpi'] = 100
#绘制十家公司营业收入图
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('营业收入',fontsize=40)
ax0 = fig.add_subplot(5,2,1)
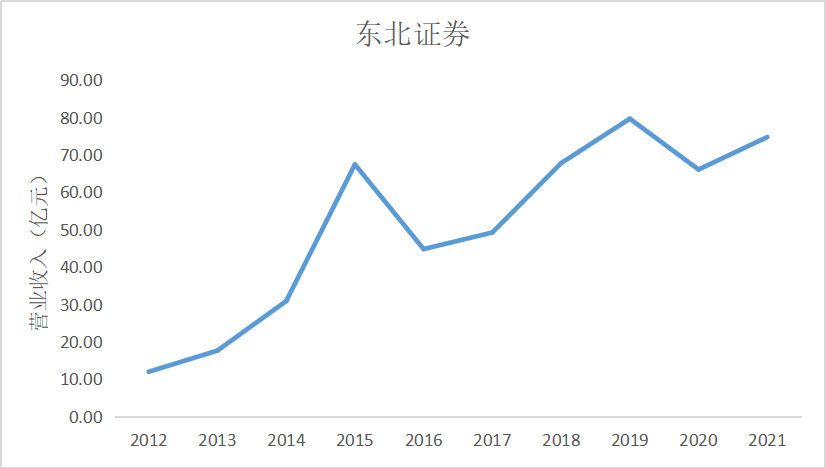
ax0.plot(dt0.loc['东北证券'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('营业收入(亿元)',fontsize=14)
ax0.set_title('东北证券',fontsize=14)
'''
绘制营业收入折线图
'''
dt0 = pd.read_csv('东北证券营业收入年报.csv',encoding='utf-8')
dt0 = dt0.rename(columns={'Unnamed: 0':'Data'})
dt0 = dt0.set_index('Data')
#删除重复列
del dt0['2020 年.1']
#将数据转换为浮点型
dt0.loc['东北证券'] = dt0.loc['东北证券'].str.replace(',','').astype(float)
dt1 = pd.read_csv('广发证券营业收入年报.csv',encoding='utf-8')
dt1 = dt1.rename(columns={'Unnamed: 0':'Data'})
dt1 = dt1.set_index('Data')
dt1.loc['广发证券'] = dt1.loc['广发证券'].str.replace(',','').astype(float)
dt2 = pd.read_csv('国海证券营业收入年报.csv',encoding='utf-8')
dt2 = dt2.rename(columns={'Unnamed: 0':'Data'})
dt2 = dt2.set_index('Data')
dt2.loc['国海证券'] = dt2.loc['国海证券'].str.replace(',','').astype(float)
dt3 = pd.read_csv('国元证券营业收入年报.csv',encoding='utf-8')
dt3 = dt3.rename(columns={'Unnamed: 0':'Data'})
dt3 = dt3.set_index('Data')
dt3.loc['国元证券'] = dt3.loc['国元证券'].str.replace(',','').astype(float)
dt4 = pd.read_csv('华西证券营业收入年报.csv',encoding='utf-8')
dt4 = dt4.rename(columns={'Unnamed: 0':'Data'})
dt4 = dt4.set_index('Data')
dt4.loc['华西证券'] = dt4.loc['华西证券'].str.replace(',','').astype(float)
dt5 = pd.read_csv('锦龙股份营业收入年报.csv',encoding='utf-8')
dt5 = dt5.rename(columns={'Unnamed: 0':'Data'})
dt5 = dt5.set_index('Data')
dt5.loc['锦龙股份'] = dt5.loc['锦龙股份'].str.replace(',','').astype(float)
dt6 = pd.read_csv('经纬纺机营业收入年报.csv',encoding='utf-8')
dt6 = dt6.rename(columns={'Unnamed: 0':'Data'})
dt6 = dt6.set_index('Data')
dt6.loc['经纬纺机'] = dt6.loc['经纬纺机'].str.replace(',','').astype(float)
dt7 = pd.read_csv('申万宏源营业收入年报.csv',encoding='utf-8')
dt7 = dt7.rename(columns={'Unnamed: 0':'Data'})
dt7 = dt7.set_index('Data')
dt7.loc['申万宏源'] = dt7.loc['申万宏源'].str.replace(',','').astype(float)
dt8 = pd.read_csv('中油资本营业收入年报.csv',encoding='utf-8')
dt8 = dt8.rename(columns={'Unnamed: 0':'Data'})
dt8 = dt8.set_index('Data')
#删除重复列
del dt8['2021 年.1']
dt8.loc['中油资本'] = dt8.loc['中油资本'].str.replace(',','').astype(float)
dt9 = pd.read_csv('东方财富营业收入年报.csv',encoding='utf-8')
dt9 = dt9.rename(columns={'Unnamed: 0':'Data'})
dt9 = dt9.set_index('Data')
dt9.loc['东方财富'] = dt9.loc['东方财富'].str.replace(',','').astype(float)
#绘制营业收入折线图
#显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#显示负号
plt.rcParams['axes.unicode_minus'] = False
# fname为你下载的字体库路径,
# 注意 SourceHanSansSC-Bold.otf
# 字体的路径
fname = "C:\Windows\Fonts\方正粗黑宋简体.ttf"
zhfont1 = fm.FontProperties(fname=fname)
#设置显示图片清晰度
plt.rcParams['figure.dpi'] = 100
#绘制十家公司营业收入图
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('营业收入',fontsize=40)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt0.loc['东北证券'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('营业收入(亿元)',fontsize=14)
ax0.set_title('东北证券',fontsize=14)
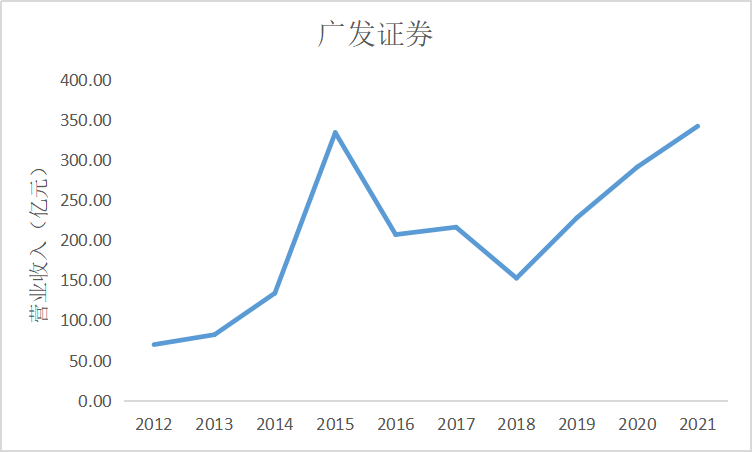
 ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt1.loc['广发证券'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('营业收入(亿元)',fontsize=14)
ax1.set_title('广发证券',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt1.loc['广发证券'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('营业收入(亿元)',fontsize=14)
ax1.set_title('广发证券',fontsize=14)
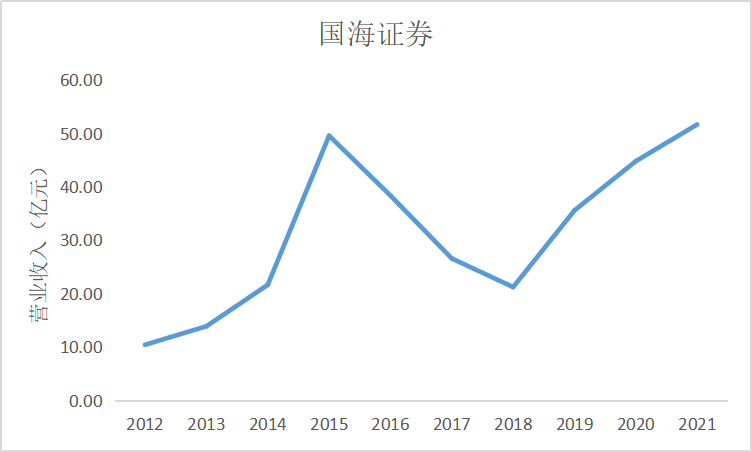
 ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt2.loc['国海证券'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('营业收入(亿元)',fontsize=14)
ax2.set_title('国海证券',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt2.loc['国海证券'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('营业收入(亿元)',fontsize=14)
ax2.set_title('国海证券',fontsize=14)
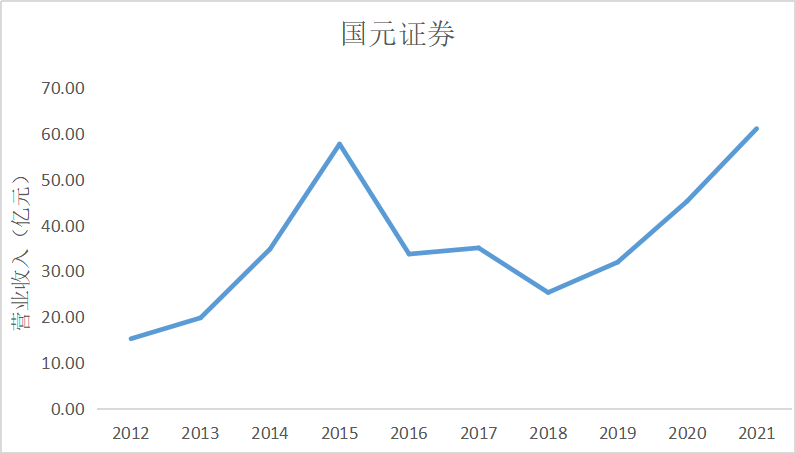
 ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt3.loc['国元证券'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('营业收入(亿元)',fontsize=14)
ax3.set_title('国元证券',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt3.loc['国元证券'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('营业收入(亿元)',fontsize=14)
ax3.set_title('国元证券',fontsize=14)
 ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt4.loc['华西证券'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('营业收入(亿元)',fontsize=14)
ax4.set_title('华西证券',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt4.loc['华西证券'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('营业收入(亿元)',fontsize=14)
ax4.set_title('华西证券',fontsize=14)
 ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt5.loc['锦龙股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('营业收入(亿元)',fontsize=14)
ax5.set_title('锦龙股份',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt5.loc['锦龙股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('营业收入(亿元)',fontsize=14)
ax5.set_title('锦龙股份',fontsize=14)
 ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt6.loc['经纬纺机'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('营业收入(亿元)',fontsize=14)
ax6.set_title('经纬纺机',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt6.loc['经纬纺机'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('营业收入(亿元)',fontsize=14)
ax6.set_title('经纬纺机',fontsize=14)
 ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt7.loc['申万宏源'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('营业收入(亿元)',fontsize=14)
ax7.set_title('申万宏源',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt7.loc['申万宏源'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('营业收入(亿元)',fontsize=14)
ax7.set_title('申万宏源',fontsize=14)
 ax8 = fig.add_subplot(5,2,9)
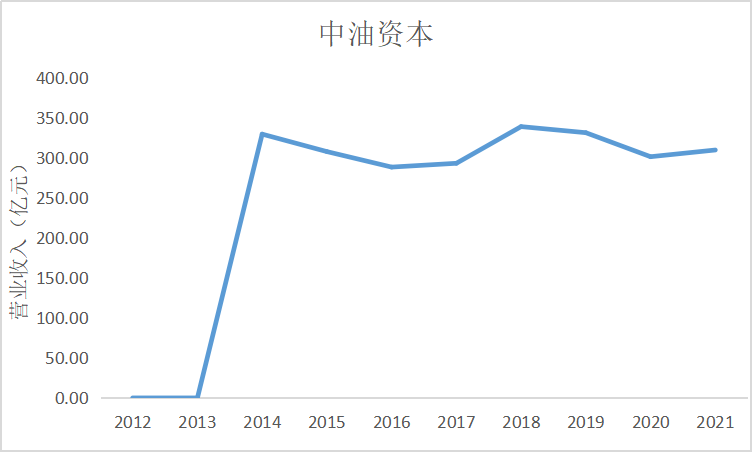
ax8.plot(dt8.loc['中油资本'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('营业收入(亿元)',fontsize=14)
ax8.set_title('中油资本',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt8.loc['中油资本'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('营业收入(亿元)',fontsize=14)
ax8.set_title('中油资本',fontsize=14)
 ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt9.loc['东方财富'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('营业收入(亿元)',fontsize=14)
ax9.set_title('东方财富',fontsize=14)
plt.show()
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt9.loc['东方财富'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('营业收入(亿元)',fontsize=14)
ax9.set_title('东方财富',fontsize=14)
plt.show()
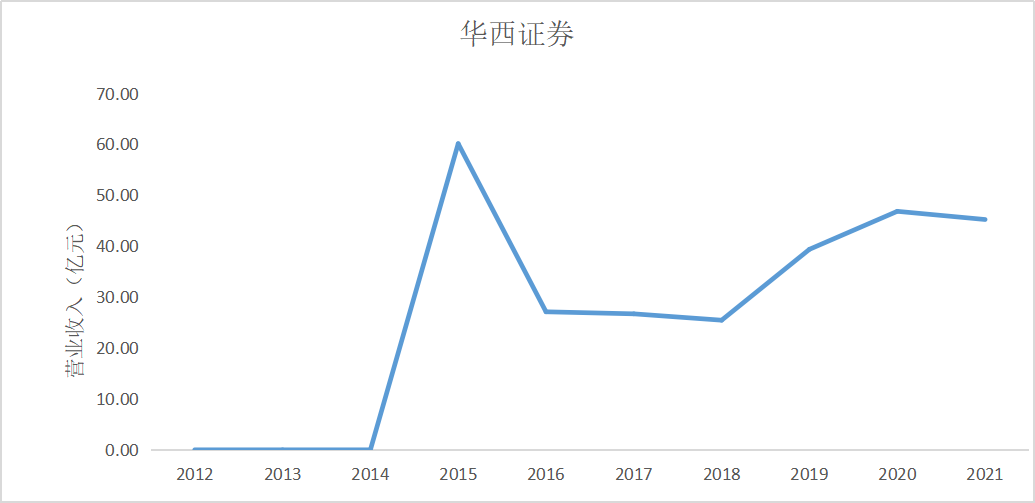
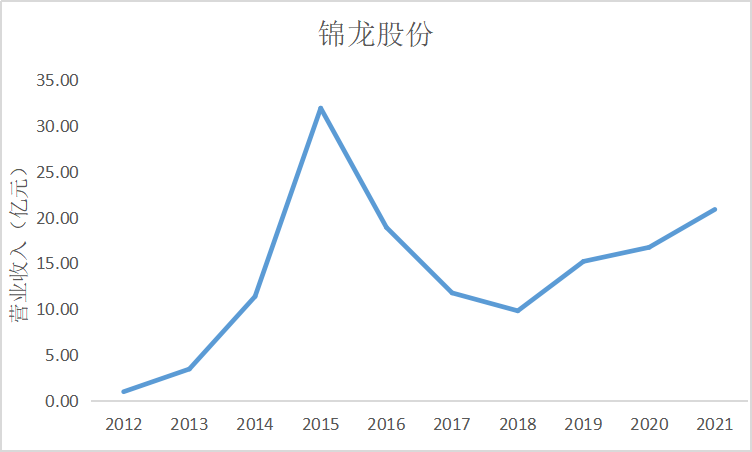
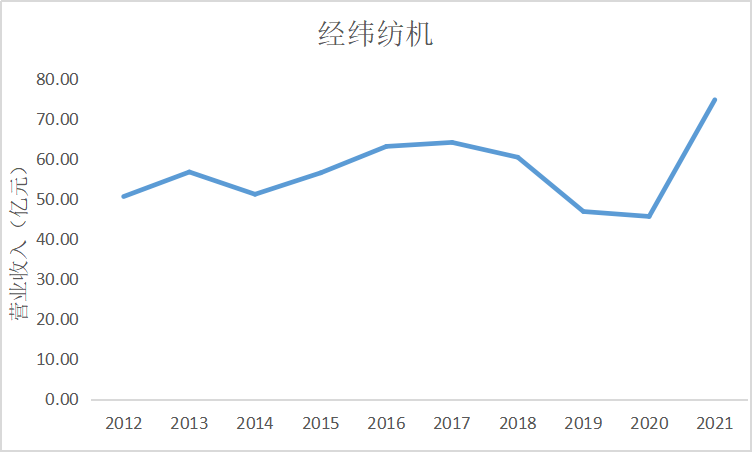
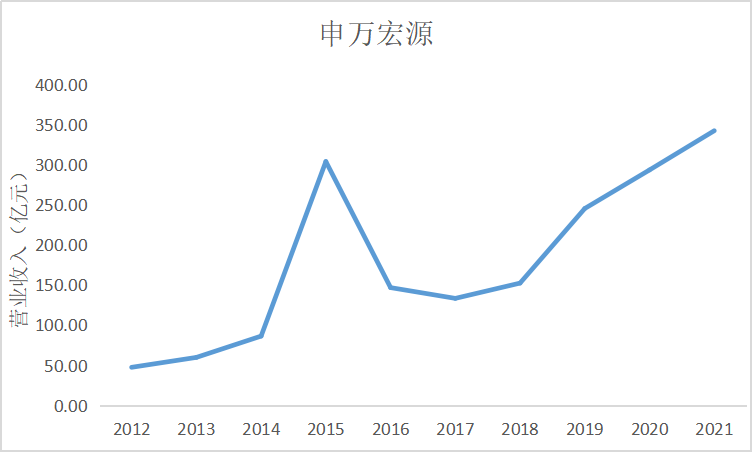
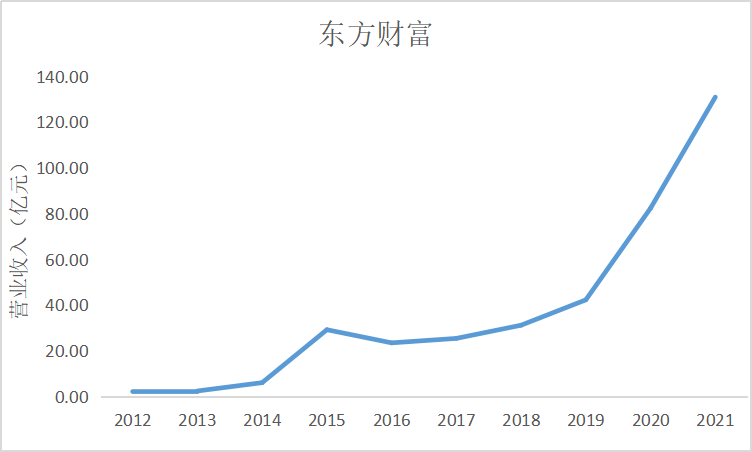 根据上面的图表可以看出十家上市公司在近10年的发展中营业收入都是呈现增加上升
趋势,尤其是在2015年正好处于我国股市牛市时期,市场行情大好,很多证券公司都从中
获利,尤其是广发证券公司,在2014年至2015年间增加了近200亿营业收入。自2018年
我国受贸易战影响国际市场收缩,再加上2020年疫情的影响,国内经济下行压力增大,国内
证券公司营业收入呈现缓慢增长趋势。
#读取十家公司基本每股收益数据
dt_0 = pd.read_csv('东北证券每股收益.csv',encoding='utf-8')
dt_0 = dt_0.rename(columns={'Unnamed: 0':'Data'})
dt_0 = dt_0.set_index('Data')
#删除重复列
del dt_0['2020 年.1']
dt_0.loc['东北证券'] = dt_0.loc['东北证券'].astype(float)
dt_1 = pd.read_csv('广发证券每股收益.csv',encoding='utf-8')
dt_1 = dt_1.rename(columns={'Unnamed: 0':'Data'})
dt_1 = dt_1.set_index('Data')
dt_1.loc['广发证券'] = dt_1.loc['广发证券'].astype(float)
dt_2 = pd.read_csv('国海证券每股收益.csv',encoding='utf-8')
dt_2 = dt_2.rename(columns={'Unnamed: 0':'Data'})
dt_2 = dt_2.set_index('Data')
dt_2.loc['国海证券'] = dt_2.loc['国海证券'].astype(float)
dt_3 = pd.read_csv('国元证券每股收益.csv',encoding='utf-8')
dt_3 = dt_3.rename(columns={'Unnamed: 0':'Data'})
dt_3 = dt_3.set_index('Data')
dt_3.loc['国元证券'] = dt_3.loc['国元证券'].astype(float)
dt_4 = pd.read_csv('华西证券每股收益.csv',encoding='utf-8')
dt_4 = dt_4.rename(columns={'Unnamed: 0':'Data'})
dt_4 = dt_4.set_index('Data')
del dt_4['2014 年.1']
del dt_4['2014 年.2']
del dt_4['2014 年.3']
del dt_4['2021 年.1']
dt_4.loc['华西证券'] = dt_4.loc['华西证券'].astype(float)
dt_5 = pd.read_csv('锦龙股份每股收益.csv',encoding='utf-8')
dt_5 = dt_5.rename(columns={'Unnamed: 0':'Data'})
dt_5 = dt_5.set_index('Data')
dt_5.loc['锦龙股份'] = dt_5.loc['锦龙股份'].astype(float)
dt_6 = pd.read_csv('经纬纺机每股收益.csv',encoding='utf-8')
dt_6 = dt_6.rename(columns={'Unnamed: 0':'Data'})
dt_6 = dt_6.set_index('Data')
dt_6.loc['经纬纺机'] = dt_6.loc['经纬纺机'].astype(float)
dt_7 = pd.read_csv('申万宏源每股收益.csv',encoding='utf-8')
dt_7 = dt_7.rename(columns={'Unnamed: 0':'Data'})
dt_7 = dt_7.set_index('Data')
dt_7.loc['申万宏源'] = dt_7.loc['申万宏源'].astype(float)
dt_8 = pd.read_csv('中油资本每股收益.csv',encoding='utf-8')
dt_8 = dt_8.rename(columns={'Unnamed: 0':'Data'})
dt_8 = dt_8.set_index('Data')
del dt_8['2021 年.1']
dt_8.loc['中油资本'] = dt_8.loc['中油资本'].astype(float)
dt_9 = pd.read_csv('东方财富每股收益.csv',encoding='utf-8')
dt_9 = dt_9.rename(columns={'Unnamed: 0':'Data'})
dt_9 = dt_9.set_index('Data')
dt_9.loc['东方财富'] = dt_9.loc['东方财富'].astype(float)
#绘制十家公司基本每股收益图
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('基本每股收益(元)',fontsize=30)
ax0 = fig.add_subplot(5,2,1)
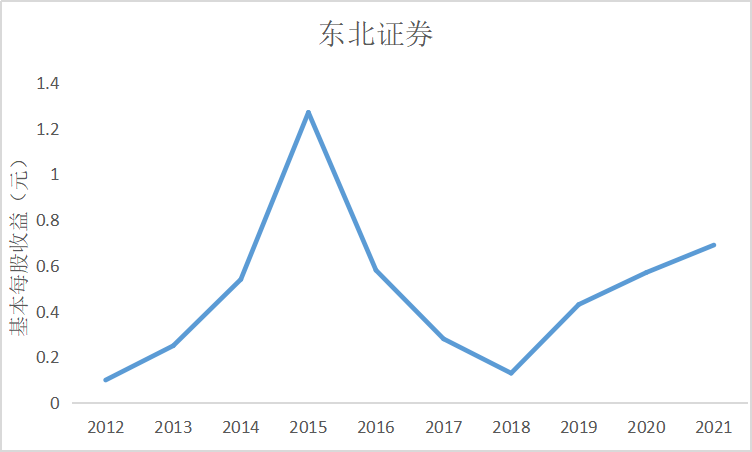
ax0.plot(dt_0.loc['东北证券'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('基本每股收益(元)',fontsize=14)
ax0.set_title('东北证券',fontsize=14)
根据上面的图表可以看出十家上市公司在近10年的发展中营业收入都是呈现增加上升
趋势,尤其是在2015年正好处于我国股市牛市时期,市场行情大好,很多证券公司都从中
获利,尤其是广发证券公司,在2014年至2015年间增加了近200亿营业收入。自2018年
我国受贸易战影响国际市场收缩,再加上2020年疫情的影响,国内经济下行压力增大,国内
证券公司营业收入呈现缓慢增长趋势。
#读取十家公司基本每股收益数据
dt_0 = pd.read_csv('东北证券每股收益.csv',encoding='utf-8')
dt_0 = dt_0.rename(columns={'Unnamed: 0':'Data'})
dt_0 = dt_0.set_index('Data')
#删除重复列
del dt_0['2020 年.1']
dt_0.loc['东北证券'] = dt_0.loc['东北证券'].astype(float)
dt_1 = pd.read_csv('广发证券每股收益.csv',encoding='utf-8')
dt_1 = dt_1.rename(columns={'Unnamed: 0':'Data'})
dt_1 = dt_1.set_index('Data')
dt_1.loc['广发证券'] = dt_1.loc['广发证券'].astype(float)
dt_2 = pd.read_csv('国海证券每股收益.csv',encoding='utf-8')
dt_2 = dt_2.rename(columns={'Unnamed: 0':'Data'})
dt_2 = dt_2.set_index('Data')
dt_2.loc['国海证券'] = dt_2.loc['国海证券'].astype(float)
dt_3 = pd.read_csv('国元证券每股收益.csv',encoding='utf-8')
dt_3 = dt_3.rename(columns={'Unnamed: 0':'Data'})
dt_3 = dt_3.set_index('Data')
dt_3.loc['国元证券'] = dt_3.loc['国元证券'].astype(float)
dt_4 = pd.read_csv('华西证券每股收益.csv',encoding='utf-8')
dt_4 = dt_4.rename(columns={'Unnamed: 0':'Data'})
dt_4 = dt_4.set_index('Data')
del dt_4['2014 年.1']
del dt_4['2014 年.2']
del dt_4['2014 年.3']
del dt_4['2021 年.1']
dt_4.loc['华西证券'] = dt_4.loc['华西证券'].astype(float)
dt_5 = pd.read_csv('锦龙股份每股收益.csv',encoding='utf-8')
dt_5 = dt_5.rename(columns={'Unnamed: 0':'Data'})
dt_5 = dt_5.set_index('Data')
dt_5.loc['锦龙股份'] = dt_5.loc['锦龙股份'].astype(float)
dt_6 = pd.read_csv('经纬纺机每股收益.csv',encoding='utf-8')
dt_6 = dt_6.rename(columns={'Unnamed: 0':'Data'})
dt_6 = dt_6.set_index('Data')
dt_6.loc['经纬纺机'] = dt_6.loc['经纬纺机'].astype(float)
dt_7 = pd.read_csv('申万宏源每股收益.csv',encoding='utf-8')
dt_7 = dt_7.rename(columns={'Unnamed: 0':'Data'})
dt_7 = dt_7.set_index('Data')
dt_7.loc['申万宏源'] = dt_7.loc['申万宏源'].astype(float)
dt_8 = pd.read_csv('中油资本每股收益.csv',encoding='utf-8')
dt_8 = dt_8.rename(columns={'Unnamed: 0':'Data'})
dt_8 = dt_8.set_index('Data')
del dt_8['2021 年.1']
dt_8.loc['中油资本'] = dt_8.loc['中油资本'].astype(float)
dt_9 = pd.read_csv('东方财富每股收益.csv',encoding='utf-8')
dt_9 = dt_9.rename(columns={'Unnamed: 0':'Data'})
dt_9 = dt_9.set_index('Data')
dt_9.loc['东方财富'] = dt_9.loc['东方财富'].astype(float)
#绘制十家公司基本每股收益图
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('基本每股收益(元)',fontsize=30)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt_0.loc['东北证券'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('基本每股收益(元)',fontsize=14)
ax0.set_title('东北证券',fontsize=14)
 ax1 = fig.add_subplot(5,2,2)
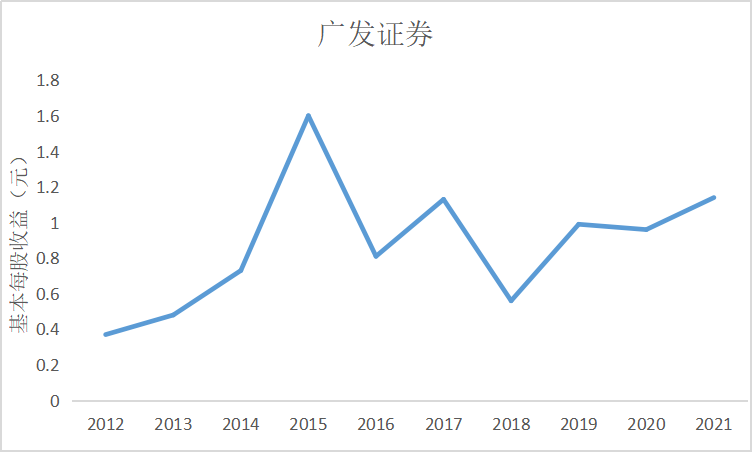
ax1.plot(dt_1.loc['广发证券'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('基本每股收益(元)',fontsize=14)
ax1.set_title('广发证券',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt_1.loc['广发证券'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('基本每股收益(元)',fontsize=14)
ax1.set_title('广发证券',fontsize=14)
 ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt_2.loc['国海证券'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('基本每股收益(元)',fontsize=14)
ax2.set_title('国海证券',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt_2.loc['国海证券'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('基本每股收益(元)',fontsize=14)
ax2.set_title('国海证券',fontsize=14)
 ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt_3.loc['国元证券'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('基本每股收益(元)',fontsize=14)
ax3.set_title('国元证券',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt_3.loc['国元证券'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('基本每股收益(元)',fontsize=14)
ax3.set_title('国元证券',fontsize=14)
 ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt_4.loc['华西证券'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('基本每股收益(元)',fontsize=14)
ax4.set_title('华西证券',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt_4.loc['华西证券'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('基本每股收益(元)',fontsize=14)
ax4.set_title('华西证券',fontsize=14)
 ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt_5.loc['锦龙股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('基本每股收益(元)',fontsize=14)
ax5.set_title('锦龙股份',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt_5.loc['锦龙股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('基本每股收益(元)',fontsize=14)
ax5.set_title('锦龙股份',fontsize=14)
 ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt_6.loc['经纬纺机'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('基本每股收益(元)',fontsize=14)
ax6.set_title('经纬纺机',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt_6.loc['经纬纺机'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('基本每股收益(元)',fontsize=14)
ax6.set_title('经纬纺机',fontsize=14)
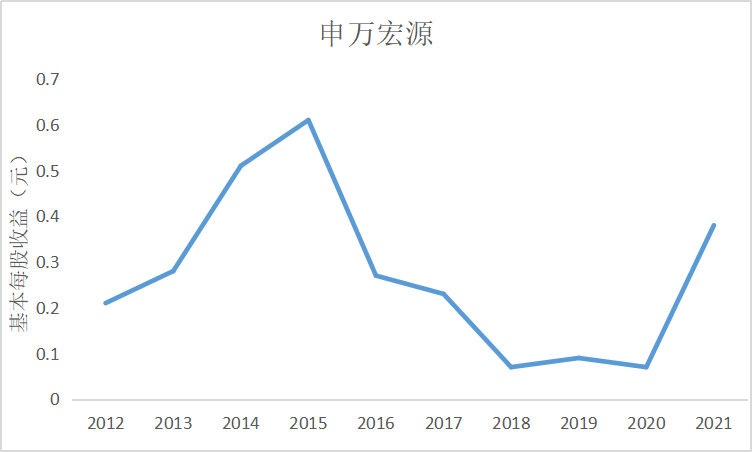
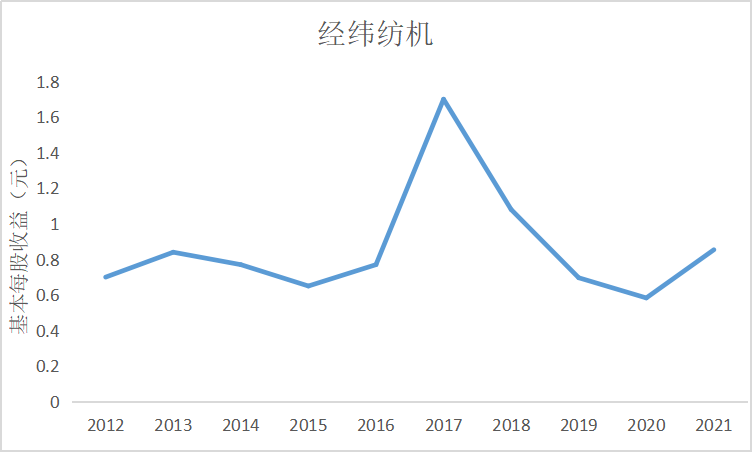 ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt_7.loc['申万宏源'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('基本每股收益(元)',fontsize=14)
ax7.set_title('申万宏源',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt_7.loc['申万宏源'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('基本每股收益(元)',fontsize=14)
ax7.set_title('申万宏源',fontsize=14)
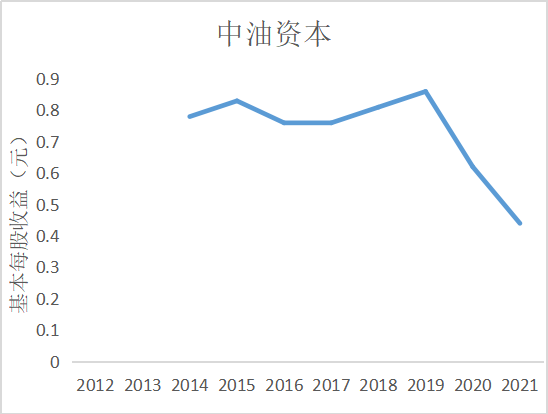
 ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt_8.loc['中油资本'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('基本每股收益(元)',fontsize=14)
ax8.set_title('中油资本',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt_8.loc['中油资本'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('基本每股收益(元)',fontsize=14)
ax8.set_title('中油资本',fontsize=14)
 ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt_9.loc['东方财富'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('基本每股收益(元)',fontsize=14)
ax9.set_title('东方财富',fontsize=14)
plt.show()
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt_9.loc['东方财富'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('基本每股收益(元)',fontsize=14)
ax9.set_title('东方财富',fontsize=14)
plt.show()
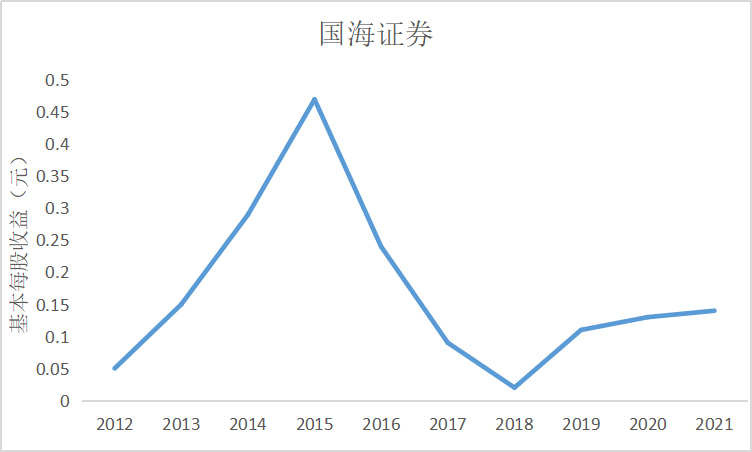
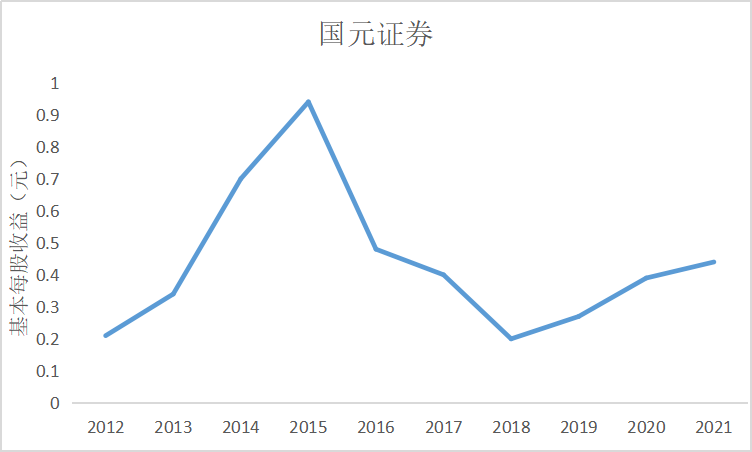
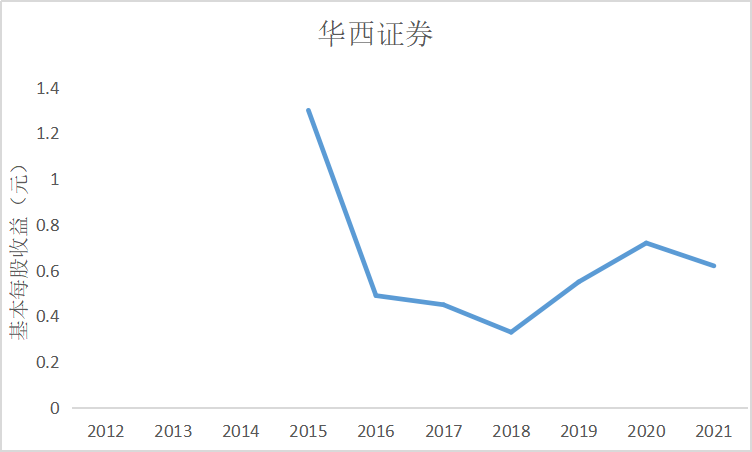
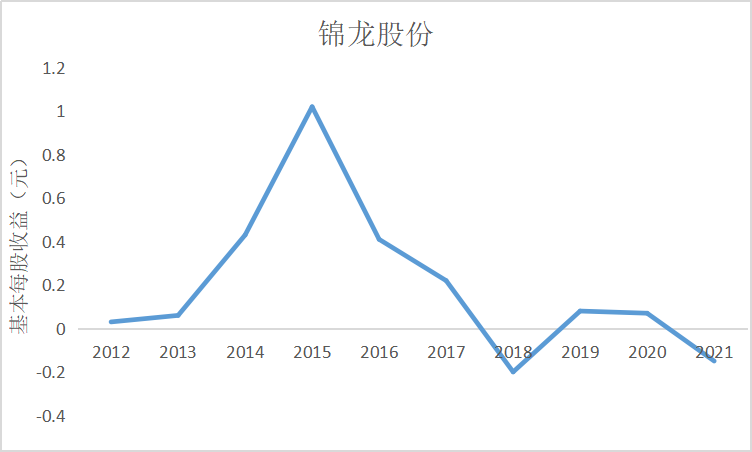
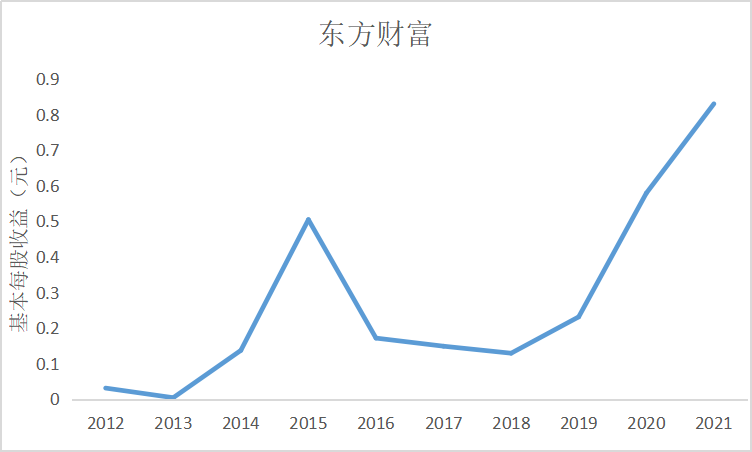 根据上图可知大部分证券公司基本每股收益都是正数,除了锦龙股份在2018和2021年间
出现了基本每股收益为负的情况,说明锦龙股份净利润为负,经营出现了亏损情况,投资者不
能从中获利。其中广发证券的基本每股收益较高,平均达到了每股1元的水平,说明公司经营情
况较好,分配给投资者的红利也较多。大多数证券公司基本每股收益水平都是在0.5左右上下波
动,随着市场行情变化比较明显。
#绘制对比图
import numpy as np
dt = pd.concat([dt0,dt1,dt2,dt3,dt4,dt5,dt6,dt7,dt8,dt9])
index_row = dt.index
index_columns = dt.columns
#利用pd.values.T对dataframe进行转置
dt = pd.DataFrame(dt.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt))
plt.bar(index,dt['东北证券'],width=0.05)
plt.bar(index+0.08,dt['广发证券'],width=0.08)
plt.bar(index+0.16,dt['国海证券'],width=0.08)
plt.bar(index+0.24,dt['国元证券'],width=0.08)
plt.bar(index+0.32,dt['华西证券'],width=0.08)
plt.bar(index+0.4,dt['锦龙股份'],width=0.08)
plt.bar(index+0.48,dt['经纬纺机'],width=0.08)
plt.bar(index+0.56,dt['申万宏源'],width=0.08)
plt.bar(index+0.64,dt['中油资本'],width=0.08)
plt.bar(index+0.72,dt['东方财富'],width=0.08)
plt.legend(['东北证券''广发证券''国海证券''国元证券''华西证券''锦龙股份'
'经纬纺机''申万宏源''中油资本''东方财富'])
plt.xticks(index+0.3,dt.index)
根据上图可知大部分证券公司基本每股收益都是正数,除了锦龙股份在2018和2021年间
出现了基本每股收益为负的情况,说明锦龙股份净利润为负,经营出现了亏损情况,投资者不
能从中获利。其中广发证券的基本每股收益较高,平均达到了每股1元的水平,说明公司经营情
况较好,分配给投资者的红利也较多。大多数证券公司基本每股收益水平都是在0.5左右上下波
动,随着市场行情变化比较明显。
#绘制对比图
import numpy as np
dt = pd.concat([dt0,dt1,dt2,dt3,dt4,dt5,dt6,dt7,dt8,dt9])
index_row = dt.index
index_columns = dt.columns
#利用pd.values.T对dataframe进行转置
dt = pd.DataFrame(dt.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt))
plt.bar(index,dt['东北证券'],width=0.05)
plt.bar(index+0.08,dt['广发证券'],width=0.08)
plt.bar(index+0.16,dt['国海证券'],width=0.08)
plt.bar(index+0.24,dt['国元证券'],width=0.08)
plt.bar(index+0.32,dt['华西证券'],width=0.08)
plt.bar(index+0.4,dt['锦龙股份'],width=0.08)
plt.bar(index+0.48,dt['经纬纺机'],width=0.08)
plt.bar(index+0.56,dt['申万宏源'],width=0.08)
plt.bar(index+0.64,dt['中油资本'],width=0.08)
plt.bar(index+0.72,dt['东方财富'],width=0.08)
plt.legend(['东北证券''广发证券''国海证券''国元证券''华西证券''锦龙股份'
'经纬纺机''申万宏源''中油资本''东方财富'])
plt.xticks(index+0.3,dt.index)
十家上市公司营业收入对比图
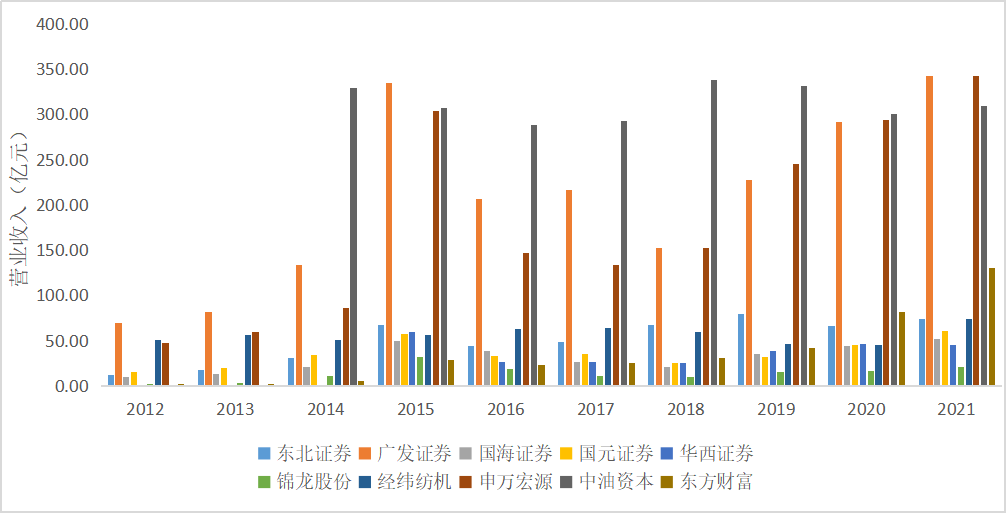 由上图可知,中油资本和广发证券年营收较多,经营状况良好。东方财富发展迅速,营业收入
近几年增长较快,整个证券公司市场行业有着较大的营业收入差距。
dt_ = pd.concat([dt_0,dt_1,dt_2,dt_3,dt_4,dt_5,dt_6,dt_7,dt_8,dt_9])
index_row = dt_.index
index_columns = dt_.columns
dt_ = pd.DataFrame(dt_.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt_))
plt.bar(index,dt_['东北证券'],width=0.08)
plt.bar(index+0.08,dt_['广发证券'],width=0.08)
plt.bar(index+0.16,dt_['国海证券'],width=0.08)
plt.bar(index+0.24,dt_['国元证券'],width=0.08)
plt.bar(index+0.32,dt_['华西证券'],width=0.08)
plt.bar(index+0.40,dt_['锦龙股份'],width=0.08)
plt.bar(index+0.48,dt_['经纬纺机'],width=0.08)
plt.bar(index+0.56,dt_['申万宏源'],width=0.08)
plt.bar(index+0.64,dt_['中油资本'],width=0.08)
plt.bar(index+0.72,dt_['东方财富'],width=0.08)
plt.legend(['东北证券''广发证券''国海证券''国元证券''华西证券''锦龙股份'
'经纬纺机''申万宏源''中油资本''东方财富'])
plt.xticks(index+0.3,dt_.index)
由上图可知,中油资本和广发证券年营收较多,经营状况良好。东方财富发展迅速,营业收入
近几年增长较快,整个证券公司市场行业有着较大的营业收入差距。
dt_ = pd.concat([dt_0,dt_1,dt_2,dt_3,dt_4,dt_5,dt_6,dt_7,dt_8,dt_9])
index_row = dt_.index
index_columns = dt_.columns
dt_ = pd.DataFrame(dt_.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt_))
plt.bar(index,dt_['东北证券'],width=0.08)
plt.bar(index+0.08,dt_['广发证券'],width=0.08)
plt.bar(index+0.16,dt_['国海证券'],width=0.08)
plt.bar(index+0.24,dt_['国元证券'],width=0.08)
plt.bar(index+0.32,dt_['华西证券'],width=0.08)
plt.bar(index+0.40,dt_['锦龙股份'],width=0.08)
plt.bar(index+0.48,dt_['经纬纺机'],width=0.08)
plt.bar(index+0.56,dt_['申万宏源'],width=0.08)
plt.bar(index+0.64,dt_['中油资本'],width=0.08)
plt.bar(index+0.72,dt_['东方财富'],width=0.08)
plt.legend(['东北证券''广发证券''国海证券''国元证券''华西证券''锦龙股份'
'经纬纺机''申万宏源''中油资本''东方财富'])
plt.xticks(index+0.3,dt_.index)
十家上市公司基本每股收益对比图
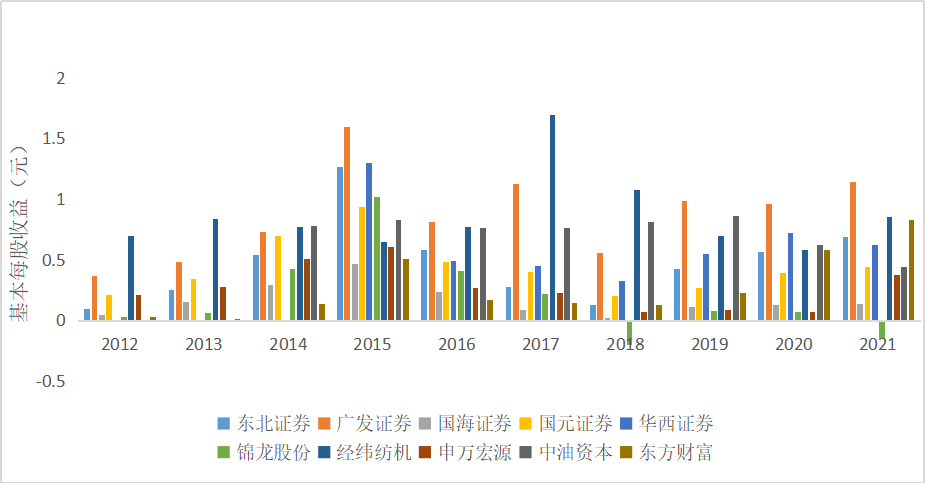 由上图可知,广发证券基本每股收益常年保持较高水平,为投资者带来了比较稳定且相比于其他证券公司
更多的收益。十家上市公司中平均基本每股收益维持在0.5左右,都较10年前呈现着较大上涨幅度。
由上图可知,广发证券基本每股收益常年保持较高水平,为投资者带来了比较稳定且相比于其他证券公司
更多的收益。十家上市公司中平均基本每股收益维持在0.5左右,都较10年前呈现着较大上涨幅度。