陈智诚的实验报告
代码
一、通过行业分类结果找到行业所属上市公司
import fitz
import re
import requests
import numpy as np
import pandas as pd
doc = fitz.open('行业分类.pdf')
txt = doc[84].get_text()
p1 = re.compile('(?<=\n)邮政业\n(.*)(?=住宿)',re.DOTALL)
a=p1.findall(txt)
print(a)
p2 = re.compile('(?:(\d+)\n(\w+)\n){1}')
b=p2.findall(a[0])
df = pd.DataFrame({'证券代码': [b[0] for b in b],
'简称': [b[1] for b in b]})
二、找到年报下载链接并下载
(一)寻找年报下载链接
1.深交所
#利用seleniumIDE爬取网页代码(此处若公司较多可以用循环,处理上交所时运用了循环)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
browser.find_element(By.ID, "input_code").click()
browser.find_element(By.ID, "input_code").send_keys("顺丰")
browser.find_element(By.CSS_SELECTOR,
".active:nth-child(1) > a").click()
browser.find_element(By.ID, "input_code").click()
browser.find_element(By.ID, "input_code").send_keys("韵达")
browser.find_element(By.CSS_SELECTOR,
".active:nth-child(1) > a").click()
browser.find_element(By.ID, "input_code").click()
browser.find_element(By.ID, "input_code").send_keys("申通")
browser.find_element(By.CSS_SELECTOR,
".active:nth-child(1) > a").click()
browser.find_element(By.CSS_SELECTOR,
"#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
browser.find_element(By.CSS_SELECTOR, ".input-left").click()
browser.find_element(By.CSS_SELECTOR,
"#c-datepicker-menu-1 .calendar-year span").click()
browser.find_element(By.CSS_SELECTOR,
".active li:nth-child(118)").click()
browser.find_element(By.CSS_SELECTOR,
"#c-datepicker-menu-1 .calendar-month span").click()
browser.find_element(By.CSS_SELECTOR,
".active > .dropdown-menu li:nth-child(1)").click()
browser.find_element(By.CSS_SELECTOR,
"#c-datepicker-menu-1 tr:
nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
browser.find_element(By.CSS_SELECTOR, ".today > .tdcontainer").click()
browser.find_element(By.ID, "query-btn").click()
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()
#利用老师给的代码提取下载链接等数据
import re
import pandas as pd
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv('data.csv')
#筛选年报下载链接
import re
import pandas as pd
df = pd.read_csv('data.csv',header=0,index_col=0)
df['f_name']=df.iloc[:,1]+df.iloc[:,2]
df=df[['f_name','attachpath','简称']]
def filter_links(words,df,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df.f_name])
else:
ls.append([word not in f for f in df.f_name])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
df_all = filter_links(['摘要','问询函','社会责任','取消','英文'],
df,include=False)
#将不同公司的年报下载链接写入不同的文件中,并以公司名称命名
company=[]
for i in df_all['简称']:
if i not in company:
df_all[df_all['简称']==i].to_csv(i+'.csv')
company.append(i)
2.上交所
#利用seleniumIDE爬取网页代码(此处使用循环)
hangye = pd.read_csv('邮政业.csv')
n = len(hangye['证券代码'])
for i in range(0,n):
if hangye['证券代码'][i]>400000:
browser.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID,
"inputCode").send_keys(hangye['简称'][i][0:2])
browser.find_element(By.ID, hangye['证券代码'][i]).click()
browser.find_element(By.CSS_SELECTOR,
".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
browser.find_element(By.XPATH, "//option[. = '年报']").click()
element = browser.find_element_by_class_name("table-hover")
innerHTML1 = element.get_attribute('innerHTML')
f = open('innerHTML1.html','w',encoding='utf-8')
f.write(innerHTML1)
f.close()
browser.quit()
p1 = re.compile('(\d+)')
code = p1.findall(innerHTML1)获取股票代码
p2 = re.compile('(\d+.*?)')
title = p2.findall(innerHTML1)#获取年报名称
p3 = re.compile('href="(.*?)" target=')
href = p3.findall(innerHTML1)
n = len(href)
for i in range(0,n):
href[i] ='http://www.sse.com.cn'+href[i]#获取下载链接并加上前缀
df = pd.DataFrame({'证券代码': code,
'f_name': title,
'attachpath': href})#生成数据框
df = filter_links(['摘要','问询函','社会责任','取消','英文','专项',
'报告书',hangye['简称'][i][0:2]],df,include=False)
#筛选年报链接,注意此处的
df.to_csv(hangye['简称'][i]+'.csv')#保存数据
(二)下载年报
for i in df_all['简称']:
if i not in company:
df_all[df_all['简称']==i].to_csv(i+'.csv')
company.append(i)
for i in company:
df=pd.read_csv(i+'.csv',header=0)
n=len(df['attachpath'])
for j in range(0,n):
href=df['attachpath'][j]
r = requests.get(href, allow_redirects=True)
f = open(df['f_name'][j]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
三、提取数据
#由于申通快递2021年年度报告数据格式与其他数据不同,因此对它单独提取
import re
import pdfplumber
with pdfplumber.open("申通快递2021年年度报告.pdf") as pdf:
page = pdf.pages[9]
txt = page.extract_text()
p_pe = re.compile('(?<=\n)基本每股收益\s?\n?
(?:(元/?/?╱?\n?股))?\s?\n?([-\d+,.]*)\s?\n?',re.DOTALL)
st_eps=p_pe.findall(txt)
p_sales = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?',re.DOTALL)
st_sales=p_sales.findall(txt)
#提取营业收入和基本每股收益数据
year_list=[]
sales_list=[]
pe_list=[]
sales.append(st_sales)
pe_list.append(st_eps)
for j in df1['简称']:
com=pd.read_csv(j+'.csv',header=0,index_col=0)
for k in com['f_name']:
p_year = re.compile('\d{4}')
year = p_year.findall(k)
year1 = int(year[0])
year_list.append(year1)
doc = fitz.open(k+'.pdf')
for i in range(20):
page = doc[i]
txt =page.get_text()
p_sales = re.compile('(?<=\n)营业总?收入
(?\w?)?\s?\n?([\d+,.]*)\s\n?')
a=p_sales.findall(txt)
if a !=[]:
c=len(a[0])
if c>0:
sales = re.sub(',','',a[0])
sales_list.append(sales)
break
for i in range(20):
page = doc[i]
txt =page.get_text()
p_pe = re.compile('(?<=\n)基本每股收益\s?\n?
(?:(元/?/?╱?\n?股))?\s?\n?([-\d+,.]*)\s?\n?')
b = p_pe.findall(txt)
if b !=[]:
d=len(b[0])
if d>0 and ',' not in b[0]:
pe_list.append(b[0])
list1.append(k)
break
sales_list = [ float(x) for x in sales_list ]
pe_list = [ float(x) for x in pe_list ]
dff=pd.DataFrame({'年份':year_list,
'营业收入(元)':sales_list,
'基本每股收益(元/股)':pe_list})
dff.to_csv(j+'data.csv',encoding='utf-8-sig')
year_list=[]
sales_list=[]
pe_list=[]
#提取办公地址和办公网址
add_list=[]
web_list=[]
for i in df1['简称']:
doc = fitz.open(i+'2017年年度报告.pdf')
for j in range(15):
page = doc[j]
txt = page.get_text()
p_add = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
com_add=p_add.findall(txt)
if com_add !=[]:
n = len(com_add[0])
if n >1:
add_list.append(com_add[0])
break
for j in range(15):
page = doc[j]
txt = page.get_text()
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-z-A-Z./:]*)\s?(?=\n)',re.DOTALL)
com_web=p_web.findall(txt)
if com_web !=[]:
n = len(com_web[0])
if n >1:
web_list.append(com_web[0])
list1.append(i)
break
df1['办公地址'] = add_list
df1['公司网址'] = web_list
df1.to_csv('公司基本信息.csv')
四、画图
#将所有公司的营业收入和基本每股收益分别合并
df_sale = pd.DataFrame()
df_eps = pd.DataFrame()
for j in df1['简称']:
df = pd.read_csv(j+'data.csv',index_col=1,header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed',case=False)],axis=1)
df_sales = pd.DataFrame(df['营业收入(元)'])
df_sales = df_sales.rename(columns={'营业收入(元)':j})
df_sale = pd.concat([df_sale,df_sales],axis=1)
for j in df1['简称']:
df = pd.read_csv(j+'data.csv',index_col=1,header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed',case=False)],axis=1)
df_epss = pd.DataFrame(df['基本每股收益(元/股)'])
df_epss = df_epss.rename(columns={'基本每股收益(元/股)':j})
df_eps = pd.concat([df_eps,df_epss],axis=1)
#行业上市公司营业收入时间序列图
from matplotlib import pyplot as plt
plt.plot(df_sale,marker='*')
plt.legend(df_sale.columns)
plt.title('邮政业上市公司营业收入时间序列图')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.grid()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.un
icode_minus']=False
#行业上市公司基本每股收益时间序列图
plt.plot(df_eps,marker='*')
plt.legend(df_eps.columns)
plt.title('邮政业上市公司基本每股收益时间序列图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid()
#行业内上市公司营业收入对比时间序列图
from matplotlib import pyplot as plt
bar_width = 0.2
bar_1 = np.arange(len(df_sale.index))
plt.bar(bar_1-2*bar_width, df_sale.iloc[:,0], width=bar_width, label=df_sale.columns[0])
plt.bar(bar_1-bar_width, df_sale.iloc[:,1], width=bar_width, label=df_sale.columns[1])
plt.bar(bar_1, df_sale.iloc[:,2], width=bar_width, label=df_sale.columns[2])
plt.bar(bar_1+bar_width, df_sale.iloc[:,3], width=bar_width, label=df_sale.columns[3])
plt.bar(bar_1+2*bar_width, df_sale.iloc[:,4], width=bar_width, label=df_sale.columns[4])
plt.xticks(bar_1, labels=df_sale.index)
plt.title('邮政业上市公司营业收入对比时间序列图')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.grid()
plt.legend()
#行业内上市公司基本每股收益对比时间序列图
bar_1 = np.arange(len(df_eps.index))
bar_width = 0.15
plt.bar(bar_1-2*bar_width, df_eps.iloc[:,0], width=bar_width, label=df_eps.columns[0])
plt.bar(bar_1-bar_width, df_eps.iloc[:,1], width=bar_width, label=df_eps.columns[1])
plt.bar(bar_1, df_eps.iloc[:,2], width=bar_width, label=df_eps.columns[2])
plt.bar(bar_1+bar_width, df_eps.iloc[:,3], width=bar_width, label=df_eps.columns[3])
plt.bar(bar_1+2*bar_width, df_eps.iloc[:,4], width=bar_width, label=df_eps.columns[4])
plt.xticks(bar_1, labels=df_eps.index)
plt.title('邮政业上市公司基本每股收益对比时间序列图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid()
plt.legend()
绘图
部分代码运行结果
1.年报下载链接分类
 2.年报批量下载
2.年报批量下载
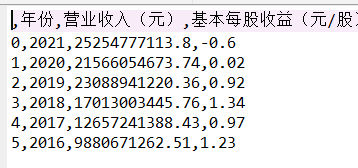
 2.公司营业收入与基本每股收益
2.公司营业收入与基本每股收益

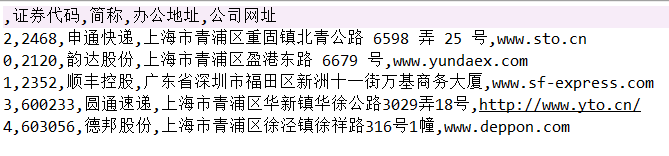
 3.公司股票代码等基本信息
3.公司股票代码等基本信息
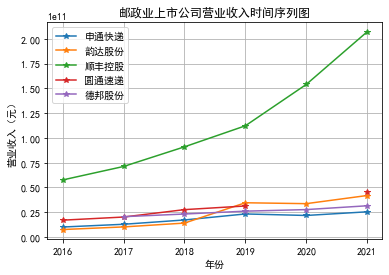
 4.公司营业收入与基本每股收益
4.公司营业收入与基本每股收益
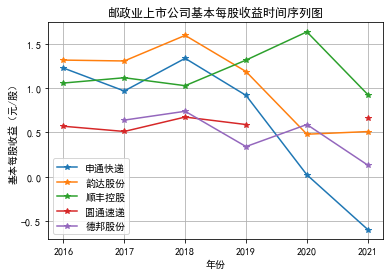
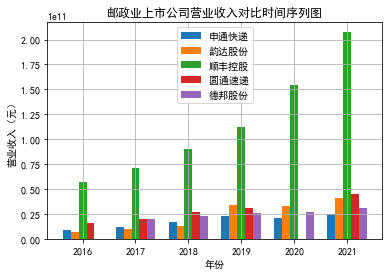
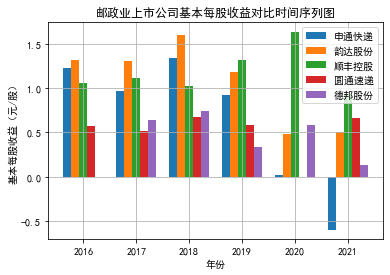
解读
- 行业总体解读
邮政行业上市公司平均营业收入都比较高,每年都保持在百亿以上,
并且该行业营业收入总体呈现出上涨的趋势,在上市后的几年里,
营业收入都实现了翻倍,部分公司甚至翻了四倍,但是与此同时每股净收益下降,
这可能是由于上市之后股权融资加大导致的每股收益下降,
以及近年来运力成本,商品成本、服务成本等上升,
导致净利润增速慢于股票发行量增速。该行业还有一个特点,
龙头企业的营业收入增长速度明显高于其他企业。
- 行业内部解读
行业内部,顺丰控股的营业收入明显高于同业其他上市公司,
以及增长速度也明显高于同行业其他公司。在客户满意度方面,
根据国家邮政局发布的调查显示,
顺丰公司行业满意度排名多年连续第一。该满意度包含22个指标,
涵盖快递服务的受理、揽收、寄运、售后及信息服务五大方面。
在运输速度指标上全程时限和72小时准点率的排名也稳居第一。
从调查结果表明,即使顺丰公司定价高于其他同类企业,
但其以时效快、服务优、网络全打造的竞争优势,
提供了多元的物流服务,使客户对其整体的服务依然保持很高的评价与品牌忠诚度,
并且愿意为优质的服务支付更高的费用,这对企业收入的增加提供稳固保障,
有利于公司盈利能力的提升。在创新能力方面,近几年,顺丰公司加大了大数据、
人工智能、智慧地图、自动化设备、智慧办公、专业服务方案等方面的科技研发投入。
科技创新为顺丰公司经营带来了变革性影响,一方面通过智慧设备的规划、自助化分拣等新技术提高了末端分拣、运送等服务效率,降低人工成本;另一方面科技可以运用到冷运、国际、供应链等新业务体系中,带来更多的客户资源,增加收益。