马振威的期末报告
代码
首先从行业分类表中爬取装卸搬运和运输代理业,爬取对应代码
下载作业报告里的pdf保存为行业分类,方便后续使用
import fitz
import re
import pandas as pd
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from parse_cninfo_table import *
os.chdir(r'C:\Users\dell\Desktop\python期末实验报告')
#Step1 提取对应行业股票代码
pdf1 = fitz.open('行业分类.pdf')
text = ''
for page in pdf1:
text += page.get_text()
p1 = re.compile('\n58\n(.*?)\n59', re.DOTALL)
text_ind = re.findall(p1, text)
p2 = re.compile('.*?\n(\d{6})\n.*?')
code = re.findall(p2, text_ind[0])
结果
#Step2 下载年报
browser = webdriver.Edge() #使用Edge浏览器
browser.maximize_window()
def get_cninfo(code): #爬取巨潮网年报信息
browser.get('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&checkedCategory=category_ndbg_szsh')
browser.find_element(By.CSS_SELECTOR, ".el-autocomplete > .el-input--medium > .el-input__inner").send_keys(code)
time.sleep(1)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.DOWN)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.ENTER)
time.sleep(0.1)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").click()
time.sleep(0.5)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").clear()
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys("2013-01-01")
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys(Keys.ENTER)
time.sleep(0.1)
browser.find_element(By.CSS_SELECTOR, ".query-btn").click()
time.sleep(1)
element = browser.find_element(By.CLASS_NAME, 'el-table__body')
innerHTML = element.get_attribute('innerHTML')
return innerHTML
def html_to_df(innerHTML): #转换为Dataframe
f = open('innerHTML.html','w',encoding='utf-8') #创建html文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
return df
df = pd.DataFrame()
for i in code:
innerHTML = get_cninfo(i)
time.sleep(0.1)
df = df.append(html_to_df(innerHTML))
time.sleep(0.1)
#df.to_csv('list.csv')
def filter_links(words,df0,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df0['公告标题']])
else:
ls.append([word not in f for f in df0['公告标题']])
index = []
for r in range(len(df0)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df1 = df0[index]
return(df1)
words1 = ["摘要","已取消"]
list = filter_links(words1,df,include=False) #去除摘要和已取消的报告
fun1 = lambda x: re.sub('(?<=报告).*', '', x)
fun2 = lambda x: re.sub('.*(?=\d{4})', '', x)
fun3 = lambda x: re.sub('.*(?=\d{4})', '', x)
list['公告标题'] = list['公告标题'].apply(fun1) #去除“20xx年度报告”前后内容
list['公告标题'] = list['公告标题'].apply(fun2)
list = list.drop_duplicates(['证券代码','公告标题'], keep='first') #删去重复值,保留最新一项
'''
#检查结果
for codes in code:
if len(list[list['证券代码']==codes])>10:
print(codes)
'''
list['公告标题'] = list['简称']+list['公告标题']
os.chdir(r'C:\Users\dell\Desktop\python期末实验报告\files')
def get_pdf(r): #构建下载巨潮网报告pdf函数
p_id = re.compile('.*var announcementId = "(.*)";.*var announcementTime = "(.*?)"',re.DOTALL)
contents = r.text
a_id = re.findall(p_id, contents)
new_url = "http://static.cninfo.com.cn/finalpage/" + a_id[0][1] + '/' + a_id[0][0] + ".PDF"
result = requests.get(new_url, allow_redirects=True)
time.sleep(1)
return result
for c in code:
rpts = list[list['证券代码']==c]
for row in range(len(rpts)):
r = requests.get(rpts.iloc[row,3], allow_redirects=True)
time.sleep(0.3)
try:
result = get_pdf(r)
f = open(rpts.iloc[row,2]+'.PDF', 'wb')
f.write(result.content)
f.close()
r.close()
except:
print(rpts.iloc[row,2])
pass
结果

 由于年报是分散下载的,故而手动将年报按照股票代码进行文件夹分类,结果如图
由于年报是分散下载的,故而手动将年报按照股票代码进行文件夹分类,结果如图
结果
#Step3 解析年报数据
def get_adata(rpt): #构建获取营业收入和每股收益数据的函数
#rpt = fitz.open('密尔克卫2021年年度报告.PDF')
text = ''
for page in rpt:
text += page.get_text()
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)稀', re.DOTALL)
txt = p_s.search(text).group(0) #匹配对应内容
p1 = re.compile('营(.*?)归',re.DOTALL) #匹配年报中3年的营业收入
data = p1.search(txt).group()
data = data.replace('\n', '') #替换掉换行符
p_digit = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字到小数点后2位
turnover = p_digit.search(data).group()
turnover = turnover.replace(',','') #去掉逗号
p2 = re.compile('基(.*?)稀',re.DOTALL) #匹配年报中3年的基本每股收益
data = p2.search(txt).group()
data = data.replace('\n', '')
pe = p_digit.search(data).group()
return turnover,pe
def get_bdata(rpt):
text = ''
for page in rpt:
text += page.get_text()
p1 = re.compile('(?<=\\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\\n)', re.DOTALL)
infom1 = p1.findall(text)[0]
p2 = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
infom2 = p2.findall(text)[0]
return infom1,infom2
#获取营业收入和每股收益数据
turnovers = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
pes = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
turnovers.loc[i,'公司'] = firm.iloc[0,1]
pes.loc[i,'公司'] = firm.iloc[0,1]
for item in range(len(firm)):
rpt = fitz.open(firm.iloc[item,2]+'.PDF')
turnover, pe = get_adata(rpt)
turnovers[int(firm.iloc[item,-1])][i] = turnover
pes[int(firm.iloc[item,-1])][i] = pe
print(firm.iloc[item,2]+'解析出错')
在这一步中,我st安通控股的2020年和2019年年度报告显示出错,于是我去巨潮网和上交所重新下载了
这个公司这两年的年度报告,移入到了我的files文件夹里,重新运行后还是错误,于是我思考许久,
发现是文件下载出了问题,2020年和2019年的安通控股年报最前面有*号,这在我的电脑文件命名中是
创立的,也是我几天琢磨后仍然无法解决的,这就导致我安通控股的公司年报少了2019年和2020年这
两年的数据
结果

#Step3 解析年报数据
def get_adata(rpt): #构建获取营业收入和每股收益数据的函数
#rpt = fitz.open('密尔克卫2021年年度报告.PDF')
text = ''
for page in rpt:
text += page.get_text()
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)稀', re.DOTALL)
txt = p_s.search(text).group(0) #匹配对应内容
p1 = re.compile('营(.*?)归',re.DOTALL) #匹配年报中3年的营业收入
data = p1.search(txt).group()
data = data.replace('\n', '') #替换掉换行符
p_digit = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字到小数点后2位
turnover = p_digit.search(data).group()
turnover = turnover.replace(',','') #去掉逗号
p2 = re.compile('基(.*?)稀',re.DOTALL) #匹配年报中3年的基本每股收益
data = p2.search(txt).group()
data = data.replace('\n', '')
pe = p_digit.search(data).group()
return turnover,pe
def get_bdata(rpt):
text = ''
for page in rpt:
text += page.get_text()
p1 = re.compile('(?<=\\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\\n)', re.DOTALL)
infom1 = p1.findall(text)[0]
p2 = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
infom2 = p2.findall(text)[0]
return infom1,infom2
#获取营业收入和每股收益数据
turnovers = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
pes = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
turnovers.loc[i,'公司'] = firm.iloc[0,1]
pes.loc[i,'公司'] = firm.iloc[0,1]
for item in range(len(firm)):
rpt = fitz.open(firm.iloc[item,2]+'.PDF')
turnover, pe = get_adata(rpt)
turnovers[int(firm.iloc[item,-1])][i] = turnover
pes[int(firm.iloc[item,-1])][i] = pe
print(firm.iloc[item,2]+'解析出错')
turnovers_n = turnovers.iloc[:,1:].astype('float')
turnovers_n.index = turnovers['公司']
turnovers_n.to_csv('营业收入汇总.csv')
pes_n = pes.iloc[:,1:].astype('float')
pes_n.index = pes['公司']
pes_n.to_csv('每股收益汇总.csv')
#获取公司信息
firm = list[list['证券代码']==code[0]]
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info = pd.DataFrame(columns=['股票代码', '股票简称', '办公地址', '公司网址'])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
try:
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info1,info2 = get_bdata(rpt)
info.loc[i,'股票代码'] = firm.iloc[0,0]
info.loc[i,'股票简称'] = firm.iloc[0,1]
info.loc[i,'办公地址'] = info1
info.loc[i,'公司网址'] = info2
except:
print(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'解析出错')
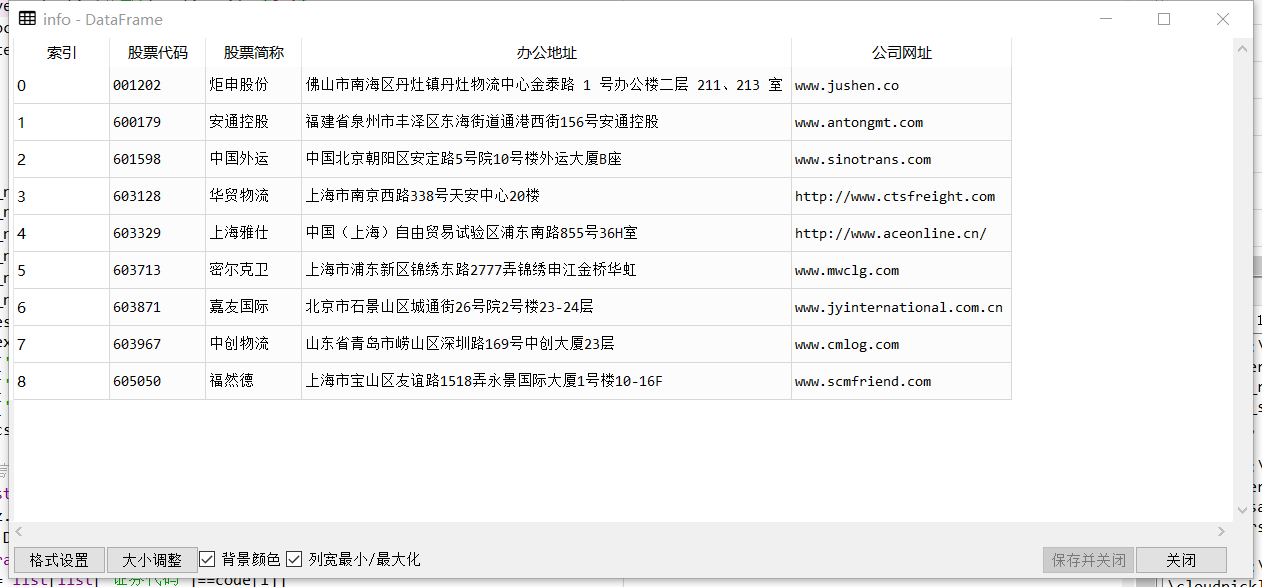
info.to_csv('公司信息.csv')
将其导出为csv以方便后期制图,excel表也如下图所示
如图

#Step4 绘制图表并分析
#绘制营业收入变化趋势图表
plt.rcParams['font.sans-serif']=['SimHei'] #确保显示中文
plt.rcParams['axes.unicode_minus'] = False #确保显示负数的参数设置
chart1 = turnovers_n
chart1['公司简称'] = turnovers_n.index
chart1.index = [i for i in range(len(chart1))]
chart1 = chart1.dropna()
chart1['mean'] = chart1.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
chart1 = chart1.sort_values('mean', ascending=False)[:10]
chart1.iloc[:,:10] = chart1.iloc[:,:10]/100000000
i = 9
plt.plot(chart1.columns[:10], chart1.iloc[i,:10], marker='o')
plt.xticks(np.linspace(2012,2021,10))
plt.xlabel('年份',fontsize=13)
plt.ylabel('营业收入(亿元)',fontsize=11)
plt.title(chart1.iloc[i,10]+"营业收入折线图",fontsize=14)
plt.show()
#绘制每股收益变化趋势图表
chart2 = pes_n
chart2['公司简称'] = pes_n.index
chart2.index = [i for i in range(len(chart2))]
chart2 = chart2.dropna()
chart2['mean'] = chart2.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
chart2 = chart2.sort_values('mean', ascending=False)[:10]
#绘制逐年营业收入和每股收益图表
year = 2012
item = pd.concat([turnovers_n[year], turnovers_n['公司简称']], axis=1)
item[year] = item[year]/100000000
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.5,bottom=2.0,)
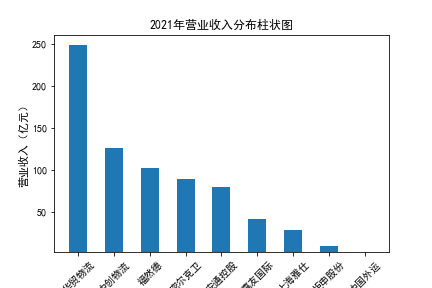
plt.title(str(year)+'年营业收入分布柱状图')
plt.ylabel('营业收入(亿元)',fontsize=11)
plt.xticks(rotation=45)
plt.show()
year = 2012
item = pd.concat([turnovers_n[year], turnovers_n['公司简称']], axis=1)
item[year] = item[year]/100000000
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.5,bottom=2.0,)
plt.title(str(year)+'年营业收入分布柱状图')
plt.ylabel('基本每股收益',fontsize=11)
plt.xticks(rotation=45)
plt.show()
因为我只有九家公司,且好几家公司只有不到三年,所以我只罗列三年以上的,安通控股会少2020和2019年
的数据,我在上述中解释到是文件下载的问题,与代码应该无关,*号的问题我还是无法解决
营业收入
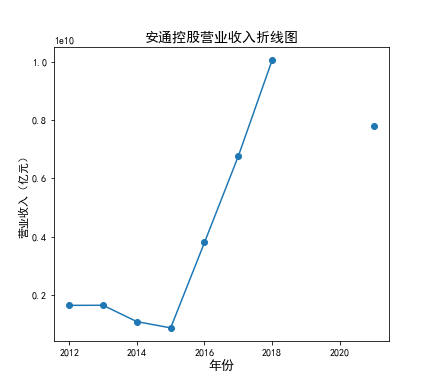
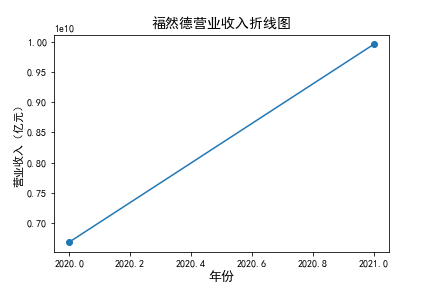
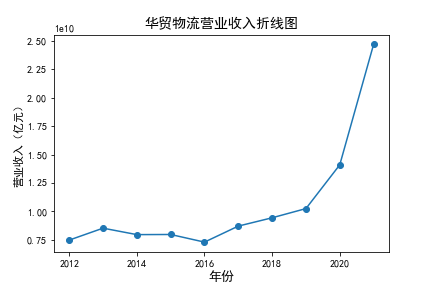
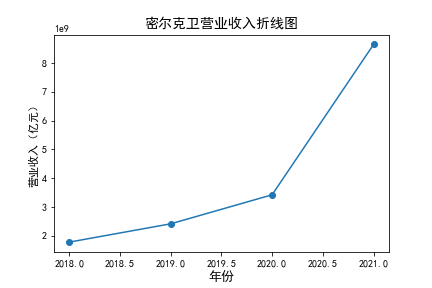
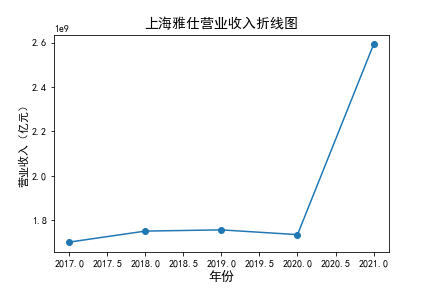
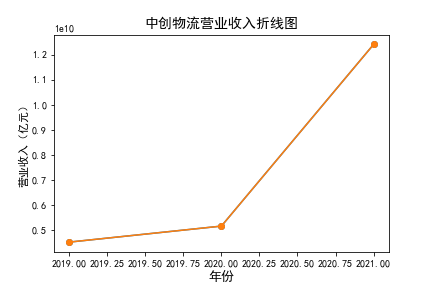
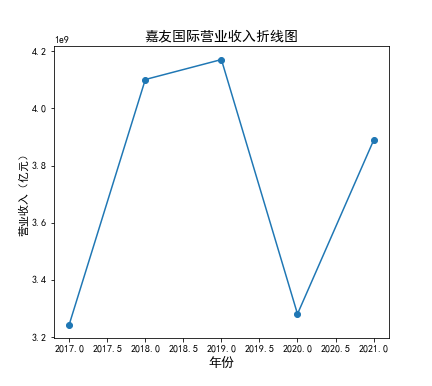 在我的九家公司中,2017年之前好几家公司没有报表,故没有营业收入,所以我从2017年开始展示
在我的九家公司中,2017年之前好几家公司没有报表,故没有营业收入,所以我从2017年开始展示
营业收入
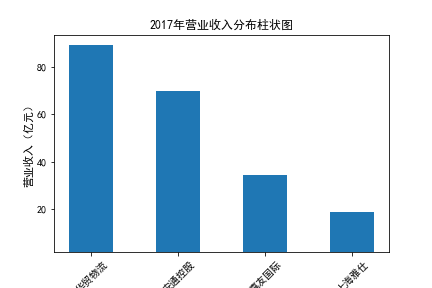
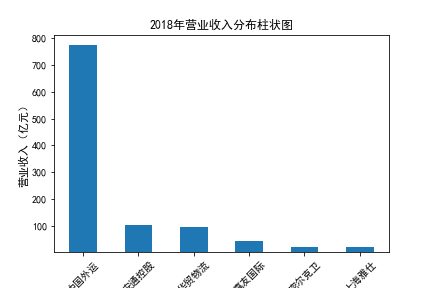
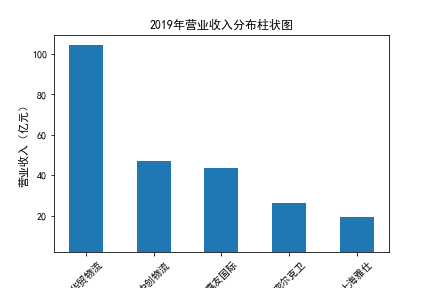
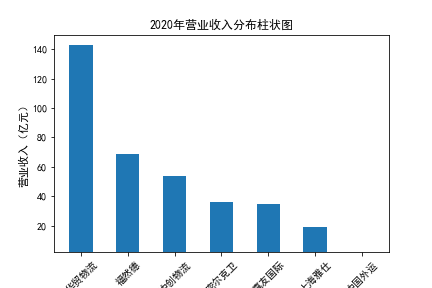
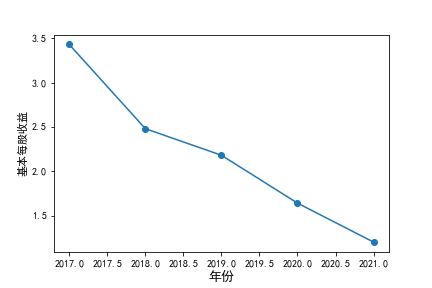
 在我的九家公司中,2017年之前好几家公司没有报表,故没有每股收益,所以我从2017年开始展示
在我的九家公司中,2017年之前好几家公司没有报表,故没有每股收益,所以我从2017年开始展示
基本每股收益
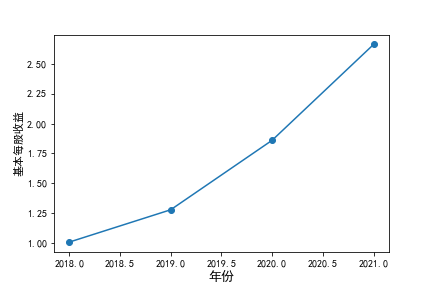
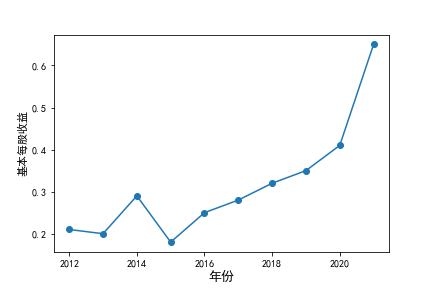
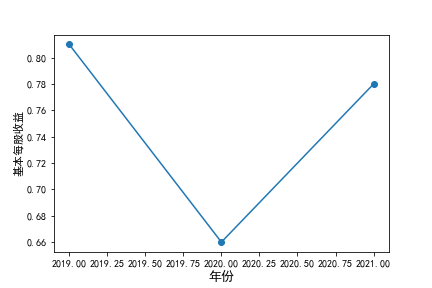
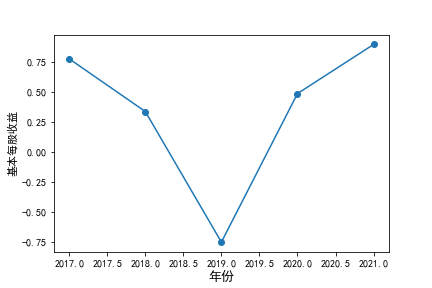
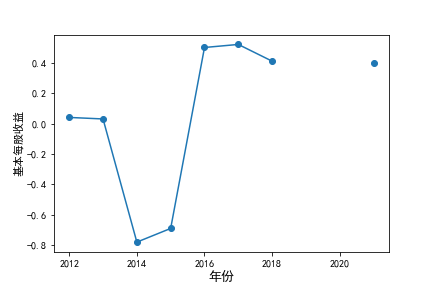
装卸搬运和运输代理业解读
在我的这9家公司中,只有华贸物流和安通控股有10年的年报,经过营业收入图和每股利润图可以看出,该行业
收到新冠疫情的影响并不大,其中大部分公司在进两年每股收益率和营业收入不降反增,说明在疫情期间国家对
该行业也是非常需要的,尤其是运输业,在疫情期间需要其积极运输救援物资。
近10年来,整体呈现上升趋势,近年来,随着国内众多集货运服务,生产服务,商贸服务和综合服务为一体的
综合物流园区相继建立,我国仓储,配送设施现代化水平不断提高,物流网络建设的不断完善,为物流行业的发展
扫除了障碍,有利于物流企业平稳,快速增长