from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import re
import pandas as pd
import time
browser = webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe')
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
# 通过id属性来选择元素
element = browser.find_element(By.ID, 'input_code')
element.send_keys('深圳机场' + Keys.RETURN)
element = browser.find_element(By.ID, 'disclosure-table')
time.sleep(2)
# 获取元素内部的html文本内容
innerHTML = element.get_attribute('innerHTML')
f = open('auto-000089disclosure-table.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()
# 定义一个函数,对所抓取的html内容进行解析
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('auto-000089disclosure-table.html')
# 定义一个函数,对html文本内容进行选择性提取,并转换为DataFrame
def txt_to_df(html):
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
# 利用正则表达式匹配想要的信息
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data(df_txt)
df_data.to_csv('auto_data_from_000089szjc.csv')
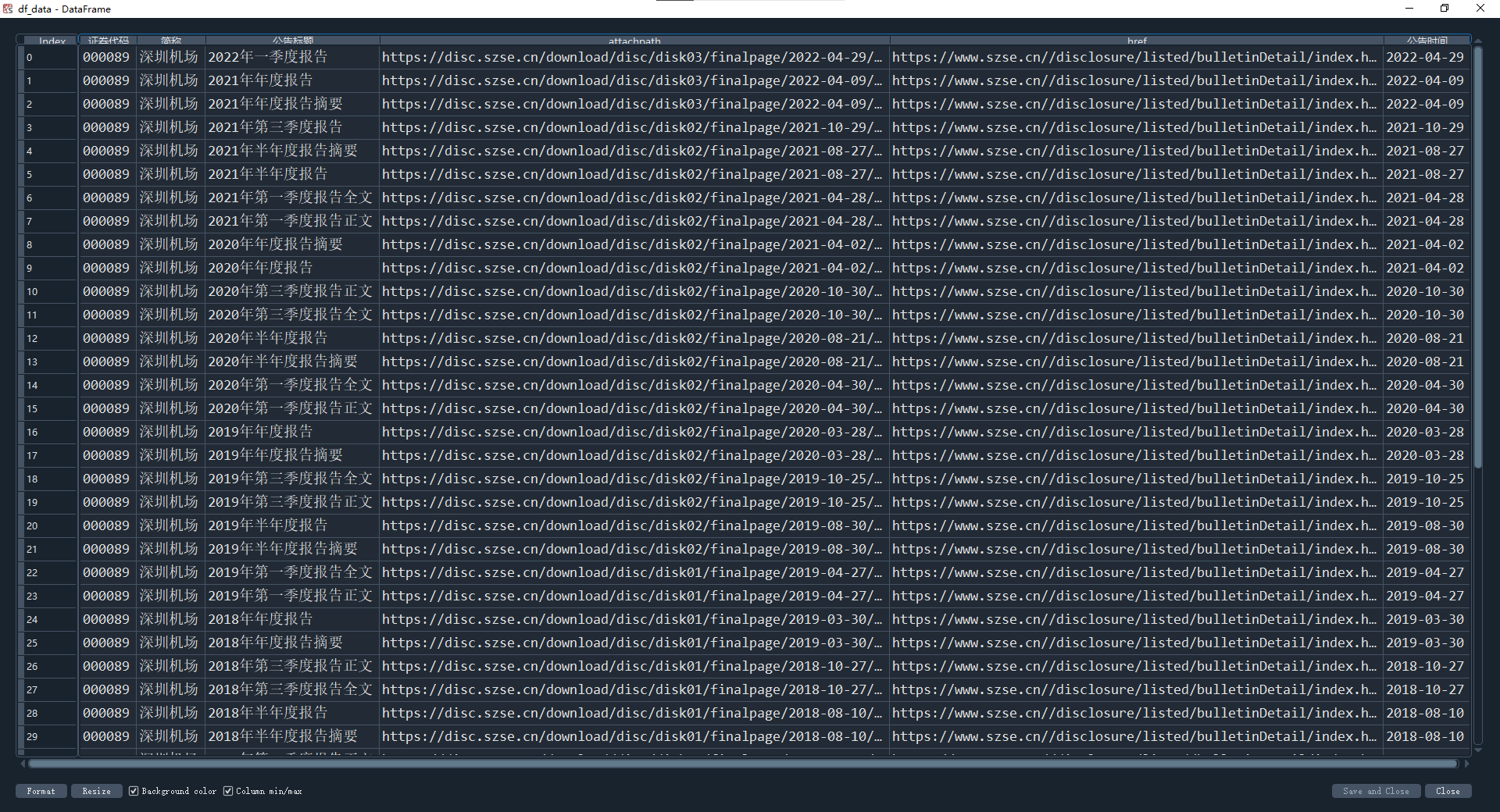
见代码注释