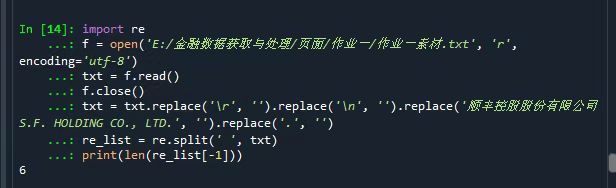
import re
#引入re库
f = open('E:/金融数据获取与处理/页面/作业一/作业一素材.txt', 'r', encoding='utf-8')
#打开文件,“r”是可读模式,以utf-8格式来读取文件
txt = f.read()
#逐字读取文件,存入txt
f.close()
#关闭文件
txt = txt.replace('\r', '').replace('\n', '').replace('顺丰控股股份有限公司S.F. HOLDING CO., LTD.', '').replace('.', '')
#将列表中的'\r'、'\n'、'顺丰控股股份有限公司S.F. HOLDING CO., LTD.'和'.'删除
re_list = re.split(' ', txt)
#调用re库中的split函数,将读取的文件txt按照" "划分,划分后的字段存入re_list列表
print(len(re_list[-1]))
#调用len函数计算最后一个单词的长度,并输出
如果所写代码复杂,且没有良好的注释,那么请在这里补充解释。