import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
import re
import requests
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup
browser = webdriver.Edge()
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code')
element.send_keys('深粮控股' + Keys.RETURN)
baogao=browser.find_element(By.CSS_SELECTOR,'#select_gonggao > div > div > a > span.c-selectex-btn-text')
nianbao=browser.find_element(By.CSS_SELECTOR,'#c-selectex-menus-3 > li:nth-child(1) > a')
baogao.click()
nianbao.click()
begin.send_keys('2013-01-01'+Keys.RETURN)
end.send_keys('2022-12-31'+Keys.RETURN)
time.sleep(2)
trs=[]
for r in range(5):
time.sleep(2)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml')
html_prettified = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
tr = p.findall(html_prettified)
trs.extend(tr)
flag = element_exist(browser,'下一页')
if flag:
nextpage = browser.find_element(By.PARTIAL_LINK_TEXT,'下一页')
nextpage.click()
wait = WebDriverWait(browser, 2)
else:
break
prefix = 'https://disc.szse.cn/download'
prefix_href = 'http://www.szse.cn'
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None,tds))
p_code = re.compile('(.*?)', re.DOTALL)
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds]
p_pub_time = re.compile('(.*?)', re.DOTALL)
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix+lf[0].strip() for lf in link_ftitles],
'href': [prefix_href+lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
df.to_csv('data.csv')
browser.quit()
title=[lf[2].strip() for lf in link_ftitles
url = [prefix+lf[0].strip() for lf in link_ftitles]
for i in range(0,20):
href = url[i]
r = requests.get(href, allow_redirects=True)
f = open('深粮控股'+title[i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/announcement/')
element = browser.find_element(By.ID, 'inputCode')
time.sleep(2)
element.send_keys('600058' + Keys.RETURN)
time.sleep(2)
baogao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div
> div.col-lg-3.col-xxl-2 > div.search_inputCol > div.sse_outerItem.js_keyWords > div.sse_searchInput > input')
baogao.send_keys('年度报告'+Keys.RETURN)
time.sleep(2)
nianbao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-3.col-xxl-2 > div.search_inputCol > div.js_typeListUl > div.announceTypeList > div.announceDiv.
announce-child > ul > li:nth-child(1)')#定位到年报
nianbao.click()
time.sleep(1)#
browser.find_element(By.CSS_SELECTOR, ".range_date").click()
browser.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(1)").click()
browser.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()
browser.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(1)").click()
browser.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()
browser.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()
time.sleep(2)
element = browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-9.col-xxl-10 > div.list_tableCol > div > div.table-responsive > table' ) # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
trs=[]
soup = BeautifulSoup(html,features='lxml')
html_prettified = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
tr = p.findall(html_prettified)
trs.extend(tr)
prefix = 'https:'
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None,tds))
p_link = re.compile('(.*?)', re.DOTALL)
title=[p_link.search(td[2]).group(2).strip() for td in tds]
link_ftitles = [p_link.search(td[2]).group(1).strip() for td in tds]
codes=tds[0][0]
name=tds[0][1].strip()
p_times = [td[4] for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': name,
'公告标题': [t for t in title],
'attachpath': [prefix+lf for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
df.to_csv('data.csv')
attachpath= [prefix+lf for lf in link_ftitles]
biaoti=[t for t in title]
for i in range(0,10):
href = attachpath[i]
r = requests.get(href, allow_redirects=True)
f = open(biaoti[i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
import re
import requests
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/announcement/')
element = browser.find_element(By.ID, 'inputCode')
time.sleep(2)
element.send_keys('600058' + Keys.RETURN)
time.sleep(2)
baogao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content >
div > div.col-lg-3.col-xxl-2 > div.search_inputCol > div.sse_outerItem.js_keyWords > div.sse_searchInput > input')
baogao.send_keys('年度报告'+Keys.RETURN)
time.sleep(2)
nianbao=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div
> div.col-lg-3.col-xxl-2 > div.search_inputCol > div.js_typeListUl > div.announceTypeList > div.announceDiv.
announce-child > ul > li:nth-child(1)')
nianbao.click()
time.sleep(1)
shijian=browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div:nth-child(1) > div >
div.announce_condition > div.announce_todayCon.d-flex.align-items-center.justify-content-between >
div.today_leftDate > span.range_date.js_laydateSearch').click()
time.sleep(1)
button=browser.find_element_by_css_selector('#layui-laydate1 > div.layui-laydate-footer > div > span').click()
time.sleep(2)
element = browser.find_element(By.CSS_SELECTOR,'body > div.announcement_con > div.container.sse_content > div >
div.col-lg-9.col-xxl-10 > div.list_tableCol > div > div.table-responsive > table' )
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
trs=[]
soup = BeautifulSoup(html,features='lxml')
html_prettified = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
tr = p.findall(html_prettified)
trs.extend(tr)
prefix = 'https:'
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None,tds))
p_link = re.compile('(.*?)', re.DOTALL)
title=[p_link.search(td[2]).group(2).strip() for td in tds]
link_ftitles = [p_link.search(td[2]).group(1).strip() for td in tds]
codes=tds[0][0]
name=tds[0][1].strip()
p_times = [td[4] for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': name,
'公告标题': [t for t in title],
'attachpath': [prefix+lf for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
df.to_csv('data.csv')
time.sleep(1)
attachpath= [prefix+lf for lf in link_ftitles]
biaoti=[t for t in title]
for i in range(0,6):
href = attachpath[i]
r = requests.get(href, allow_redirects=True)
f = open(biaoti[i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
import fitz
import re
import pandas as pd
shouru=[]
shouyi=[]
name=['gongsinianbao']
class NB():
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
doc = fitz.open(name[9])
sf2021 = NB(name[9])
p1=re.compile(r"(?<=\n)(营业收入(元).*?)(?=\n归属于上市公司股东的净利润)",re.DOTALL)
x1=doc[5].get_text()
x2=doc[6].get_text()
x3=doc[7].get_text()
t=x1+x2+x3
r=p1.findall(t)
a=r[0].split('\n')
p2=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n加权平均净资产收益率)",re.DOTALL)
r2=p2.findall(t)
while r2==[]:
try:
p3=re.compile(r"(?<=\n)(基本每股收益(元/股).*?)(?=\n稀释每股收益(元/股))",re.DOTALL)
r2=p3.findall(t)
except Exception:
pass
b=r2[0].split('\n')
shouru.append(a[1])
shouyi.append(b[1])
p4=re.compile(r"\n股票简称 \n(.*?)股票代码(.*?)\n股票上市证券交易所.*?办公地址(.*?)\n办公地址的邮政编码 .*?
公司网址(.*?)\n电子信箱",re.DOTALL)#提取上市公司信息
info=p4.findall(t)
d=pd.DataFrame({'股票简称':[t[0] for t in info],
'股票代码':[t[1] for t in info],
'办公地址':[t[2] for t in info],
'公司网址':[t[3] for t in info]})
f=pd.DataFrame({'营业收入':[t for t in shouru],
'基本每股收益':[s for s in shouyi]},index=['2012年','2013年','2014年','2015年',
'2016年','2017年','2018年','2019年','2020年','2021年'])
#将提取的数据存入csv文件
df.to_csv('公司财务.csv')
d.to_csv('公司信息.csv')
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
i=['神州数码','远大控股','厦门信达','浙商中拓','爱施德','五矿发展','建发股份','物产中大','厦门国贸','九州通']
for i in i:
df=pd.read_excel("C:/Users/13644/Desktop/{}.xlsx".format(i))
fig=plt.figure(figsize=(20,8),dpi=80)
ax=fig.add_subplot(111)
lin1=ax.plot(df.index,df["营业收入"],marker="o",label="营业收入")
ax.set_title('{}公司2012——2021营业收入及基本每股收益'.format(i),size=20)
ax.set_xlabel("时间",size=18)
ax.set_ylabel("营业收入",size=18)
for i,j in df["营业收入"].items():
ax.text(i,j+20,str(j),va="bottom",ha="center",size=15)
ax1=ax.twinx()
lin2=ax1.plot(df.index,df["基本每股收益"],marker="o",color="red",label="基本每股收益")
ax1.set_ylabel("基本每股收益)",size=18)
lins=lin1+lin2
labs=[l.get_label() for l in lins]
ax.legend(lins,labs,loc="upper left",fontsize=15)
plt.show()
df=pd.read_excel("C:/Users/13644/Desktop/1.xlsx",header=0,index_col=0)
for i in range(10):
a=i+12
plt.figure(figsize=(12,10))
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.title("20{}年上市公司基本每股收益比较".format(a))
plt.bar(x=df.columns,height=df.iloc[i],width=0.5)
df=pd.read_excel("C:/Users/13644/Desktop/2.xlsx",header=0,index_col=0)
for i in range(10):
a=i+12
plt.figure(figsize=(12,10))
plt.xlabel('年份')
plt.ylabel('营业收入/元')
plt.title("20{}年上市公司营业收入比较".format(a))
plt.bar(x=df.columns,height=df.iloc[i],width=0.5)

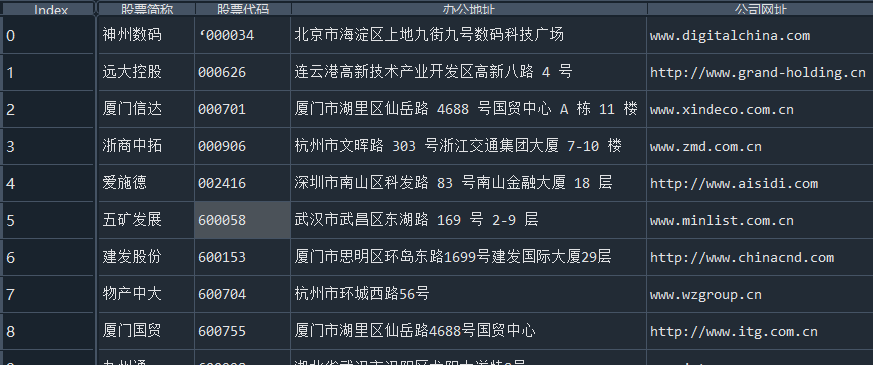
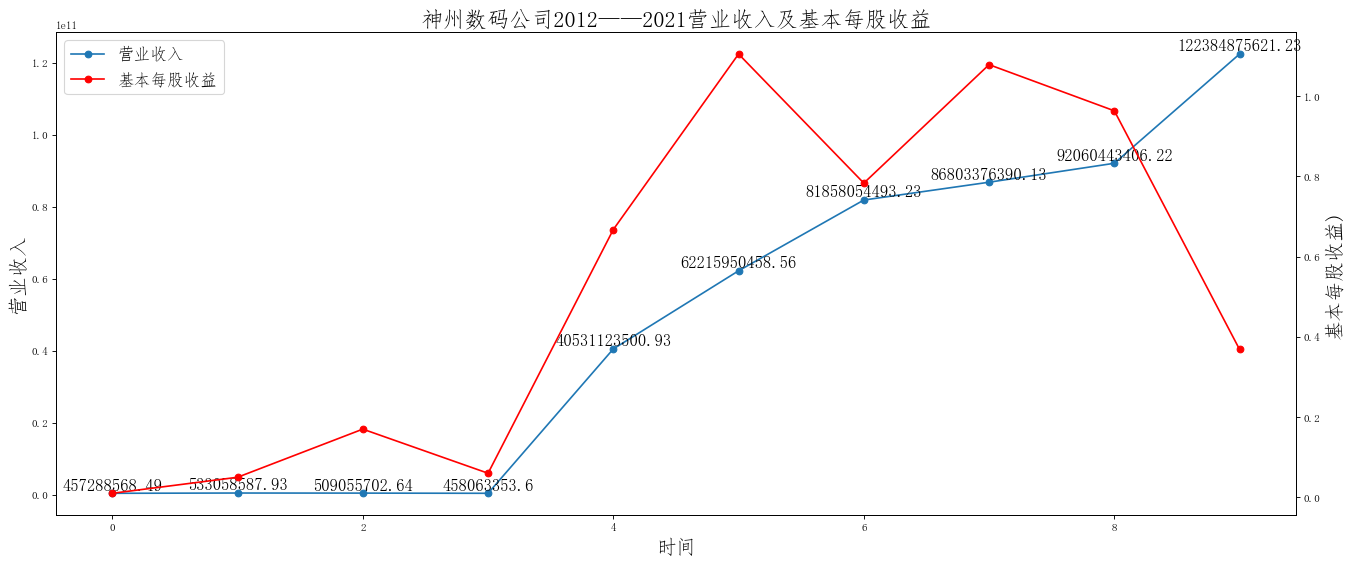
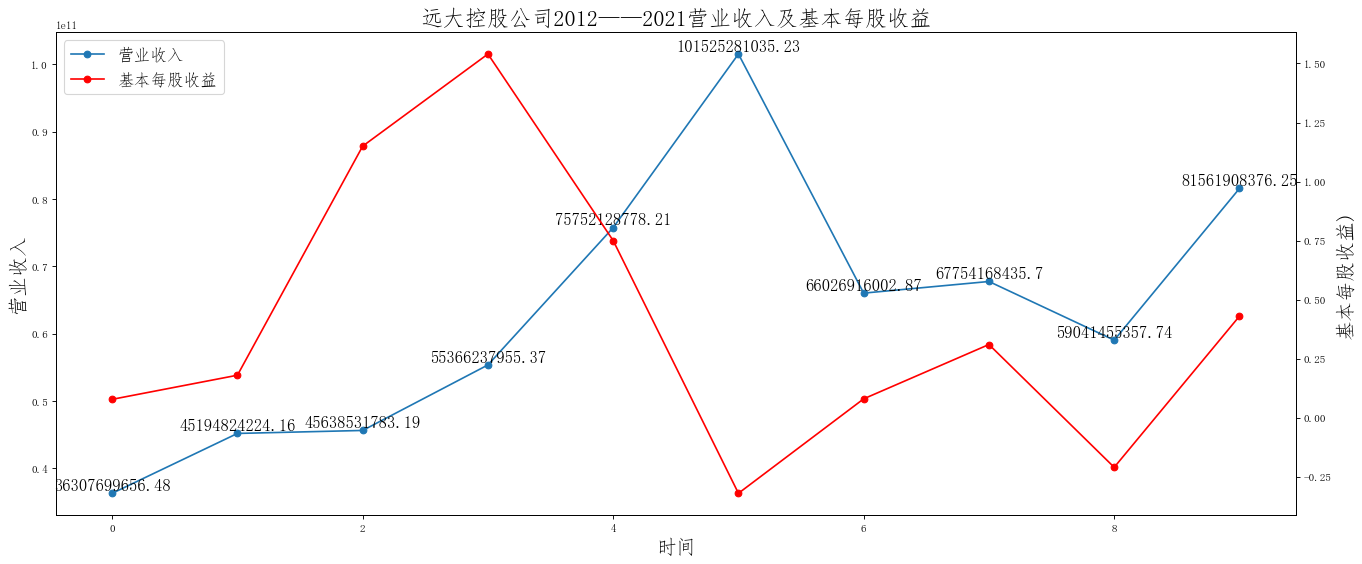
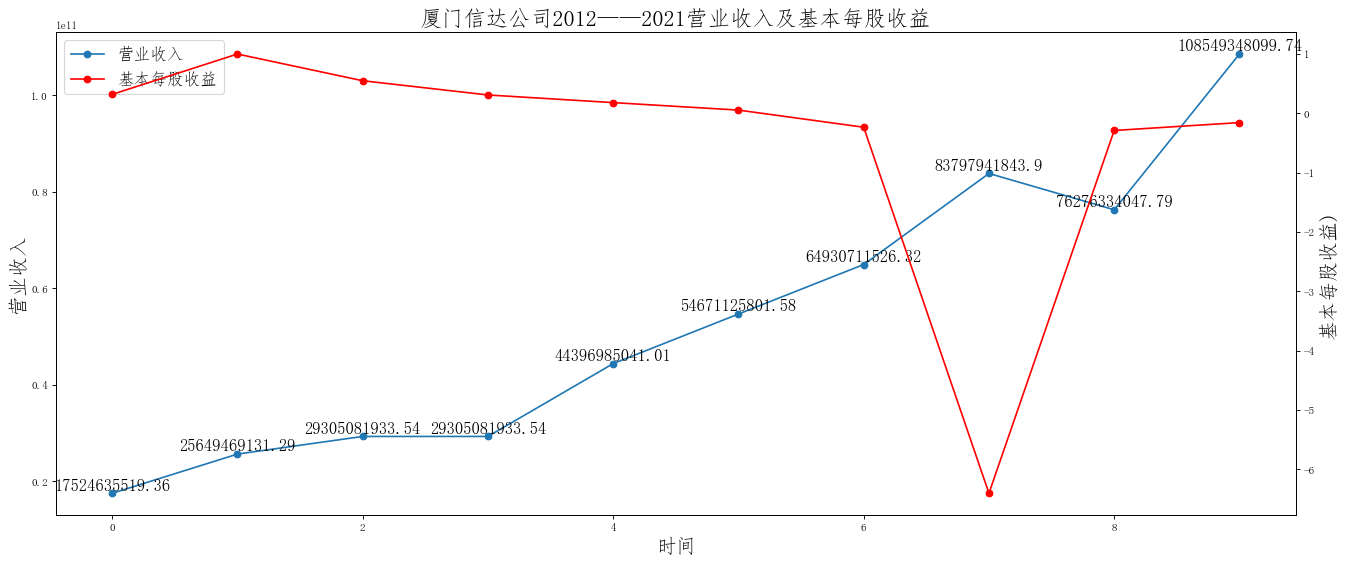
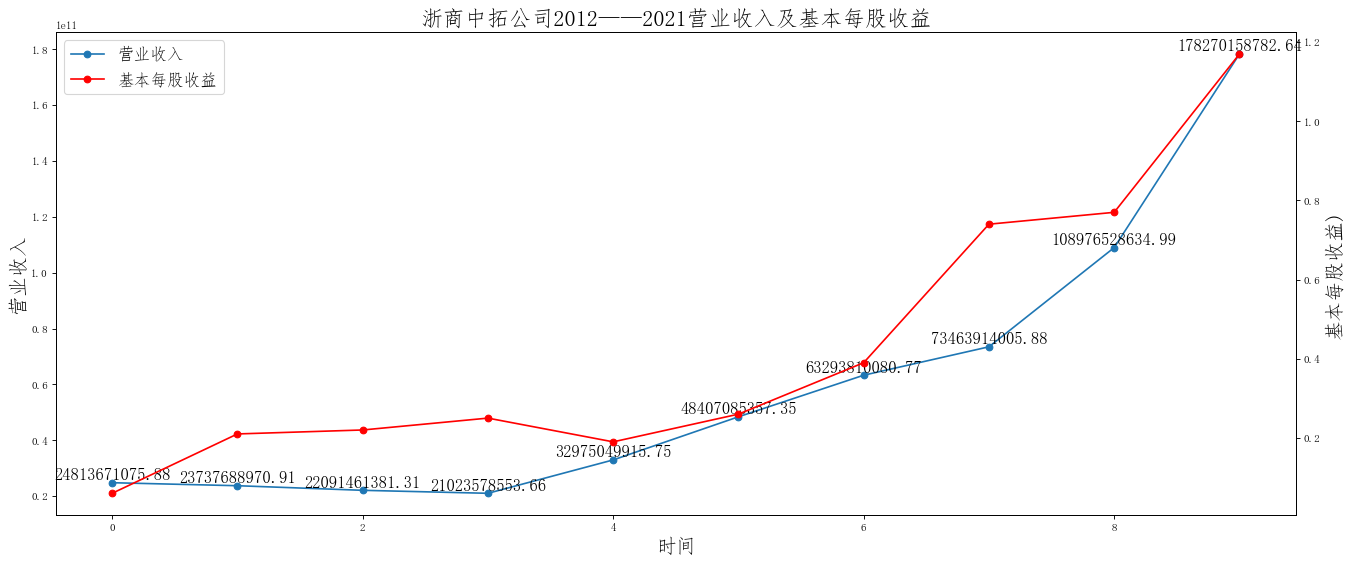
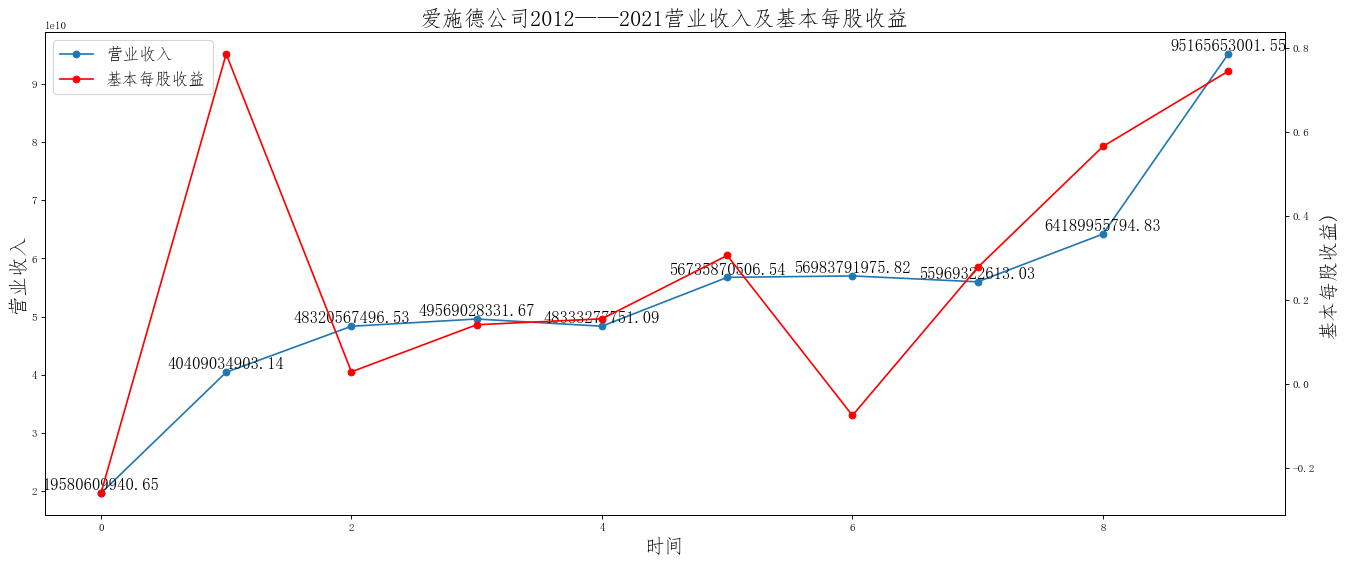
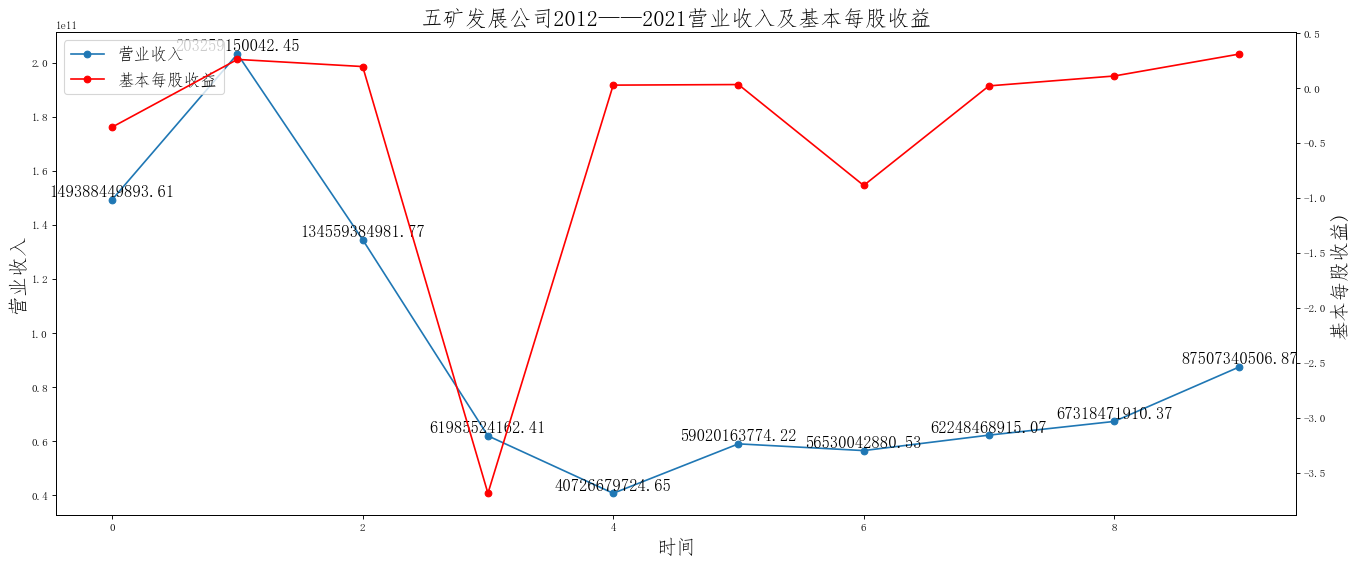
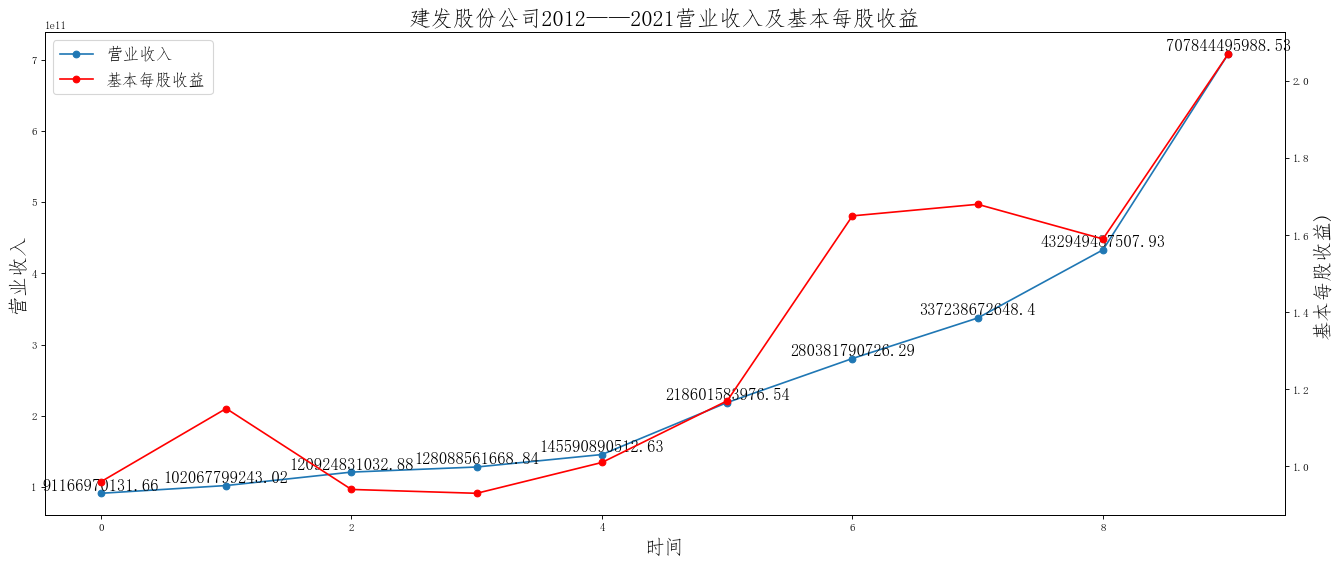
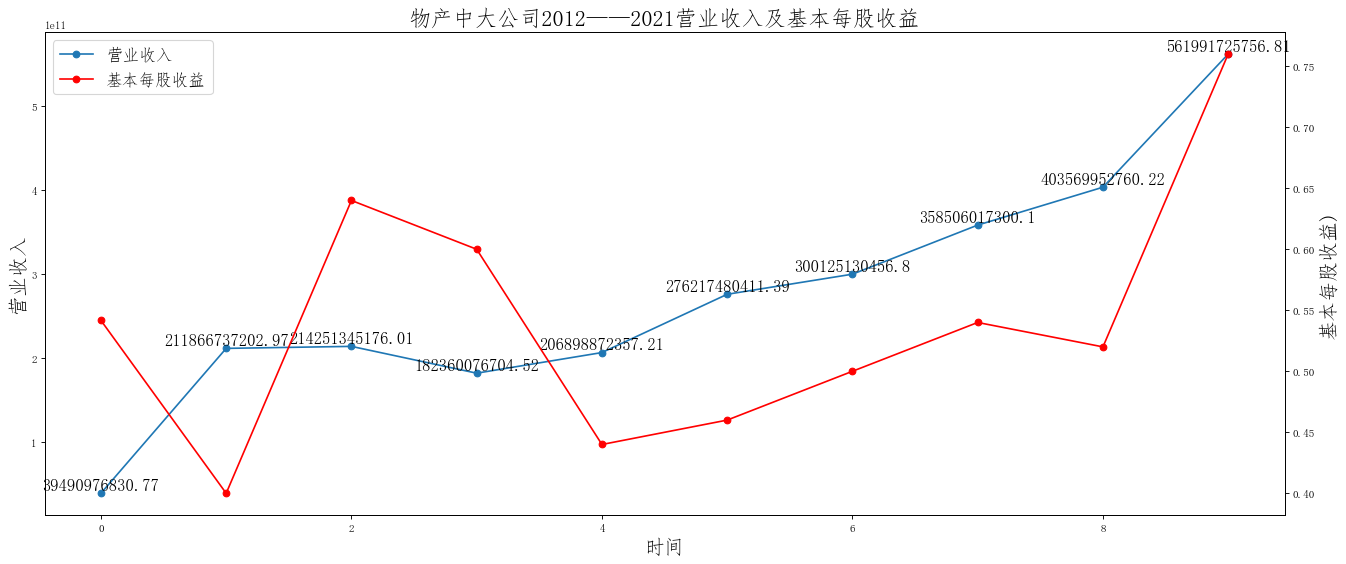
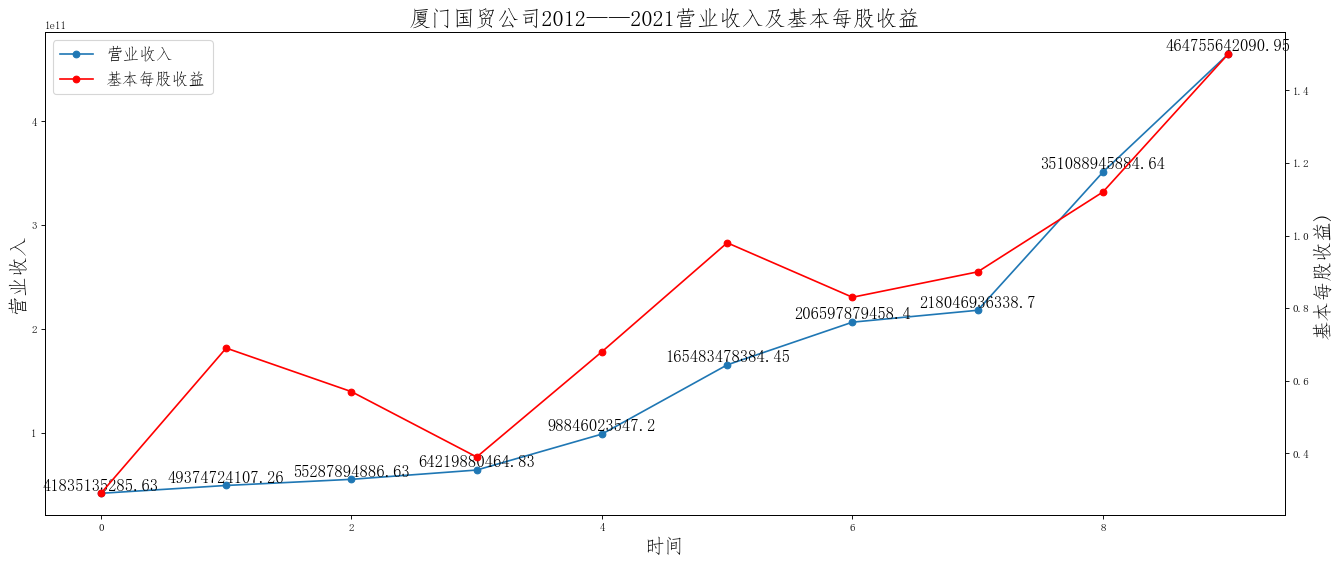
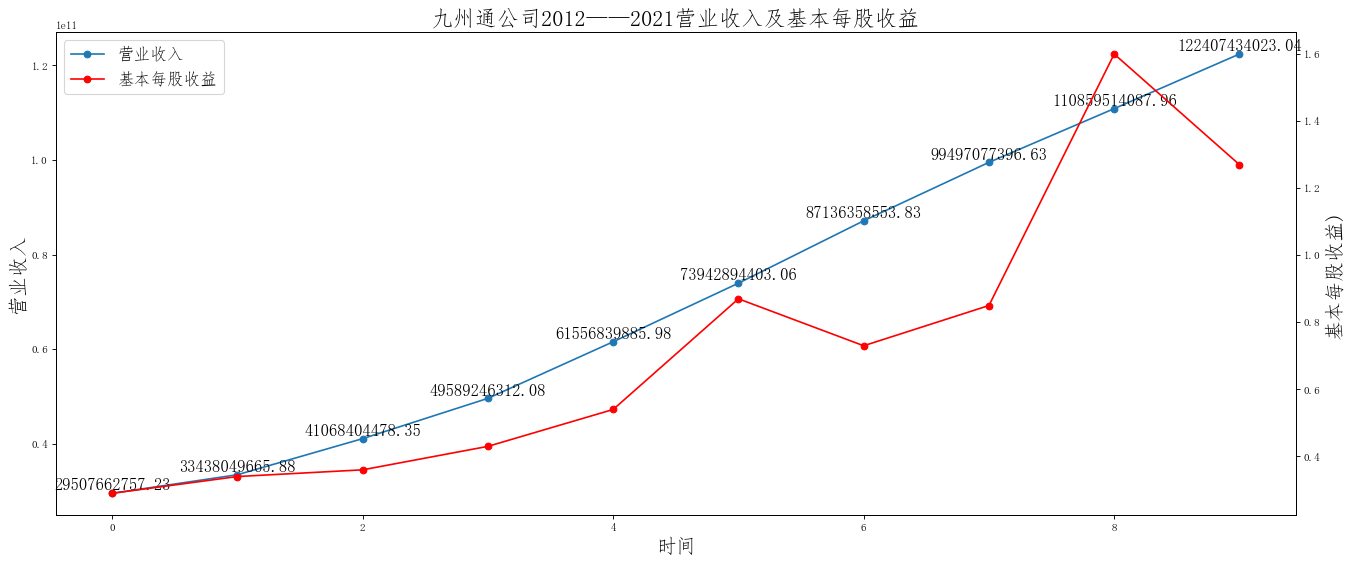
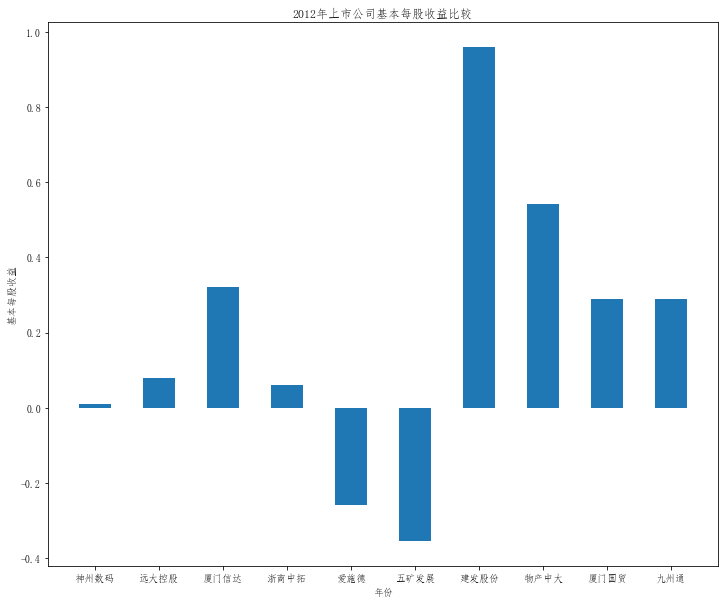
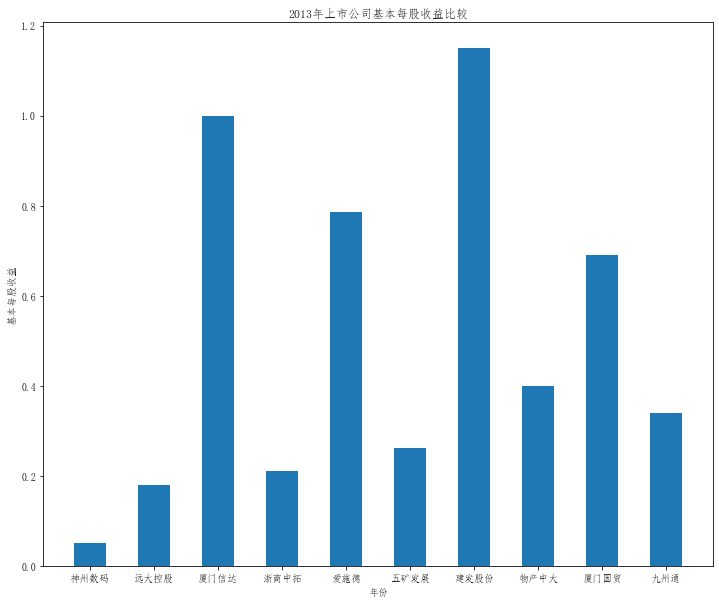
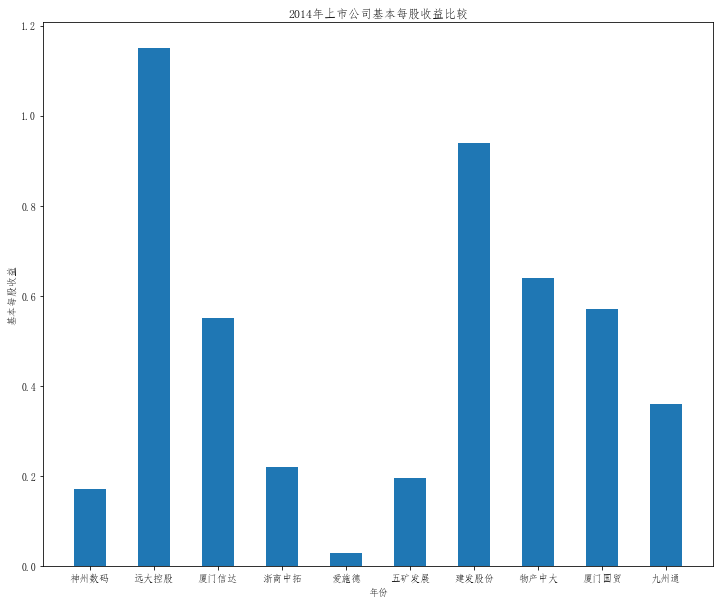
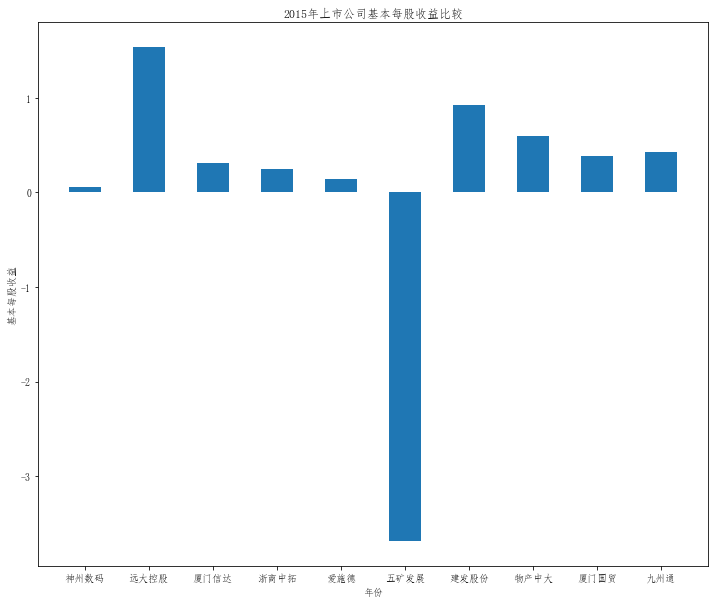
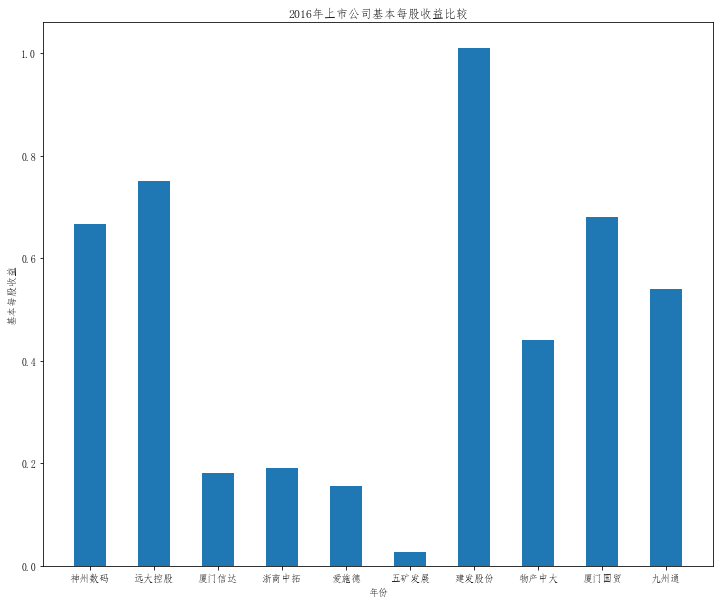
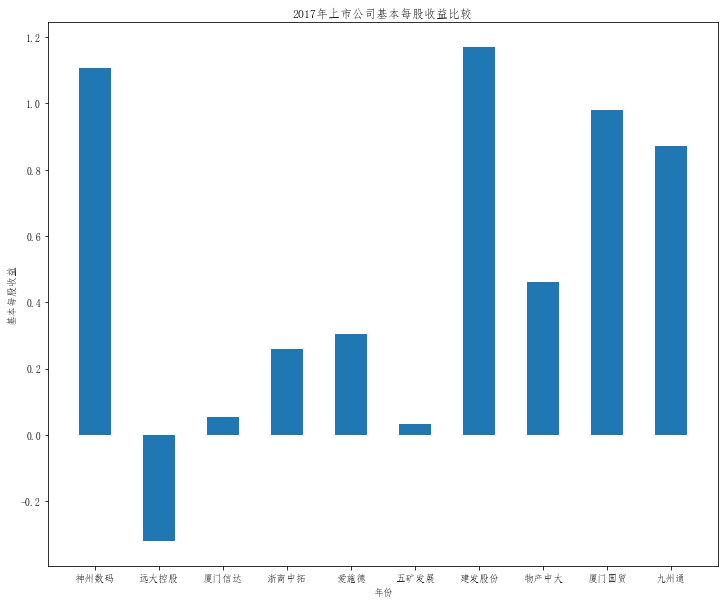
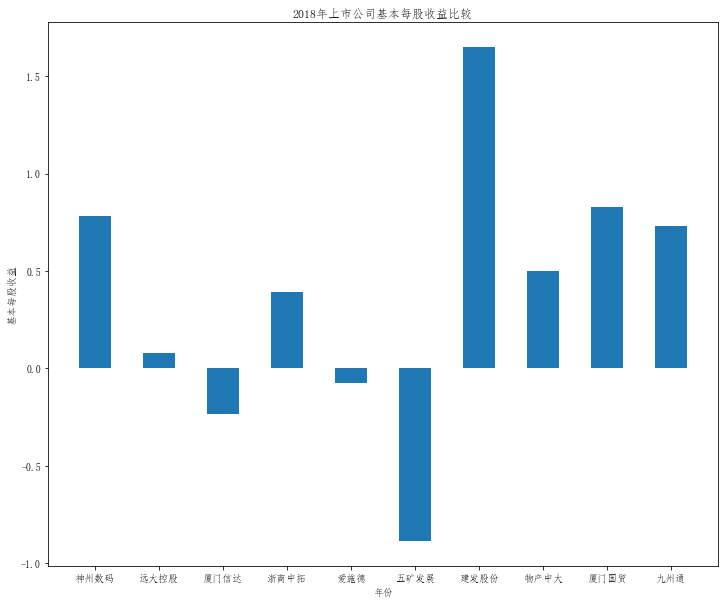
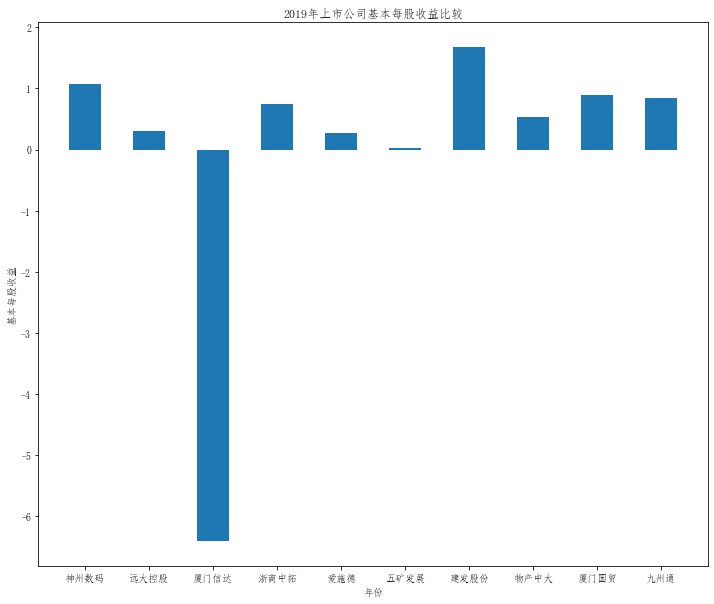
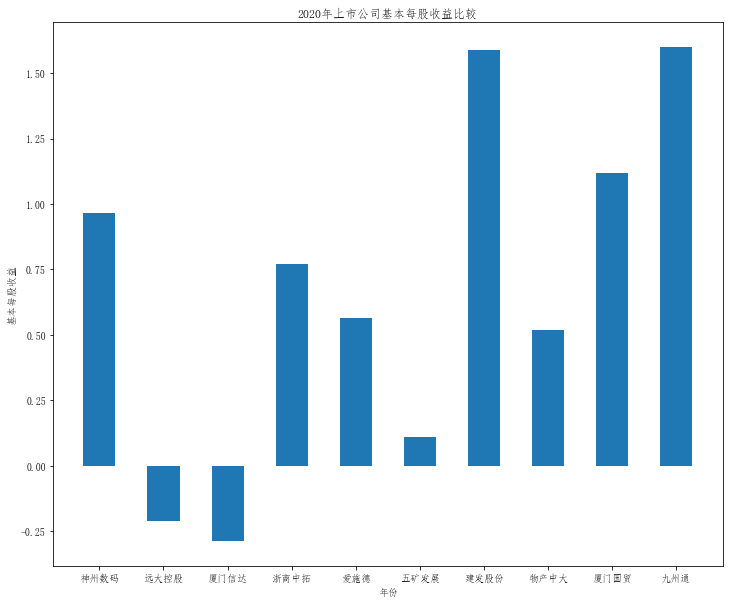
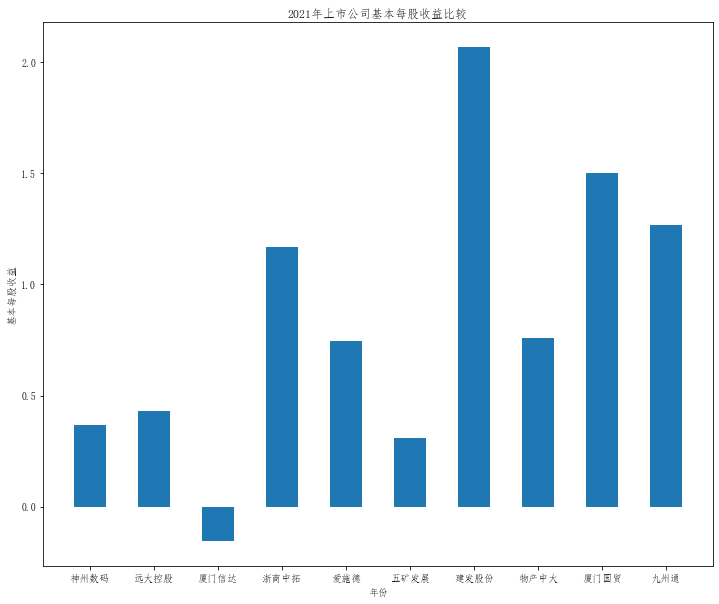
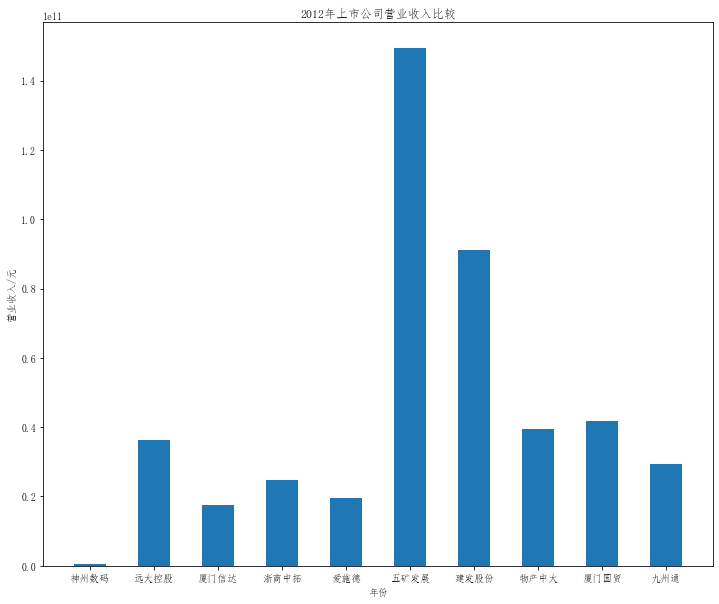
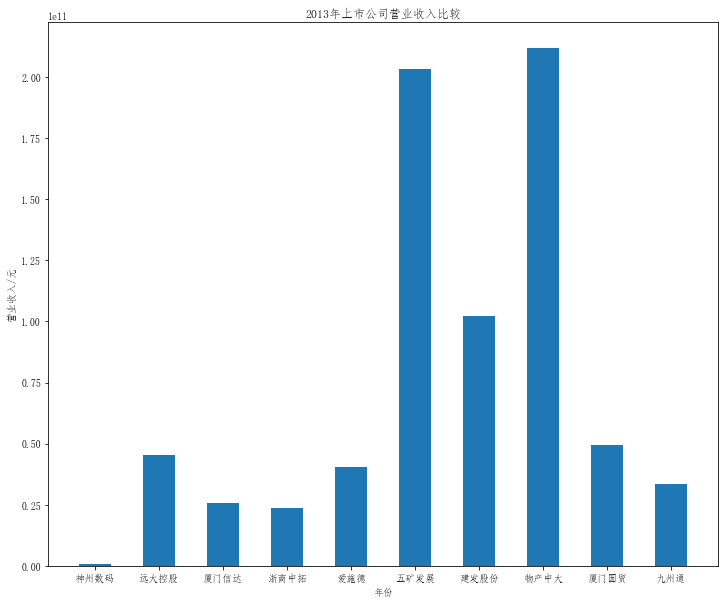
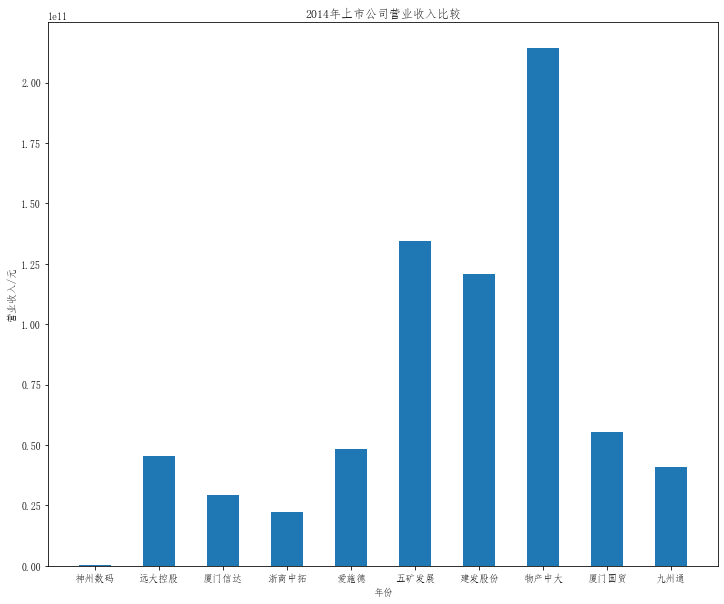
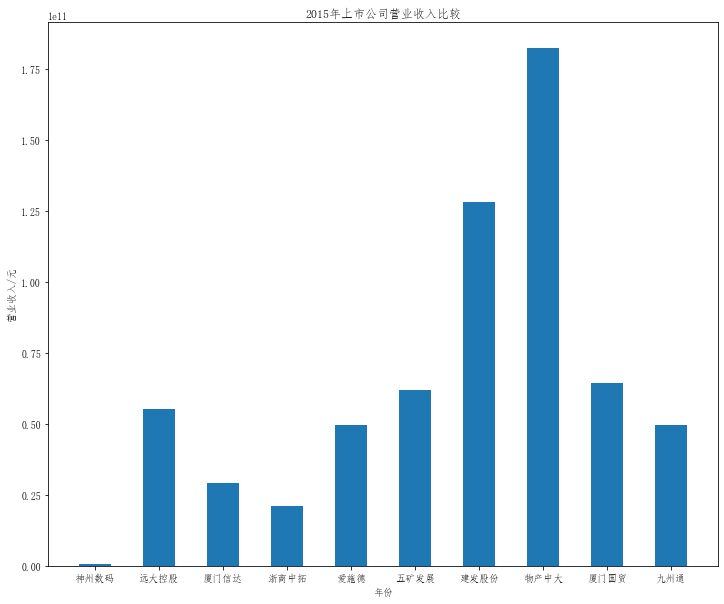
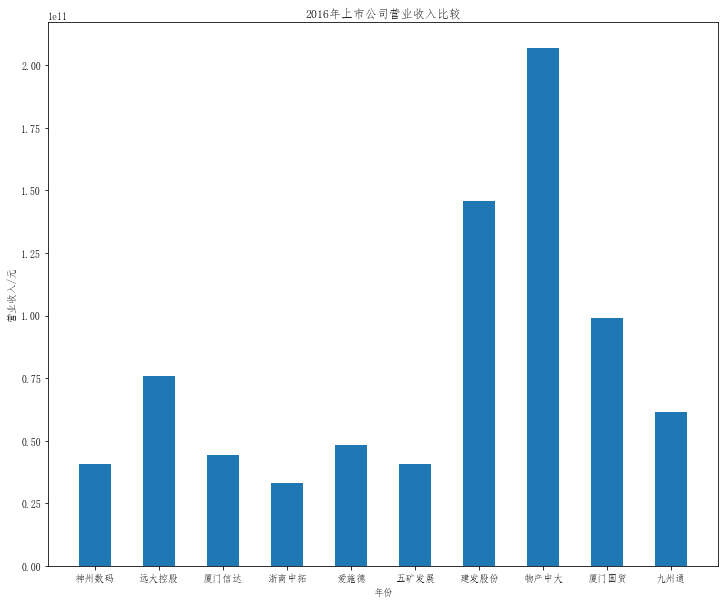
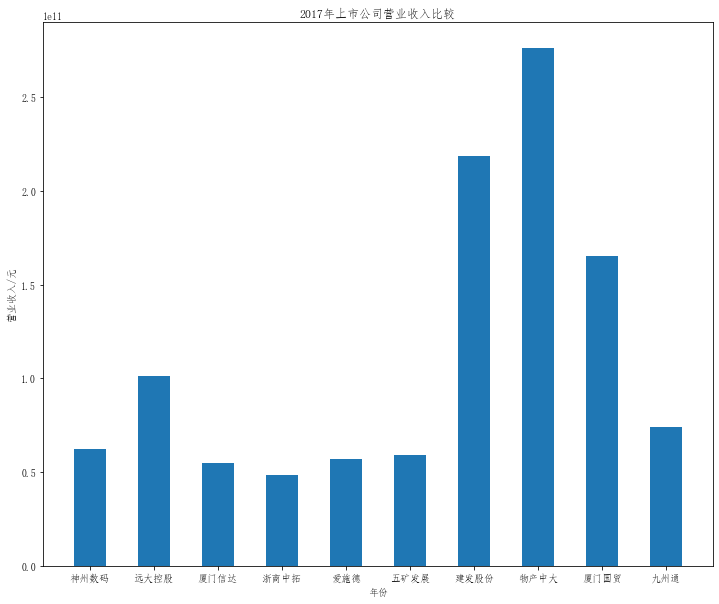
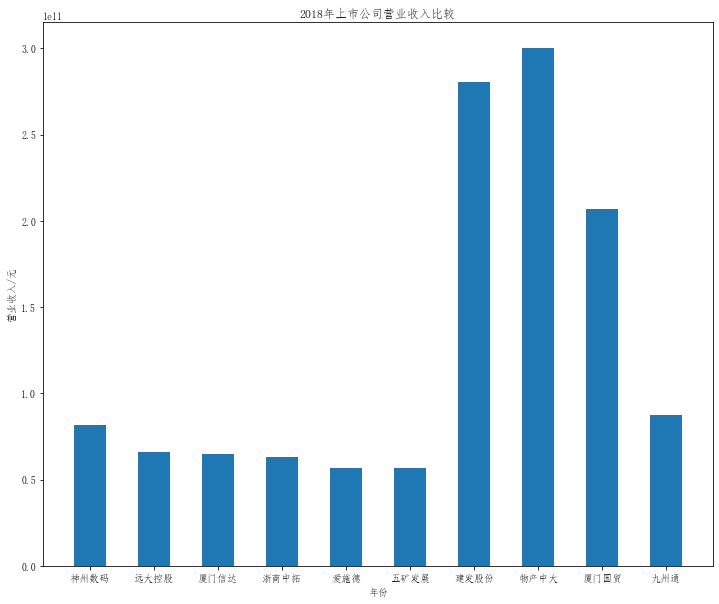
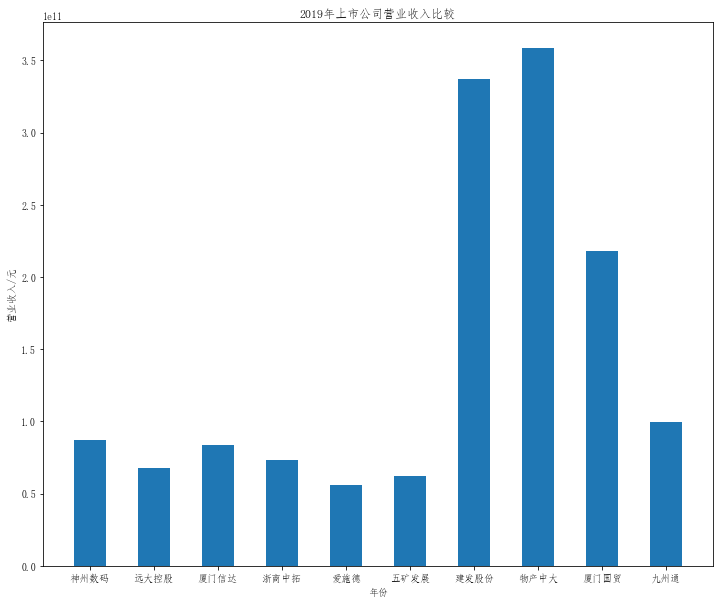
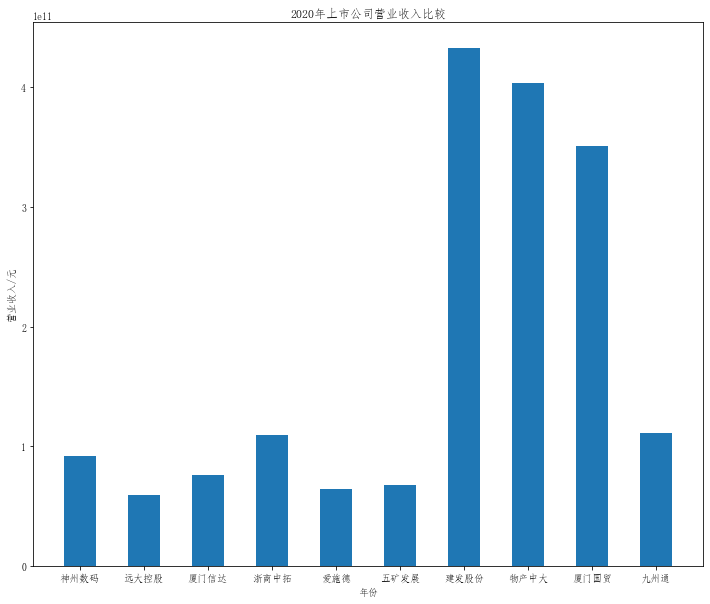
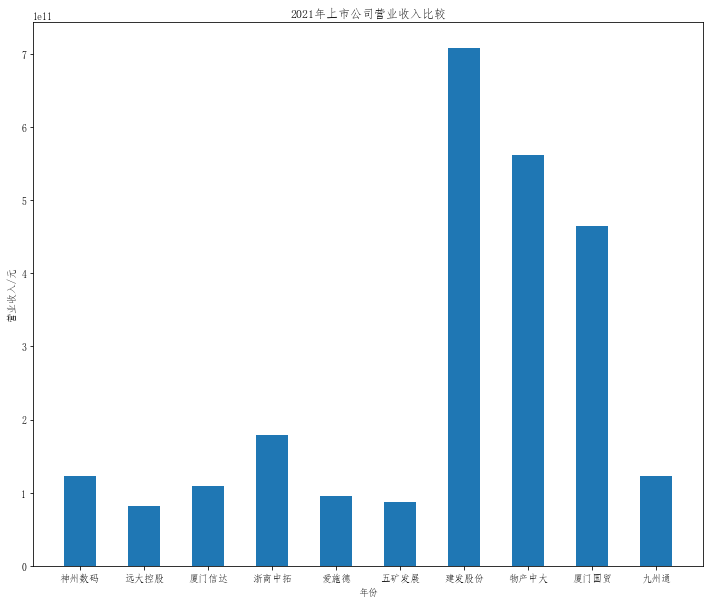
在这次大作业中,我解析的行业为行业分类51的批发业,这个行业的上市公司一共有81家,所以数量上还是挺多, 而且在解析信息时,我发现这些公司被分为批发业在我心中还是有点疑惑的,因为这些公司有医疗,有交通等等, 所以我还是不太能知道,为什么能这样分类。在最后的行业数据解析时,我发现一些典型的批发业公司在2015到 2019年的数据都挺惨淡的,原因我分析还是因为电商平台的大力发展,还是对这些公司产生了比较大的影响,但 能生存下来的公司在最近几年都扭转了颓势,数据都在上升。 最后还是总结一下吧,这门课真实我大学期间选的最难的一门了,因为我在之前有过一点点python基础,所以选 这门课的时候还是挺自信的,尤其是在前几门课,我感觉应该会很轻松地拿分,但到了正则表达式这里,就开始 难起来了,这门课不仅对一些库的使用方法需要比较熟练的掌握,最关键的还是要对python这门语言有更深的理 解,不管是循环语法的使用,还是一些细节的处理,在这门课中,我真的提升了许多,还是很谢谢吴老师这学期 细心的教导,我也相信这门课学到的东西能伴随我一生。