从行业分类结果中爬取‘建筑装饰和其他建筑业’所有企业的代码
爬取企业对应代码,并且存到列表li中以便后续使用,如下
import fitz
import re
import pandas as pd
from bs4 import BeautifulSoup
doc = fitz.open(r'F:\python大数据挖掘与处理\homework\a_zuoye\category.pdf')
#手动定位所在行业
page78 = doc[77]
text1 = page78.get_text()
doc.close()
#获取行业企业的代码
#p1 = re.compile(r'(?<=\n)(?:\d{6}\n\*?\w+)*(?=\n)')
p1 = re.compile(r'(?<=\n)(\d{6})\n(\*?\w+)*(?=\n)')
txt_1 = p1.findall(text1)
txt1 = txt_1[1:32]
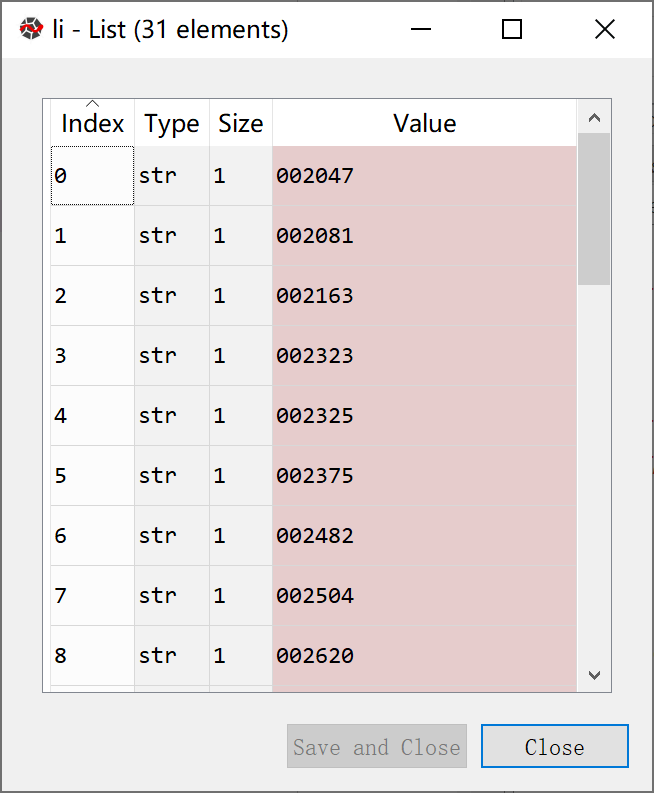
li = []
for i in range(0,len(txt1)):
x = txt1[i]
x = x[0]
i=i+1
li.append(x)
如图
爬取深交所中对应企业的年报链接,并存放到csv中,如下
#进行深交所网页的爬取
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
for m in range(21):
element = browser.find_element(By.ID, 'input_code')
element.send_keys(li[m])
time.sleep(1)
element.send_keys(Keys.ENTER)
time.sleep(1)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(1)
browser.find_element(By.CSS_SELECTOR, ".input-left").click()
browser.find_element(By.CSS_SELECTOR, ".input-left").send_keys("2012-12-20")
browser.find_element(By.CSS_SELECTOR, ".input-right").click()
browser.find_element(By.CSS_SELECTOR, ".input-right").send_keys("2022-05-20")
browser.find_element(By.CSS_SELECTOR, ".input-right").send_keys(Keys.ENTER)
time.sleep(2)
element1 = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element1.get_attribute('innerHTML')
time.sleep(2)
f = open('innerHTML.html','a',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.find_element(By.CSS_SELECTOR, ".btn-clearall").click()
browser.quit()
#对爬取的网页数据进行处理,得到所需要的信息并提取至csv文件
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('innerHTML.html')
def txt_to_df(html):
# html table text to DataFrame
p1 = re.compile('(.*?) ', re.DOTALL)
trs = p1.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None,tds1))#删去空行
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'http://disc.szse.cn/download'
prefix_href = 'http://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data(df_txt)
#过滤年报摘要与已取消的年报
df_data1 = df_data[df_data['公告标题'].str.endswith('摘要')]
df_data2 = df_data[df_data['公告标题'].str.endswith('(已取消)')]
df_data3 = df_data[df_data['公告标题'].str.endswith('摘要(更新后)')]
df_data4 = df_data[df_data['公告标题'].str.endswith('(英文版)')]
df_data_temporary1 = df_data[-df_data['公告标题'].isin(df_data1['公告标题'])]
df_data_temporary2 = df_data_temporary1[-df_data_temporary1['公告标题'].isin(df_data2['公告标题'])]
df_data_temporary3 = df_data_temporary2[-df_data_temporary2['公告标题'].isin(df_data3['公告标题'])]
df_data_final = df_data_temporary3[-df_data_temporary3['公告标题'].isin(df_data4['公告标题'])]
df_data_final = df_data_final.reset_index(drop=True)
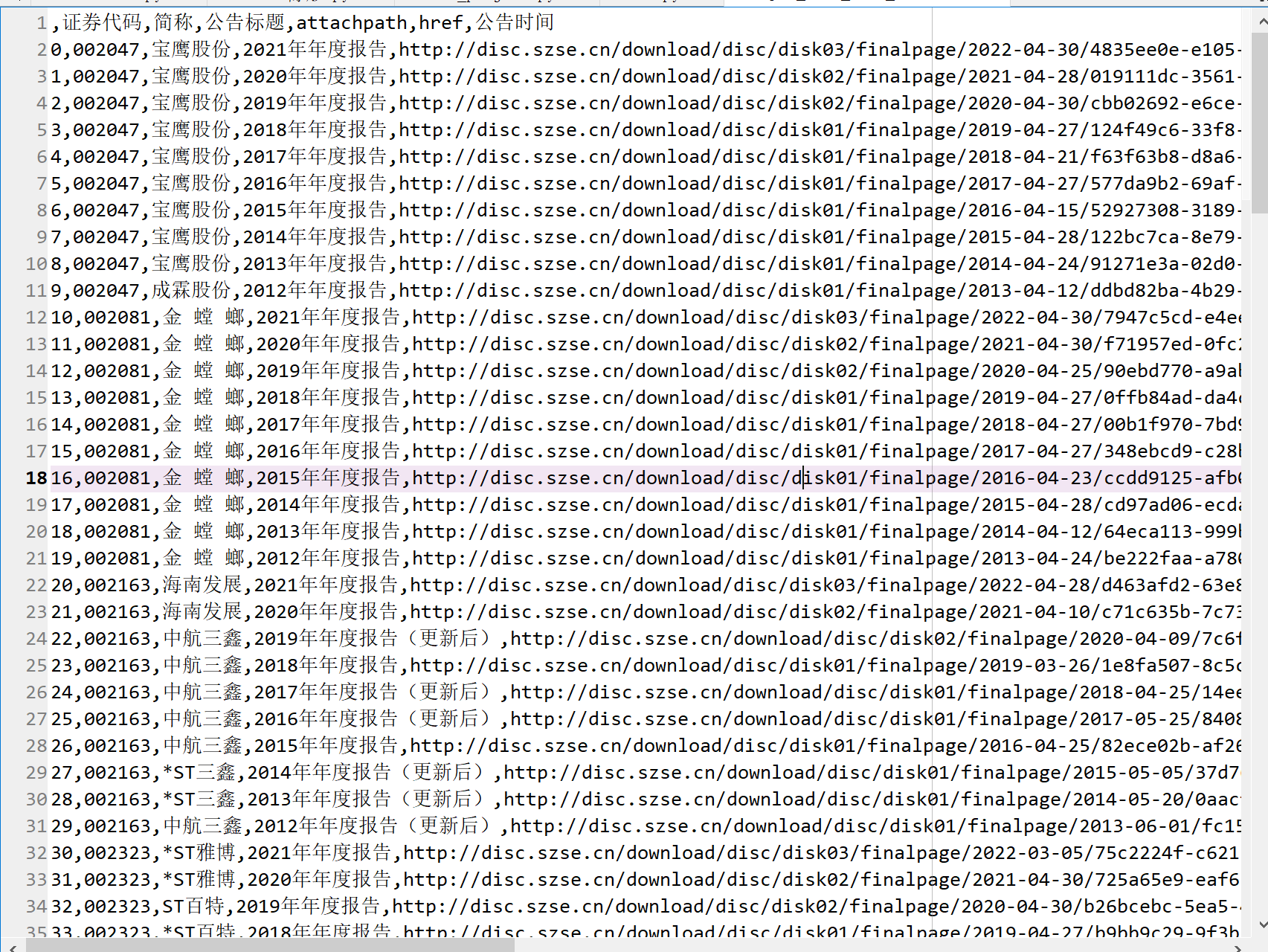
df_data_final.to_csv('sample_data_from_shen.csv')
如图
提取深交所股票代码和股票简称,如下
#提取股票代码和股票简称
jc_shen = pd.DataFrame(df_data_final['简称'])
dm_shen = pd.DataFrame(df_data_final['证券代码'])
dmjc_shen = dm_shen.join(jc_shen, how='outer')
dmjc_shen.drop_duplicates(subset=["简称"], inplace=True)
根据提取的下载地址下载深交所年报,如下
#根据提取的下载地址下载年报
import requests
filenames =df_data_final.iloc[:,0]+'—'+ df_data_final.iloc[:,2]
df_filenames = pd.DataFrame({'文件名称': filenames})
for n in range(len(df_data_final)):
href = df_data_final.iloc[n,3]
print(href)
r = requests.get(href, allow_redirects=True)
f = open(df_filenames.iloc[n,0] + '.pdf', 'wb')
f.write(r.content)#写入r的内容
f.close()
r.close()
爬取上交所年报链接并另存,如下
for m in range(21,31):
driver = webdriver.Chrome()
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
element = driver.find_element(By.ID, 'inputCode')
driver.find_element(By.ID, "inputCode").click()
driver.find_element(By.ID, "inputCode").send_keys(li[m])
time.sleep(2)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(2)
element2 = driver.find_element(By.CLASS_NAME, "sse_colContent.js_regular")
time.sleep(2)
innerHTML2 = element2.get_attribute('innerHTML')
time.sleep(2)
f = open('innerHTML2.html','a',encoding='utf-8')
f.write(innerHTML2)
f.close()
driver.quit()
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html2 = to_pretty('innerHTML2.html')
def txt_to_df(html):
# html table text to DataFrame
p1 = re.compile('(.*?) ', re.DOTALL)
trs = p1.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None,tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html2)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
p_time = re.compile('\s+(.*?)\s+',re.DOTALL)
get_a = lambda txt: p_a.search(txt).group(1).strip()
get_span = lambda txt: p_span.search(txt).group(1).strip()
get_time = lambda txt: p_time.search(txt).group(1).strip()
def get_link2(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
href = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
def get_data2(df_txt):
prefix_href = 'http://static.sse.com.cn/'
df = df_txt
codes = [get_span(td) for td in df['证券代码']]
short_names = [get_span(td) for td in df['简称']]
ahts = [get_link2(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data2(df_txt)
#过滤年报摘要与已取消的年报
df_data1 = df_data[df_data['公告标题'].str.endswith('摘要')]
df_data2 = df_data[df_data['公告标题'].str.endswith('意见')]
df_data3 = df_data[df_data['公告标题'].str.endswith('工作报告')]
df_data4 = df_data[df_data['公告标题'].str.endswith('决算报告')]
df_data5 = df_data[df_data['公告标题'].str.endswith('摘要(修订版)')]
df_data6 = df_data[df_data['公告标题'].str.endswith('检查报告')]
df_data7 = df_data[df_data['公告标题'].str.endswith('审核报告')]
df_data8 = df_data[df_data['公告标题'].str.endswith('报告书')]
df_data9 = df_data[df_data['公告标题'].str.endswith('说明')]
df_data_temporary1 = df_data[-df_data['公告标题'].isin(df_data1['公告标题'])]
df_data_temporary2 = df_data_temporary1[-df_data_temporary1['公告标题'].isin(df_data2['公告标题'])]
df_data_temporary3 = df_data_temporary2[-df_data_temporary2['公告标题'].isin(df_data3['公告标题'])]
df_data_temporary4 = df_data_temporary3[-df_data_temporary3['公告标题'].isin(df_data4['公告标题'])]
df_data_temporary5 = df_data_temporary4[-df_data_temporary4['公告标题'].isin(df_data5['公告标题'])]
df_data_temporary6 = df_data_temporary5[-df_data_temporary5['公告标题'].isin(df_data6['公告标题'])]
df_data_temporary7 = df_data_temporary6[-df_data_temporary6['公告标题'].isin(df_data7['公告标题'])]
df_data_temporary8 = df_data_temporary7[-df_data_temporary7['公告标题'].isin(df_data8['公告标题'])]
df_data_final2 = df_data_temporary8[-df_data_temporary8['公告标题'].isin(df_data9['公告标题'])]
#df_data_final = df_data_temporary3[-df_data_temporary3['公告标题'].isin(df_data4['公告标题'])]
df_data_final2 = df_data_final2.reset_index(drop=True)
for n in range(len(df_data_final2)):
df_data_final2['公告标题'] = df_data_final2.iloc[:,4] + '出的年度报告'
df_data_final2.to_csv('sample_data_from_shang.csv')
如图结果

提取所有公司的股票简称和股票代码存入csv文件,如下
##提取上交所股票代码和股票简称
jc_shang = pd.DataFrame(df_data_final2['简称'])
dm_shang = pd.DataFrame(df_data_final2['证券代码'])
dmjc_shang = dm_shang.join(jc_shang, how='outer')
dmjc_shang.drop_duplicates(subset=["简称"], inplace=True)
#合并所有公司的股票代码和简称并另存
dmjc = pd.concat([dmjc_shen,dmjc_shang])
dmjc.reset_index(drop=True)
dmjc.to_csv('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\dmjc.csv')
代码和简称如图所示

下载上交所年报,如下
#根据提取的下载地址下载年报
import requests
filenames =df_data_final.iloc[:,0]+'—'+ df_data_final.iloc[:,2]
df_filenames = pd.DataFrame({'文件名称': filenames})#对爬取的文件进行重命名
for n in range(len(df_data_final)):
href = df_data_final.iloc[n,3]
print(href)
r = requests.get(href, allow_redirects=True)
f = open(df_filenames.iloc[n,0] + '.pdf', 'wb')
f.write(r.content)#写入r的内容
f.close()
r.close()
由于年报是分散下载的,故而手动将年报按照股票代码进行文件夹分类,结果如图
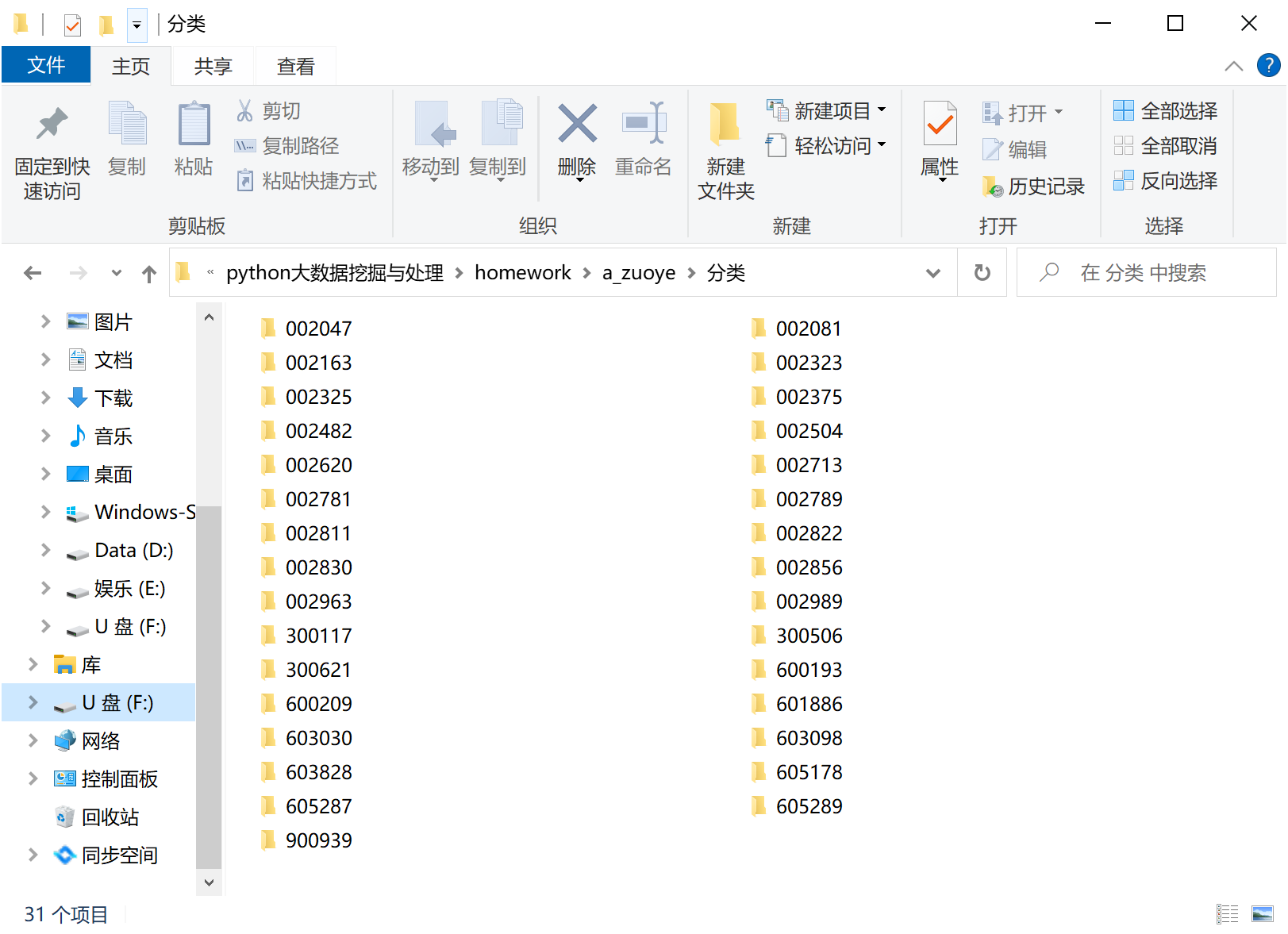
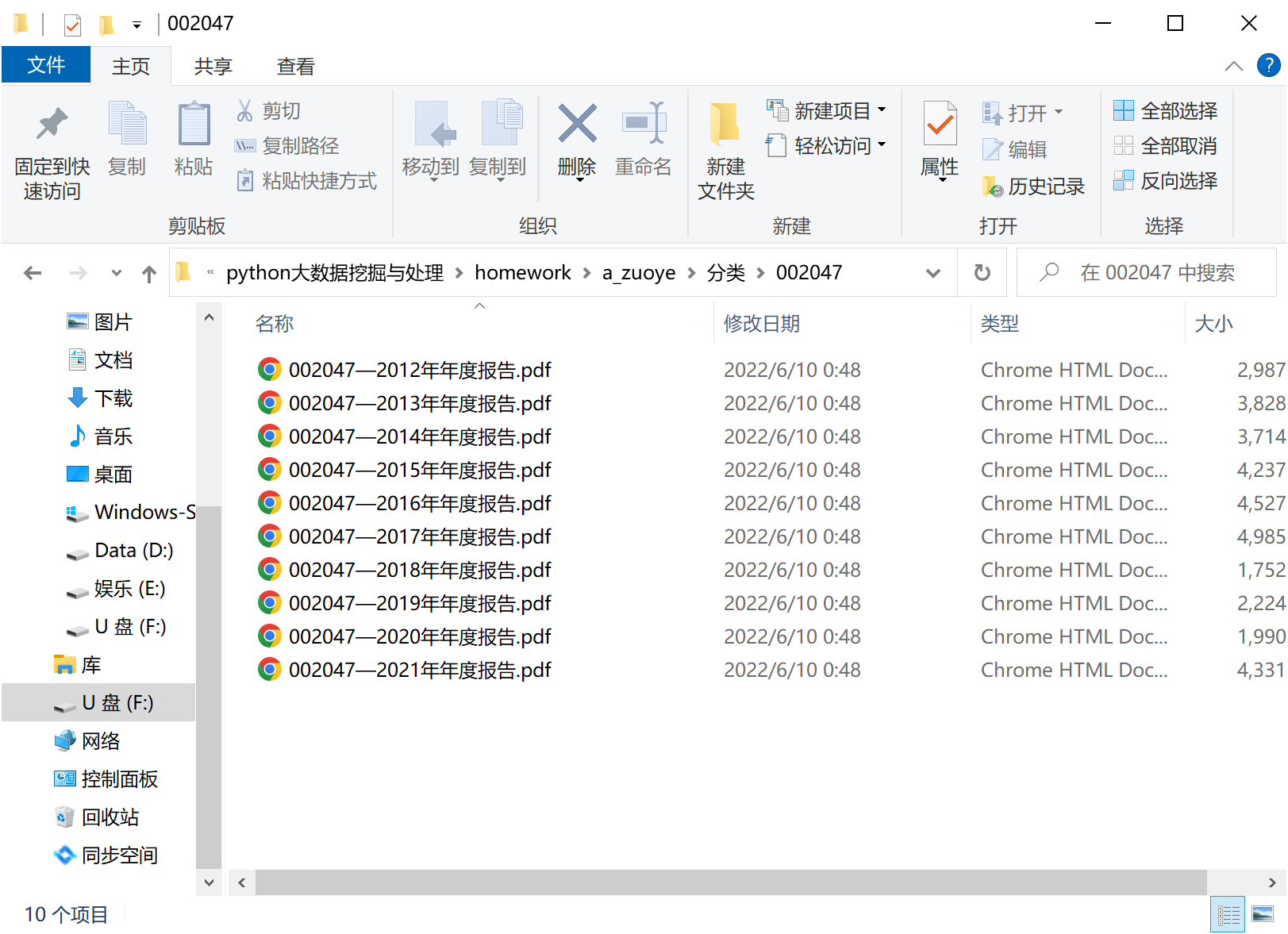
股票代码文件内部存放该公司的年报,如图
处理pdf,先定义获取年报的函数,再分别利用正则表达式定义提取营业收入和每股收益的函数如下:
#处理pdf
import fitz
import re
import pandas as pd
import os
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
#获取营业收入
def getText(pdf):#定义函数获取文本
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.get_text()
doc.close()
text = text.replace(" "," \n")
text = text.replace("\n\n","\n")#由于后续subp匹配过程中,有的数字后面没有换行符,无法成功进行非贪婪的匹配,所以通过文本内部符号替换
return(text)
def get_content(pdf):#定义函数获取营业收入所在年报内容的位置
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?数据\D*?\s*(?=\\n)(.*?)经营活动产生的',re.DOTALL)#定位各个年报固定位置的内容
content = p.search(text).group(0)
return(content)
def parse_data_line(pdf):#定义函数单独提取营业收入所在行的内容
content = get_content(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)营业(\D*?\n)+%s" % psub)#定义营业收入那一行的内容
lines = p.search(content)
lines = lines[0]#形成列表内容
return(lines)
#提取每股净收益
def get_profit(pdf):
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?指标\D*?\s*(?=\\n)(.*?)稀释每股',re.DOTALL)
profit = p.search(text).group(0)
return(profit)
def profit_data_line(pdf):
profit = get_profit(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)基本每股收益(\D*?\n)+%s" % psub)#定义每股收益那一行的内容
lines_profit = p.search(profit)
lines_profit = lines_profit[0]#形成列表内容
return(lines_profit)
再写出循环,提取各家公司各个年份的营业收入,发现提取营业收入的函数中的正则可以匹配下载中的年报的所有营业收入,没有中途报错
将提取出的营业收入放入DataFrame中,改变索引后输出为csv文件,便于后续画图使用如下:
#循环获取营业收入
df_sale = pd.DataFrame()#创建一个空表格
path = 'F:\\python大数据挖掘与处理\\homework\\a_zuoye\\分类'
os.chdir(path)
wenjian = os.listdir(path)
for info in wenjian:
domain = os.path.abspath(path) #获取文件夹的路径
info = os.path.join(domain,info) #完整路径
ste = info[-6:]#将公司名称赋给st3
filenames = os.listdir(ste)#获取各个公司文件夹中pdf文件的名称
sale = []
for pdf in filenames:
i=0
df = pd.DataFrame()#创建一个空表格
pdf = "\\"+pdf
x = "F:\\python大数据挖掘与处理\\homework\\a_zuoye\\分类\\"+ste+pdf#形成路径链接(直接用pdf会打不开)
sale_gain = parse_data_line(x)
sale_gain = sale_gain.split("\n")#将列表里的字符串以换行符进行分割,形成新的列表
sale_gain = sale_gain[1]#取列表中第二个字符串,即营业收入
sale.append(sale_gain)#将营业收入放入新的列表
df.insert(i, ste, sale)#以列为单位加入表格
i=i+1
df_sale = df_sale.join(df, how='outer')
print('循环结束')
os.chdir('F:\\python大数据挖掘与处理\\homework\\a_zuoye')
index1 = ['2021营业收入','2020营业收入','2019营业收入','2018营业收入','2017营业收入',\
'2016营业收入','2015营业收入','2014营业收入','2013营业收入','2012营业收入']
df_sale_T = pd.DataFrame(df_sale.values.T,columns=index1,index=df_sale.columns)
df_sale_T.to_csv('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\sales.csv')
营业收入结果
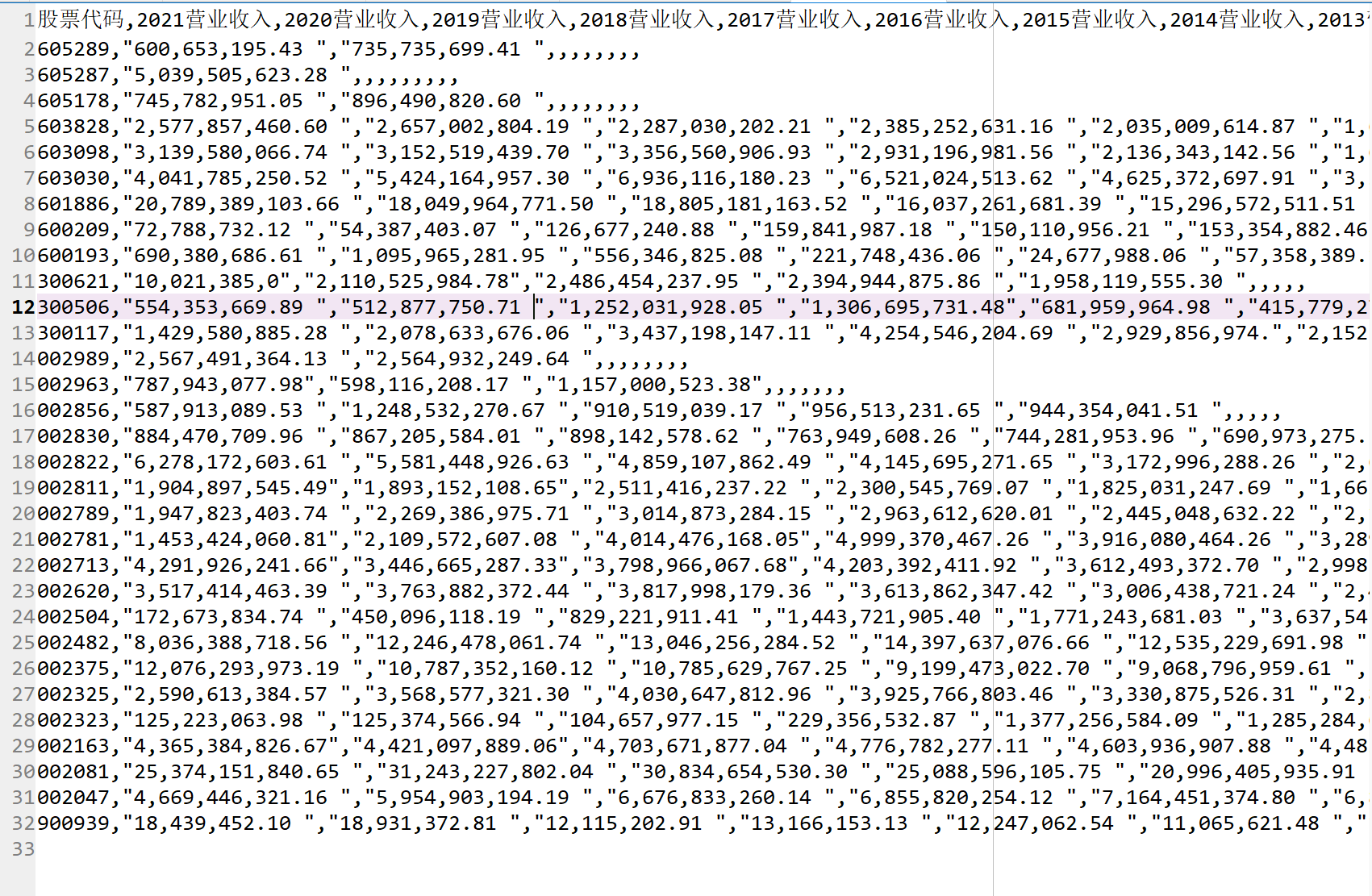
循环提取每股净收益,在多次报错之后试图找到原因并解决,但学艺不精,没有解决,但是找到了报错的问价, 故而,在循环之时提出该600209和600193两个文件,由后续人为输入
将提取出的每股净收益放入DataFrame中,改变索引,输出为excel文件如下
#循环提取每股收益
df_profit = pd.DataFrame()
path = 'F:\\python大数据挖掘与处理\\homework\\a_zuoye\\分类'
os.chdir(path)
wenjian = os.listdir(path)
wenjian = wenjian[:7]+wenjian[9:]#由于wenjian[7:8]对应的股票年报报错,所以剔除
for info in wenjian:
domain = os.path.abspath(path) #获取文件夹的路径
info = os.path.join(domain,info) #完整路径
ste = info[-6:]#将公司名称赋给st3
filenames = os.listdir(ste)#获取各个公司文件夹中pdf文件的名称
profit = []
for pdf in filenames:
i=0
df1 = pd.DataFrame()
pdf = "\\"+pdf
x = "F:\\python大数据挖掘与处理\\homework\\a_zuoye\\分类\\"+ste+pdf#形成路径链接(直接用pdf会打不开)
profit_gain = profit_data_line(x)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
df1.insert(i, ste, profit)
i=i+1
df_profit = df_profit.join(df1, how='outer')
print('循环结束')
os.chdir('F:\\python大数据挖掘与处理\\homework\\a_zuoye')
index2 = ['2021每股收益','2020每股收益','2019每股收益','2018每股收益','2017每股收益',\
'2016每股收益','2015每股收益','2014每股收益','2013每股收益','2012每股收益']
df_profit_T = pd.DataFrame(df_profit.values.T,columns=index2,index=df_profit.columns)
df_profit_T.to_excel('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\profits.xlsx')
#由于未能找到解决办法,后续将该两个股票对应的每股收益认为人为补充
每股净收益结果
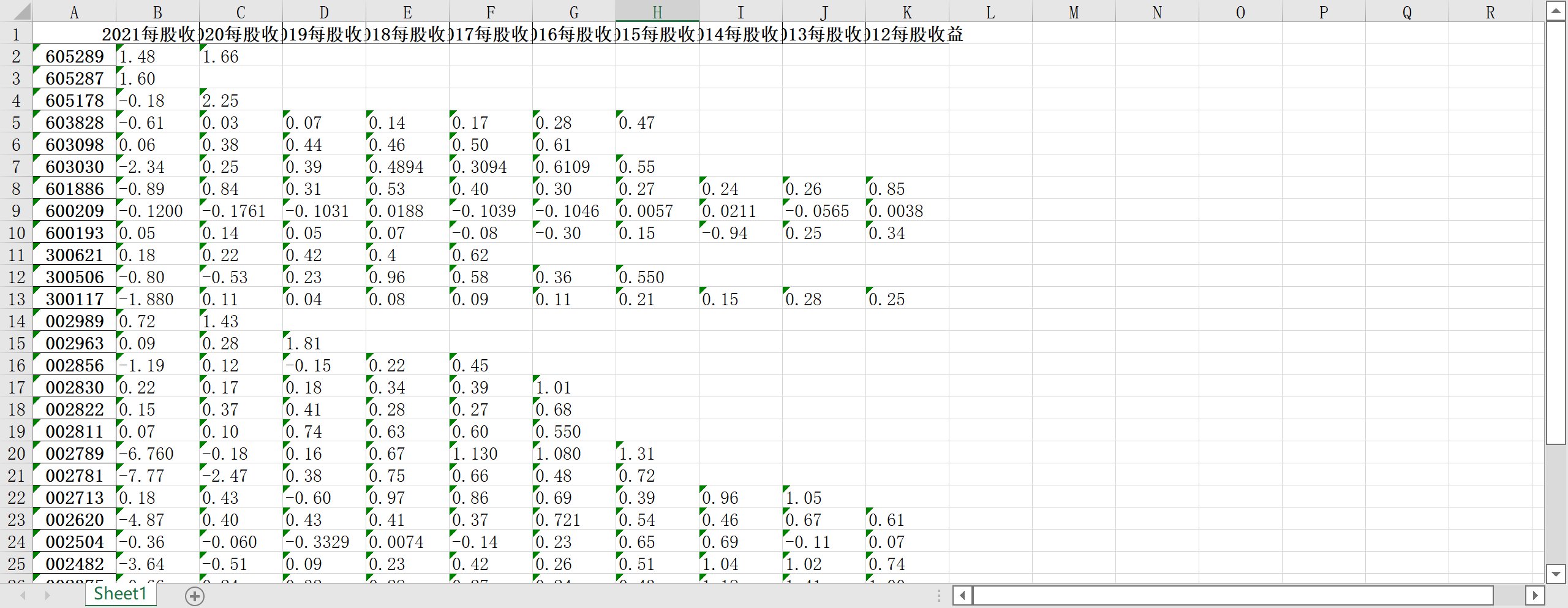
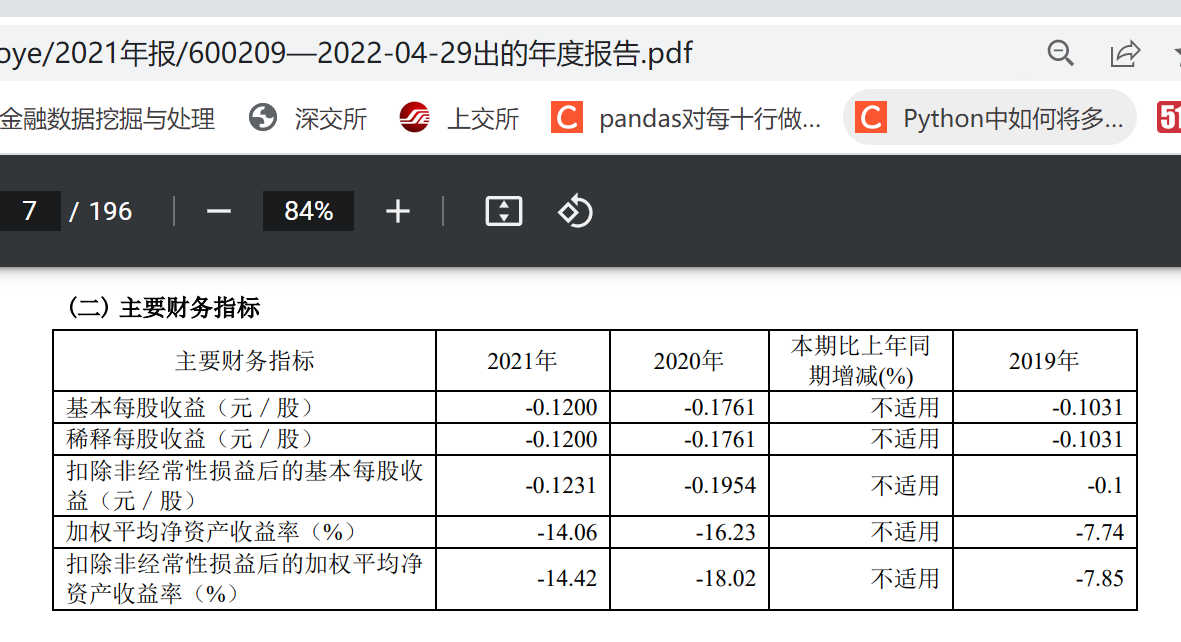
查找错误时发现该两个公司的每股收益与众不同,细看下图(示例为600209的2021年年报)
循环提取公司办公地址和公司网址,内含正则表达式,可以成功匹配我所下载的所有年报, 分别存入两个csv文件中,因为每年公司的办公地址和公司网址都没有变化,故而将每个公司最新的年报提取至2021年报文件夹中 如下
#提取办公地址,公司网址(同时)
index_site = dmjc['证券代码'].drop_duplicates()
index_web = dmjc['证券代码'].drop_duplicates()
df_site = pd.DataFrame()#创建一个空表格
df_web = pd.DataFrame()#创建一个空表格
filenames = os.listdir('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\2021年报')
site = []
web = []
for pdf in filenames:
i=0
df2 = pd.DataFrame()#创建一个空表格
df3 = pd.DataFrame()
pdf = "\\"+pdf
x = "F:\\python大数据挖掘与处理\\homework\\a_zuoye\\2021年报"+pdf#形成路径链接(直接用pdf会打不开)
text =getText(x)
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
site1 = p_site.search(text).group(0)
site.append(site1)
p_web = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
web1 = p_web.search(text).group(0)
web.append(web1)
df2.insert(i,'办公地址' , site)#以列为单位加入表格
df3.insert(i,'网址', web)
i=i+1
df_site = df_site.join(df2, how='outer')
df_web = df_web.join(df3, how='outer')
df_site.index =index_site
df_web.index =index_web
df_site.to_csv('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\sites.csv')
df_web.to_csv('F:\\python大数据挖掘与处理\\homework\\a_zuoye\\webs.csv')
‘2021年报’文件夹内部如下
办公地址结果

公司网址结果

分别按行按列提取数据,方便后续画图
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib.pyplot import MultipleLocator
import os
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#导入营业收入数据,并分别按行提取和按列提取数据
csv_data1 = pd.read_csv("sales.csv")
csv_df1 = pd.DataFrame(csv_data1)
csv_df_new1 = csv_df1.iloc[21:,1:]#得到包含前十家公司不同年份营业收入的表格
csv_df_new2 = csv_df1.iloc[21:,]#含股票代码
csv_df_new1.reset_index(drop=True)
list_row = csv_df_new1.values.tolist()#以行为单位取成列表,每个列表是十年同一公司的营业收入
list_name = csv_df_new2['股票代码']#取索引
print(list_name)
columns = list(csv_df_new1)
list_columns = []#以列为单位取的列表,每个都是每一年十家公司的营业收入
for c in columns:
d = csv_df_new1[c].values.tolist()
list_columns.append(d)#以列为单位取成列表
结果如图

将数据转化为浮点数据
#将数据转化为以亿元为单位的浮点数
def change_type(list_x):
list_want=[]
for i in range(len(list_x)):
x_a = []
for j in range(len(list_x[1])):
a_a = list_x[i][j]
a_b = a_a.replace(",","")#将字符串中的,替换为空格
a_c = float(a_b)
a_d = a_c / 10**8#将数值缩小为亿分之一,便于在后续图标上展示
a_e = round(a_d,2)#保留两位小数
x_a.append(a_e)
list_want.append(x_a)
return(list_want)
list_row_1 = change_type(list_row)
list_columns_1 = change_type(list_columns)
os.chdir('..\\')#为了后续将图片保存在父文件夹中
name_list = ['2021',"2020","2019","2018","2017","2016","2015","2014",'2013','2012']
list_name_1 = ['002620','002504',"002482","002375",'002325',"002323","002163","002081","002047",'900939']
def y_ticks(list_row,list_name_1):
num_list_1 = list_row
rects = plt.barh(range(len(list_row)),num_list_1,color='rgby')
N = 10
index = np.arange(N)
plt.yticks(index,name_list)
plt.title(list_name_1+" 2012—2021营业收入对比")
plt.xlabel("年份")
plt.ylabel("营业收入(亿元)")
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(list_name_1 +".png",dpi = 600)
plt.show()
for i in range(len(list_row)):
y_ticks(list_row_1[i], list_name_1[i])
结果
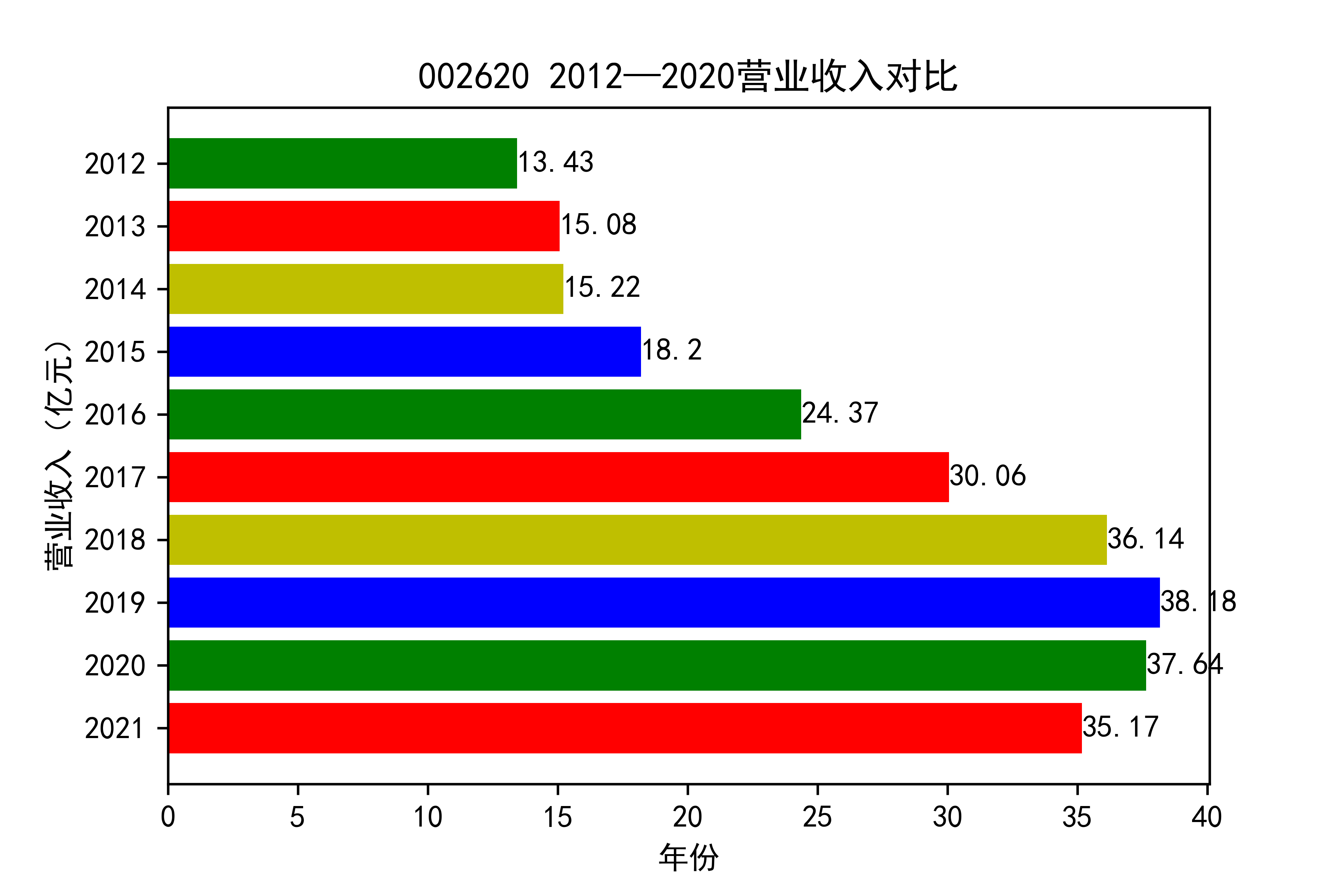
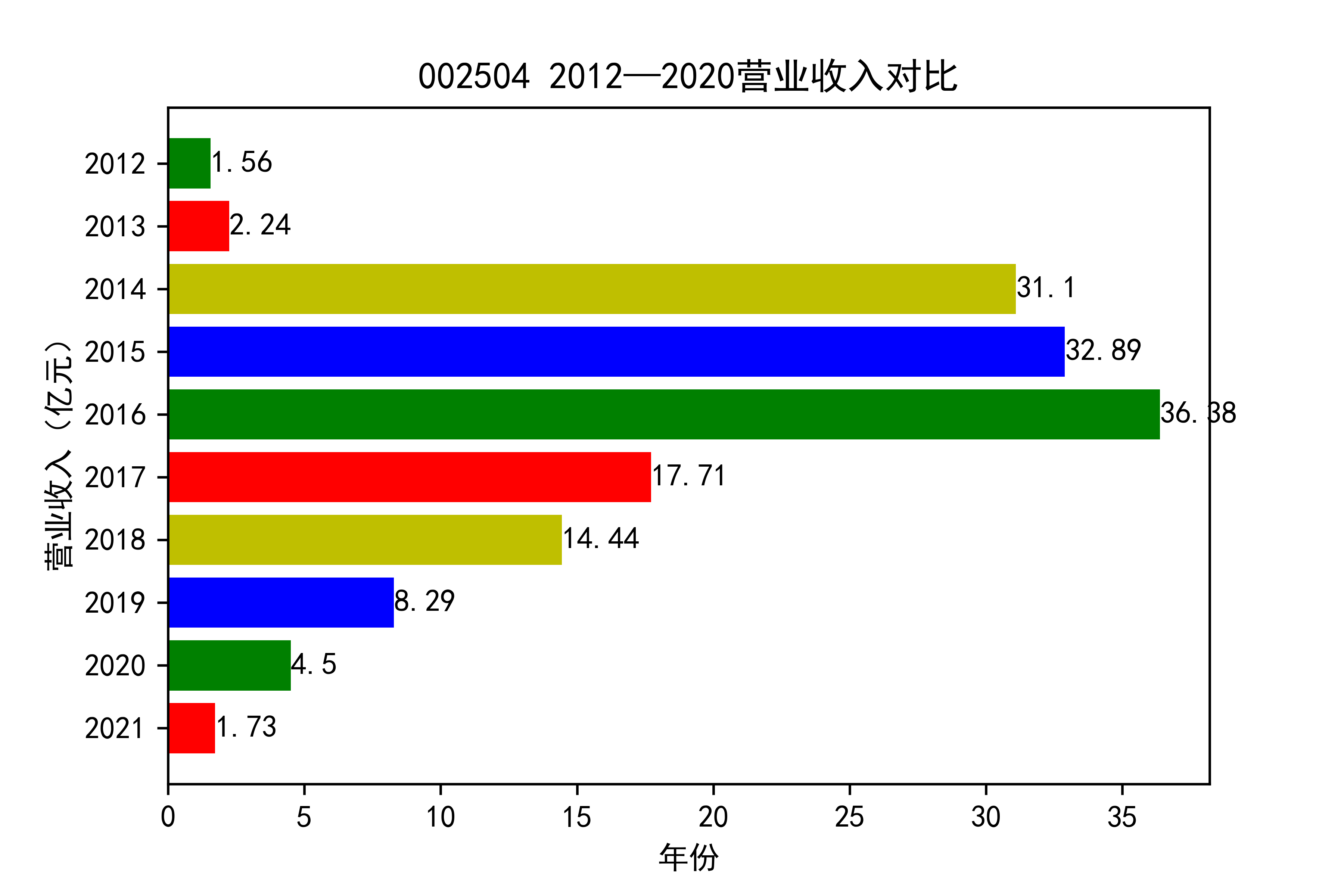
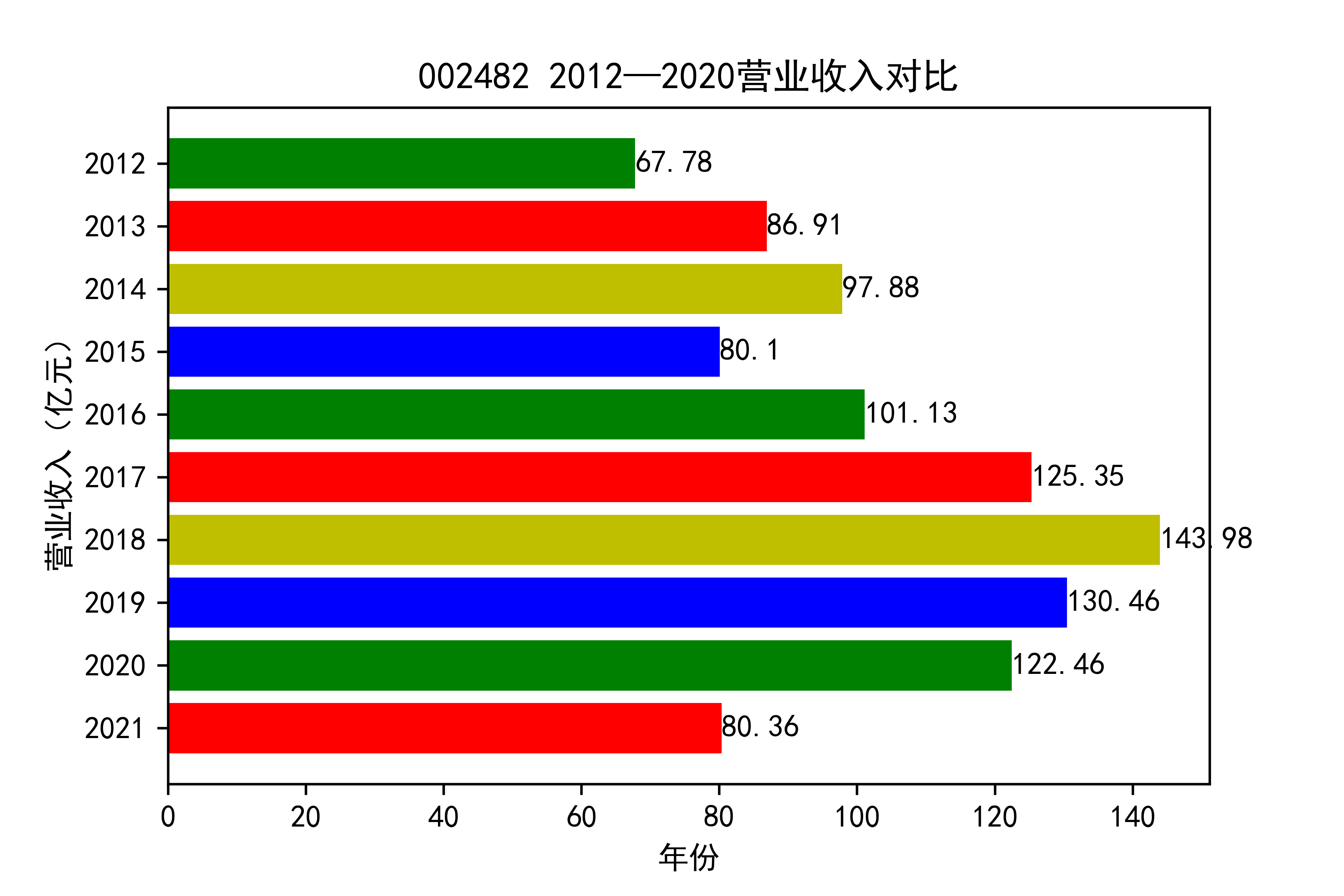
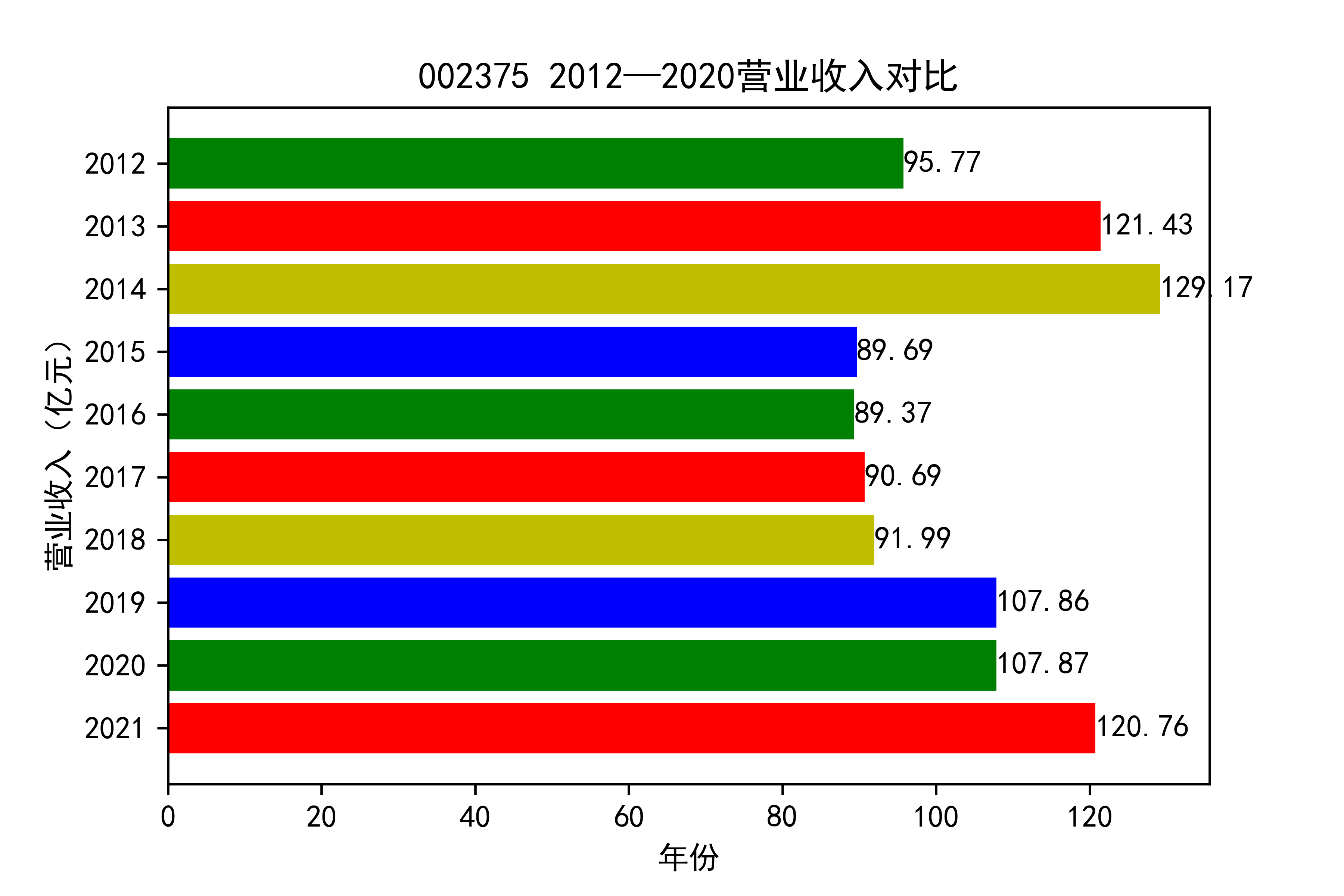
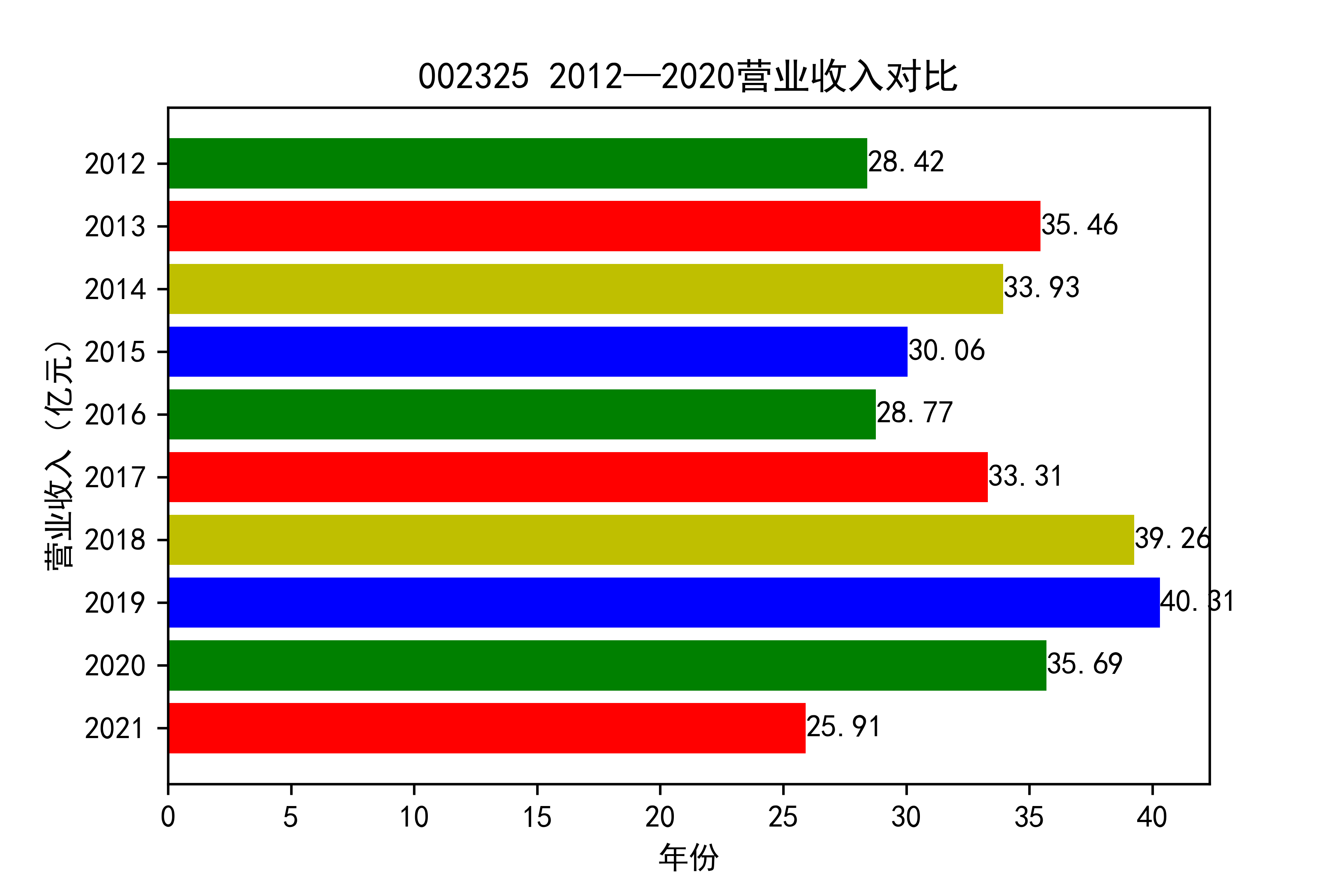
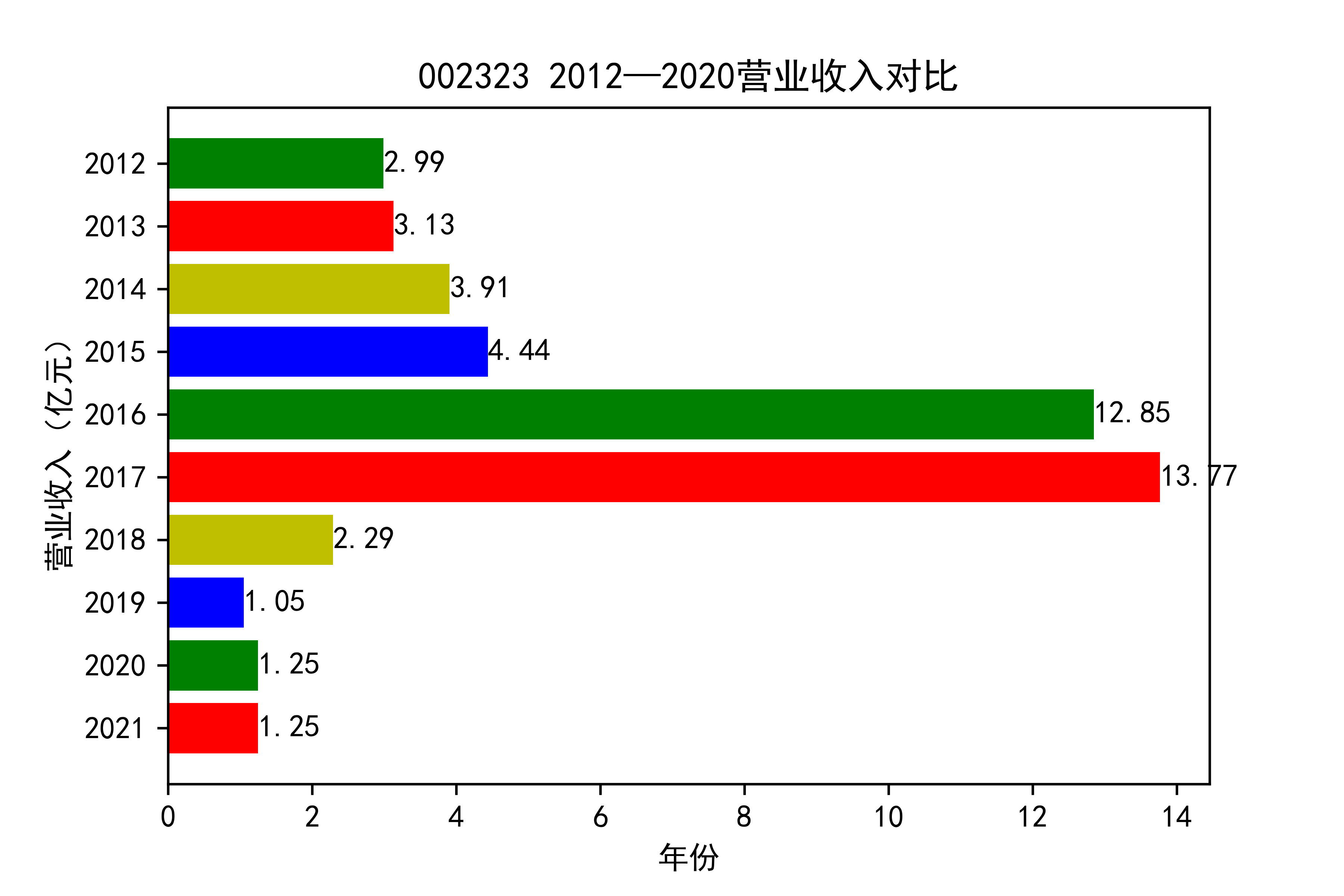

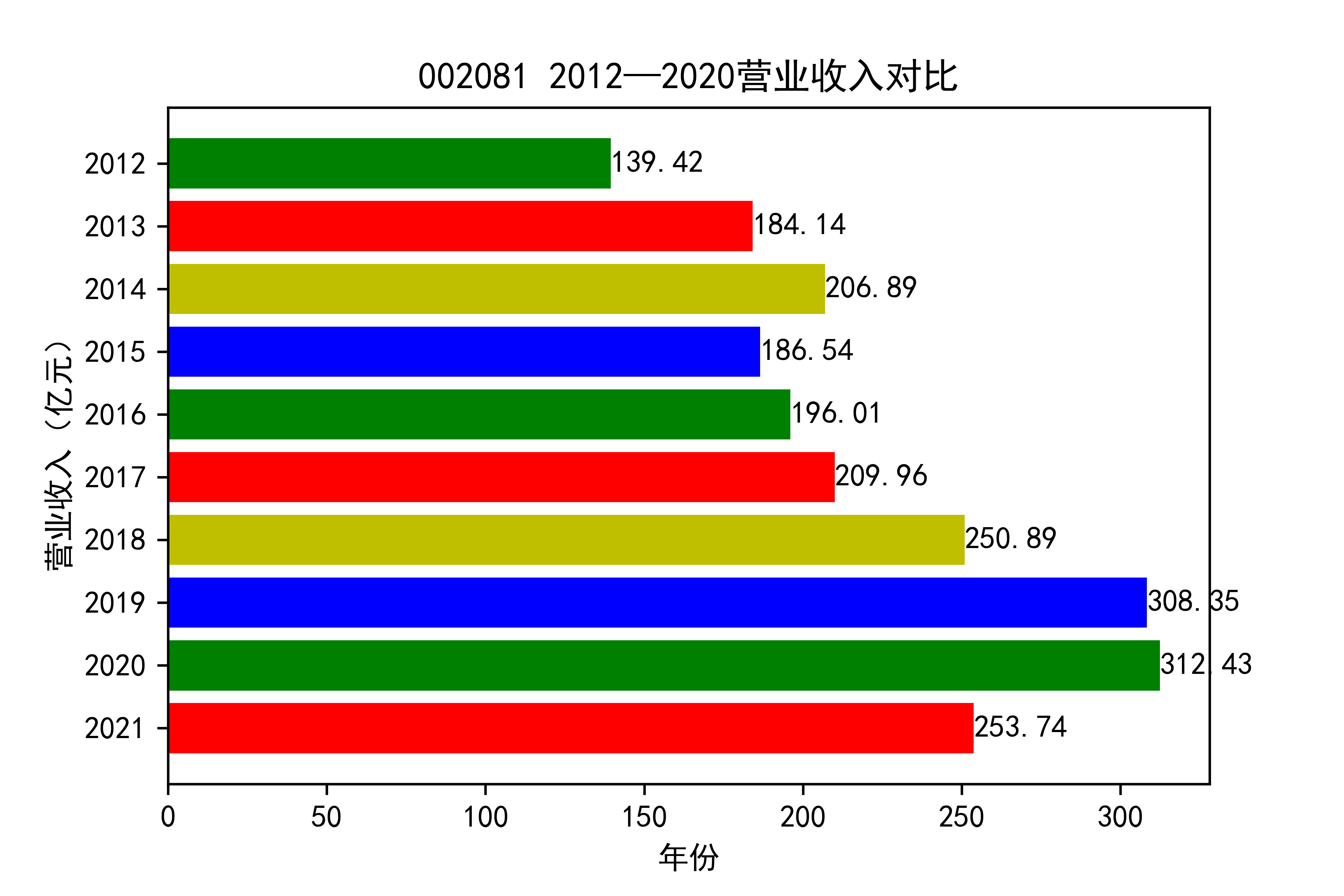

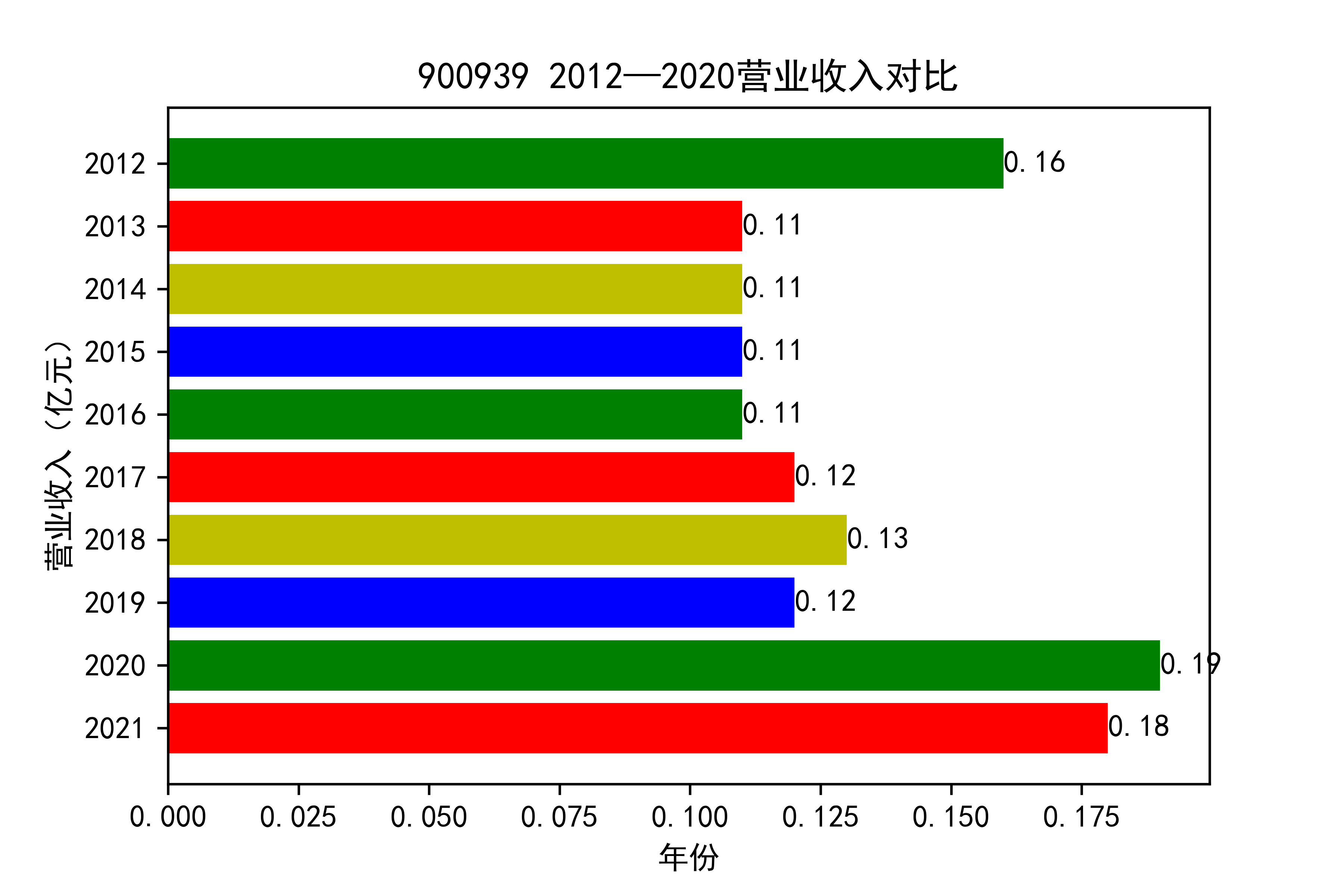
从各个公司的营业收入图来看,可以看出从2012年到2021年大部分公司呈现营业收入先增后减的趋势, 个别公司如002375和900939对应的两家公司,恰好呈现出在两端(即2012和2021年附近)高于中间的情况。
整体情况来看,建筑装饰业这整个行业都处于一种先繁荣发展再受到疫情的强烈冲击的状态 。
于2013年开始我国建筑市场经历了上升期,营业收入稳步上涨,虽然在后期期又出现暴跌现象, 但2019年疫情来临,带来的时经济的不景气,整个市场都出现低迷状态,少有的两家公司反而出现了上涨的趋势。 引人注意,去搜查过资料后发现,002375亚夏股份市场在于装配式内装放量,商业化运营日渐成熟,准备进入快速发展阶段 900939汇丽B主营业务以厂房租赁和地板贸易业为主,未明显受疫情的冲击。
建筑装饰行业未来的发展,还需要看其能不能度过疫情这个难关,前景扑朔迷离,有待进一步的观察。
def x_ticks(list_columns,name_list):
num_list = list_columns
rects = plt.bar(range(len(list_columns)),num_list,color="rgb",width = 1,tick_label=list_name_1)
plt.title(name_list+"不同公司营业收入对比")
plt.xlabel("营业收入(亿元)")
plt.ylabel("公司名称")
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(name_list +".png",dpi = 600)
plt.show()
for i in range(len(list_columns)):
x_ticks(list_columns_1[i], name_list[i])
结果

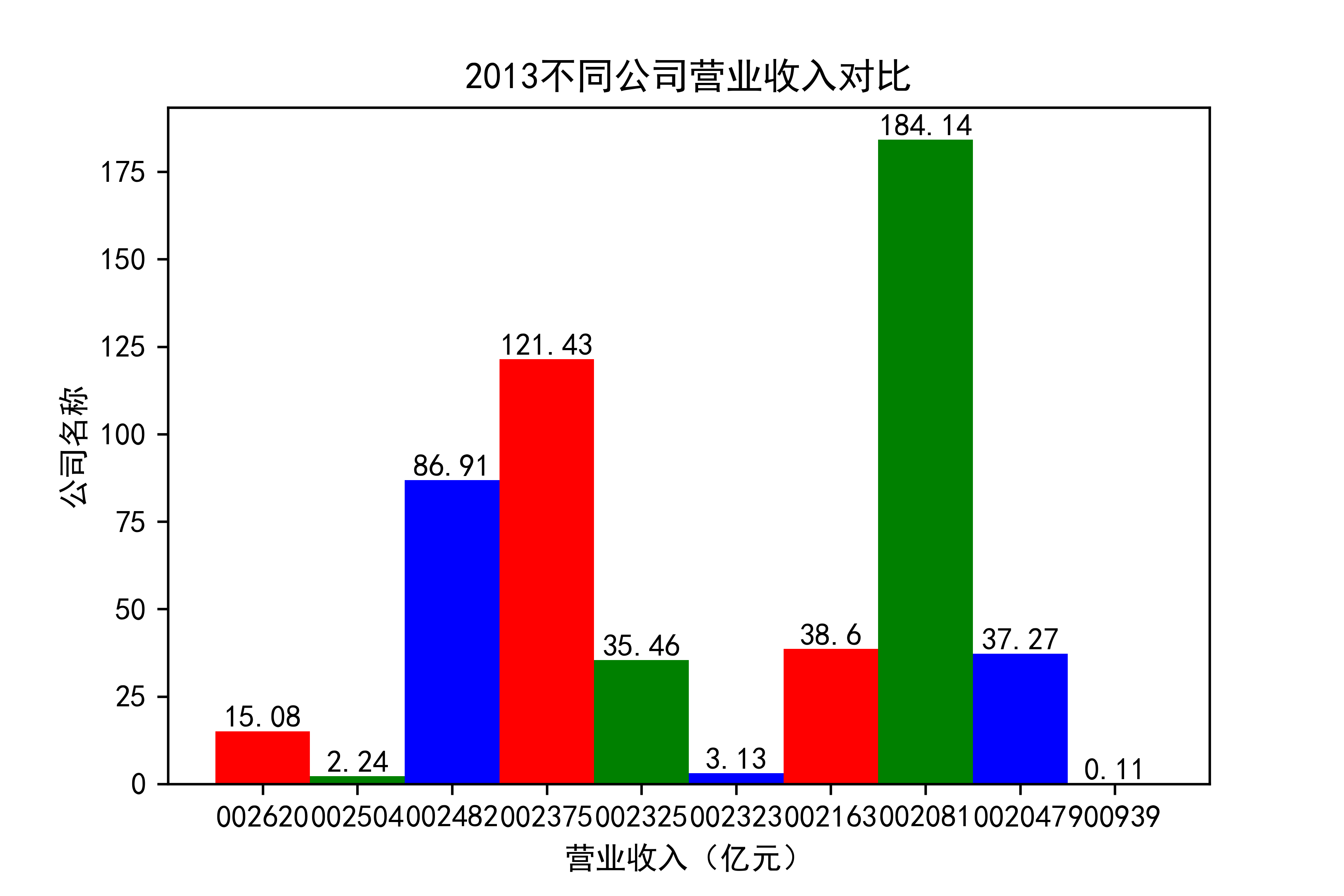
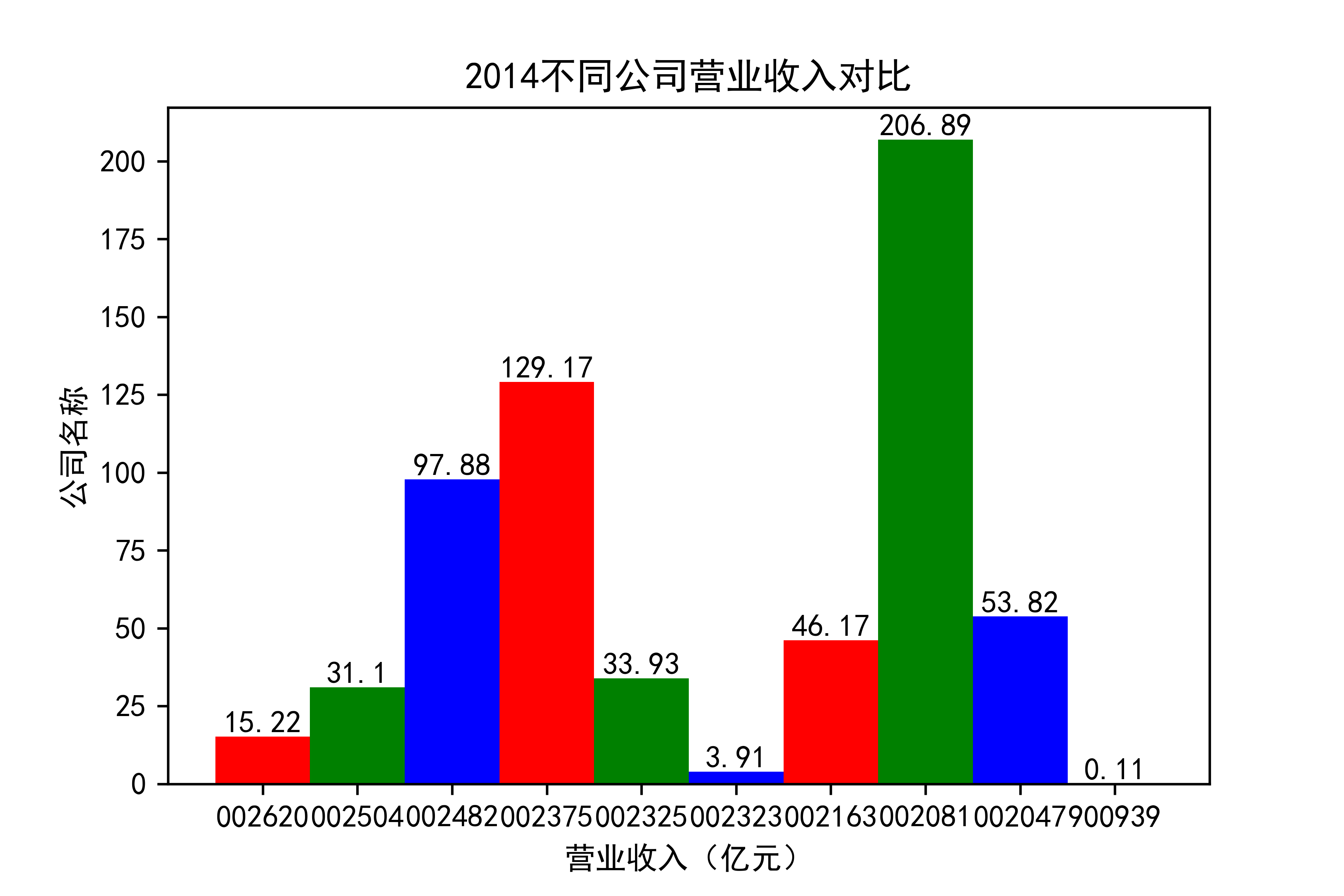


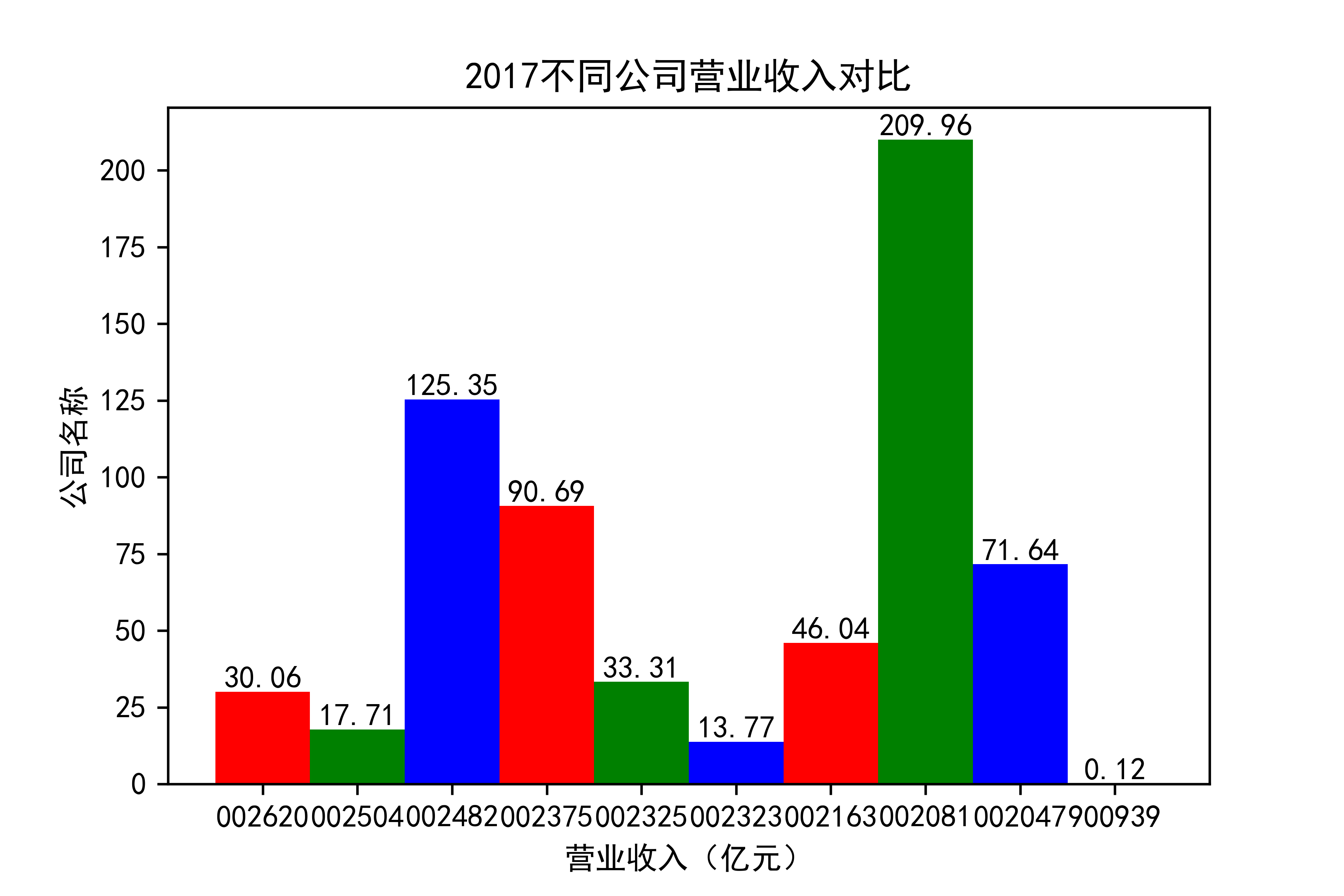
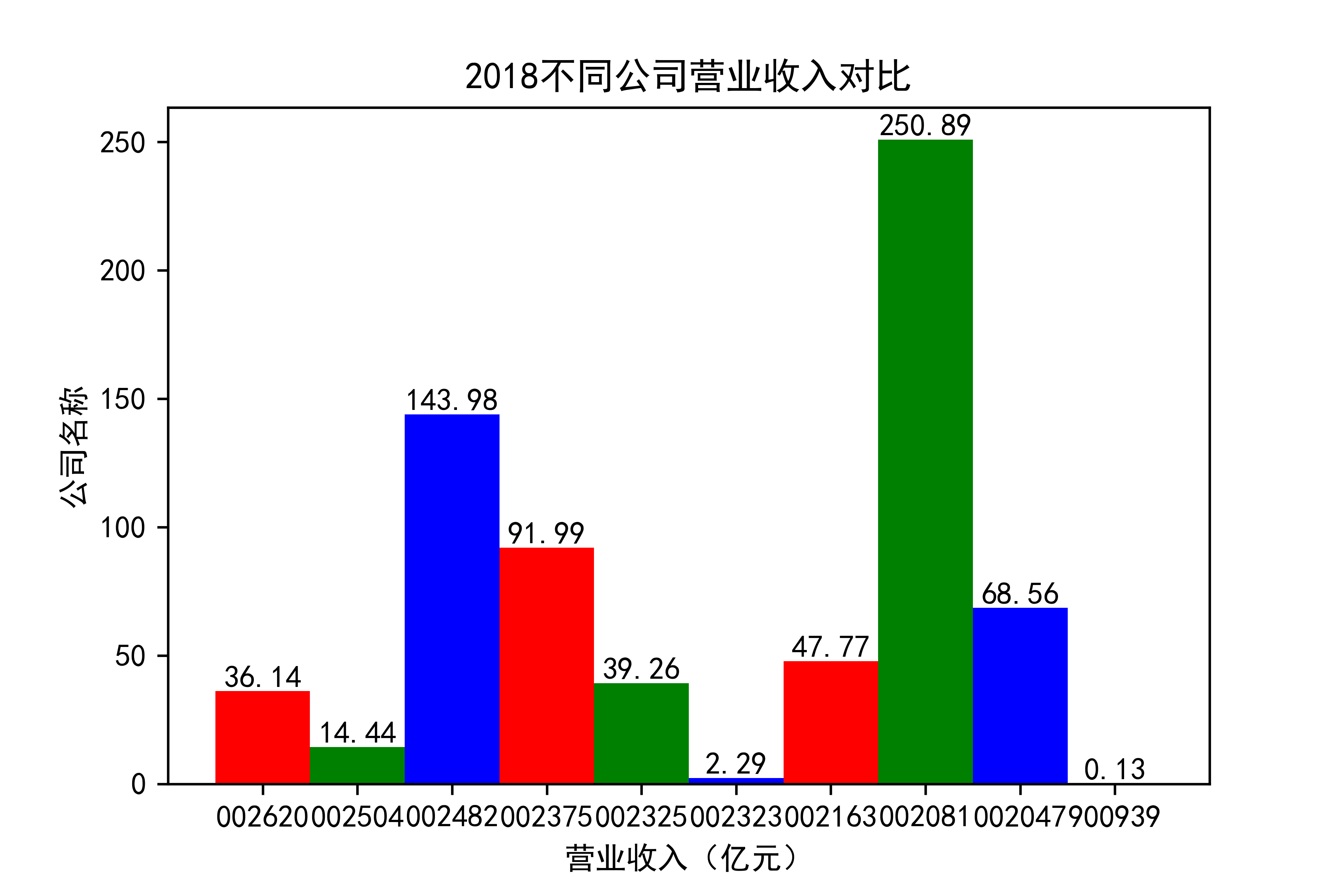

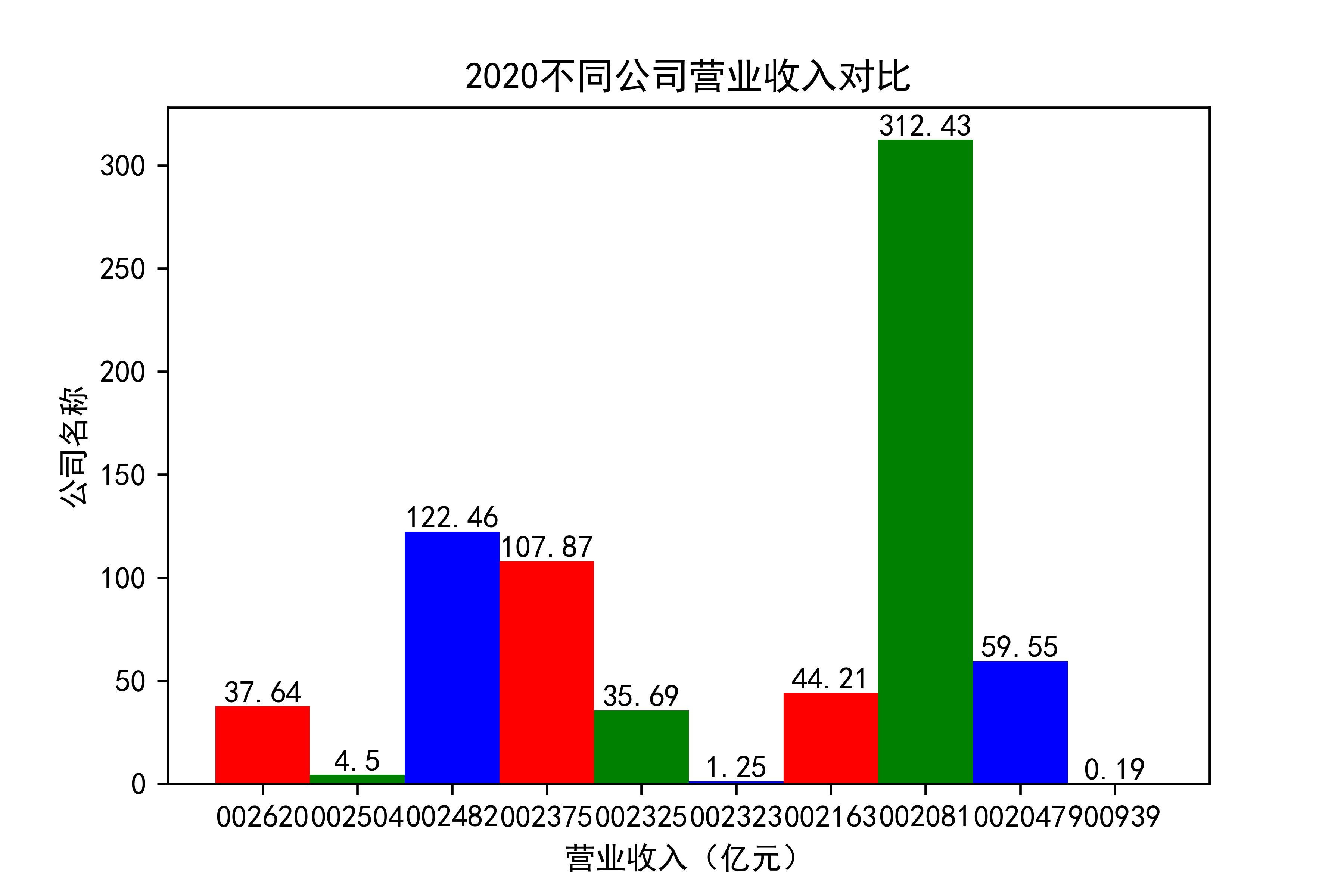

观察每年行业的大致情况,发现行业内部的参差很大,龙头效应似乎很明显。行业龙头遥遥领先。但小企业也在不断发展提升自己。
抓住产业升级趋势,推动渠道多元化。受新冠疫情影响,住宅装修量大幅下滑,完全依靠家装渠道 的装饰公司在业绩方面普遍受到冲击。反观项目中公装占比较高的装饰公司,比如002081金螳螂,仍然保持了较为稳健的经营状态。 由此不难看出,相比于坚守一个赛道,企业抓住产业升级趋势,走多元化发展道路,对于 公司抵御风险以及长远发展,都有着非常重要的作用。
os.chdir('..\\')#为了后续将图片保存在父文件夹中
csv_data2 = pd.read_excel('profits.xlsx')
csv_profit1 = pd.DataFrame(csv_data2)
csv_profit_new1 = csv_profit1.iloc[-10:,1:]#得到包含前十家公司不同年份每股收益的表格
csv_profit_new2 = csv_profit1.iloc[-10:,]#含股票代码
csv_profit_new1.reset_index(drop=True)
list_row_profit = csv_profit_new1.values.tolist()#以行为单位取成列表,每个列表是十年同一公司的每股收益
list_name_profit = csv_profit_new2['股票代码']#取索引
print(list_name_profit)
columns1 = list(csv_profit_new1)
list_columns_profit = []#以列为单位取的列表,每个都是每一年十家公司的营业收入
for c in columns1:
d = csv_profit_new1[c].values.tolist()
list_columns_profit.append(d)#以列为单位取成列表
name_list = ['2021',"2020","2019","2018","2017","2016","2015","2014",'2013','2012']
list_name_1 = ['002620','002504',"002482","002375",'002325',"002323","002163","002081","002047",'900939']
def y_ticks2(list_row_profit,list_name_1):
num_list_1 = list_row_profit
rects = plt.barh(range(len(list_row_profit)),num_list_1,color='rgby')
N = 10
index = np.arange(N)
plt.yticks(index,name_list)
plt.title(list_name_1+" 2012—2021每股净收益对比")
plt.xlabel("年份")
plt.ylabel("每股净收益(元)")
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(list_name_1 +"净收益.png",dpi = 600)
plt.show()
for i in range(len(list_row_profit)):
y_ticks2(list_row_profit[i], list_name_1[i])
结果
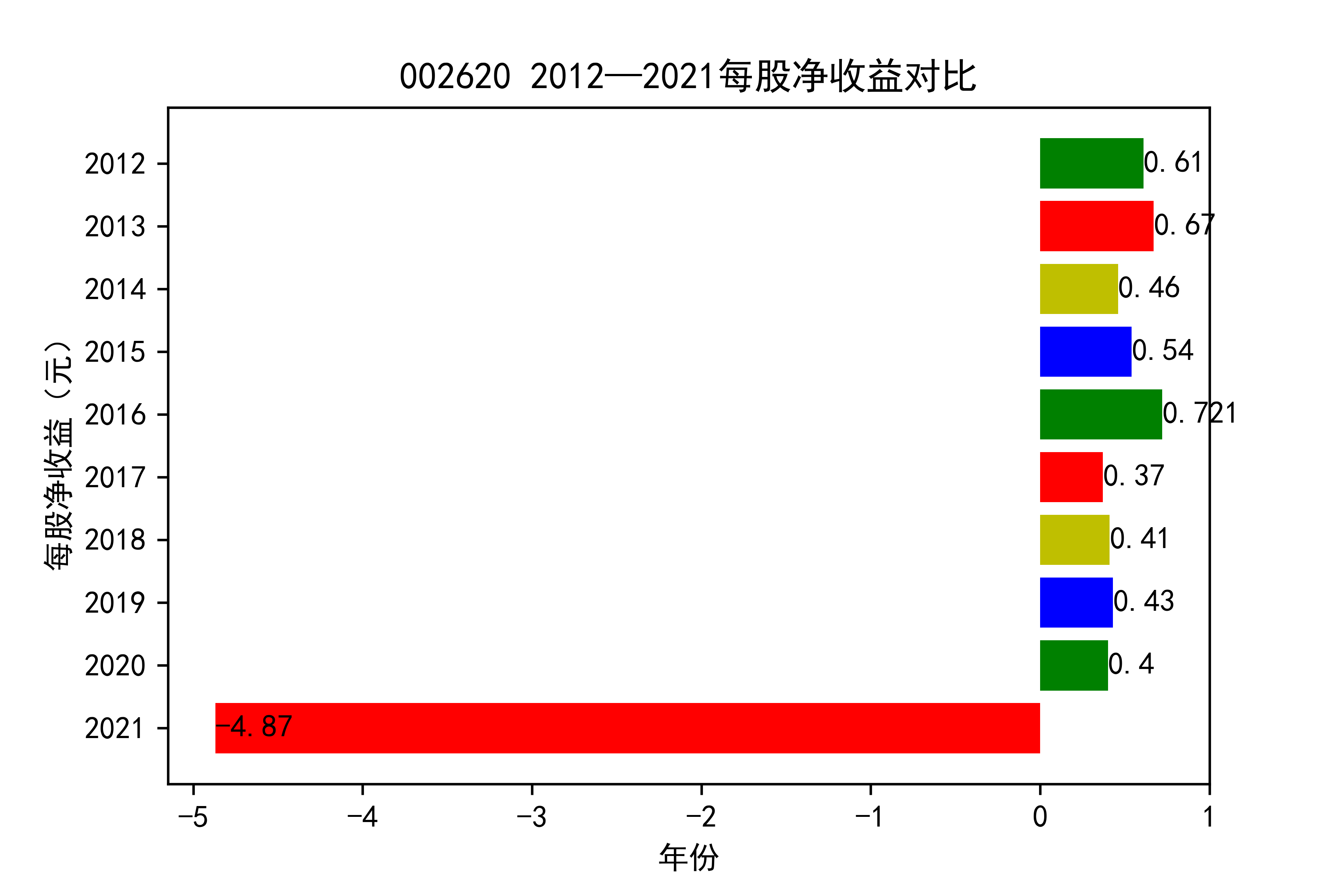
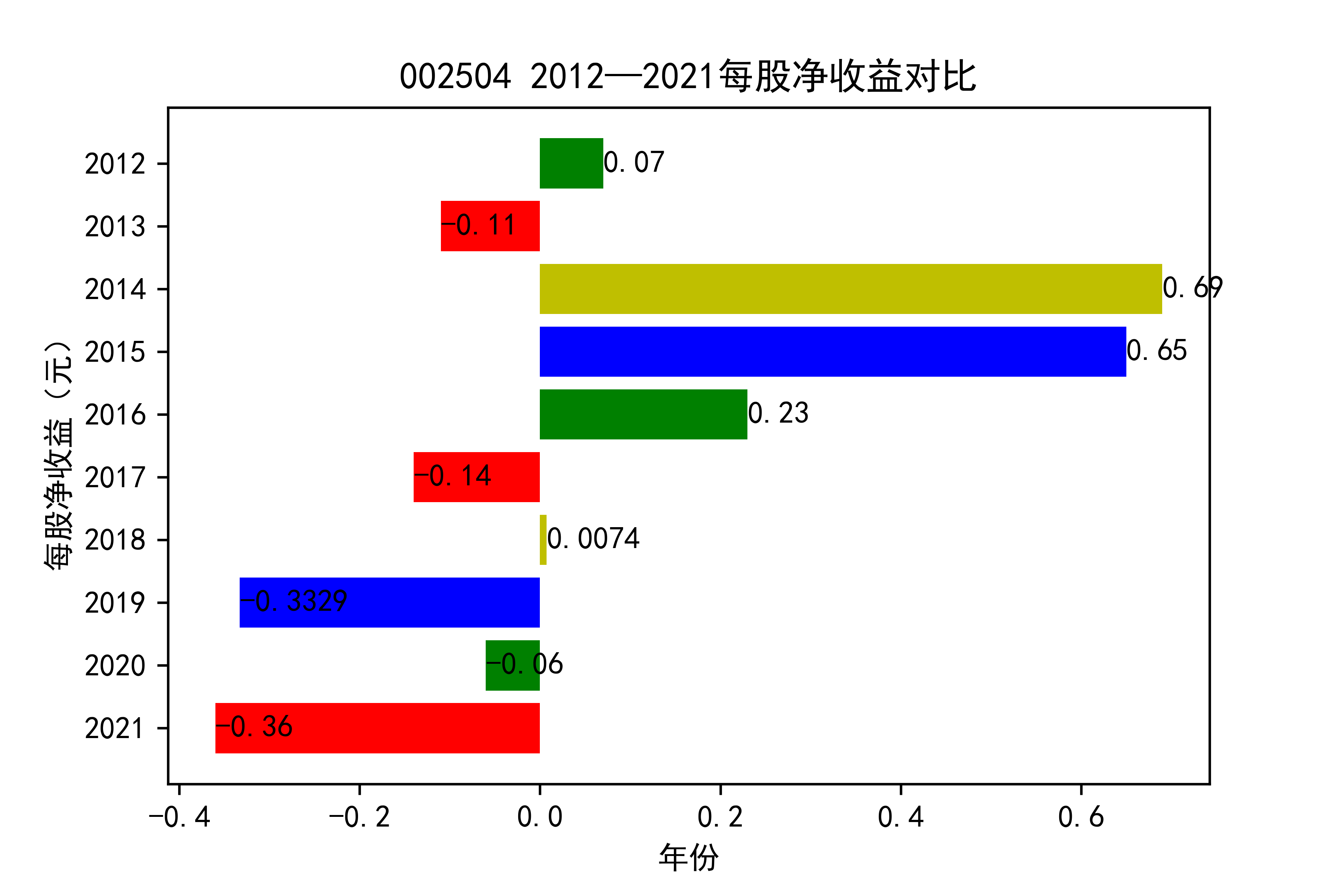
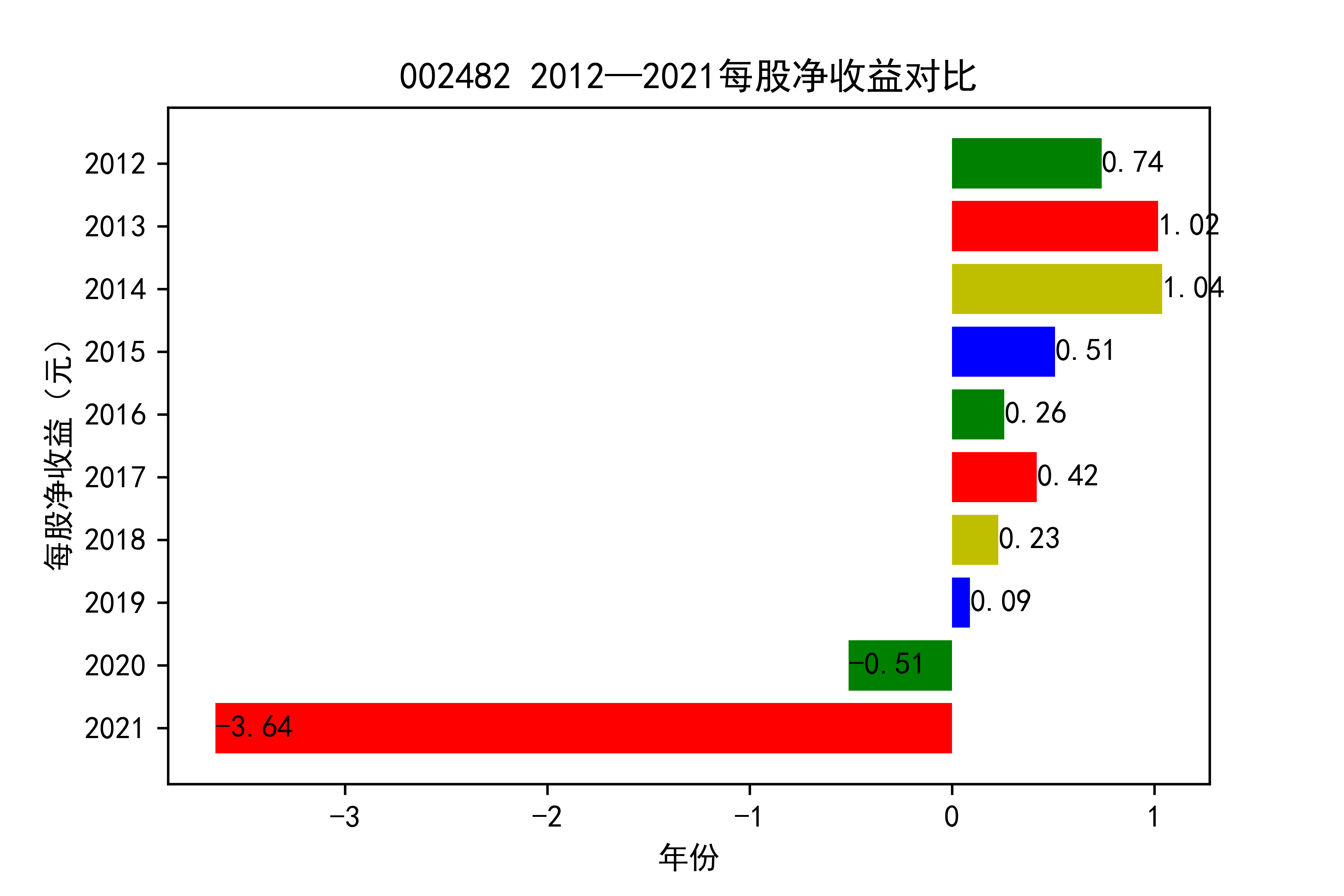
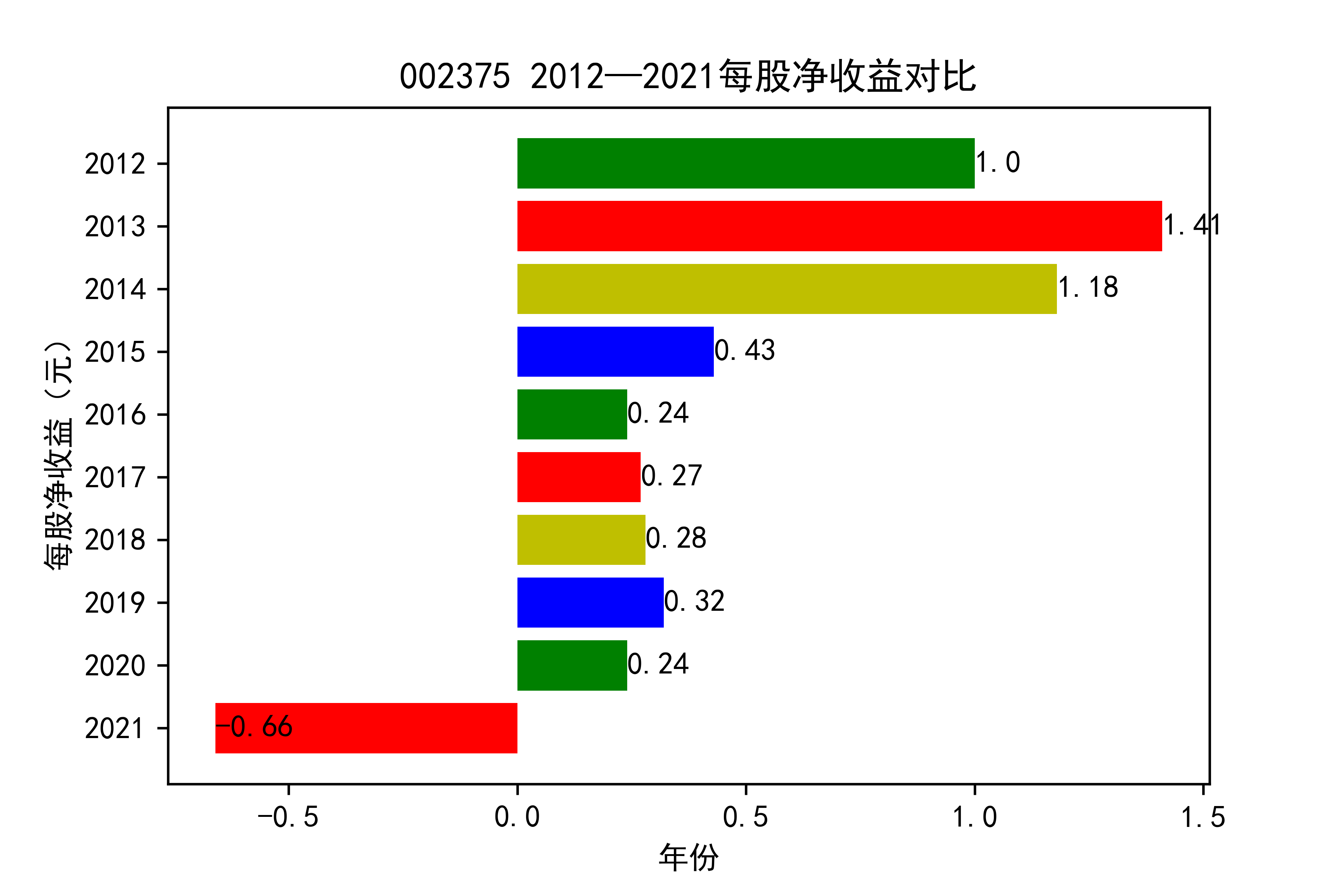
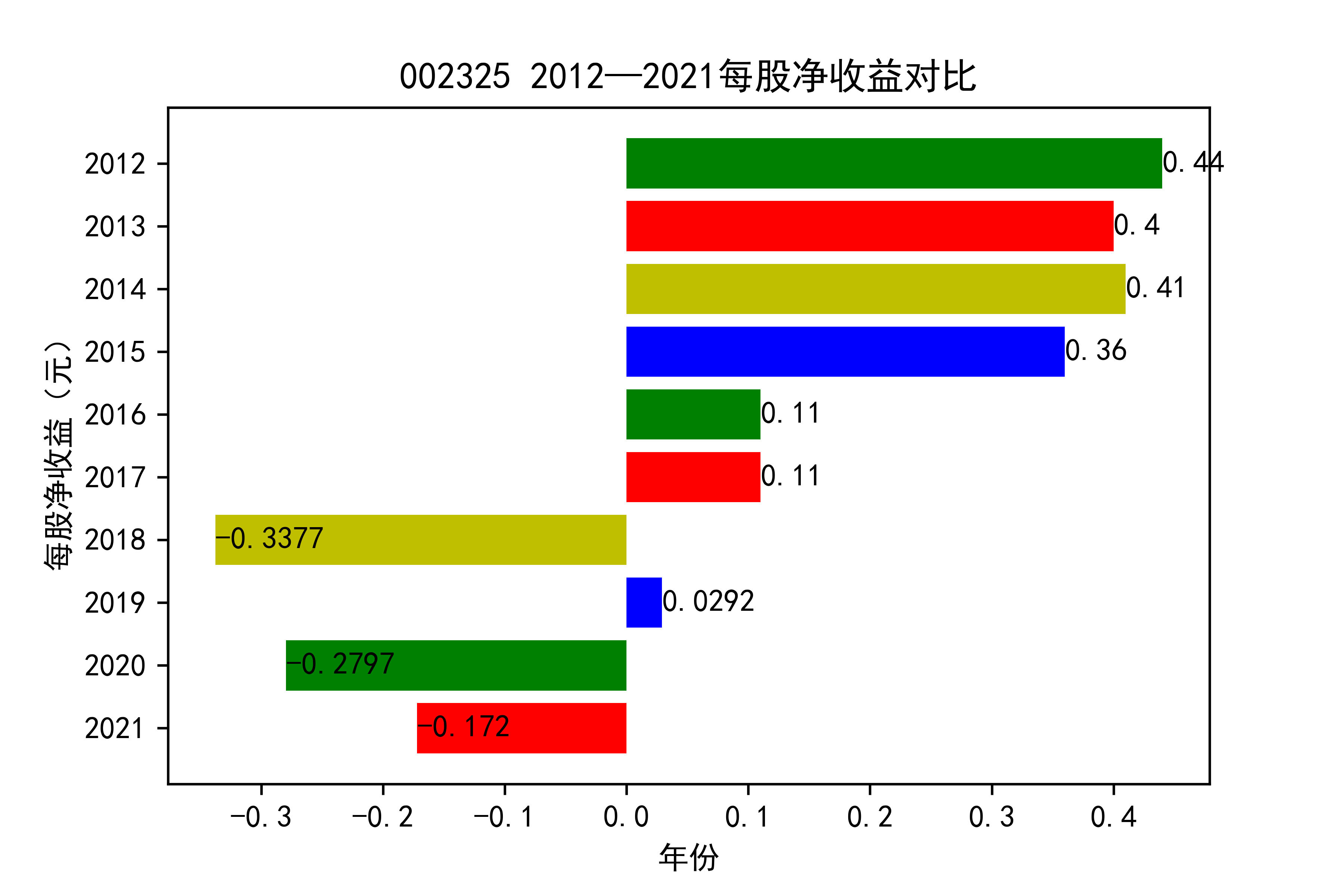
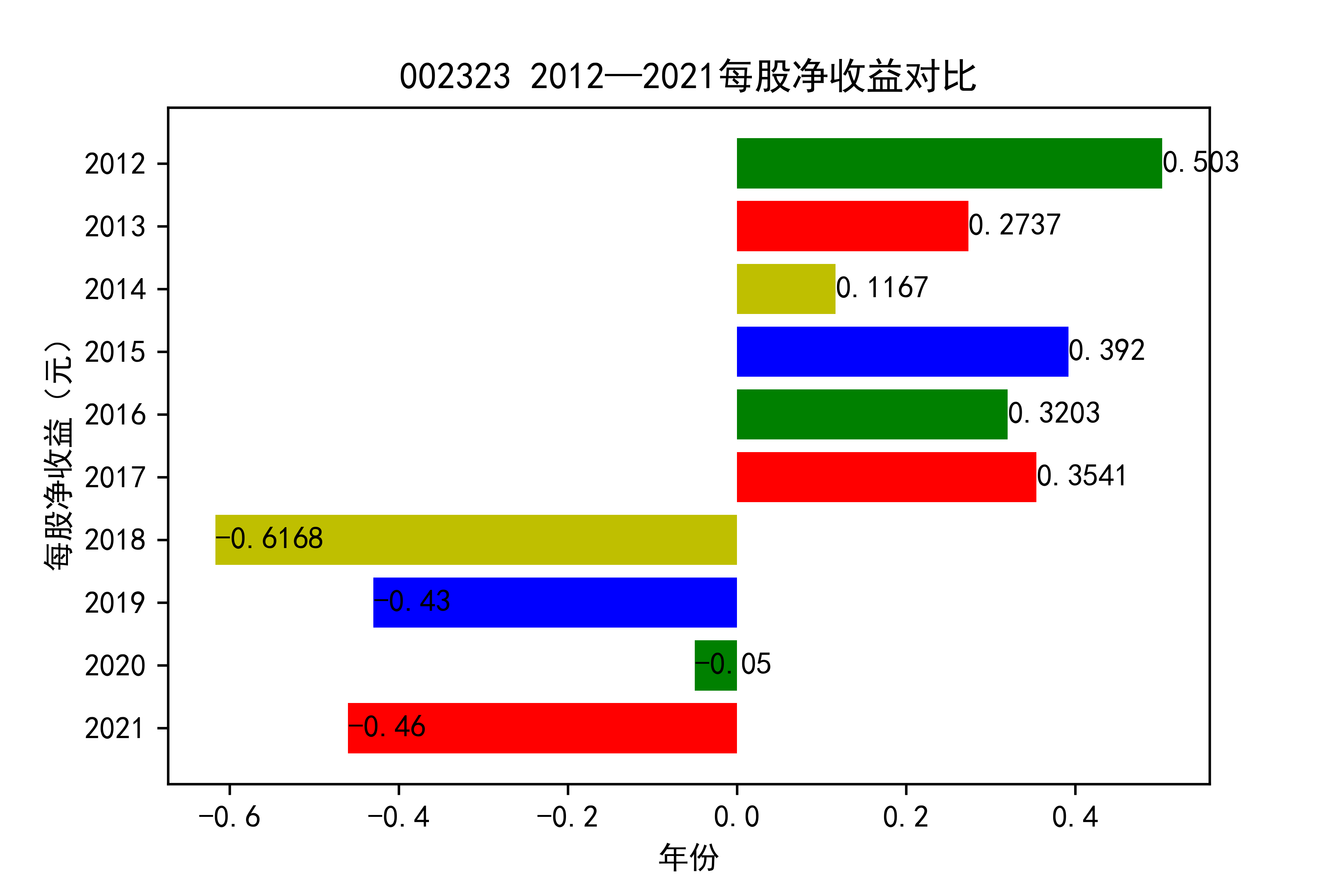
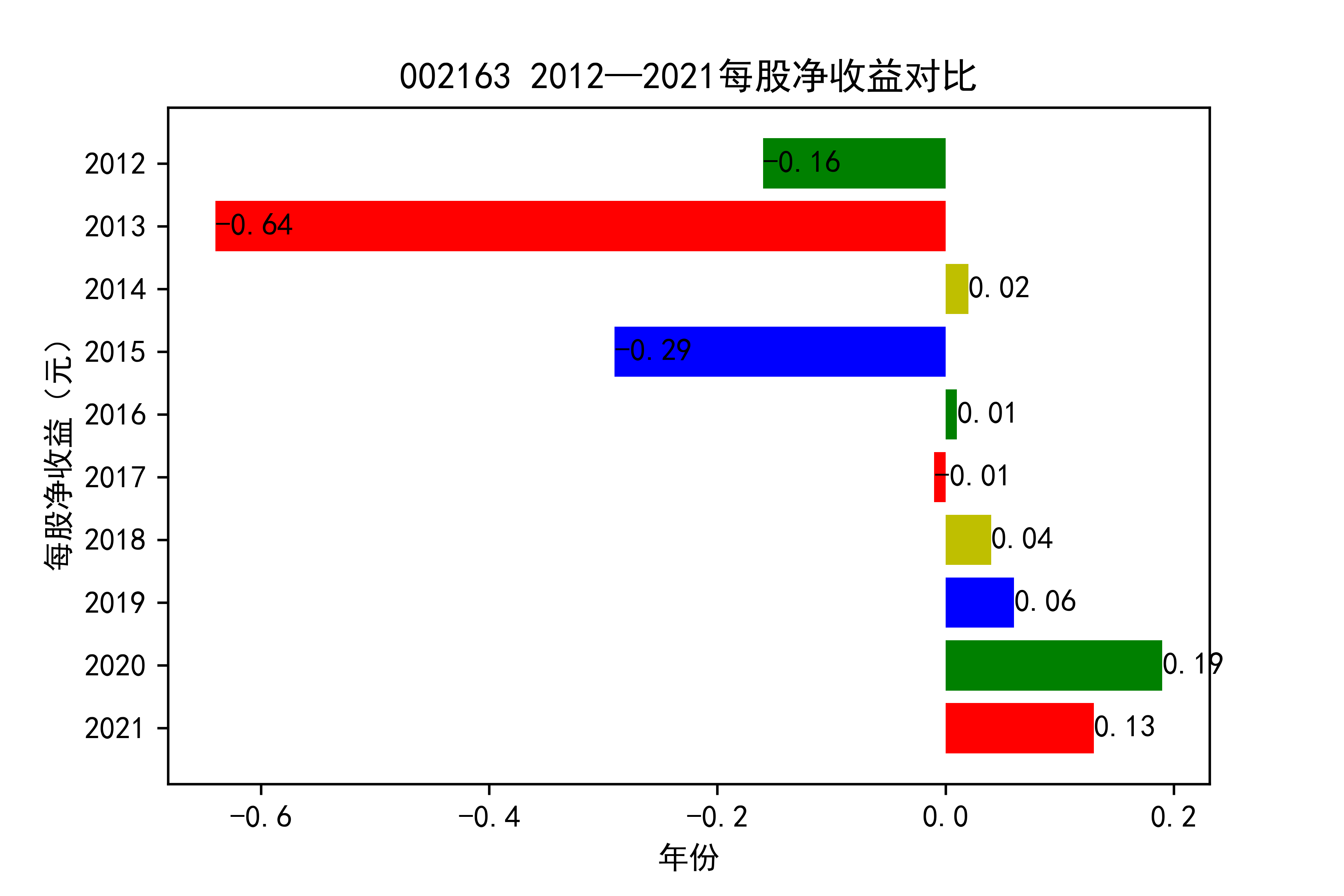
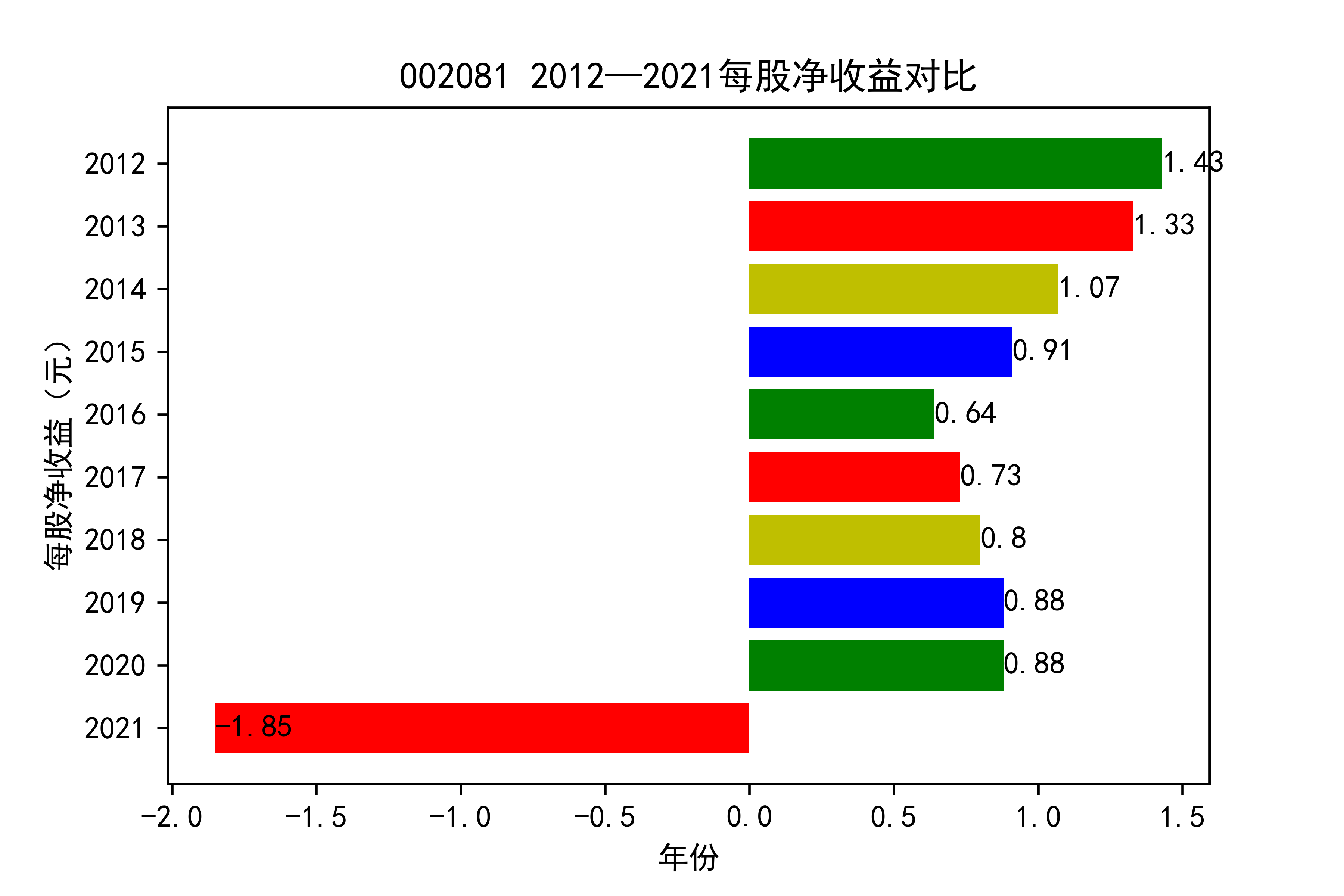

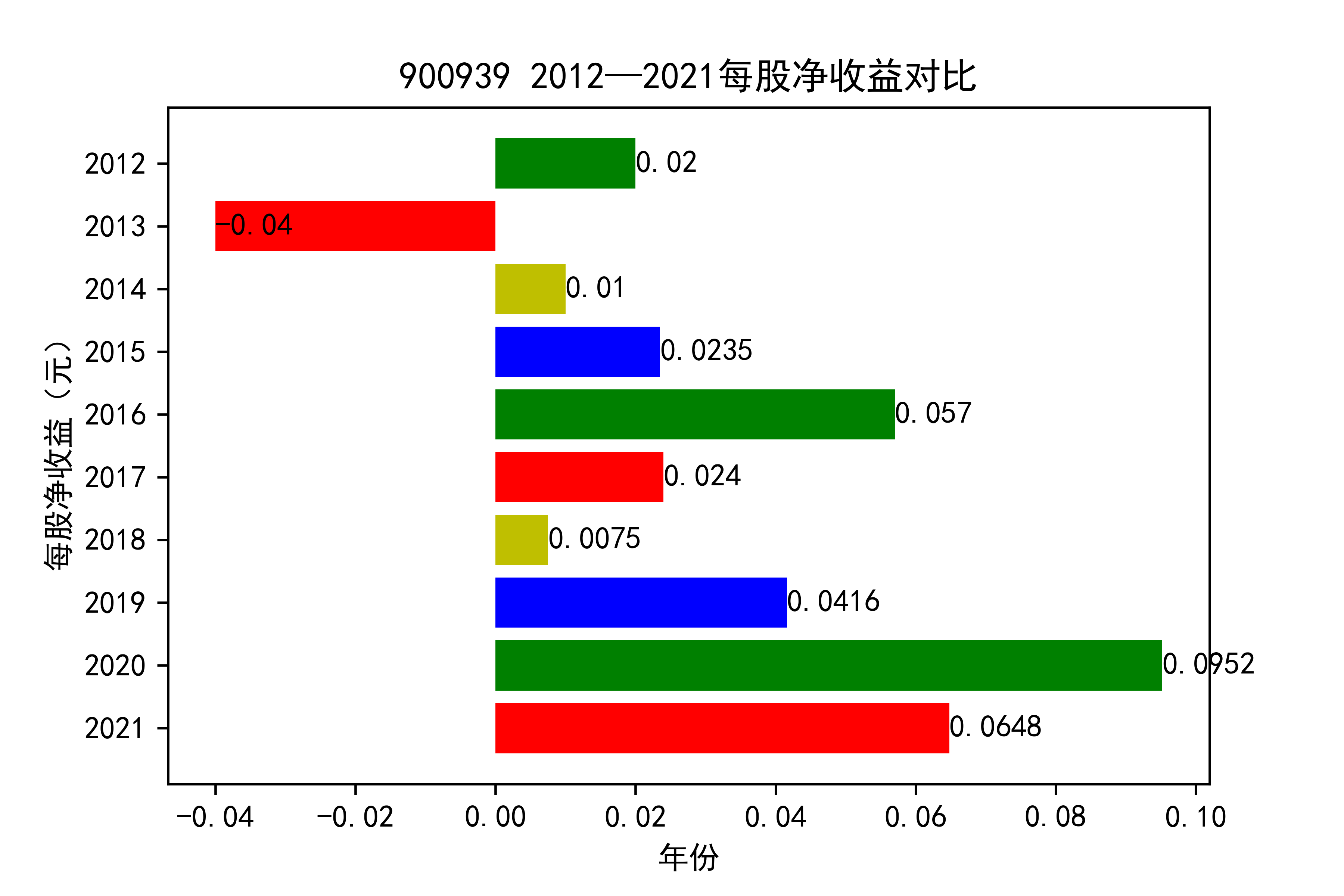
从各个公司的每股收益图来看,可以看出从2012年到2020年大部分公司呈现每股收益大多是大于零的, 个别公司在2021年以前也处于每股收益为负的情况,可能是受到了其他因素影响,但是从2021年骤然下降的情况不在少数, 说明整个行业普遍受到了疫情的强烈冲击。
对于每家公司,每股收益的波动都比较大,可以推断该行业容易受各种外界因素影响。且每股收益呈现下降趋势,说明该行业暂时经济不太乐观。但 但以后的发展趋势还需要继续观察,无法得出结论。
def x_ticks2(list_columns_profit,name_list):
num_list = list_columns_profit
rects = plt.bar(range(len(list_columns_profit)),num_list,color="rgb",width = 1,tick_label=list_name_1)
plt.title(name_list+"不同公司每股净收益对比")
plt.xlabel("每股净收益(元)")
plt.ylabel("公司名称")
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(name_list +"净收益.png",dpi = 600)
plt.show()
for i in range(len(list_columns_profit)):
x_ticks2(list_columns_profit[i], name_list[i])
结果
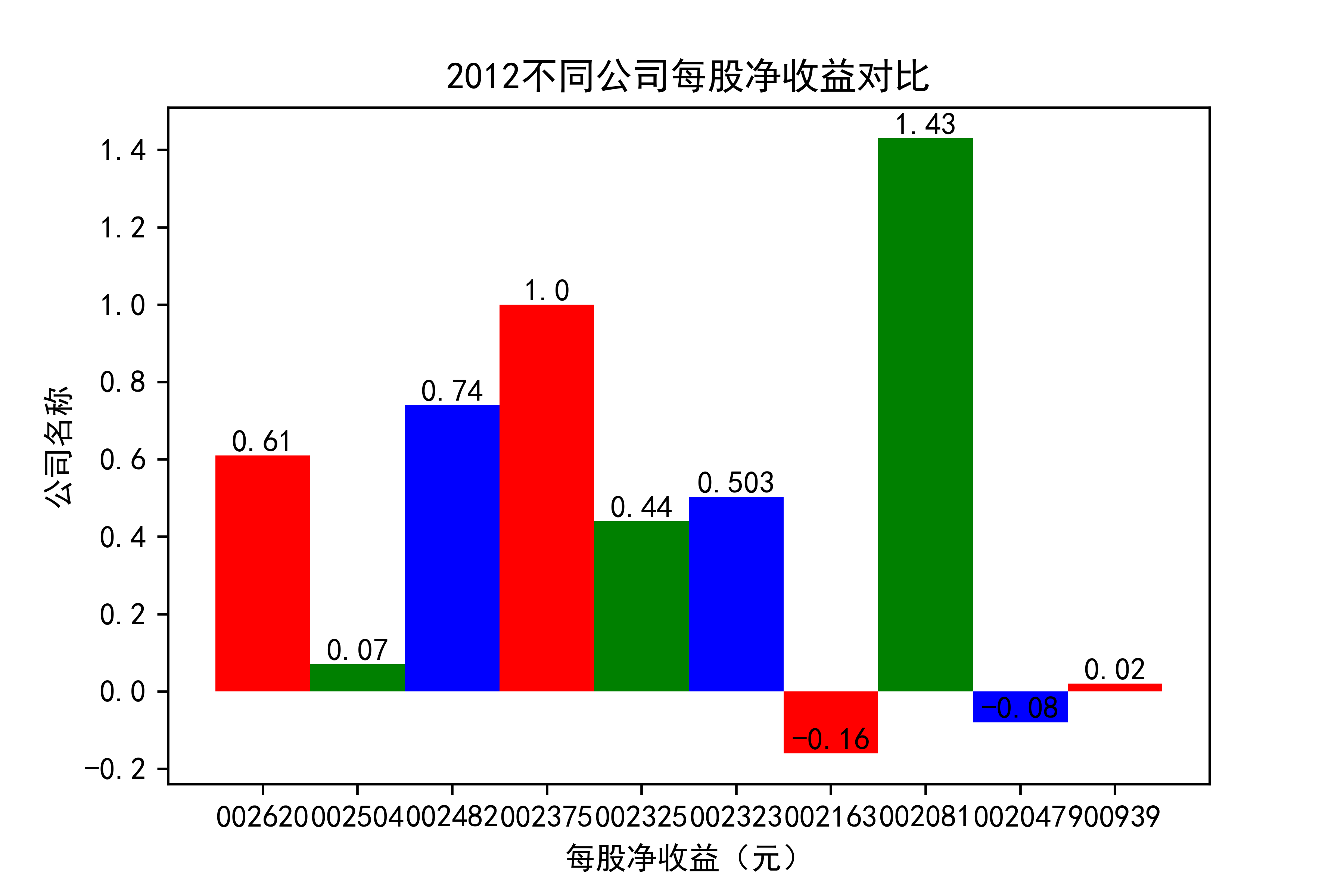

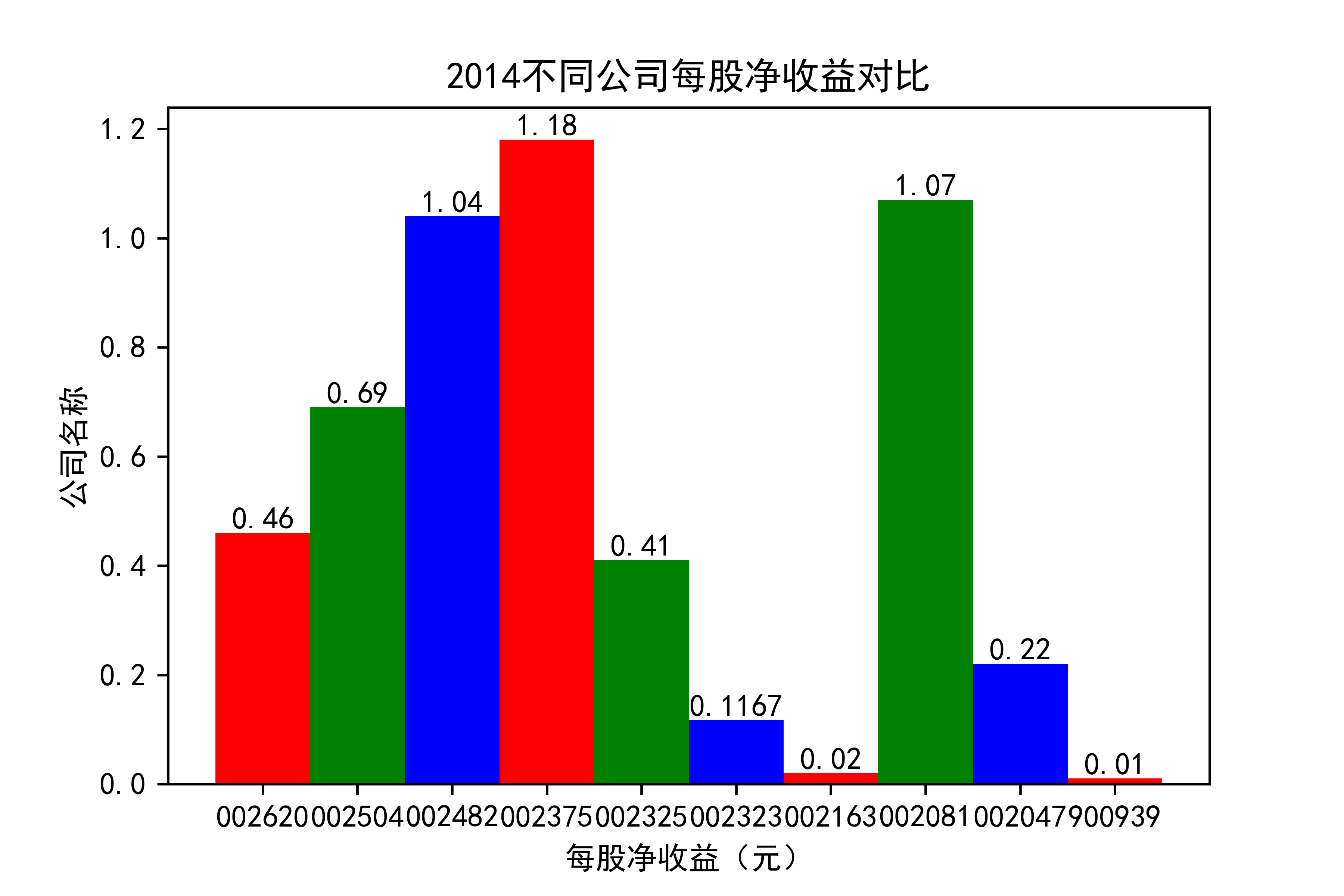
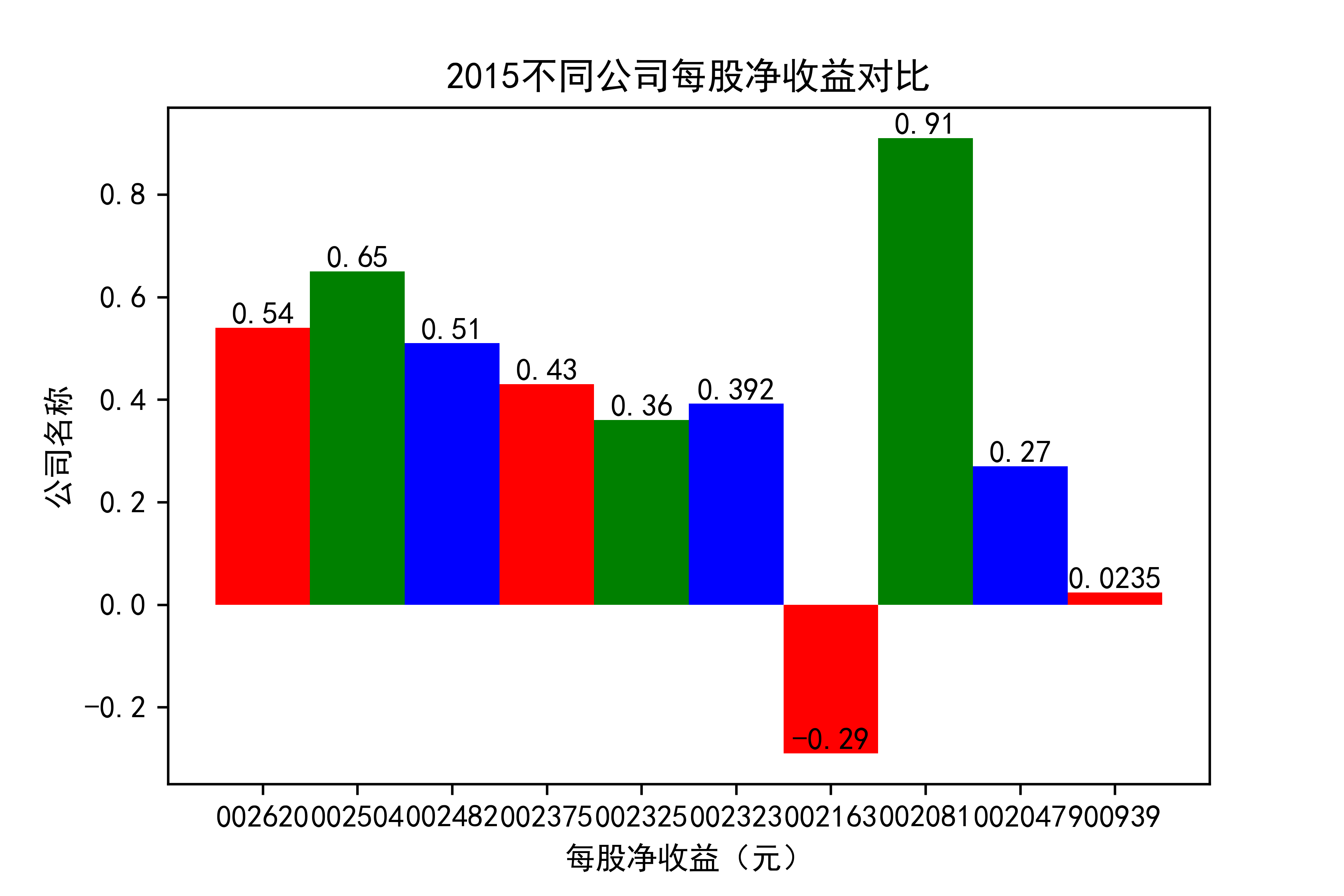

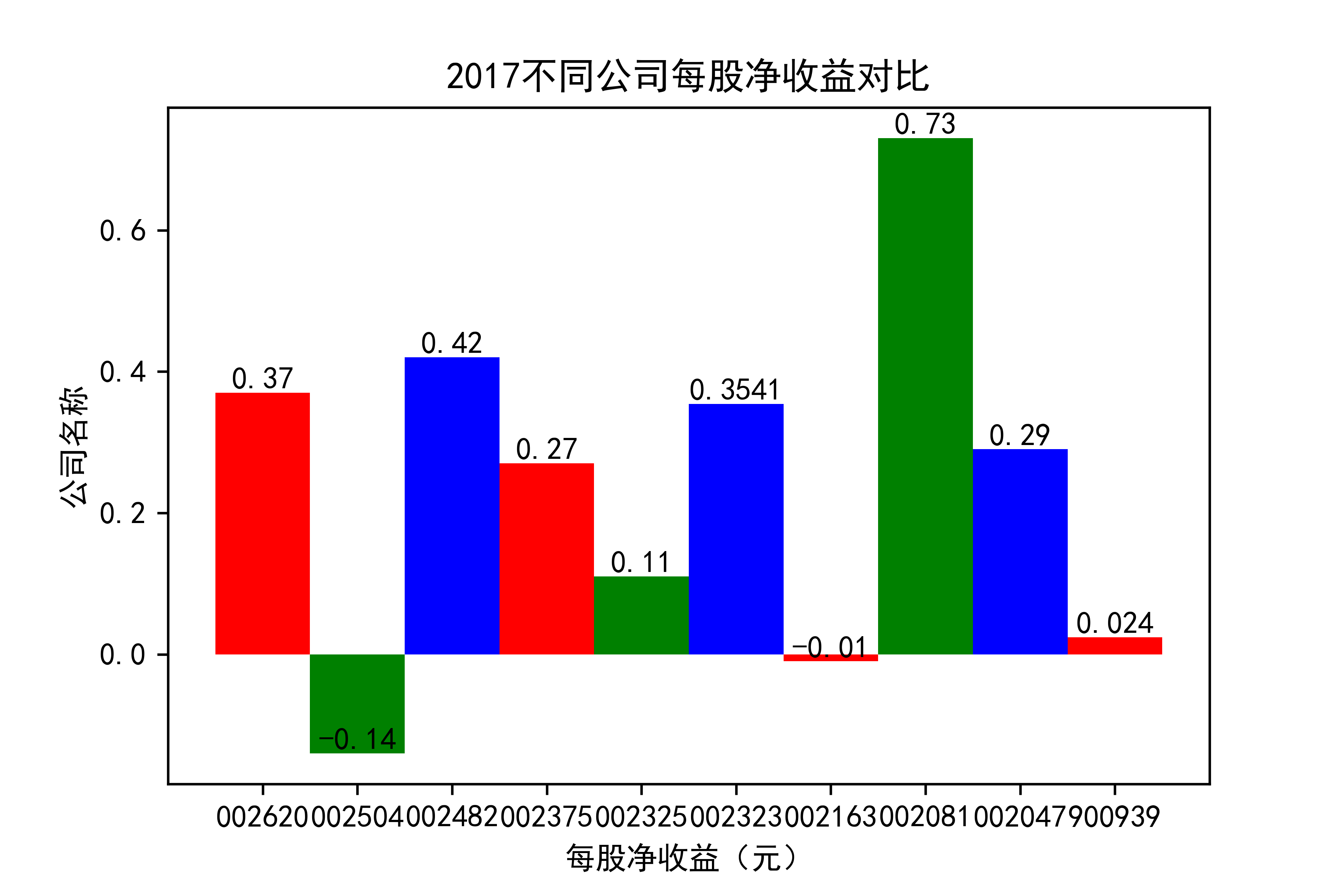
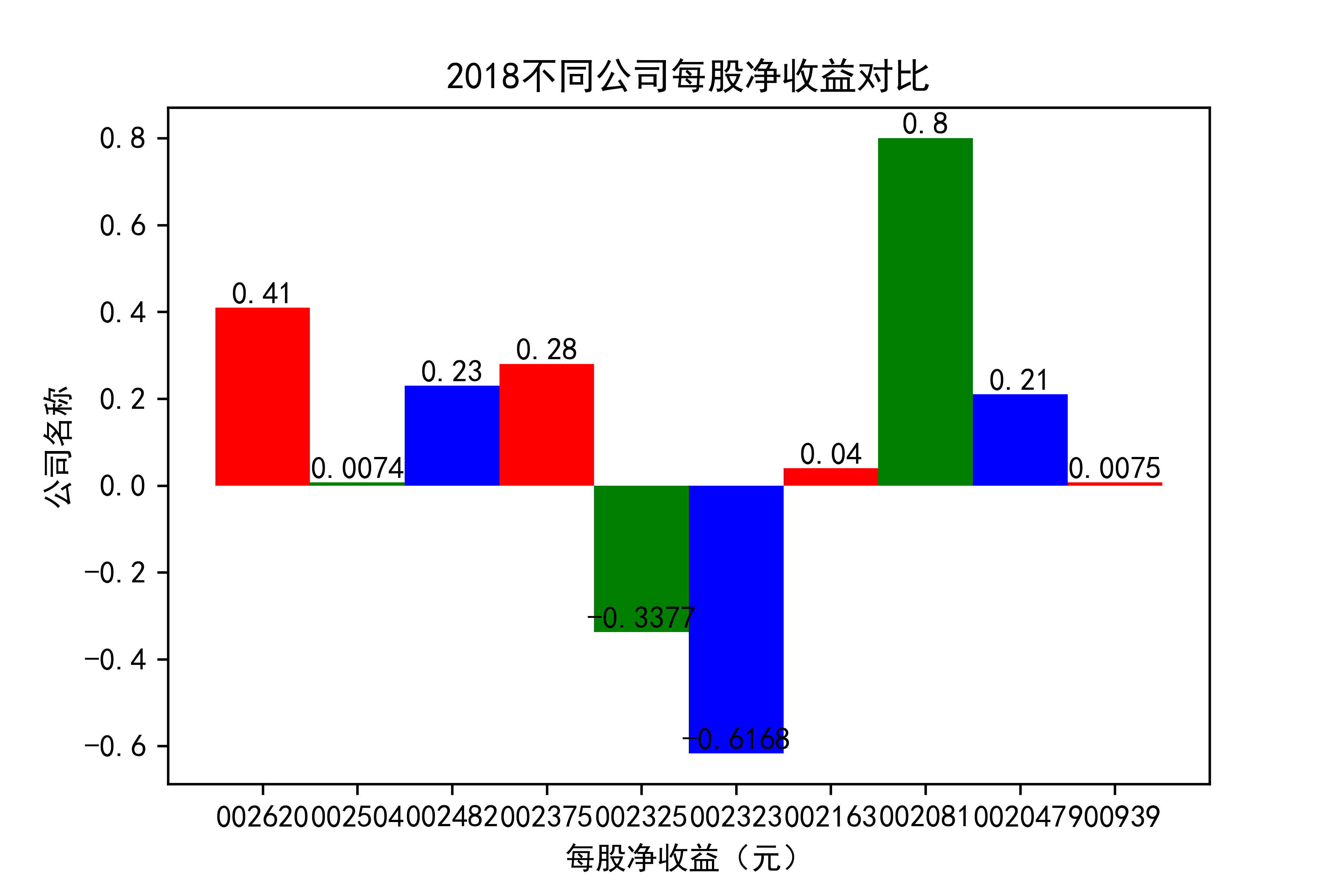
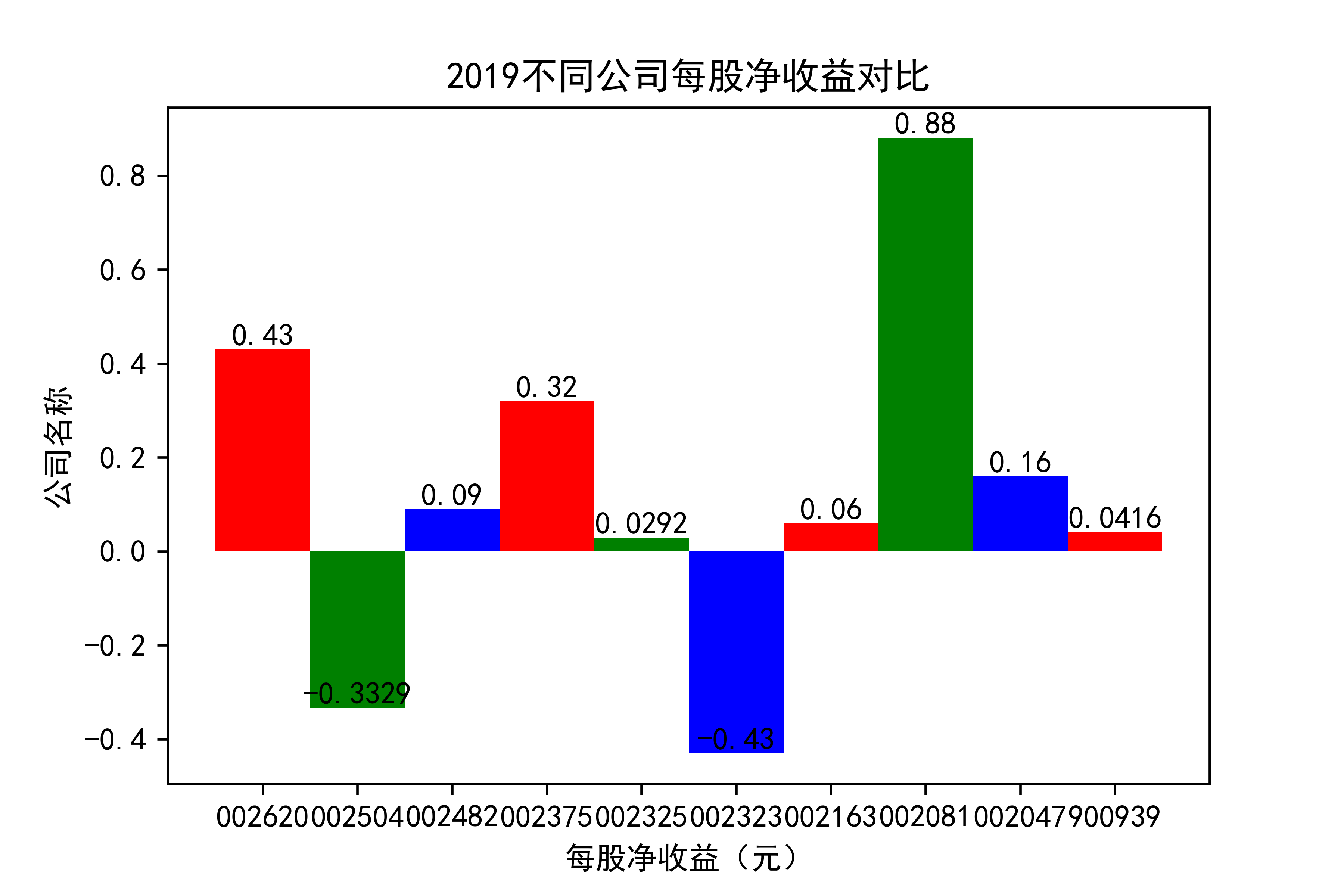
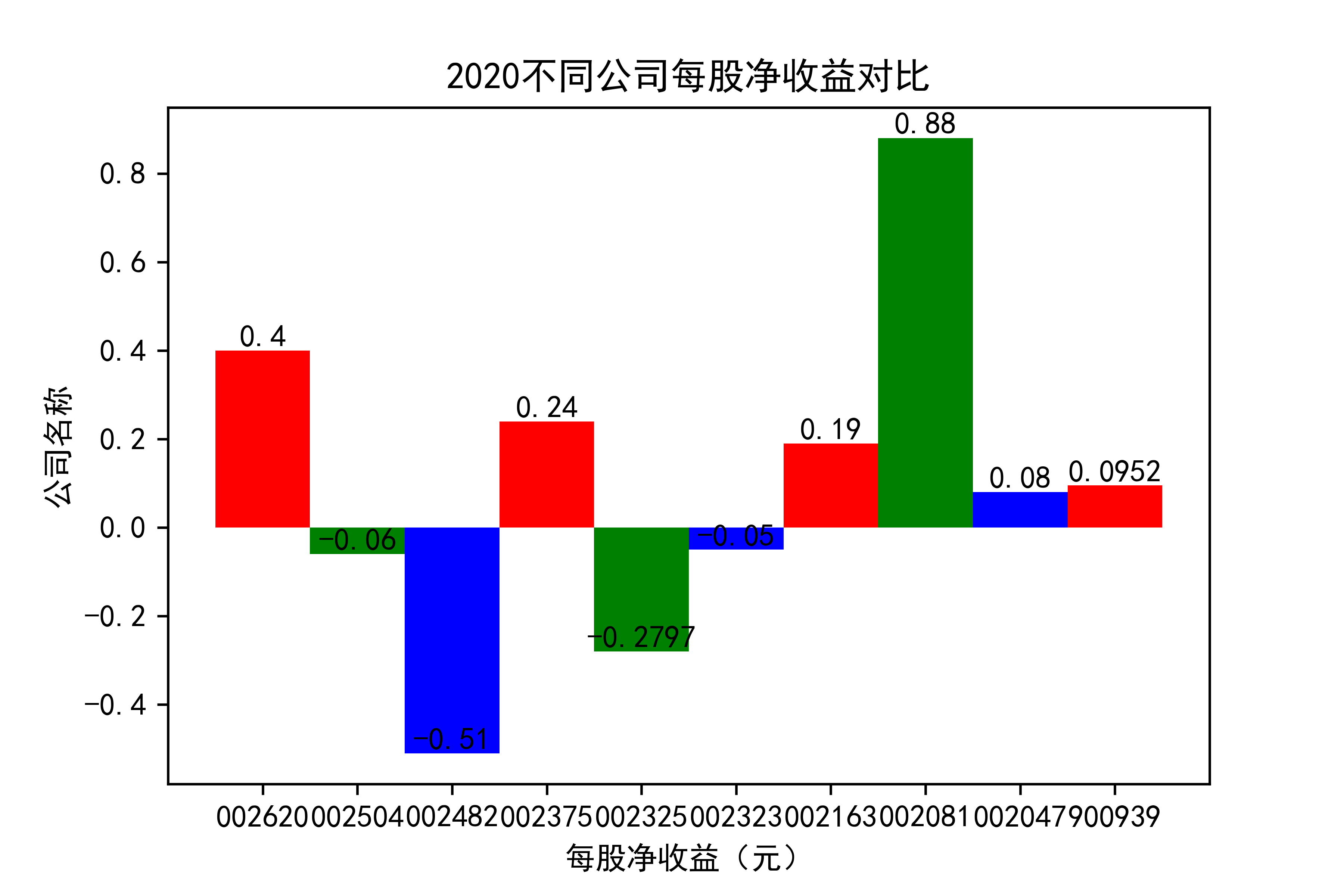

观察每年行业的大致情况,可以看出,在2021年几乎十家公司的每股收益都为负值,可见疫情冲击下,该行业的抗压能力并不太强。
横向对比之下,发现龙头公司不一定一直是龙头公司,其他公司都在发展,行业内竞争很大,但龙头公司保持也比较稳定,有一定的抗压能力。 在竞争激烈的行业内,毋庸置疑,各个公司需要不断地优化自己的产能结构,吸纳新元素,不断改革创新,才能在市场上生存,不被“劣汰”。