韩琦的实验报告
代码
一、获取深交所与上交所的页面信息,下载企业年报
先对行业分类文件进行处理,提取仪器仪表制造业的企业的公司代码与公司简称;再selenium模块模拟页面操作,提取页面信息,获取年报文件下载地址;过滤年报摘要与已取消的年报;利用循环下载所有公司2012-2021年年度报告。
import fitz
import re
doc = fitz.open(r'C:\Users\12621\Desktop\金融数据处理\industry.PDF')
#提取企业代码与名称
page69 = doc.load_page(70)
text1_1 = page69.get_text()
page70 = doc.load_page(71)
text1_2 = page70.get_text()
text1 = text1_1+ text1_2
#p = re.compile(r'(?<=\n)仪器仪表制造业(?:\n\d{6}\n\w+)*(?=\n)')
#p = re.compile(r'仪器仪表制造业(?<=\n)(\d{6})\n(\*?\w+)(?=\n)')
p1 = re.compile(r'仪器仪表制造业\n(?:\d{6}\n\*?\w+\n)*')
toc1 = p1.findall(text1)
toc1_1 = ''.join(toc1)
p2 = re.compile(r'(?<=\n)(\d{6})\n\*?\w+(?=\n)')
toc1_2 = p2.findall(toc1_1)
#提取深交所页面的企业信息
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
for i in range(0,45):
element = browser.find_element(By.ID, 'input_code') # Find the search box
element.send_keys(toc1_2[i])
time.sleep(2)
element.send_keys(Keys.ENTER)
start = browser.find_element(By.CSS_SELECTOR, ".input-left")
start.send_keys("2012-12-31")
end = browser.find_element(By.CSS_SELECTOR, ".input-right")
end.send_keys("2022-5-26")
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element1 = browser.find_element(By.ID, 'disclosure-table')
time.sleep(2)
innerHTML = element1.get_attribute('innerHTML')
time.sleep(2)
f = open('innerHTML.html','a',encoding='utf-8')
f.write(innerHTML)
time.sleep(2)
f.close()
browser.find_element(By.CSS_SELECTOR, ".btn-clearall").click()
i = i+1
browser.quit()
from bs4 import BeautifulSoup
import re
import pandas as pd
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('innerHTML.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data(df_txt)
#过滤年报摘要与已取消的年报
df_data1 = df_data[df_data['公告标题'].str.endswith('摘要')]
df_data2 = df_data[df_data['公告标题'].str.endswith('(已取消)')]
df_data3 = df_data[df_data['公告标题'].str.endswith('摘要(更新后)')]
df_data_temporary1 = df_data[-df_data['公告标题'].isin(df_data1['公告标题'])]
df_data_temporary2 = df_data_temporary1[-df_data_temporary1['公告标题'].isin(df_data2['公告标题'])]
df_data_refinement = df_data_temporary2[-df_data_temporary2['公告标题'].isin(df_data3['公告标题'])]
df_data_refinement = df_data_refinement.reset_index(drop=True)
df_data_refinement.to_csv('sample_data_of_industry.csv')
#根据提取的下载地址下载年报
import requests
filenames =df_data_refinement.iloc[:,0]+ df_data_refinement.iloc[:,2]
df_filenames = pd.DataFrame({'文件名称': filenames})
for n in range(len(df_data_refinement)):
href = df_data_refinement.iloc[n,3]
print(href)
r = requests.get(href, allow_redirects=True)
f = open(df_filenames.iloc[n,0] + '.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
n = n+1
#提取深交所页面的企业信息
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
for i in range(44,65):
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
browser.find_element(By.ID, "inputCode").click()
element = browser.find_element(By.ID, "inputCode").send_keys(toc1_2[i])
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
time.sleep(2)
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(2)
element1 = browser.find_element(By.CLASS_NAME, 'table-responsive ')
time.sleep(2)
innerHTML = element1.get_attribute('innerHTML')
time.sleep(2)
f = open('innerHTML_sse.html','a',encoding='utf-8')
f.write(innerHTML)
time.sleep(2)
f.close()
browser.quit()
i = i+1
from bs4 import BeautifulSoup
import re
import pandas as pd
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('innerHTML_sse.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
p_blank = re.compile('\s+(.*?)\s+', re.DOTALL)
get_a = lambda txt: p_a.search(txt).group(1).strip()
get_span = lambda txt: p_span.search(txt).group(1).strip()
get_blank = lambda txt: p_blank.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
href = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
def get_data(df_txt):
prefix_href = 'http://static.sse.com.cn'
df = df_txt
codes = [get_span(td) for td in df['证券代码']]
short_names = [get_span(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_blank(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
return(df)
df_data = get_data(df_txt)
#过滤年报摘要与已取消的年报
df_data1 = df_data[df_data['公告标题'].str.endswith('年度报告')]
df_data2 = df_data[df_data['公告标题'].str.endswith('年报')]
df_data_temporary1 = df_data[-df_data['公告标题'].isin(df_data1['公告标题'])]
df_data_temporary2 = df_data_temporary1[-df_data_temporary1['公告标题'].isin(df_data2['公告标题'])]
df_data_refinement = df_data[-df_data['公告标题'].isin(df_data_temporary2['公告标题'])]
df_data_refinement = df_data_refinement.reset_index(drop=True)
df_data_refinement1 = df_data_refinement.replace('-',None)
df_data_refinement1 = df_data_refinement1.fillna(method='ffill')
df_data_refinement1 = df_data_refinement1.drop([33,35])
df_data_refinement1 = df_data_refinement1.reset_index(drop=True)
df_data_refinement1.to_csv('sample_data_of_industry_sse.csv')
#根据提取的下载地址下载年报
import requests
df_filenames = pd.DataFrame({})
for n in range(len(df_data_refinement1)):
filenames =df_data_refinement1.iloc[n,0] + '_' +str(n)
df_filenames = df_filenames.append({'文件名称': filenames},ignore_index=True)
for n in range(len(df_data_refinement1)):
href = df_data_refinement1.iloc[n,3]
print(href)
r = requests.get(href, allow_redirects=True)
f = open(df_filenames.iloc[n,0] +'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
结果
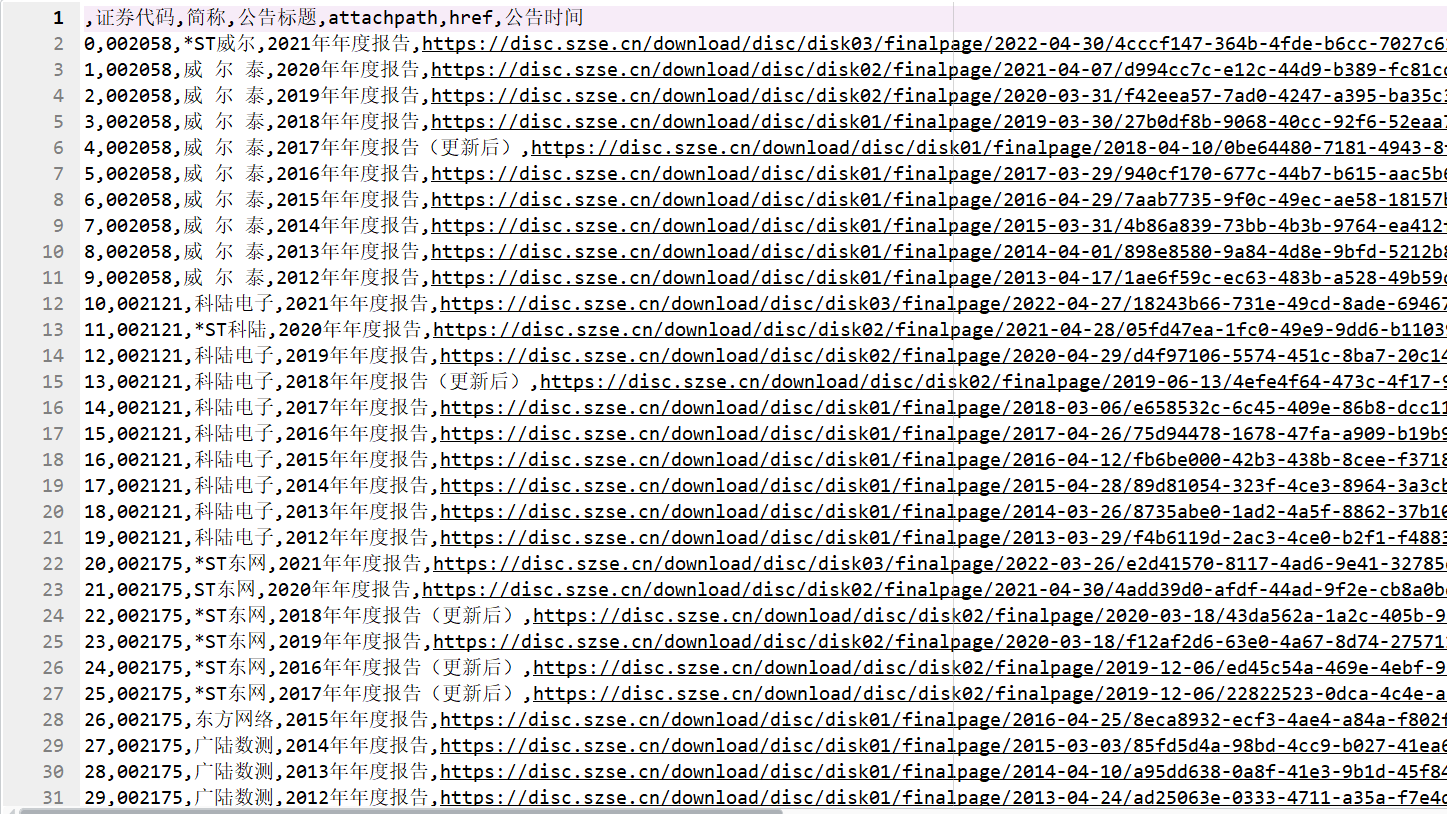
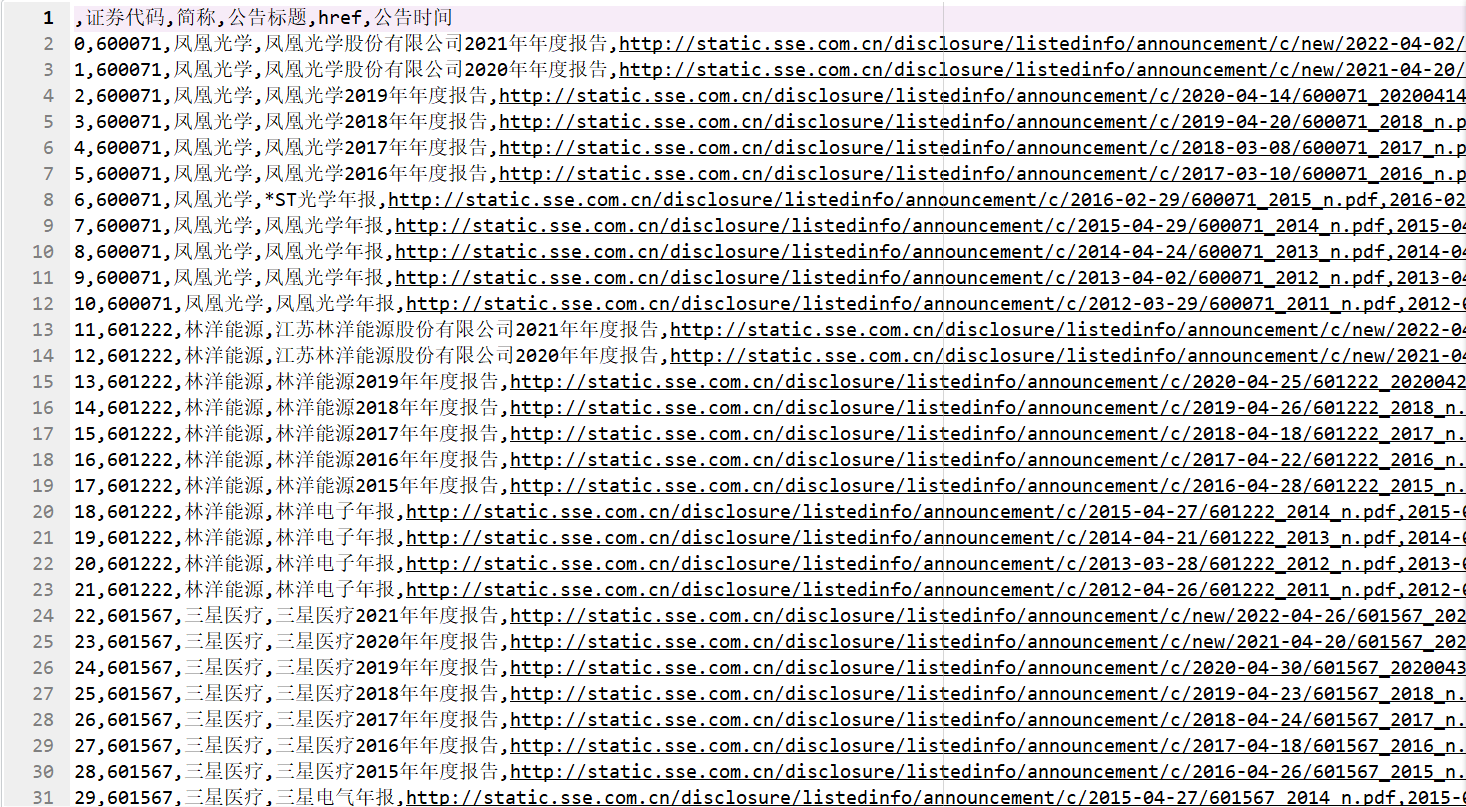
二、处理年报文件,提取营业收入、基本每股收益与公司信息
定义class REVENUE,解析上市公司财务数据:
定义函数get_toc,获取年报目录页信息;
定义函数jie_pages_title,提取目录页中章节数、章节名称与相应页码;
定义函数get_key_findata_pages,获取主要财务数据章节所在页码;
定义函数get_target_page,考虑到表格可能跨页,提取主要财务数据章节前三节的文本内容;
定义函数parse_revenue_table,获取主要财务数据表;
由于parse_revenue_table函数只能处理列数为5的表格,遇到6列或者7列的表格需要在class REVENUE中额外定义处理6列与7列的函数,也即parse_revenue_table531,parse_revenue_table522,parse_revenue_table6;
定义函数file_refinement,提取当年的营业收入与基本每股收益。
定义class INFORMATION,解析上市公司财务数据:
类中的其他函数作用同class REVENUE一致;
定义函数parse_information_table,利用正则表达式匹配获取股票简称、股票代码、办公地址与公司网址信息。
对pdf进行处理,将提取的十年财务数据合并入同一个DataFrame并写入csv,公司信息会被覆盖为2021年的最新内容,同样将其写入csv,csv文件储存在以股票代码命名的文件夹中。
class REVENUE():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]节)\s+(\w*).*?(\d+)\s' % jie_zh)
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
break
self.match = match
def jie_pages_title(self):
match = self.match
jie_pages, jie_title = {}, {}
for i in range(10):
jie, title, pageNumber = match[i][0], match[i][1], match[i][2]
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
return(jie_pages)
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '公司简介']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
print('没有找到“公司简介和主要财务指标”或“公司简介”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('公司信息', re.DOTALL)
target_page = ''
target_page1 = ''
target_page2 = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
target_page1 = p+1
target_page2 = p+2; break
if target_page == '':
print('没找到“公司信息”页')
self.key_fin_data_page1 = target_page
self.key_fin_data_page2 = target_page1
self.key_fin_data_page3 = target_page2
return(target_page)
def parse_revenue_table(self):
page_number1 = self.key_fin_data_page1
page_number2 = self.key_fin_data_page2
page_number3 = self.key_fin_data_page3
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
page3 = self.doc[page_number3]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt3 = page3.get_text()
txt = txt1+txt2+txt3
#
pt = '(.*?)(20\d{2}\s*年)\s*(20\d{2}\s*年)\s*(.*?\n*.*?\n*.*?\n*.*?)\s*(20\d{2}\s*年)\s*'
pt = '(?<=主要会计数据)' + pt + '(?=营业收入)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0]# 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,]+.\d+'
pentage = '-?[\d.]+'
pr = ('(\w+[\s]?\w+)[(元)]*[(元/股)]*\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*' %(number,
number,
pentage,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
# pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[txt.find('主要会计数据'):]
txt = txt[:txt.find('稀释每股收益(元/股)')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[3] for t in data],
title[4]: [t[4] for t in data]})
# return((df,title))
self.revenue_table = df
return(df)
def parse_revenue_table531(self):
page_number1 = self.key_fin_data_page1
page_number2 = self.key_fin_data_page2
page_number3 = self.key_fin_data_page3
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
page3 = self.doc[page_number3]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt3 = page3.get_text()
txt = txt1+txt2+txt3
#
pt = '(.*?)(20\d{2}\s*年)\s*(20\d{2}\s*年)\s*(.*?\n*.*?\n*.*?\n*.*?)\s*(20\d{2}\s*年)\s*'
pt = '(?<=主要会计数据)' + pt + '(?=调整后)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0]# 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,]+.\d+'
pentage = '-?[\d.]+'
pr = ('(\w+)[\n]*\w*[(元)]*[(元/股)]*\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*' %(number,
number,
pentage,
number,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
# pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[txt.find('主要会计数据'):]
txt = txt[:txt.find('稀释每股收益(元/股)')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[3] for t in data],
title[3]: [t[4] for t in data],
title[4]: [t[5] for t in data]})
df = df.replace('\n','', regex=True)
# return((df,title))
self.revenue_table = df
return(df)
def parse_revenue_table522(self):
page_number1 = self.key_fin_data_page1
page_number2 = self.key_fin_data_page2
page_number3 = self.key_fin_data_page3
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
page3 = self.doc[page_number3]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt3 = page3.get_text()
txt = txt1+txt2+txt3
#
pt = '(.*?)(20\d{2}\s*年)\s*(20\d{2}\s*年)\s*(.*?\n*.*?\n*.*?\n*.*?)\s*(20\d{2}\s*年)\s*'
pt = '(?<=主要会计数据)' + pt + '(?=调整后)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0]# 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,]+.\d+'
pentage = '-?[\d.]+'
pr = ('(\w+)[\n]*\w*[(元)]*[(元/股)]*\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*' %(number,
number,
pentage,
number,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
# pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[txt.find('主要会计数据'):]
txt = txt[:txt.find('稀释每股收益(元/股)')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[3] for t in data],
title[4]: [t[4] for t in data]})
df = df.replace('\n','', regex=True)
# return((df,title))
self.revenue_table = df
return(df)
def parse_revenue_table6(self):
page_number1 = self.key_fin_data_page1
page_number2 = self.key_fin_data_page2
page_number3 = self.key_fin_data_page3
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
page3 = self.doc[page_number3]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt3 = page3.get_text()
txt = txt1+txt2+txt3
#
pt = '(.*?)(20\d{2}\s*年)\s*(20\d{2}\s*年)\s*(.*?\n*.*?\n*.*?\n*.*?)\s*(20\d{2}\s*年)\s*'
pt = '(?<=主要会计数据)' + pt + '(?=调整后)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0]# 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,]+.\d+'
pentage = '-?[\d.]+'
pr = ('(\w+)[(元)]*[(元/股)]*\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*' %(number,
number,
number,
pentage,
number,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[txt.find('主要会计数据'):]
txt = txt[:txt.find('稀释每股收益(元/股)')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[4] for t in data],
title[4]: [t[5] for t in data]})
df = df.replace('\n','', regex=True)
# return((df,title))
self.revenue_table = df
return(df)
def file_refinement(self):
df_r = self.revenue_table
df_r_data1 = df_r[df_r.iloc[:,0].str.startswith('营业收入')]
df_r_data2 = df_r[df_r.iloc[:,0].str.startswith('基本每股收益')]
df_data_temporary1 = df_r[-df_r.iloc[:,0].isin(df_r_data1.iloc[:,0])]
df_data_temporary2 = df_data_temporary1[-df_data_temporary1.iloc[:,0].isin(df_r_data2.iloc[:,0])]
df_r = df_r[-df_r.iloc[:,0].isin(df_data_temporary2.iloc[:,0])]
df_r = df_r.reset_index(drop=True)
df_r = df_r.drop(df_r.iloc[:,2:5],axis=1)
df_r = df_r.set_index(df_r['项目'])
df_r = df_r.drop(columns='项目')
#
self.refinement_table = df_r
return(df_r)
class INFORMATION():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]节)\s+(\w*).*?(\d+)\s' % jie_zh)
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
break
self.match = match
def jie_pages_title(self):
match = self.match
jie_pages, jie_title = {}, {}
for i in range(10):
jie, title, pageNumber = match[i][0], match[i][1], int(match[i][2])-1
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
return(jie_pages)
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '公司简介']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
print('没有找到“公司简介和主要财务指标”或“公司简介”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('公司的中文名称', re.DOTALL)
target_page = ''
target_page1 = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
target_page1 = p+1; break
if target_page == '':
# Warning('没找到“基本情况简介”页')
print('没找到“基本情况简介”页')
self.key_fin_data_page1 = target_page
self.key_fin_data_page2 = target_page1
return(target_page)
def parse_information_table(self):
page_number1 = self.key_fin_data_page1
page_number2 = self.key_fin_data_page2
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt = txt1+txt2
#
pr1 = '上海证券交易所\n*科创板\s*(\w+)\s*(\d{6})\s*'
pr2 = '公司办公地址\s*(.*?\s*.*?)\s*'
pr3 = '公司网址\s*(.*?)\s*'
# pr1 = '(?<=\n)' + pr1 + '(?=\n)'
pr2 = '(?<=\n)' + pr2 + '(?=\n公司办公地址的邮政编码)'
pr3 = '(?<=\n)' + pr3 + '(?=\n电子信箱)'
p1 = re.compile(pr1)
data1 = p1.findall(txt)
p2 = re.compile(pr2)
data2 = p2.findall(txt)
p3 = re.compile(pr3)
data3 = p3.findall(txt)
df = pd.DataFrame({'股票简称': [t[0] for t in data1],
'股票代码': [t[1] for t in data1],
'办公地址': [data2[0]],
'公司网址': [data3[0]]})
self.information_table = df
return(df)
#2012
wrt2012_r = REVENUE('0020582012年年度报告.pdf')
df_r = wrt2012_r.parse_revenue_table()
df_r2012 = wrt2012_r.file_refinement()
wrt2012_i = INFORMATION('0020582012年年度报告.pdf')
df_i = wrt2012_i.parse_information_table()
#2013
wrt2013_r = REVENUE('0020582013年年度报告.pdf')
df_r = wrt2013_r.parse_revenue_table()
df_r2013 = wrt2013_r.file_refinement()
wrt2013_i = INFORMATION('0020582013年年度报告.pdf')
df_i = wrt2013_i.parse_information_table()
#2014
wrt2014_r = REVENUE('0020582014年年度报告.pdf')
df_r = wrt2014_r.parse_revenue_table()
df_r2014 = wrt2014_r.file_refinement()
wrt2014_i = INFORMATION('0020582014年年度报告.pdf')
df_i = wrt2014_i.parse_information_table()
#2015
wrt2015_r = REVENUE('0020582015年年度报告.pdf')
df_r = wrt2015_r.parse_revenue_table()
df_r2015 = wrt2015_r.file_refinement()
wrt2015_i = INFORMATION('0020582016年年度报告.pdf')
df_i = wrt2015_i.parse_information_table()
#2016
wrt2016_r = REVENUE('0020582016年年度报告.pdf')
df_r = wrt2016_r.parse_revenue_table()
df_r2016 = wrt2016_r.file_refinement()
wrt2016_i = INFORMATION('0020582016年年度报告.pdf')
df_i = wrt2016_i.parse_information_table()
#2017
wrt2017_r = REVENUE('0020582017年年度报告.pdf')
df_r = wrt2017_r.parse_revenue_table()
df_r2017 = wrt2017_r.file_refinement()
wrt2017_i = INFORMATION('0020582017年年度报告.pdf')
df_i = wrt2017_i.parse_information_table()
#2018
wrt2018_r = REVENUE('0020582018年年度报告.pdf')
df_r = wrt2018_r.parse_revenue_table()
df_r2018 = wrt2018_r.file_refinement()
wrt2018_i = INFORMATION('0020582018年年度报告.pdf')
df_i = wrt2018_i.parse_information_table()
#2019
wrt2019_r = REVENUE('0020582019年年度报告.pdf')
df_r = wrt2019_r.parse_revenue_table()
df_r2019 = wrt2019_r.file_refinement()
wrt2019_i = INFORMATION('0020582019年年度报告.pdf')
df_i = wrt2019_i.parse_information_table()
#2020
wrt2020_r = REVENUE('0020582020年年度报告.pdf')
df_r = wrt2020_r.parse_revenue_table()
df_r2020 = wrt2020_r.file_refinement()
wrt2020_i = INFORMATION('0020582020年年度报告.pdf')
df_i = wrt2020_i.parse_information_table()
#2021
wrt2021_r = REVENUE_special('0020582021年年度报告.pdf')
df_r = wrt2021_r.parse_revenue_table()
df_r2021 = wrt2021_r.file_refinement()
wrt2021_i = INFORMATION('0020582021年年度报告.pdf')
df_i = wrt2021_i.parse_information_table()
df_r2012 = pd.concat([df_r2012,df_r2013],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2014],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2015],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2016],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2017],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2018],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2019],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2020],axis=1)
df_r2012 = pd.concat([df_r2012,df_r2021],axis=1)
#将数据写入excel
df_r2012.to_csv('annual_revenue.csv')
df_i.to_csv('company_information.csv')
结果


三、分别合并所有上市公司营业收入、基本每股收益与公司信息
遍历深交所与上交所文件夹中的所有annual_revenue文件,即包含营业收入与基本每股收益的csv文件,获取每一份文件的绝对路径;
根据文件的绝对路径,读入文件,将所有数据写入一份DataFrame表格,再根据营业收入与基本每股收益拆分成df1与df2两张表;
遍历深交所与上交所文件夹中的所有company_information文件,即公司信息文件,获取每一份文件的绝对路径,读入文件,将所有信息写入一份表格。
合并深交所与上交所的营业收入、基本每股收益与公司信息表格,将股票代码设为以上表格的索引,将表格写入csv文件。
import os
import pandas as pd
#遍历深交所文件夹中的所有annual_revenue文件,获取每一份文件的绝对路径
file_dir = r'C:\Users\12621\Desktop\金融数据处理\文件下载\深交所'
for files in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'annual_revenue':
print(file)
lst = []
for dirpath in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'annual_revenue':
h = os.path.join(dirpath[0], file)
lst.append(h)
#将提取的数据写入表格
df = pd.DataFrame({})
for i in range(1,46):
df=df.append(pd.read_excel(lst[i],sheet_name='Sheet1',header=0,index_col=None))
#拆分营业收入与基本每股收益
df1 = df[df.iloc[:,0].str.startswith('营业收入')]
df1 = df1.reset_index()
df1 = df1.drop(df1.iloc[:,0:2],axis=1)
df2 = df[df.iloc[:,0].str.startswith('基本每股收益')]
df2 = df2.reset_index()
df2 = df2.drop(df2.iloc[:,0:2],axis=1)
file_dir = r'C:\Users\12621\Desktop\金融数据处理\文件下载\深交所'
for files in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'company_information':
print(file)
lst = []
for dirpath in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'company_information':
h = os.path.join(dirpath[0], file)
lst.append(h)
df5 = pd.DataFrame({})
for i in range(1,46):
df5 = df5.append(pd.read_excel(lst[i],sheet_name='Sheet1',header=0,index_col=None,dtype=object))
df5 = df5.reset_index()
df5 = df5.drop(df5.iloc[:,0:2],axis=1)
#上交所营业收入、基本每股收益、公司信息
file_dir = r'C:\Users\12621\Desktop\金融数据处理\文件下载\上交所'
for files in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'annual_revenue':
print(file)
lst = []
for dirpath in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'annual_revenue':
h = os.path.join(dirpath[0], file)
lst.append(h)
df = pd.DataFrame({})
for i in range(1,22):
df_tem = pd.read_excel(lst[i],sheet_name='Sheet1',header=0,index_col=None)
df = pd.concat([df,df_tem],axis=0)
df3 = df[df.iloc[:,0].str.startswith('营业收入')]
df3 = df3.reset_index()
df3 = df3.drop(df3.iloc[:,0:2],axis=1)
df4 = df[df.iloc[:,0].str.startswith('基本每股收益')]
df4 = df4.reset_index()
df4 = df4.drop(df4.iloc[:,0:2],axis=1)
for files in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'company_information':
print(file)
lst = []
for dirpath in os.walk(file_dir):
for file in files[2]:
if os.path.splitext(file)[1] == '.csv' and os.path.splitext(file)[0] == 'company_information':
h = os.path.join(dirpath[0], file)
lst.append(h)
df6 = pd.DataFrame({})
for i in range(1,22):
df6 = df6.append(pd.read_excel(lst[i],sheet_name='Sheet1',header=0,index_col=None,dtype=object))
df6 = df6.reset_index()
df6 = df6.drop(df6.iloc[:,0:2],axis=1)
df1 = pd.concat([df1,df3],axis=0)
df2 = pd.concat([df2,df4],axis=0)
df5 = pd.concat([df5,df6],axis=0)
df1.index = df5['股票代码']
df2.index = df5['股票代码']
df1.to_csv('营业收入.csv')
df2.to_csv('基本每股收益.csv')
df5.to_csv('公司信息.csv')
df1.to_excel('营业收入.xlsx')
df2.to_excel('基本每股收益.xlsx')
df5.to_excel('公司信息.xlsx')
结果
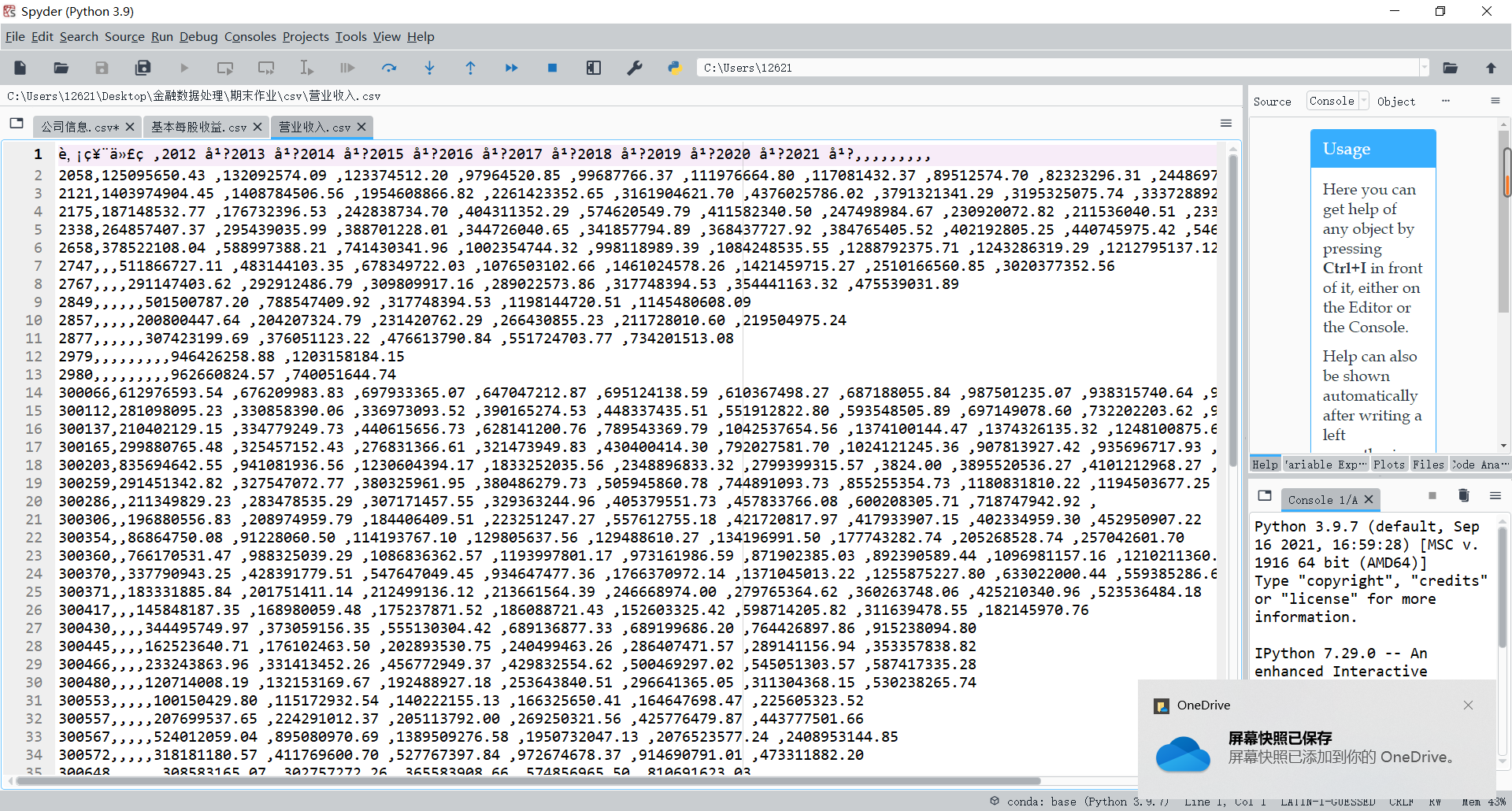
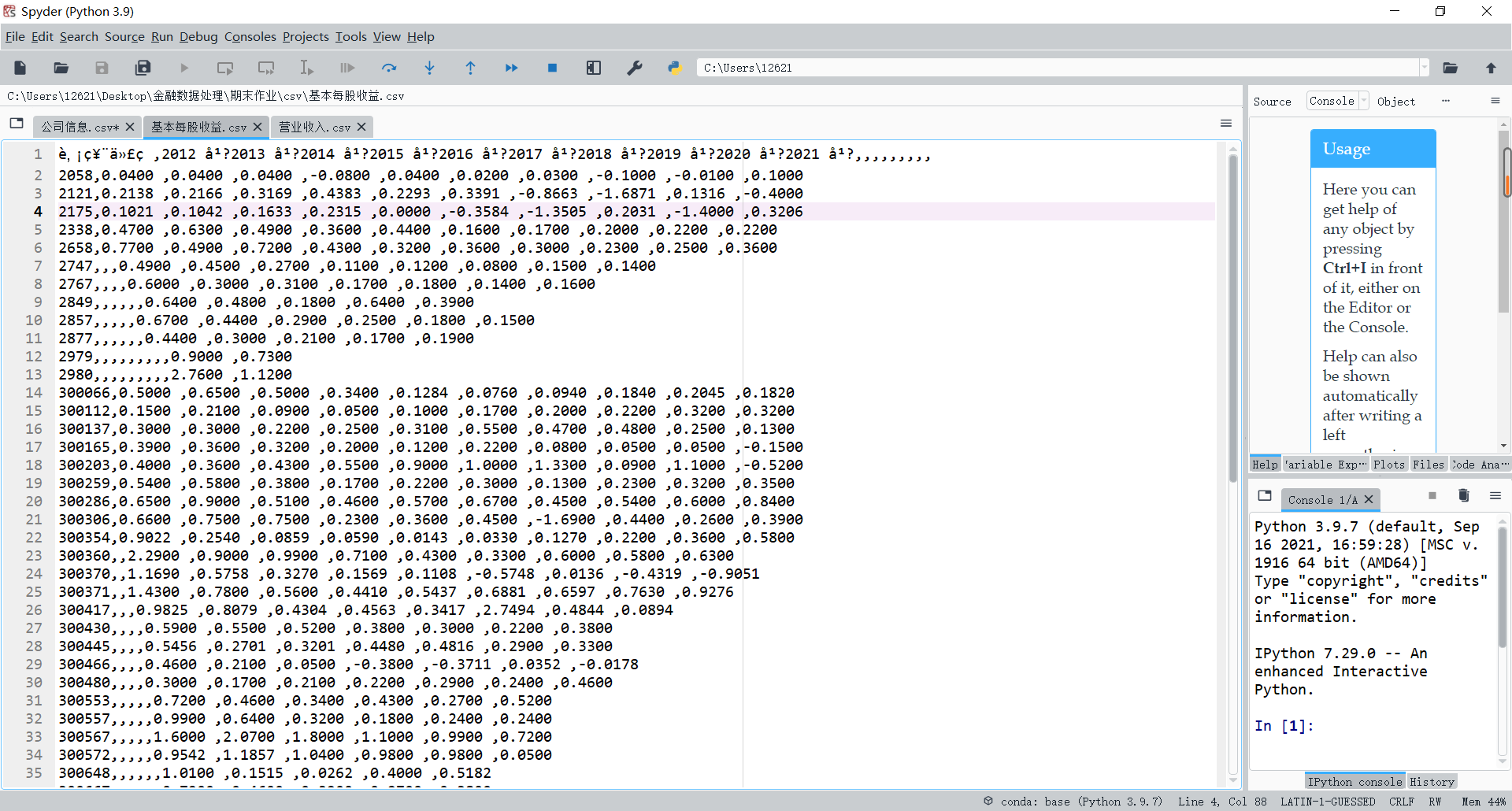
四、根据年报信息绘图
读取文件数据,根据各公司2012年营业收入数据降序排序,选取前十家公司;
对每家上市公司绘制“营业收入(元)”、“基本每股收益(元/股)”随时间变化趋势图;
按每一年度,对该行业内公司“营业收入(元)”、“基本每股收益(元/股)”绘制对比图。
import pandas as pd
import numpy as np
np.set_printoptions(suppress=True)
import pandas as pd
from pylab import mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
import re
df1=pd.read_excel(r'C:\Users\12621\Desktop\金融数据处理\文件下载\营业收入.xlsx',dtype=object)
df2=pd.read_excel(r'C:\Users\12621\Desktop\金融数据处理\文件下载\基本每股收益.xlsx',dtype=object)
df1 = df1.sort_values(by=['2012 年'],ascending=False)
df3 = df1.iloc[0:10]
df3 = df3.reset_index()
df3 = df3.drop(columns='index')
df4 = df2.iloc[[45,44,1,43,16,12,4,15,17,13]]
df4 = df4.reset_index()
df4 = df4.drop(columns='index')
for i in range(10):
ypoints = np.array(df3.iloc[i,1:])
xpoints = np.array(df3.columns)
xpoints = xpoints[1:]
plt.figure(figsize=(9,6))
plt.plot(xpoints,ypoints, marker = 'o')
plt.xlabel(u'年份',fontsize=13)
plt.ylabel(u'营业收入(万元)',fontsize=13)
plt.title(df3.iloc[i,0],fontsize=14)
plt.show()
for i in range(10):
ypoints = np.array(df4.iloc[i,1:])
xpoints = np.array(df4.columns)
xpoints = xpoints[1:]
plt.figure(figsize=(9,6))
plt.plot(xpoints,ypoints, marker = 'o')
plt.xlabel(u'年份',fontsize=13)
plt.ylabel(u'基本每股收益(元/股)',fontsize=13)
plt.title(df4.iloc[i,0],fontsize=14)
plt.show()
for i in range(10):
ypoints = np.array(df3.iloc[0:10,i+1])
xpoints = np.array(df3.iloc[0:10,0])
plt.figure(figsize=(9,6))
plt.bar(xpoints,ypoints)
plt.xlabel(u'股票代码',fontsize=13)
plt.ylabel(u'营业收入(万元)',fontsize=13)
plt.title(df3.columns[i+1],fontsize=14)
plt.show()
for i in range(10):
ypoints = np.array(df4.iloc[0:10,i+1])
xpoints = np.array(df4.iloc[0:10,0])
plt.figure(figsize=(9,6))
plt.bar(xpoints,ypoints)
plt.xlabel(u'股票代码',fontsize=13)
plt.ylabel(u'基本每股收益(元/股)',fontsize=13)
plt.title(df4.columns[i+1],fontsize=14)
plt.show()
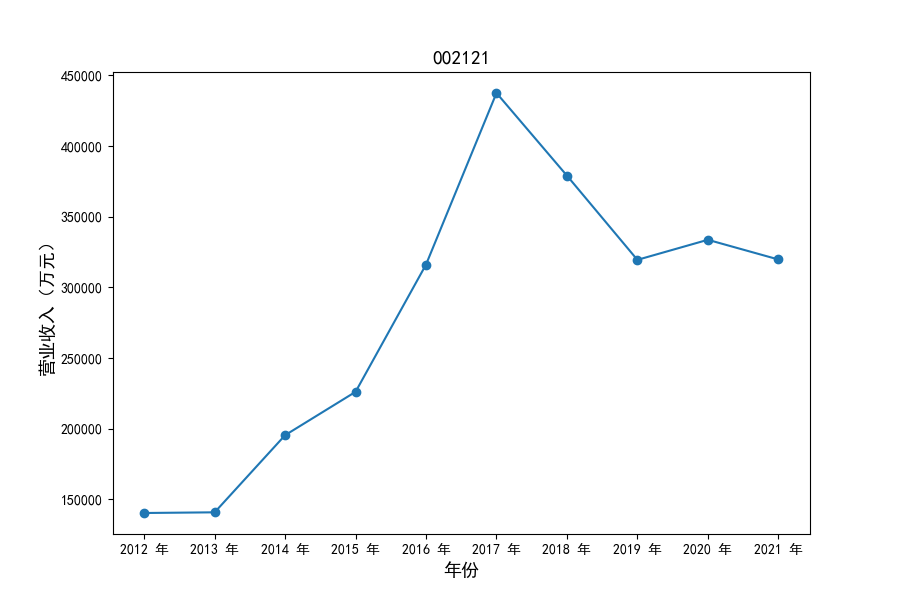
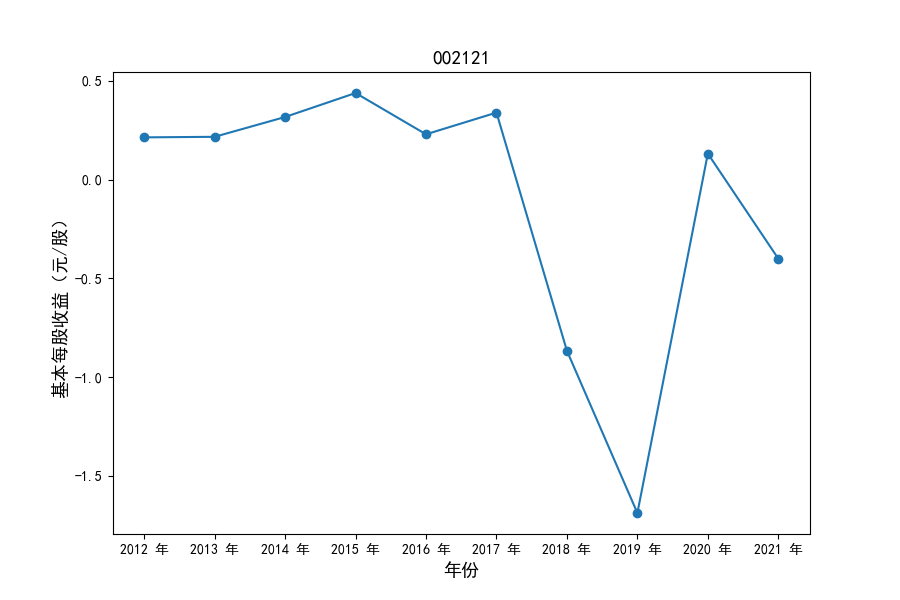
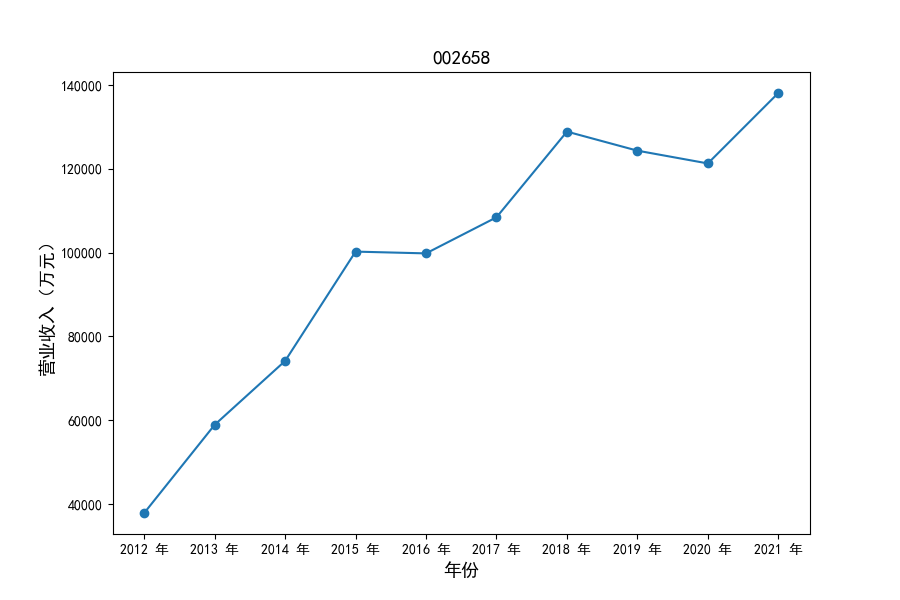
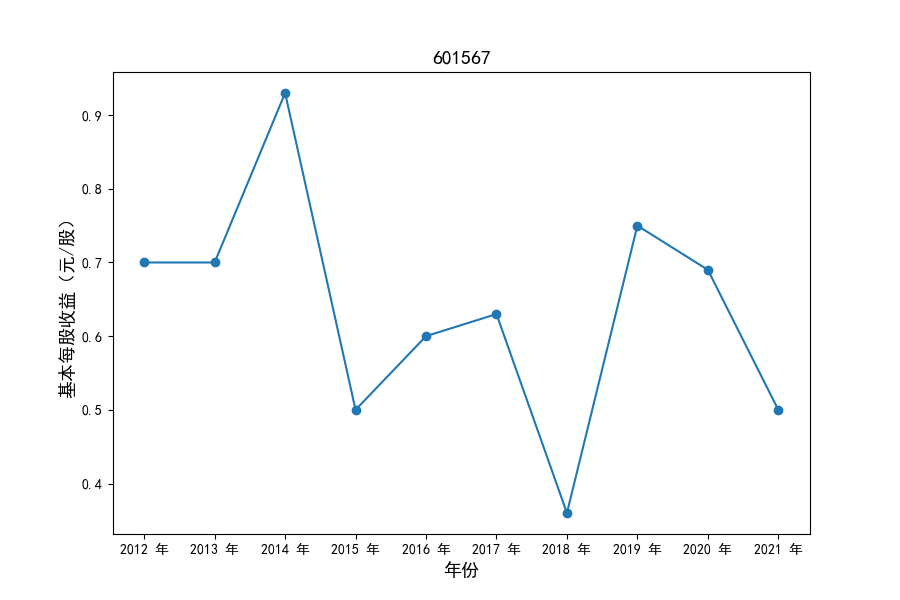
各家公司2012-2021年度营业收入与基本每股收益
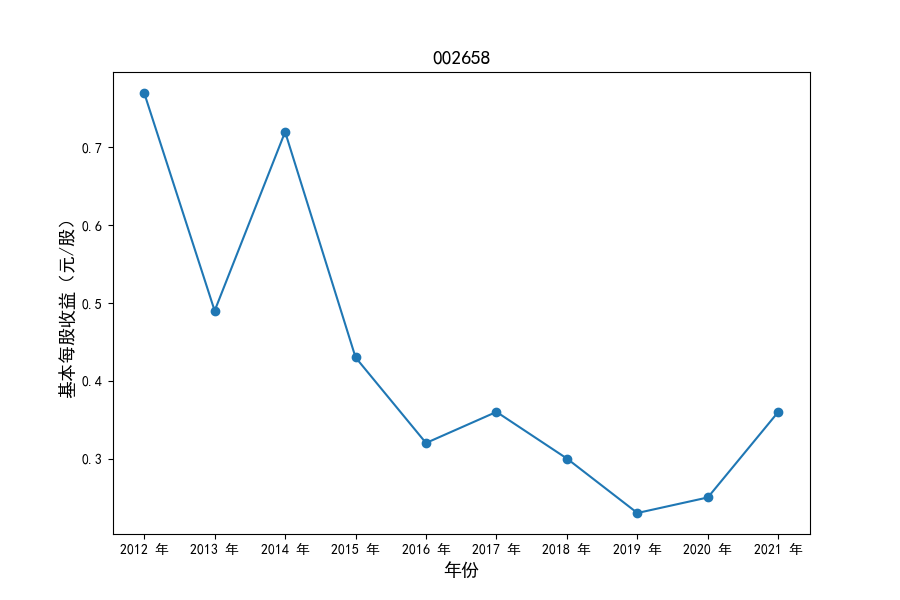
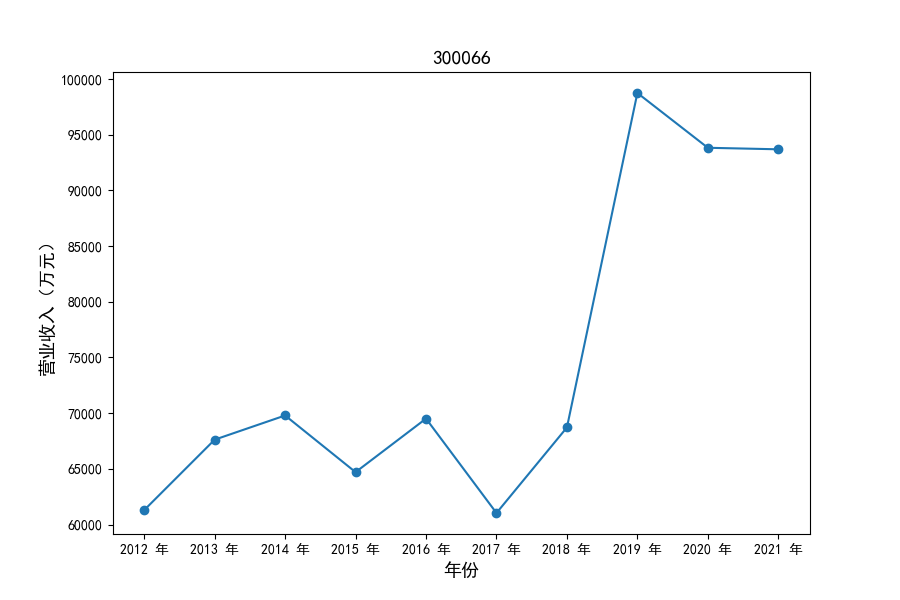
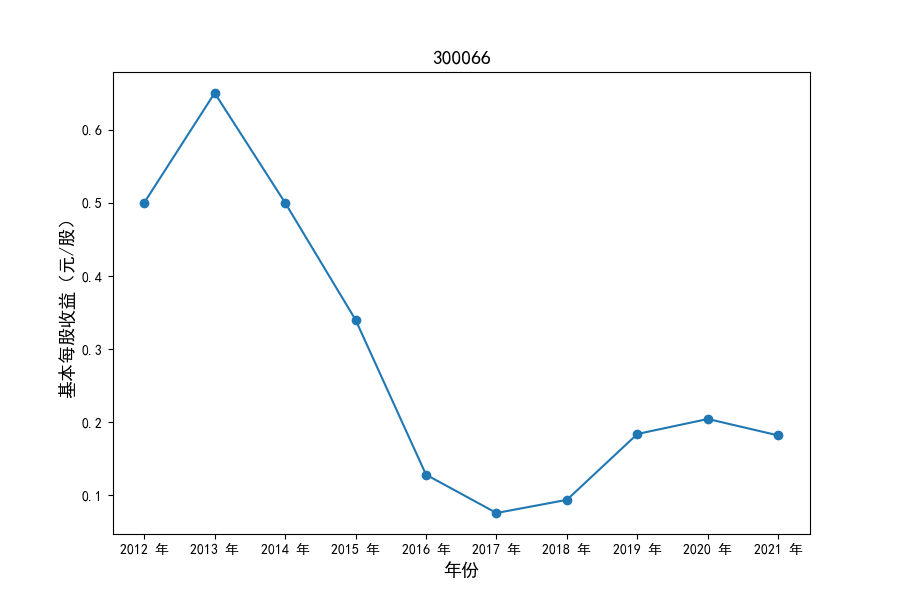
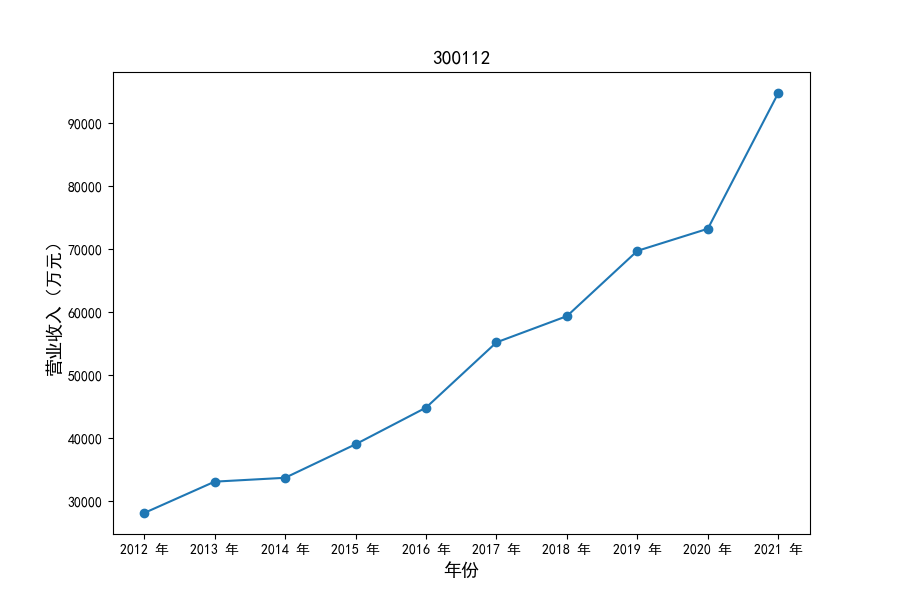
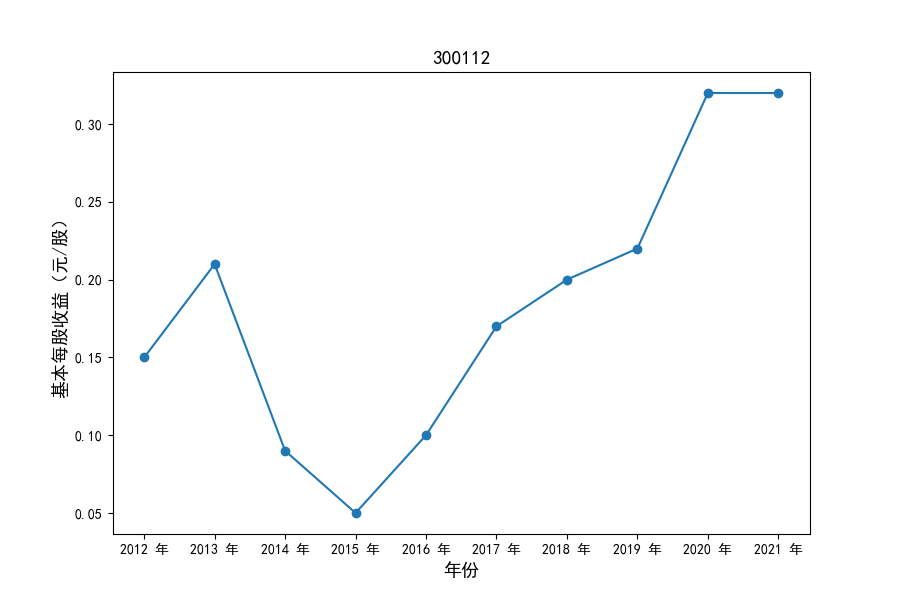
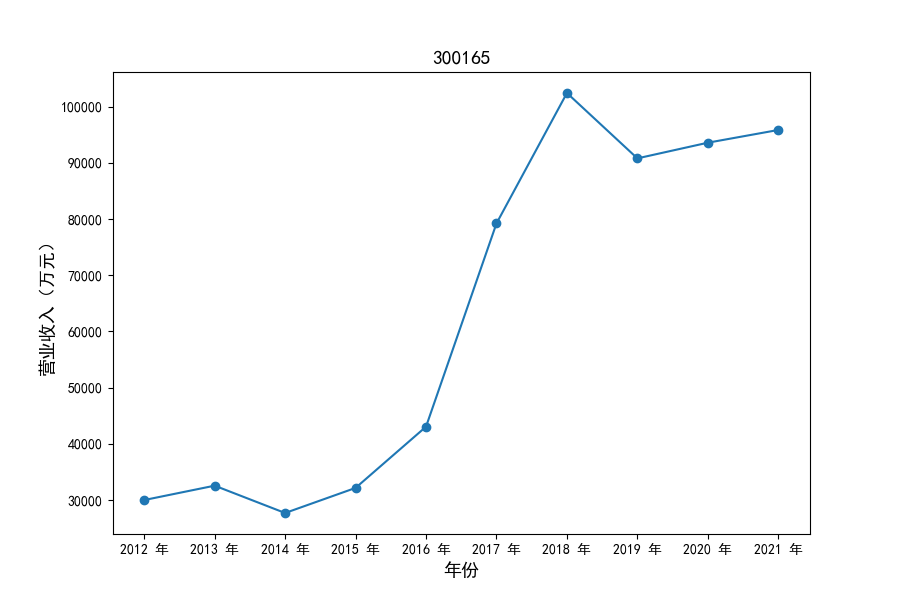
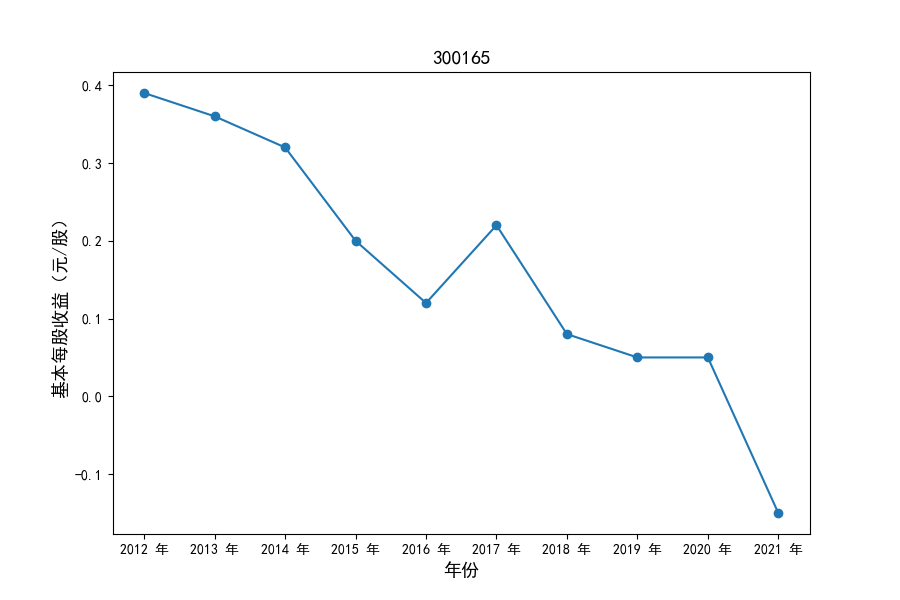
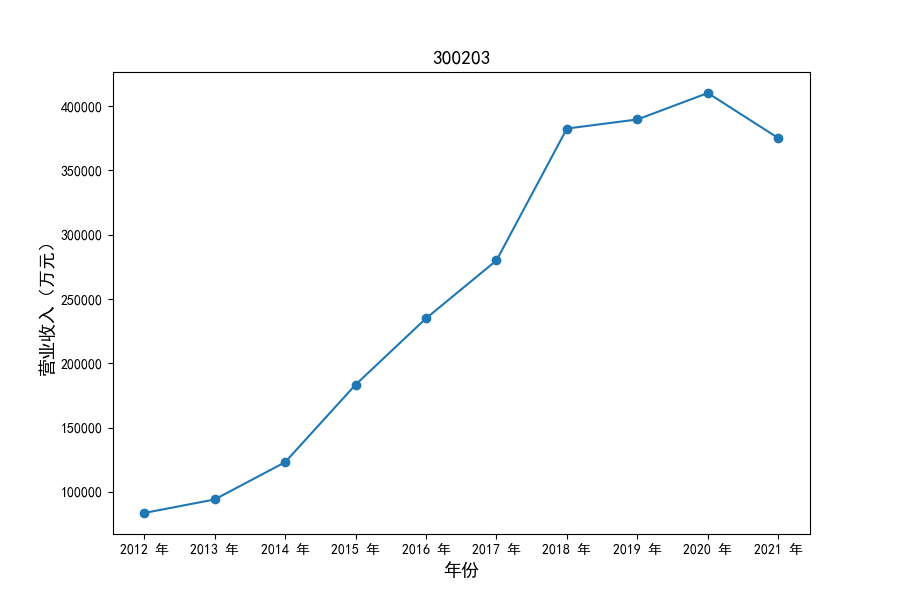
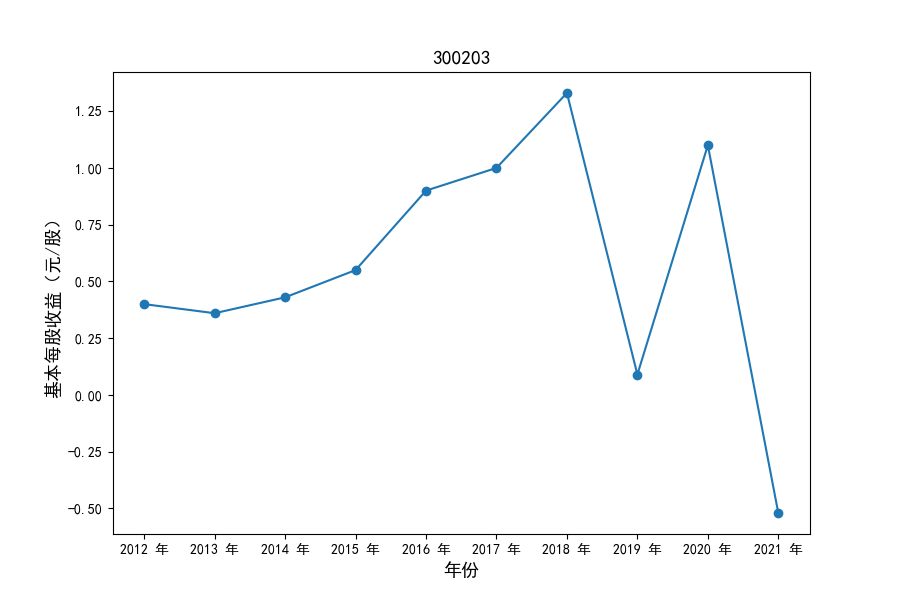
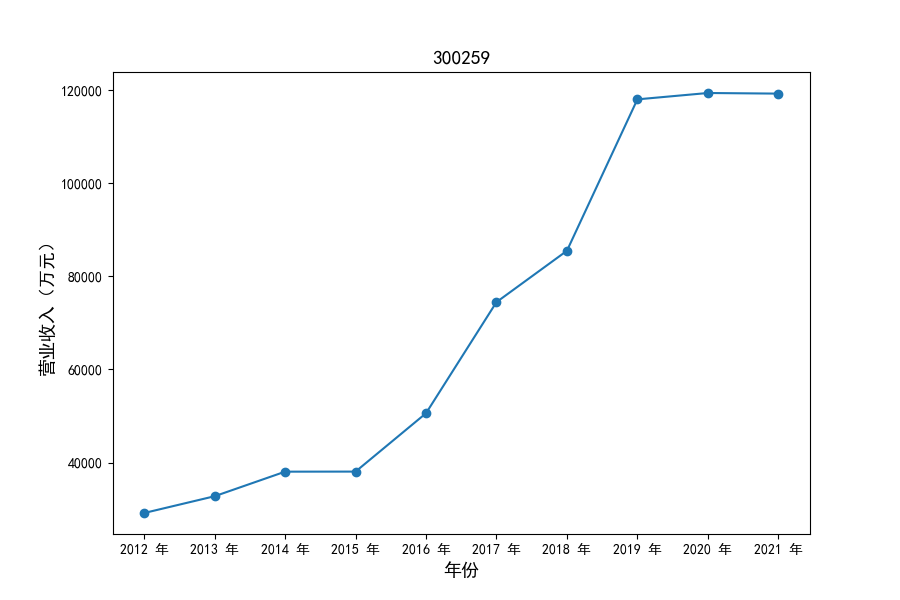
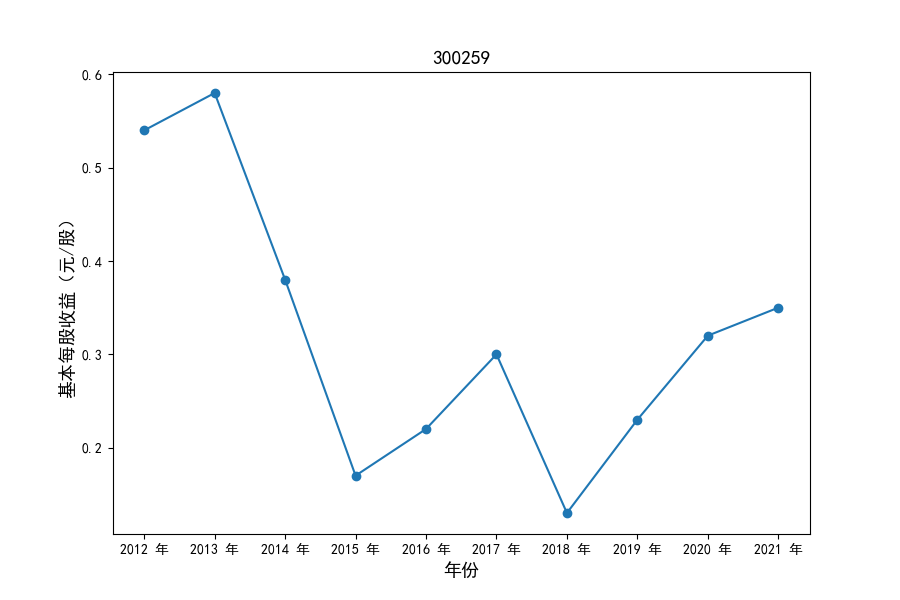
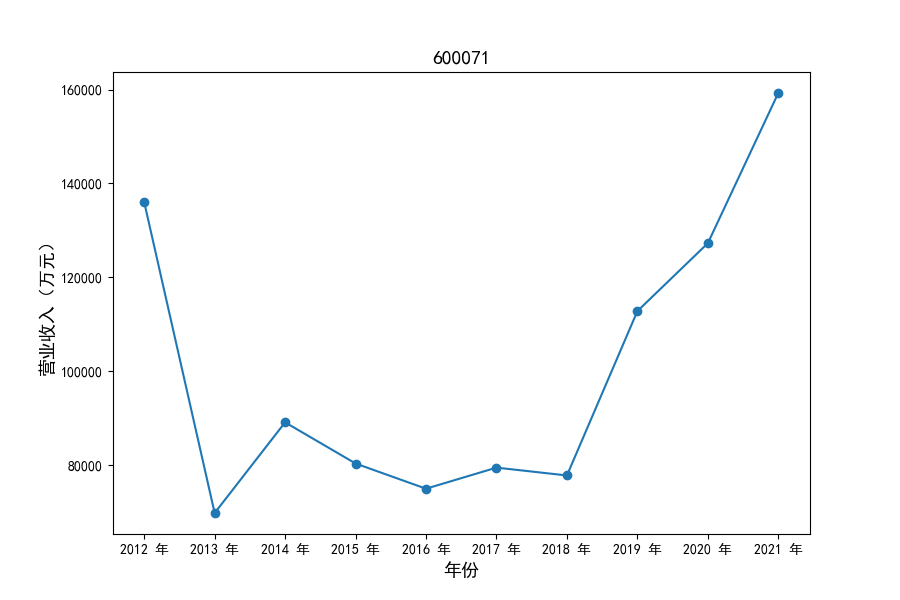
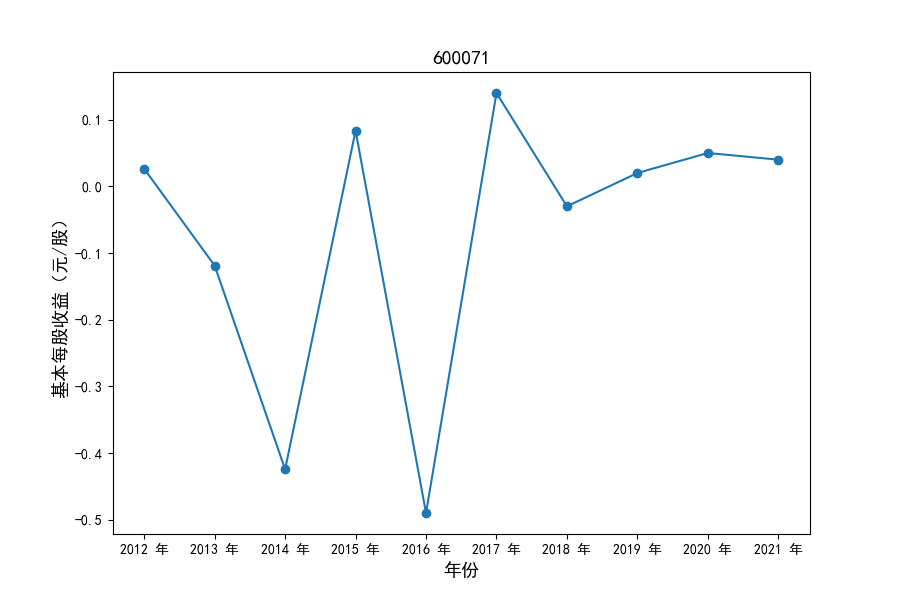
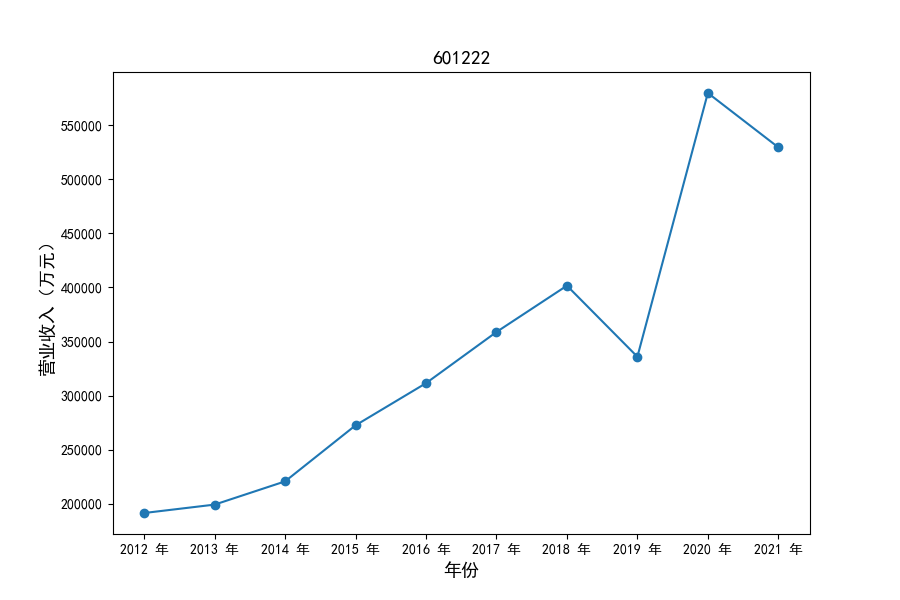
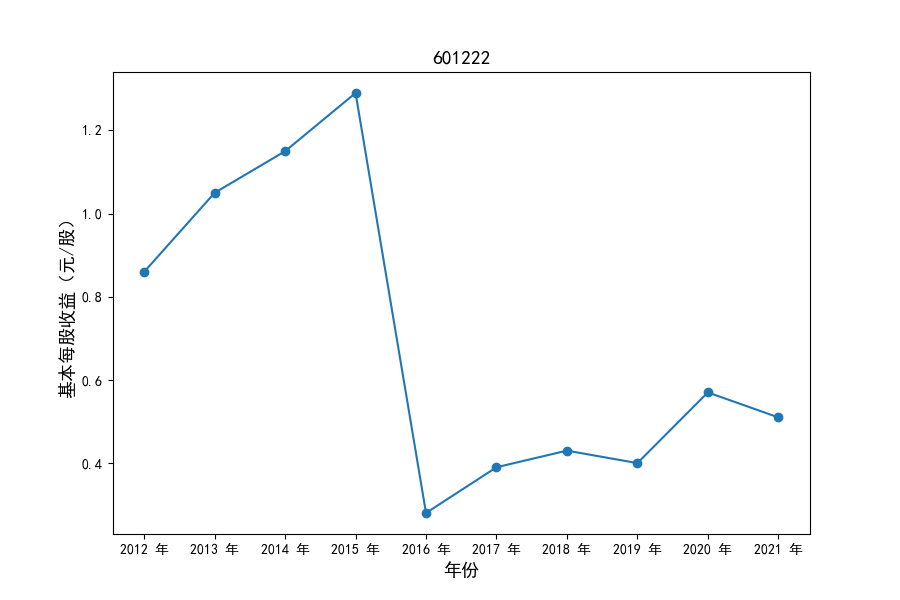
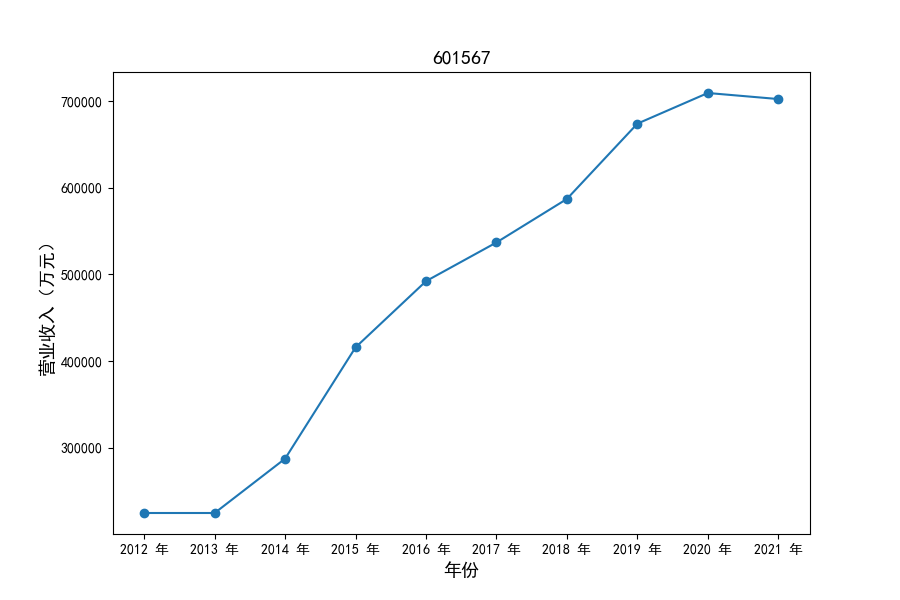
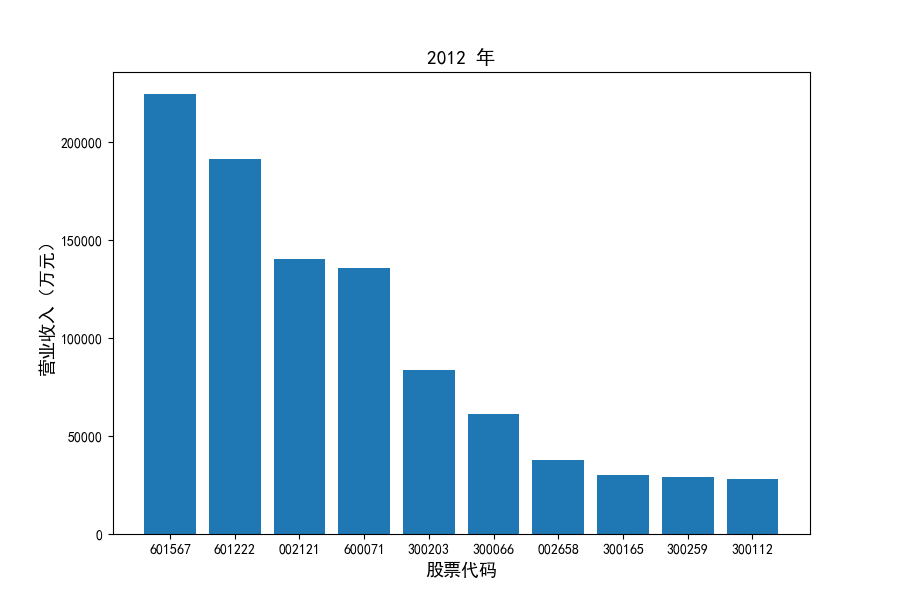
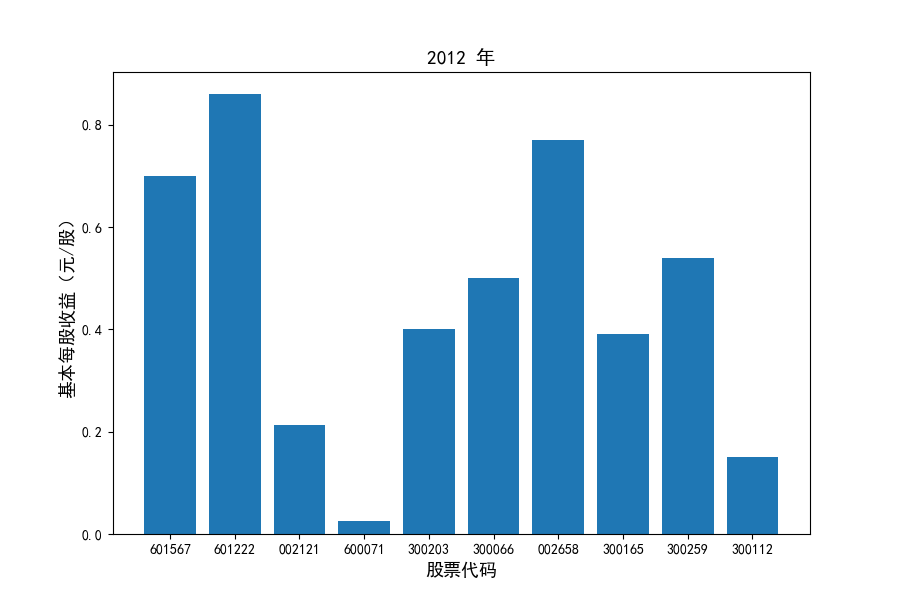
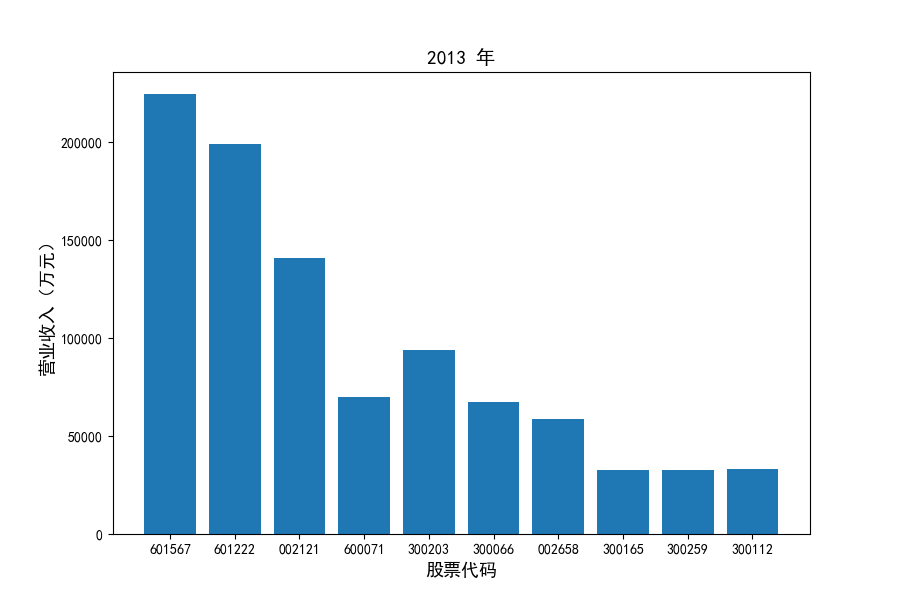
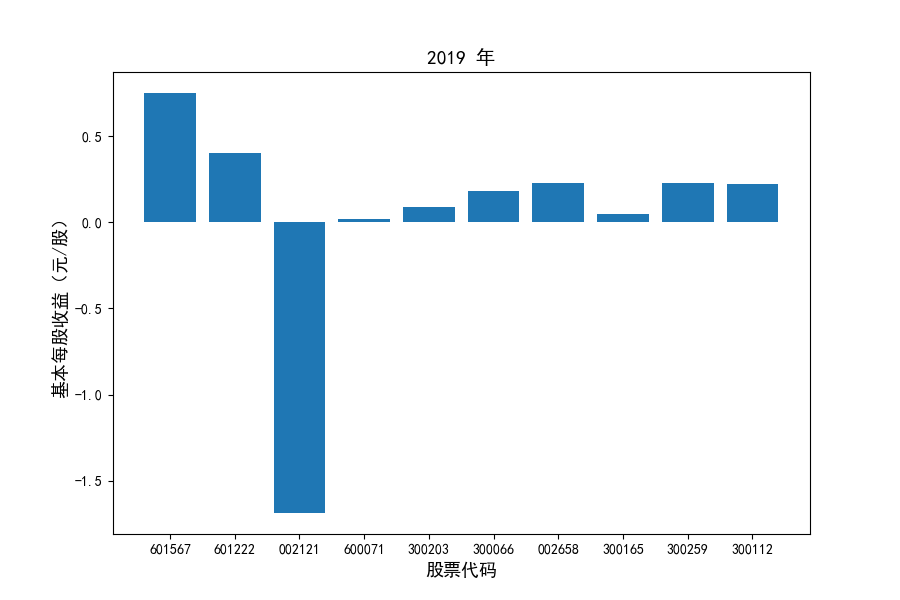
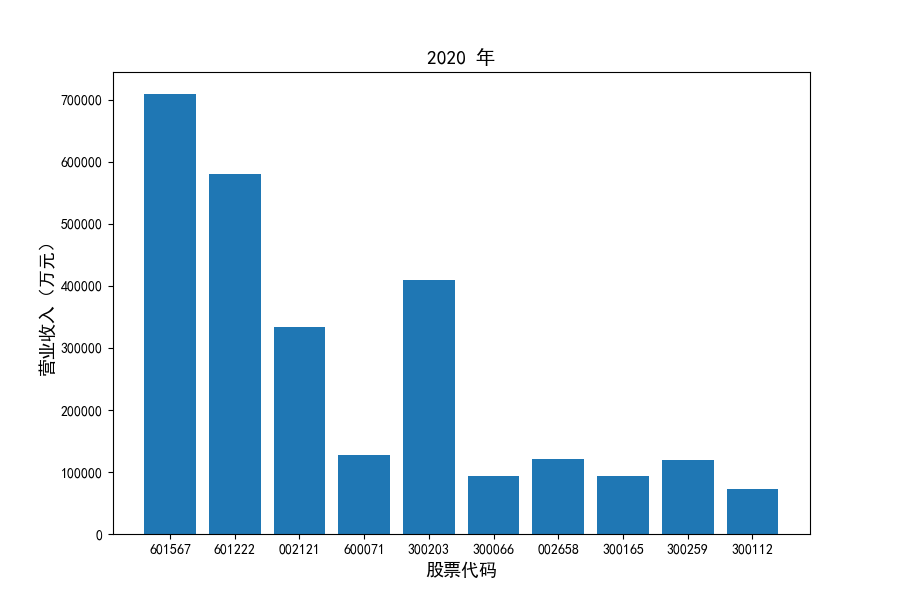
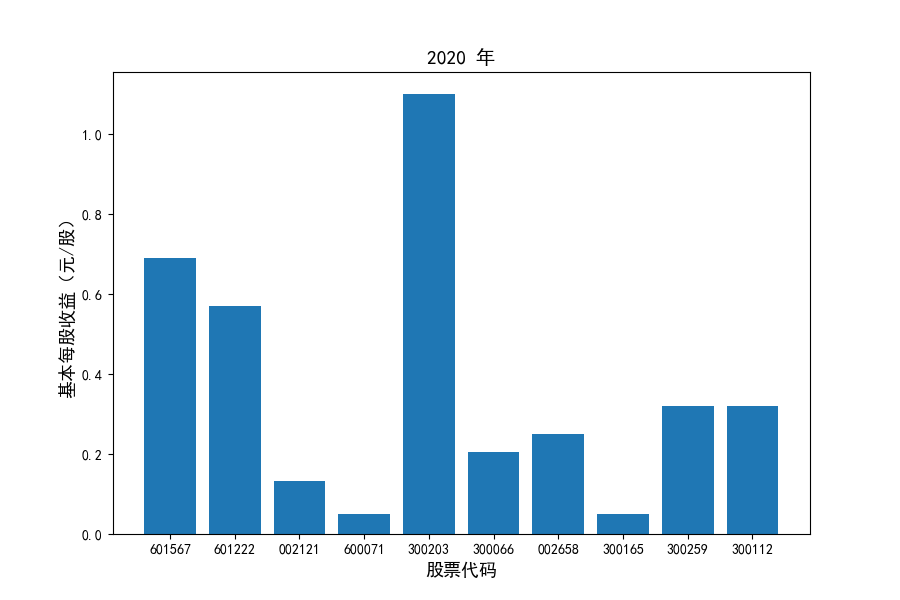
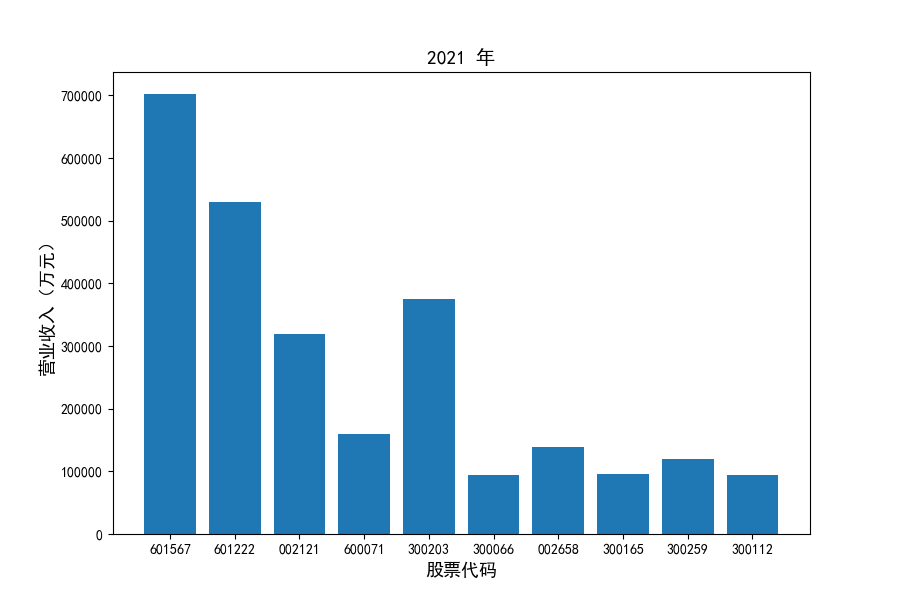
每年度各公司营业收入与每股收益对比
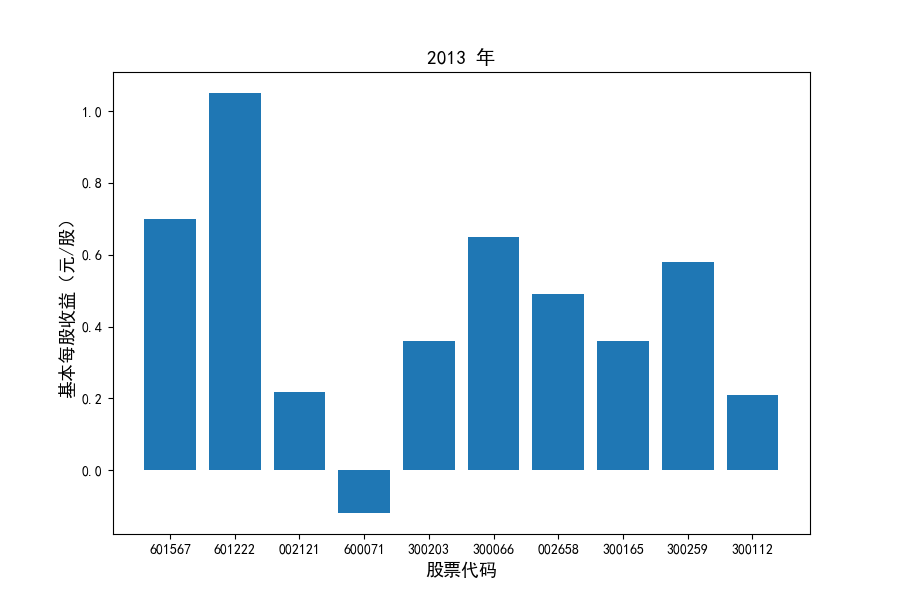
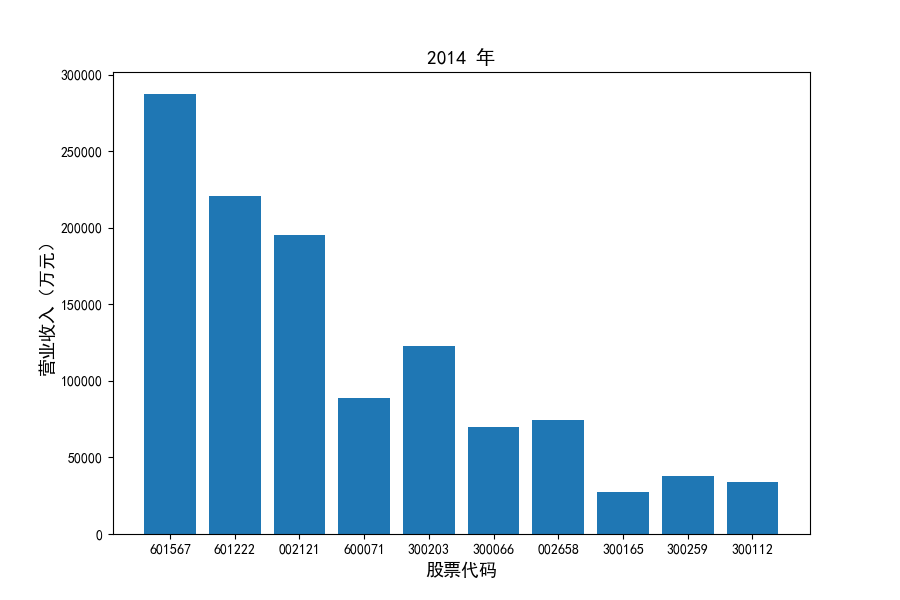
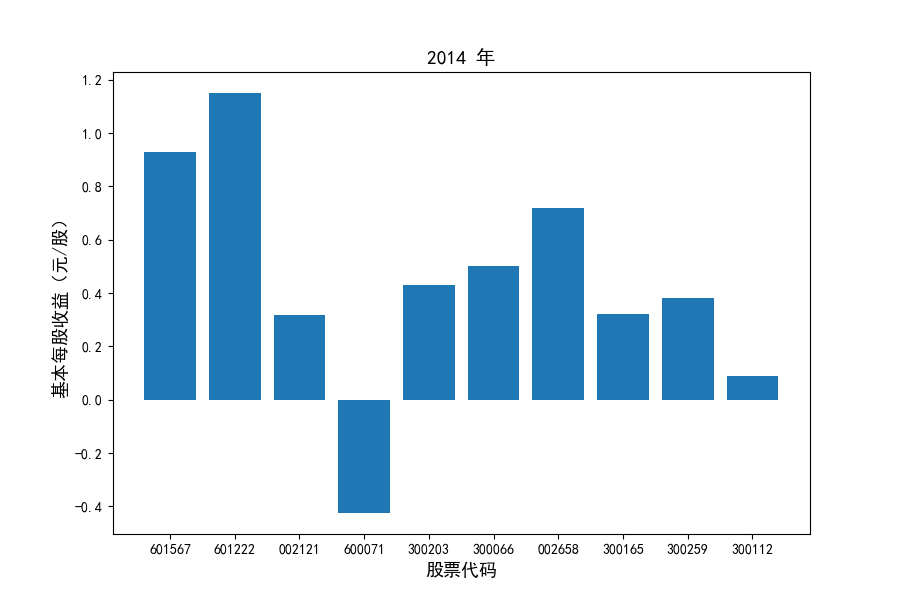
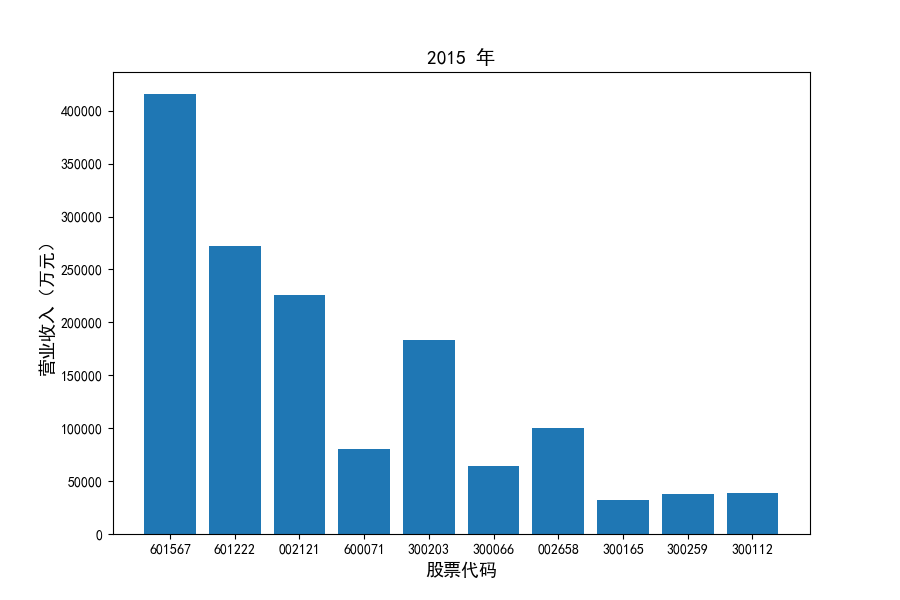
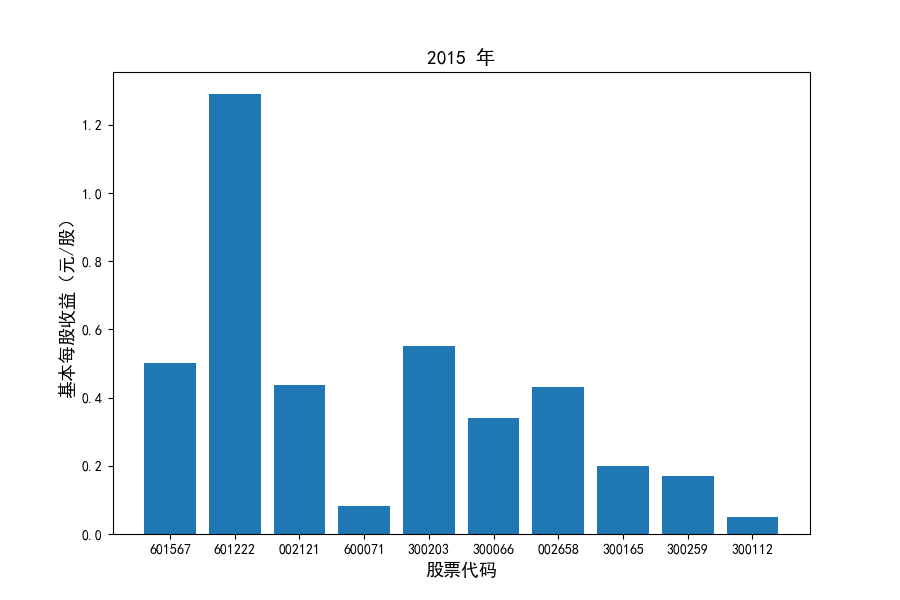
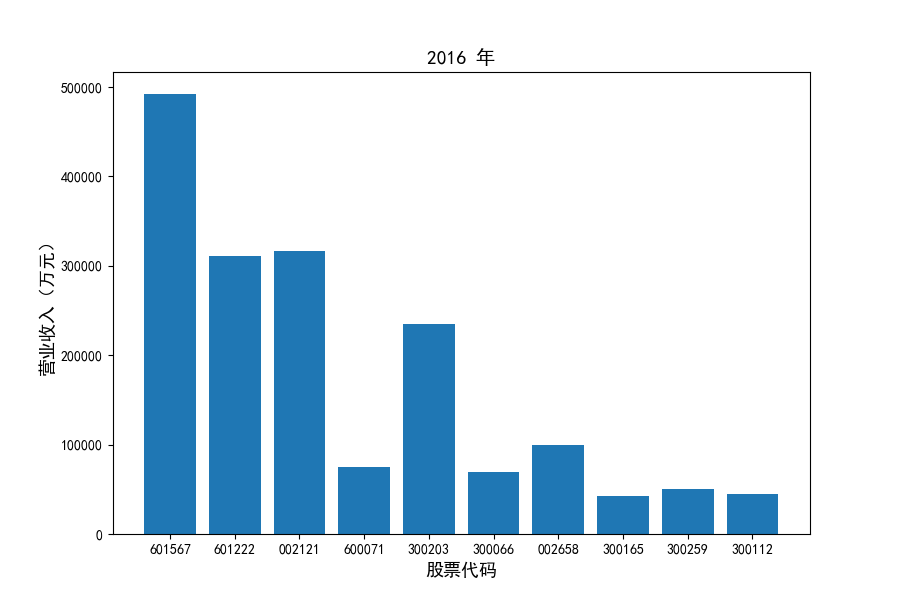
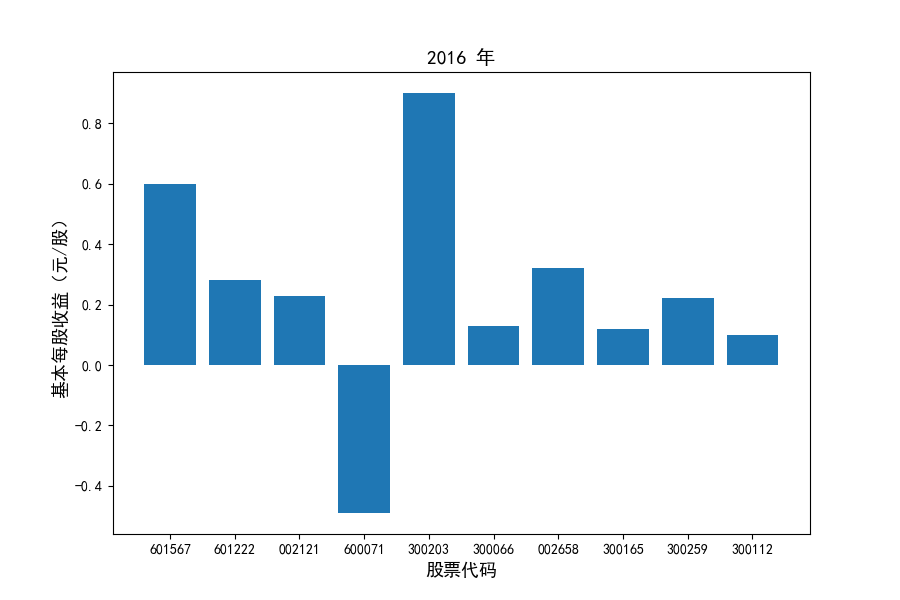
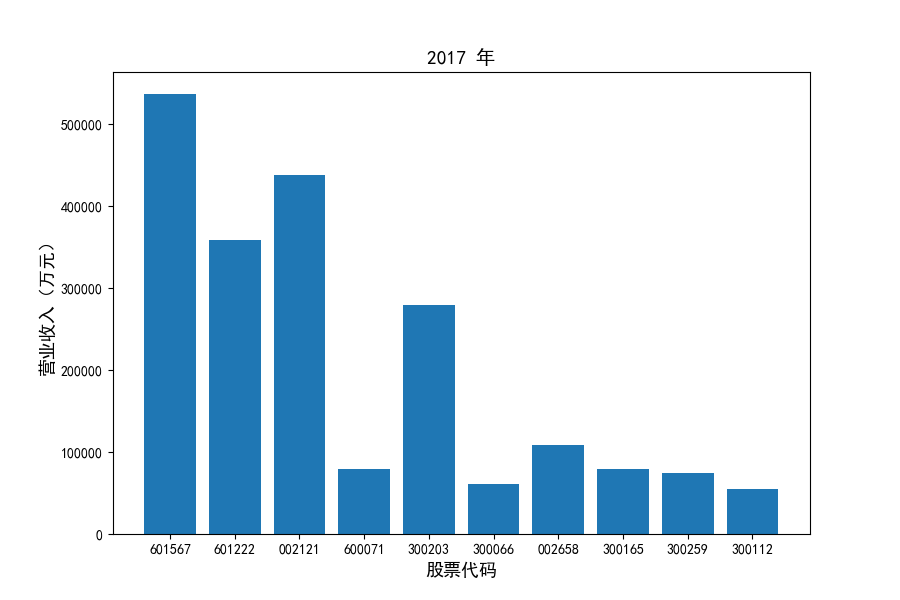
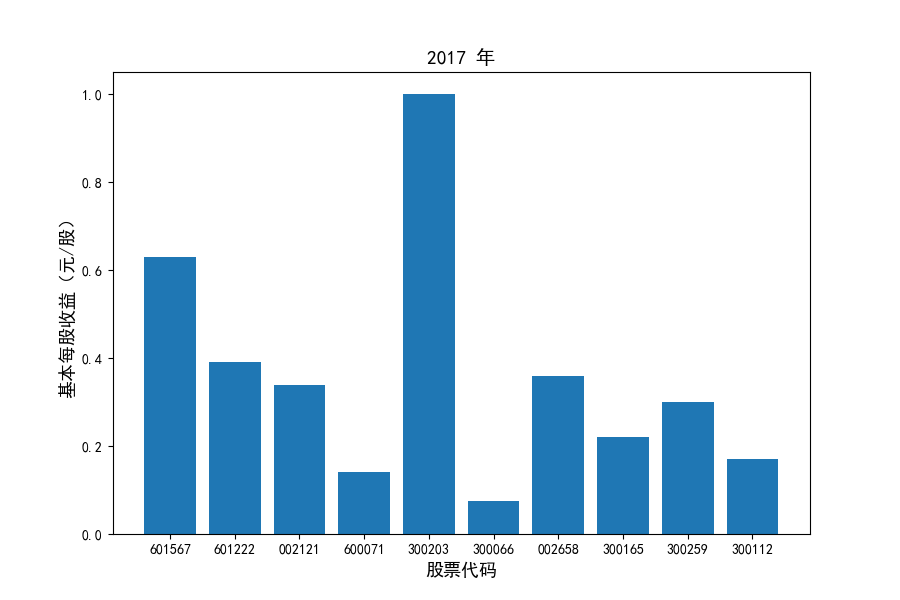
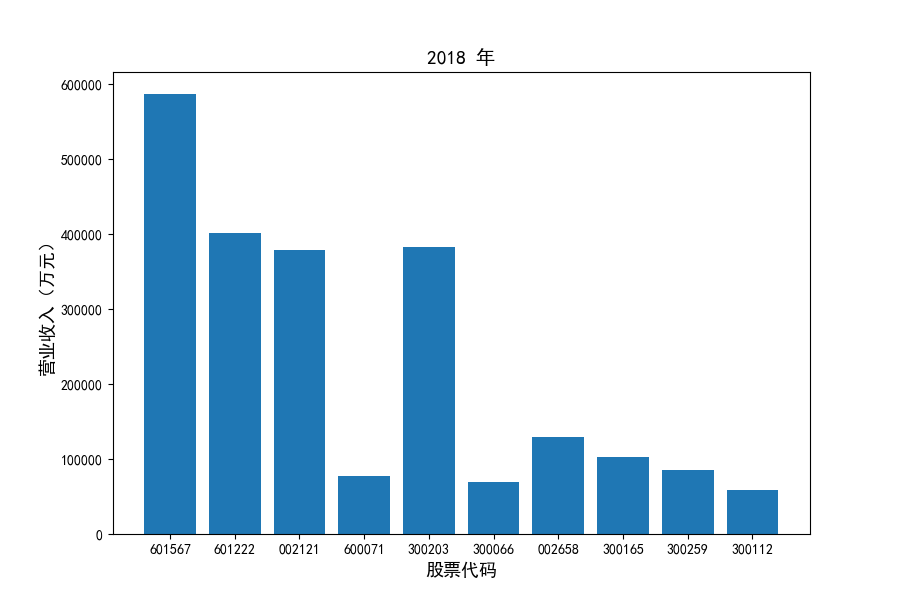
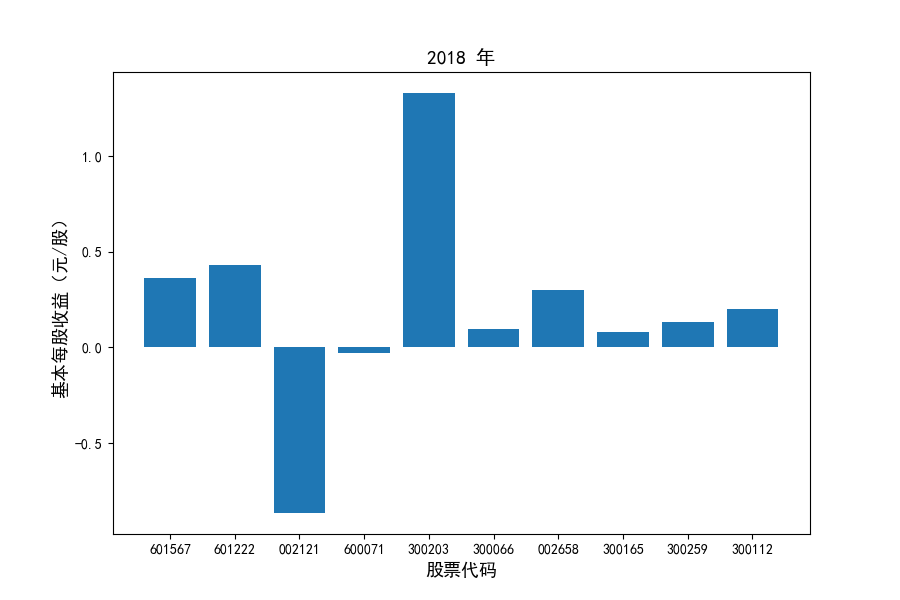
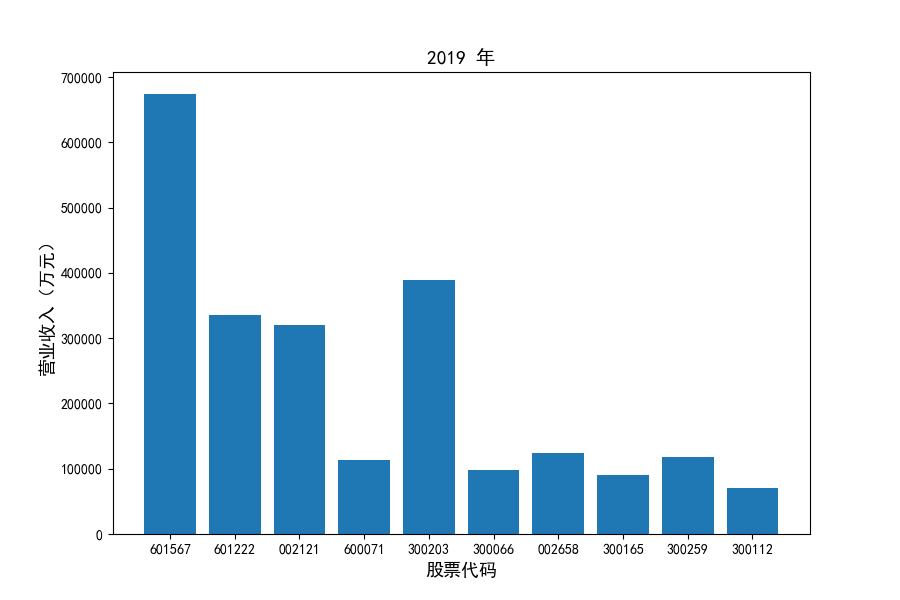
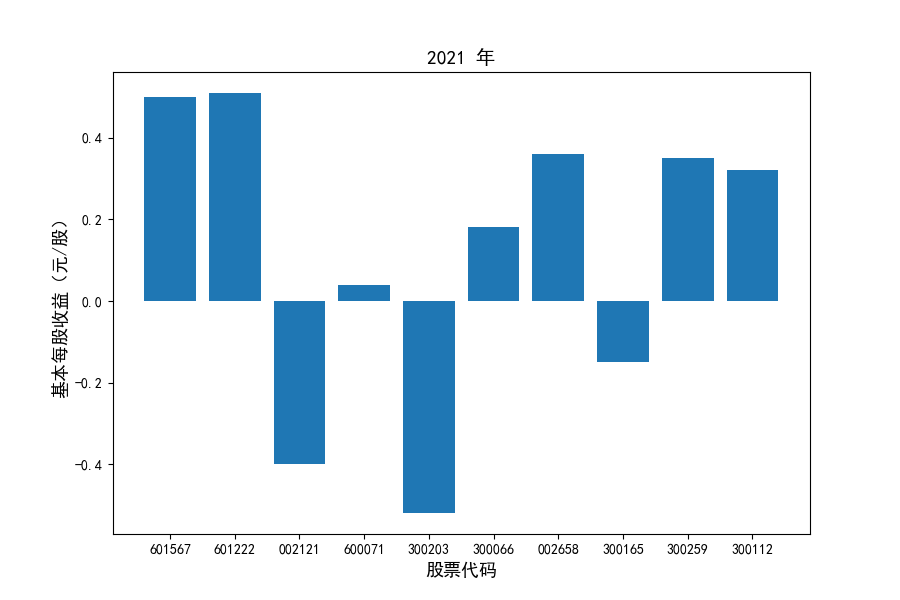
图表解读
从营业收入的绝对值分析,仪器仪表制造业排名前十的公司中共有4家年度营业收入超过十亿,剩余6家公司营业收入也迈入了亿元行列。
观察营业收入变化趋势可以发现,2012-2021年仪器仪表制造业处于快速增长时期,排名前十的上司公司在十年内营业收入都实现了倍数增长。
原因在于仪器仪表制造业不仅深耕国内市场,布局智能板块、新能源板块近年快速发展的领域,并且同样重视出口对拉动收入增长的作用,在“十二五”、“十三五”发展规划的支持下实现营业收入的迅速增长。
同时还应该观察到的是2012-2021年十年间,各家上市公司基本每股收益都存在一定的波动,其中的共同点是在2018年与2019年两年所有公司每股收益都存在不同程度的下降,这主要是受到2018年股灾的影响。
观察每年度各家上市公司营业收入的绝对体量可以发现,伴随着行业‘黄金十年’快速增长是各家公司营业收入越发明显的分化。这种分化尤其体现在行业中的头部公司之间,截止2021年,营业收入排名前三的公司年度营业收入相差20亿元左右。
上市公司利用融资和品牌优势实现了快速发展,市场和技术等资源向行业优势企业集中,提高了行业产业集中度。